从PageRank到反欺诈与TextRank

PageRank 是一种利用网页之间的连接数量和质量来计算网页重要性的技术。PageRank 算法基础上衍生出来很多重要的链接分析算法,TextRank 是其重要的衍生之一,在 nlp 领域用于文章摘要和关键词提取。
PageRank 也可以用于反作弊,网页的连接数量和质量可以类比成某个黑产团伙中的成员之间的连接数量和连接的质量,可以用于黑产成员重要性分析。

背景
最早的搜索引擎采用的是分类目录方法,即通过人工编辑审核进行网页分类并整理出高质量的网站,并按照人工编辑认为的重要程度去排序。由于早期的网页比较少,那时 Yahoo 和国内的 hao123 就是使用这种方法,在那一历史时期是可以行的。后来网页越来越多,人工分类已经不可能了。
搜索引擎采用文本检索的方式,即计算用户查询关键词与网页内容的相关程度来返回搜索结果,被搜索词语在网页中的出现次数来决定排序——出现次数越多的网页排在越前面。但是总有一些垃圾网站,来回地倒腾某些关键词使自己的搜索排名靠前,使得李鬼取代李逵,显然这种方式是不合理的。
1996 年初,谷歌公司的创始人, 当时还是美国斯坦福大学(Stanford University)研究生的佩奇(Larry Page)和布林(Sergey Brin)开始了对网页排序存在的问题进行研究。
PageRank 于 1997 年用于构建早期的搜索系统原型时提出的链接分析算法,用来衡量一个网站的好坏,使得更加重要或者等级越高的网站排名更加靠前,提升搜索结果的相关性和质量。 PageRank 的得分简称 PR 值,Google 把 PR 值分为 0 到 10 级,10 级为满分,PR 值越高说明网站越重要。

在 PageRank 提出之前,已经有研究者利用网页的入链数来表示网页的重要程度。PageRank 除了考虑入链的数量还考虑网页的质量,两者结合起来表示网页的重要性。PageRank 有两个基本假设:
数量假设:如果一个页面收到其他网页指向它的入链数越多,说明这个页面越重要。
质量假设:指向一个页面的入链质量不同,质量高的页面通过链接向其他页面传递更多的权重。
PageRank 计算公式如下:

 : 网页
: 网页
 的 PageRank 值;
的 PageRank 值;
 表示网页
链入合集中的某个网页;
表示网页
链入合集中的某个网页;
 : 网页
链入的集合;
: 网页
链入的集合;
 : 表示链入网页
的 PageRank 值;
: 表示链入网页
的 PageRank 值;
 :表示网页
链出的数量。
:表示网页
链出的数量。
初始阶段:网页通过链接关系构建起 Web 图,每个链接的页面具有相同的 PageRank 值。可以将网页的 PageRank 值都初始化为 1/N,N 是网页的数量,认为每个网页的权重一样,刚开始都是可以随机访问到的。
更新 PageRank 得分:在一轮更新页面 PageRank 得分的计算中,每个页面将其当前的 PageRank 值平均分配到本页面包含的出链上,这样每个链接即获得了相应的权值;而每个页面将所有指向本页面的入链所传入的权值求和,即可得到新的 PageRank 得分。当每个页面都获得了更新后的 PageRank 值,就完成了一轮 PageRank 计算。

具体实例
-
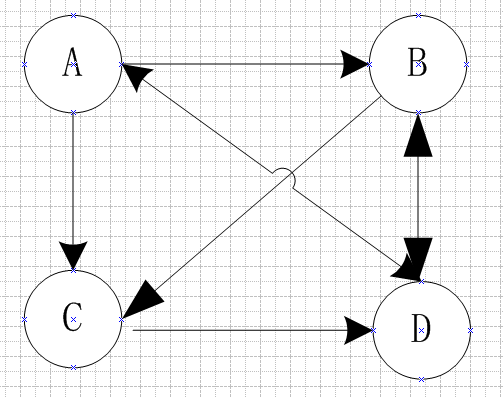
将每个网页抽象成一个节点 如果一个页面 A 有链接直接链向 B,则存在一条有向边从 A 到 B
PageRank 值简称 PR 值,意义是一个网页被访问的概率,初始时用户访问每个页面的概率均等,假设一共有 N 个网页,每个网页的初始 PR 值 = 1 / N。

