基于 Python 的自动文本提取:抽象法和生成法的比较

本文为 AI 研习社编译的技术博客,原标题 :Text Summarization in Python: Extractive vs. Abstractive techniques revisited
翻译 | 田栋文、二十六 整理 | 凡江
原文链接:https://rare-technologies.com/text-summarization-in-python-extractive-vs-abstractive-techniques-revisited/
本博客是对文本摘要的简单介绍,可以作为当前该领域的实践总结。它描述了我们(一个RaRe 孵化计划中由三名学生组成的团队)是如何在该领域中对现有算法和Python工具进行了实验。
我们将现有的 提取方法(Extractive)(如LexRank,LSA,Luhn和Gensim现有的TextRank摘要模块)与含有51个文章摘要对的Opinosis数据集进行比较。我们还尝试使用Tensorflow的文本摘要算法进行抽象技术(Abstractive),但由于其极高的硬件需求(7000 GPU小时,$ 30k云信用额),因此无法获得良好的结果。
为什么要文字摘要?
随着推送通知和文章摘要获得越来越多的需求,为长文本生成智能和准确的摘要已经成为流行的研究和行业问题。
文本摘要有两种基本方法:提取法和抽象法。前者从原始文本中提取单词和单词短语来创建摘要。后者学习内部语言表示以生成更像人类的摘要,来解释原始文本的意图。

文本摘要有两种基本方法:提取和抽象。
提取文本摘要
首先,简单描述当前已经存在的一些流行的文本摘要算法和实现:
Gensim中的文本摘要
gensim.summarization模块实现了TextRank,这是一种Mihalcea等人的论文中基于加权图的无监督算法。它也被另一个孵化器学生Olavur Mortensen添加到博客 - 看看他在此博客上之前的一篇文章。它建立在Google用于排名网页的流行PageRank算法的基础之上。TextRank的工作原理如下:
预处理文本:删除停止词并补足剩余的单词。
创建把句子作为顶点的图。
通过边缘将每个句子连接到每个其他句子。边缘的重量是两个句子的相似程度。
在图表上运行PageRank算法。
选择具有最高PageRank分数的顶点(句子)
在原始TextRank中,两个句子之间的边的权重是出现在两个句子中的单词的百分比。Gensim的TextRank使用Okapi BM25函数来查看句子的相似程度。它是Barrios等人的一篇论文的改进。
PyTeaser
PyTeaser是Scala项目TextTeaser的Python实现,它是一种用于提取文本摘要的启发式方法。
TextTeaser将分数与每个句子相关联。该分数是从该句子中提取的特征的线性组合。TextTeaser中的特征如下:
titleFeature:文档和句子标题共有的单词数。
sentenceLength:TextTeaser的作者定义了一个常量“理想”(值为20),它表示摘要的理想长度,以表示字数。 sentenceLength计算为距此值的标准化距离。
sentencePosition:规范化的句子数(句子列表中的位置)。
keywordFrequency:词袋模型中的术语频率(删除停用词后)。
有关摘要的句子特征的更多信息,请参阅Jagadeesh等人的基于句子提取的单文档摘要。
PyTextRank
PyTextRank是原始TextRank算法的python实现,具有一些增强功能,例如使用词形结构而不是词干,结合词性标注和命名实体解析,从文章中提取关键短语并基于它们提取摘要句子。除了文章的摘要,PyTextRank还从文章中提取了有意义的关键短语。PyTextRank分四个阶段工作,每个阶段将输出提供给下一个:
在第一阶段,对文档中的每个句子执行词性标注和词形还原。
在第二阶段,关键短语与其计数一起被提取,并被标准化。
通过近似句子和关键短语之间的jaccard距离来计算每个句子的分数。
根据最重要的句子和关键短语总结文档。
Luhn的算法
该算法[ PDF ] 于1958年发布,通过考虑文档中经常出现的“重要的”单词以及由于非重要单词与这些单词之间的线性距离,对摘要提取的句子进行排名。
LexRank
LexRank是一种类似于TextRank的无监督图形方法。LexRank使用IDF修改的余弦作为两个句子之间的相似性度量。该相似度用作两个句子之间的图形边缘的权重。LexRank还采用了智能的后处理步骤,确保为摘要选择的顶级句子彼此不太相似。
更多关于LexRank与TextRank的比较可以在这里找到。
文本摘要中的潜在语义分析(LSA)
LSA的工作原理是将数据投影到较低维空间而不会有任何重要信息丢失。解释该空间分解操作的一种方式是奇异向量可以捕获并表示在语料库中重复出现的单词组合模式。奇异值的大小表示模式在文档中的重要性。
如果奇异向量和奇异值之类的术语似乎不熟悉,我们建议这个教程,其中涵盖了LSA的理论,如果你是初学者,其中有python的实现教程可以帮助到您(对于熟练的人,为了强大而快速的实现,使用gensim中的LSA)。
如何评估文本摘要质量?