3.2 PageRank计算


上面左图是邻接矩阵,以列为源,行为目标节点,那么从 A 到 B,C,D 都能连通,那么矩阵对应的位置都为1,即 [0,1,1,1]。因为是有向图,所以 B 不能到 A,B 可以到 C、D,因此第二列是 [0 0 1 1],以此类推构建邻接矩阵。
那么 A 节点有多大的概率跳到 B 节点呢?因为 A 节点有三个出度,所以分给 B,C,D 各三分之一。B 节点有两个出度,给 C、D 各二分之一,以此类推构建概率转移矩阵,如上面右图。


以此类推,PR 值向量,不断左乘概率转移矩阵 M,更新 PR 值,直到 P 收敛,即 
上面网络结构图是一个马尔科夫过程的实例,要满足收敛性,需要具备一个条件:
图是强连通的,即从任意网页可以到达其他任意网页。
实际中互联网上网页可能不满足强连通性,有的网页不指向任何网页。如果按照上面矩阵相乘的计算,会导致前面累计的转移概率被清零,这样下去,最终的得到的概率分布向量所有元素几乎都为 0。假设我们把上面图中 C 到 D 的链接改成 D 到 C,C 变成了一个终止点,得到下面这个图:
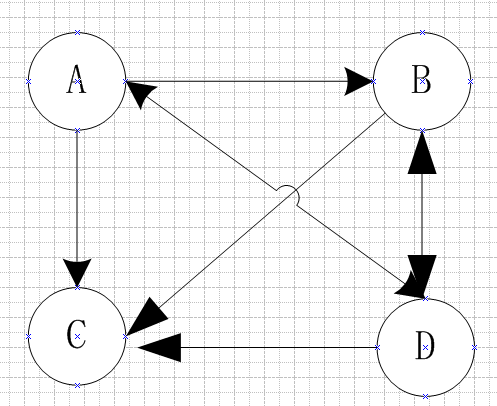
概率转移矩阵变成了

3.4 陷阱问题
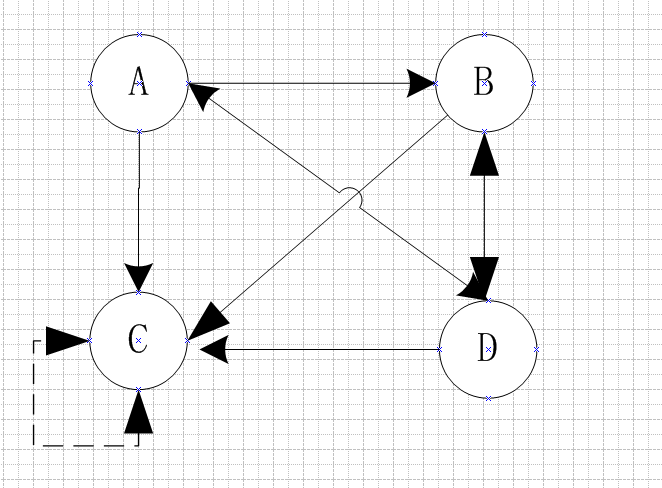

3.5 改进的PageRank公式
一个上网者,随机浏览页面有两个选择:
-
从当前页面跳转 -
在浏览器中直接输入新地址
上网者通过点击链接开启新页面的概率为 d(d 也称阻尼系数,通常取 0.85)。此时,我们的 PageRank 模型变为:在每一个页面,用户都有 d 的概率通过点击链接进入下一个页面;此外,还有 1-d 的概率随机跳转,此时跳转到其他页面的概率为 1/M(M 表示网页的总结点)。改进后的 PageRank 公式为:


PR 值计算过程变为:

由于存在一定的概率跳出循环,因此可以避免陷阱问题。
3.6 PageRank优缺点
优点:是一个与查询无关的静态算法,所有网页的 PageRank 值通过离线计算获得;有效减少在线查询时的计算量,极大降低了查询响应时间。
缺点:
人们的查询具有主题特征,PageRank 是主题无关的;因为下一时刻 PageRank 值与前一时刻的 PageRank 值无直接关系,即算法是主题无关的,只取决于入度的权重。假设有一个搜索引擎,其相似度计算函数不考虑内容相似因素,完全采用 PageRank 来进行排序,那么这个搜索引擎的表现是什么样子的呢?这个搜索引擎对于任意不同的查询请求,返回的结果都是相同的,即返回 PageRank 值最高的页面。
旧的页面等级会比新页面高。因为即使是非常好的新页面也不会有很多上游链接,除非它是某个站点的子站点。
3.7 简单实现代码
下面是上图计算内容的简单代码,用 python3 写的。虽然没有 PageRank 的源码那么完善,但是有助于学习 PageRank 算法的理解。
# -*- coding: utf-8 -*-
from numpy import *
def pro_transfer(a): # 构建概率转移矩阵
b = transpose(a) # b为a的转置矩阵
c = zeros((a.shape), dtype=float)
for i in range(a.shape[0]):
for j in range(a.shape[1]):
c[i][j] = a[i][j] / (b[j].sum())
print(c)
print("===================================")
return c
def init_pr(M): # PageRank值初始化
pr = zeros((M.shape[0], 1), dtype=float) # 构造一个存放pr值得矩阵
for i in range(M.shape[0]):
pr[i] = float(1) / M.shape[0]
print(pr)
print("======================================")
return pr
def page_rank(m, v): # 计算pageRank值
while ((v == dot(m, v)).all() == False):
#判断pr矩阵是否收敛,(v == dot(m, v)).all()判断前后的pr矩阵是否相等,若相等则停止循环
v = dot(m, v)
return v
def page_rank_d(d, m, v): # 计算pageRank值,增加阻尼系数
while ((v == d * dot(m, v) + (1 - d) / m.shape[0]).all() == False):
# 判断pr矩阵是否收敛,(v == d * dot(m, v) + (1 - d) / m.shape[0]).all()判断前后的pr矩阵是否相等,若相等则停止循环
v = d * dot(m, v) + (1 - d) / m.shape[0]
return v
if __name__ == "__main__":
a_matrix = array([[0, 0, 0, 1],
[1, 0, 0, 1],
[1, 1, 0, 0],
[1, 1, 1, 0]], dtype=float) # 构建邻接矩阵
M = pro_transfer(a_matrix) # 构建概率转移矩阵
pr = init_pr(M)
d = 0.85 # 阻尼系数
print(page_rank(M, pr)) # 计算pr值,无阻尼系数
print("==================================")
print(page_rank_d(d, M, pr))# 计算pr值,有阻尼系数

反欺诈方向应用
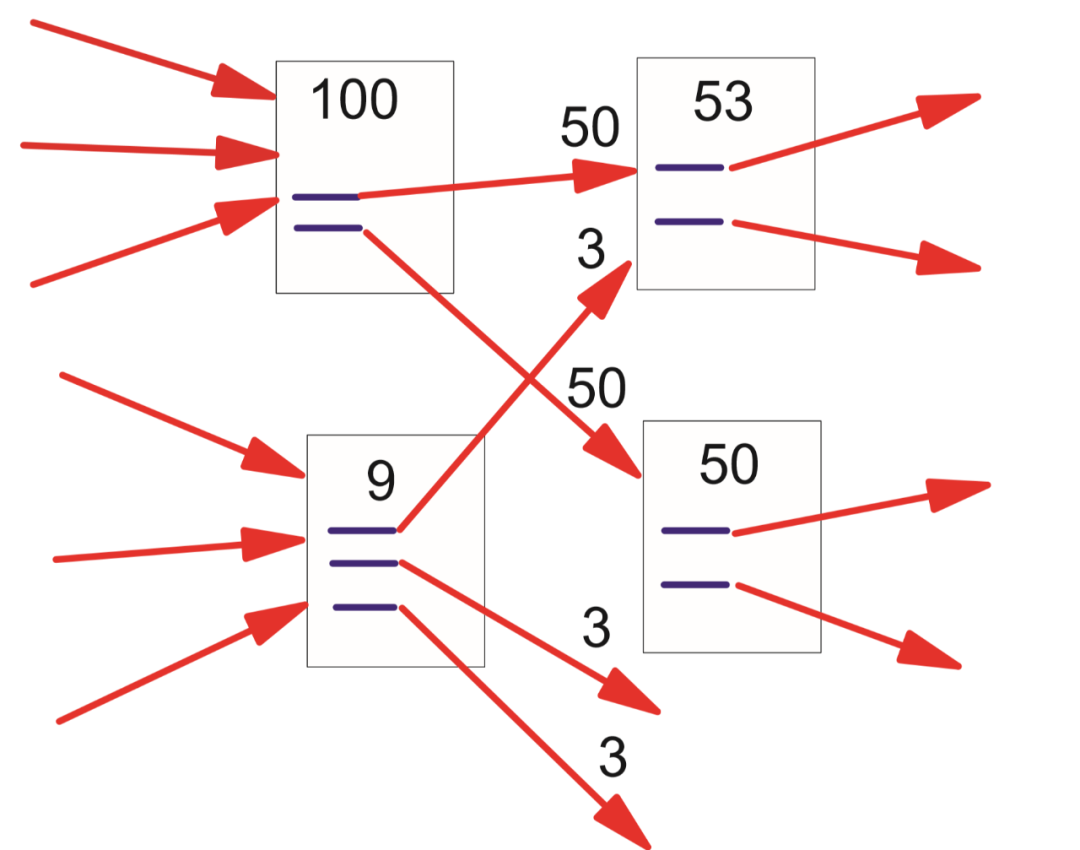
数量假设:如果很多人转账给一个人员,说明这个人员更加重要。
质量假设:假设有个用户叫张三,转账给张三的人的质量不同。质量低的人员向张三转账传递的权重小,质量高的人员向张三转账传递的权重大;越多质量高的人员向张三转账,说明张三越重要。
4.1 实践过程
可以套用改进的 PageRank 公式,那么原始公式中变成以下含义:

初始化阶段:人员通过链接关系构建有向图,有链接关系的初始化 PageRank 值为1,没有链接关系的初始化为 0,从而构造了邻接矩阵;之后使用邻接矩阵构建概率转移矩阵;
在一轮更新人员 PageRank 值的时候,都是将其 PageRank 值链出,指向出链上的每个人员即可获得相应的权值,每个人员指向自己的入链所传入的权值和就是其新的 PageRank 得分。
当所有人的 PageRank 都更新后,就完成了一轮迭代。在每一轮迭代中,人员当前的 PageRank 值会不断得到更新。通过若干轮的计算,每人会获得最终的 PeopleRank 值。(本质是计算邻接矩阵的特征值)
4.2 应用实例
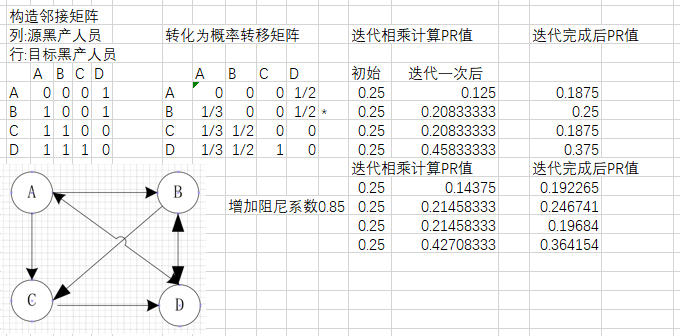
▲ 整个实例
问:一个思考小问题,影响团伙成员的关系不仅仅有转账人数、转账人的质量,还应该有转账的总金额,如何去设计一个更加完善的 PageRank 呢?
答:转账的总金额全局归一化后,可以设计为边的权重,来表达数额的重要性。TextRank 就是一种带权重的 PageRank 衍生出来的。

TextRank
文章提取有两种方式,抽取式和生成式。抽取式提取文中关键信息,可以是词也可以是句子。生成式使用自然语言理解生成技术,形成自我总结的词句,不是文章中的原文,算法相对复杂,可控性差一些。TextRank 是基于 PageRank,用于提取文本的关键词和摘要,属于抽取式的方式。
在 TextRank 的论文中,PageRank 表述为:使用









问:为什么这里的PageRank介绍公式和上文的介绍公式不同?
答:因为这是两个论文,上面的是 PageRank 论文中写的,这个是 TextRank 论文中表述的 PageRank 的公式。我是忠于他们的原文,这样便于更好的衔接 TextRank 算法的介绍,虽然两者符号上有差异,但是表述的内容是一致的。
自然语言文本构建包括从文本中提取的单元(节点)之间有多个或部分链接。因此,将两个节点