ROUGE-N指标
对于LexRank,Luhn和LSA方法,我们使用Sumy 摘要库来实现这些算法。我们使用ROUGE-1指标来比较所讨论的技术。
Rouge-N是模型和黄金摘要(gold summary)之间的单词N-gram度量。
具体而言,它是在模型和黄金摘要中出现的N-gram短语的计数与在黄金摘要中出现的所有N-gram短语的计数的比率。
解释它的另一种方法是作为召回值来衡量模型摘要中出现的黄金摘要中有多少N-gram。
通常对于摘要评估,只使用ROUGE-1和ROUGE-2(有时候ROUGE-3,如果我们有很长的黄金摘要和模型)指标,理由是当我们增加N时,我们增加了需要在黄金摘要和模型中完全匹配的单词短语的N-gram的长度。
例如,考虑两个语义相似的短语“apples bananas”和“bananas apples”。如果我们使用ROUGE-1,我们只考虑单词,这两个短语都是相同的。但是如果我们使用ROUGE-2,我们使用双字短语,因此“apples bananas”成为一个与“bananas apples” 不同的单一实体,导致“未命中”和较低的评价分数。
例:
黄金摘要:A good diet must have apples and bananas.
模型 Apples and bananas are must for a good diet.
如果我们使用ROUGE-1,则得分为7/8 = 0.875。
对于ROUGE-2,它是4/7 = ~0.57。
上述比率可以解释为我们的算法从所有相关信息的集合中提取的相关信息量,这正是召回(recall)的定义,因此Rouge是基于召回的。
更多关于如何计算得分的例子都在这里中。
BLEU指标
BLEU指标是一种经过修改的精度形式,广泛用于机器翻译评估。
精度是黄金和模型转换/摘要中共同出现的单词数与模型摘要中单词数的比率。与ROUGE不同,BLEU通过采用加权平均值直接考虑可变长度短语 - 一元分词,二元分词,三元分词等。
实际指标只是修改精度,以避免模型的翻译/摘要包含重复的相关信息时的问题
例:
黄金摘要:A good diet must have apples and bananas.
模型摘要:Apples and bananas are must for a good diet.
如果我们仅考虑一元分词的BLEU指标,即一元分词的权重为1,所有其他N-gram权重为0,我们的BLEU比率计算为7/9 = 0.778。
分别对于一元分词和二元分词的权重[0.6,0.4],该比率变为0.6 *(7/9)+ 0.4 *(4/8)= 0.667。
具有修正N-gram精度的 BLEU
修改的N-gram精度的关键是,一旦在模型摘要中识别出参考短语/单词,就应该将其视为耗尽。这个想法解决了模型摘要中重复/过度生成的单词的问题。
通过首先找到单个/短语在任何单个引用中出现的最大次数来计算修改的N-gram精度。此计数成为该单词/短语的最大引用计数。然后,我们通过其最大引用计数剪切每个模型词/短语的总计数,在模型转换/摘要中添加每个单词的剪切计数,并将总和除以模型转换/摘要中的单词/短语的总数。
关于BLEU论文的链接(见上文)在其修改的N-gram精度上有很好的例子。
一句话总结:ROUGE和BLEU得分越高,摘要越好。
数据集
使用51篇文章的Opinosis数据集(Opinosis指一种基于图形的方法,针对高度冗余的意见进行抽象总结)进行比较。 每篇文章都是与产品的功能相关,如iPod的电池寿命等。这些文章是购买该产品客户的评论的集合。 数据集中的每篇文章都有5个手动编写的重点摘要。 通常5个重点摘要是不同的,但它们也可以是重复5次的相同文本。
模型参数
对于Gensim 的TextRank(Gensim一个python NLP库,TextRank是python的文本处理工具,<span arial",sans-serif;color:red;background:="" white;font-style:normal'="">Gensim集成基于<span arial",sans-serif;color:red;background:="" white;font-style:normal'="">Textrank的文本摘要模块),输出总结中的单词计数(word_count)设置为75。
对于Sumy-LSA和Sumy-Lex_rank,输出摘要(sentence_count)中的句子数设置为2。
结果
获得的ROUGE-1和BLEU得分的平均值和标准差显示在下表中。
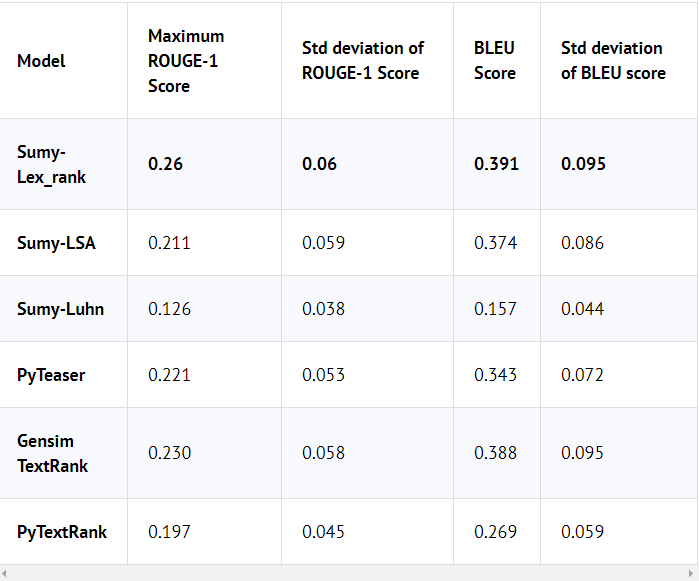
每个总结的ROUGE分数是在这五个(个人重要摘要)分数中的最大ROUGE分数。
对于BLEU评分,我们使用NLTK的bleu_score模块,其中unigrams,bigrams和trigrams的权重分别为0.4,0.3,0.2。
对于具体示例,请查看Garmin 255W导航设备的这篇评论。 查看人工和模型生成的摘要。
定性评估
LexRank是这儿的胜者,因为它产生了更好的ROUGE和BLEU得分。 不幸的是,我们发现它生成的总结比Gensim的TextRank和Luhn模型的总结信息量少。 此外,LexRank并不总是在ROUGE得分中击败TextRank 。 例如,TextRank在DUC 2002数据集上的表现略好于LexRank。 所以LexRank和TextRank之间的选择取决于你的数据集,这是值得尝试这两者的。
从数据中推导的另一个结论是Gensim的Textrank优于普通的PyTextRank,因为它在纯TextRank中使用BM25函数代替了Cosine IDF函数。
该表的另一点是Luhn的算法具有较低的BLEU分数。 这是因为它提取了更长的概要,因此涵盖了对产品的更多评论。 不幸的是,我们无法缩短它,因为Sumy中Luhn算法的封装不提供更改字数限制的参数。
抽象文本抽样
一种神经网络方法
Google的Textsum是一种最先进的开源抽象文本概要架构。 它可以根据前两个句子创建新闻文章的头条。
以Textsum形式的Gigaword数据集(前两个句子,头条)训练了400万对之后,这已经展示出了良好的结果。 在训练期间,它根据文章的前两句优化了概要的可能性。 编码层和语言模块是同时训练。 为了生成概要,它搜索所有可能概要的地方,以找到给定文章的最可能的单词序列。
以下是用于训练TextSum模型以及模型生成的概要的数据示例。

请注意“head”一词不会出现在原始文本中。 该模型已生成它。 这在以上几种的提取算法中永远不会发生。
我们运行了谷歌提供的Tensorflow网络并调整了一些超参数。 不幸的是,我们仅仅能在需要的时间内训练模型10%,并获得质量非常低的概要。 由于这个获得的概要没有任何意义,我们甚至无法使用上面的ROUGE和BLEU分数。
为了比较对神经网络架构的不同调整,我们不得不求助于使用适合训练集“运行平均损失”的模型的数学测量。 可以在此要点中建立模型的平均运行损耗图。
训练了多少才算够?