-
确定定义的文本单元,将其添加到图形的节点中。 -
确定连接这些文本单元的关系,边可以是有向或无向的,加权或未加权的。 -
迭代基于图的排名算法,直到收敛为止。 根据最终得分对节点排序,使用附加到每个节点的值进行排名/选择决策。
5.1 基于TextRank的关键词提取
-
将给定文本按照整句进行分割,即 ; -
对于每个句子 ,对其进行分词和词性标注,然后剔除停用词,只保留指定词性的词,如名词、动词、形容词等,即 ,其中 保留后的候选关键词; -
构建词图 ,其中 V 为节点集合,由以上步骤生成的词组成,然后采用共现关系构造任意两个节点之间的边:两个节点之间存在边仅当它们对应的词在长度为 K 的窗口中共现,K 表示窗口大小,即最多共现 K 个单词,一般 K 取 2;其实这里也可以改成 word2vec 来表示两个词,之后采用相似度衡量公式,例如余弦相识度来衡量两个词的相似性,根据实际效果来选择相似度的方式。 -
根据上面的公式,迭代计算各节点的权重,直至收敛; -
对节点的权重进行倒序排序,从中得到最重要的 t 个单词,作为 top-t 关键词; -
对于得到的 top-t 关键词,在原始文本中进行标记,若它们之间形成了相邻词组,则作为关键词组提取出来。
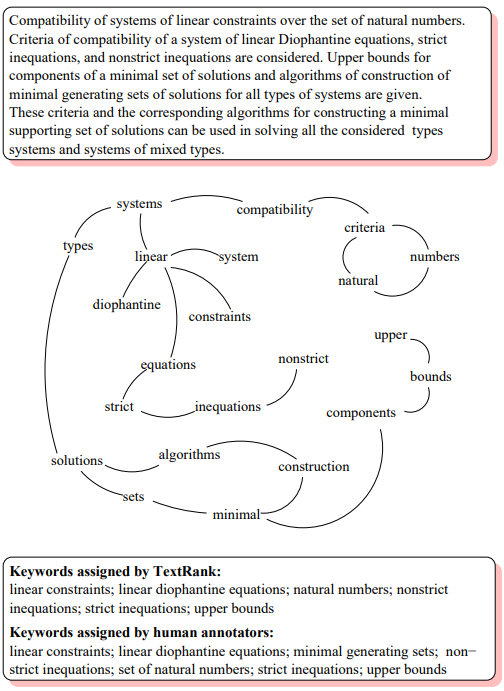
▲ 论文中关键词抽取图和效果
从文章中提取关键句,将每个句子作为一个节点,两个句子节点对应的边是无向有权的,他们的相似性衡量公式如下:




公式中:分子部分同时出现在两个句子中的同一个词的数量;分母是对句子中词的个数求对数后求和,这样的目的是为了遏制较长的句子在相似度计算上的优势。
这个相似度衡量公式感觉像是 Jaccard 相似度衡量公式的改版,相似度也可以将句子改成 word2vec 之后采用余弦相似度或者其他相似度公式衡量两个句子的相似性,具体看实际效果。
其他步骤和关键词提取步骤类似,不同点在于根据相似度计算公式遍历计算任意两个节点之间的相似度,设置阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后迭代计算每个节点的 TextRank 值,排序后选出 TextRank 值最高的几个节点对应的句子作为关键句。
5.3 PageRank和TextRank异同点
TextRank 从 PageRank 衍生出来的,思想有共通之处都是通过图模型构造节点和边,节点的值表示重要程度。
区别在于,PageRank 的网络构建是根据网页之间的链接关系,而 TextRank 的网络构建是根据词句的共线关系;PageRank 构造的网络中的边是有向无权边,而 TextRank 构造的网络中的边是无向有权边。

一点感想
有时候我们对算法不够了解,有时候只是知道算法在他原始的应用场景或者同类的应用场景;如果我们能在对算法有全面了解的基础上,拓宽思路和扩展思维方式,有种破界创新的勇气,这样有利于各种算法和产业更好的相结合,促进算法落地和扩展在业务中的应用范围。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。