Tensorflow的作者建议实施培训数百万个时间步骤,以成功地在现他们的结果。 这意味着在启用GPU的群集上需要为期数周的培训时间。 谷歌自己使用10台机器,每台4个GPU,持续训练一个周。 这相当于运行 GPU 7000个小时或3万美元的AWS云信用。 但是在我们的处理中,我们没有这样的硬件资源。
此外,Google TextSum作者使用Annotated English Gigaword数据集,且数据集需要3000美元的许可证。 因此,我们使用相对较小但免费的新闻文章数据集:CNN和DailyMail来代替Annotated English Gigaword数据集。 这些320k文章被转换成Textsum兼容格式和词汇。 你可以通过github使用我们的代码生成你自己的TextSum兼容的预处理CNN和DailyMail数据。
最初,使用默认参数的培训是在NVIDIA GTX 950M笔记本电脑上完成的,但是即使在培训超过48小时后算法似乎也没有收敛。 为了加快过程并生成有意义的概要,我们切换到配备NVIDIA K520 GPU的g2.2xlarge Amazon EC2设备上。
注意
我们不充分训练的TextSum模型生成的非常差的概要的一些示例。 这类似于在Pavel Surmenok的博客中训练TextSum的尝试。
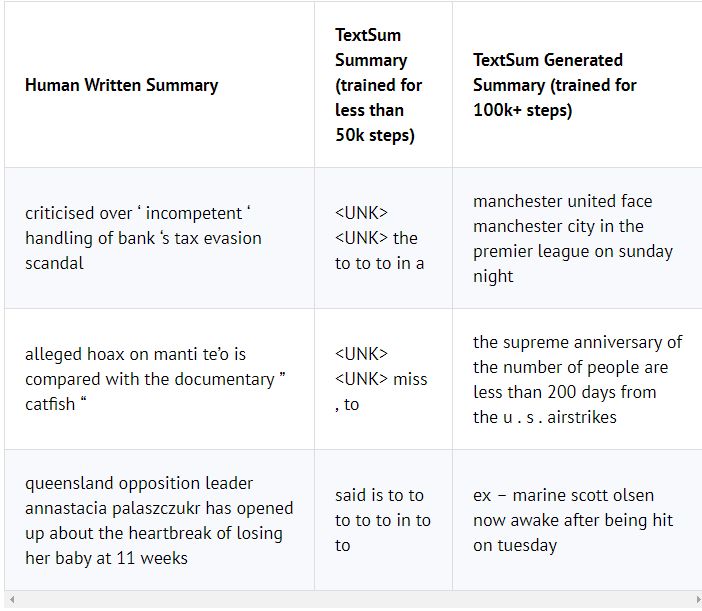
某些词语在许多概要中,然而不考虑这些词语是否出现在实际文章及其在测试集中的概要中,例如, “曼彻斯特联合”和“曼彻斯特城市”这一短语在生成的概要中重复了很多次。
另一个观察是,最初(global_steps <50000)模型没有生成语法正确的句子,因为我们训练模型的持续时间更长,生成的概要开始有意义,语法稍微变得正确。但是,生成的概要仍然与原始文章以及相应的人为摘要完全无关。
只有在50,000个时间步之后,损失(以及概要的语义质量)才有明显的改善。在接近一天训练了100,000个时间步长之后,我们观察了质量 - 在这里我们使用我们的主观理解来判断所述质量 – 概要总体上有所改善。即便如此,摘要显然不符合标准。考虑到培训时间,这是可以预期的。该模型的作者声称,如果用户愿意在所需时间和计算方面进行权衡,则可以获得更好的结果。
总结
对于提取技术,我们的测量告诉我们:LexRank的表现稍优于Gensim的TextRank,但同时我们也观察到TextRank能够提供更高质量的概要。 我们认为这个使用的数据集会影响获得的总结的质量。 一个好的做法是运行两种算法并使用其中一个能够提供更令人满意的概要的算法。 未来的方向是将Gensim的TextRank实现与Paco Nathan的PyTextRank进行比较。
由于缺乏GPU资源和许多优化参数,我们结束了对抽象概括的研究,在这一点上我们无法绝对推断该模型可以用作当前提取实现的替代方案。当然,人们总是可以尝试在几百万(更多)时间步长内训练模型并调整一些参数,以查看结果在CNN-Dailymail数据集或其他数据集上是否变的更好。
想要继续查看该篇文章更多代码、链接和参考文献?
戳链接:
http://www.gair.link/page/TextTranslation/1069



