【NPJ|数字医药】医学影像的机器学习:方法学的失败和对未来的建议

摘要
医学图像的计算机分析研究为改善病人的健康带来了许多希望。然而,一些系统性的挑战正在减缓该领域的进展,从数据的局限性(如偏差)到研究激励(如优化出版)。在这篇文章中,我们回顾了开发和评估方法的障碍。根据来自文献和数据挑战的证据,我们的分析表明,在每一步中,潜在的偏见都可能渗入。我们还积极地讨论了目前为解决这些问题所作的努力。最后,对今后如何进一步解决这些问题提出了建议。
引言
作为当今人工智能(AI)革命的基石,机器学习通过医学图像为临床实践带来了新的承诺。例如,在根据医学图像诊断各种疾病时,机器学习的表现与医学专家不相上下。软件应用程序开始被认证用于临床。机器学习可能是实现几十年前在医学领域勾勒出的人工智能愿景的关键。风险很高,关于医学图像的机器学习的研究数量惊人。但这种增长并不必然导致临床进展。更高的研究量可以与学术动机相结合,而不是临床医生和患者的需要。例如,可能有大量的论文显示了基准数据的最先进性能,但对临床问题没有实际的改善。关于机器学习治疗COVID的话题,Robert等人回顾了62项已发表的研究,但没有发现有临床应用潜力。
在这篇论文中,我们探索了提高机器学习在医学成像中的临床影响的途径。在概述了情况后,在章节中记录了不平衡的进展,这并不全是关于更大的数据集,我们研究了医学影像论文中经常出现的一些失败,在“出版生命周期”的不同步骤: 使用什么数据,使用什么方法和如何评估它们,以及如何发布结果。在每个部分,我们首先讨论问题,支持从以前的研究证据以及我们自己的分析最近的论文。然后,我们讨论了一些改善这种状况的步骤,有时借鉴了相关社区的做法。我们希望这些想法将有助于塑造研究实践,从而更有效地解决现实世界的医学挑战。
并不全是大数据集
大型标记数据集的可用性使得解决困难的机器学习问题成为可能,例如计算机视觉中的自然图像识别,其中数据集可以包含数百万张图像。因此,人们普遍希望在医疗应用领域也能取得类似的进展,算法研究最终应该能够解决一个临床问题,即判别任务。然而,医疗数据集通常较小,在数百或数千个量级: 共享一个由16个“大型开源医疗成像数据集”组成的列表,规模从267到65,000个受试者不等。请注意,在医学成像中,我们指的是受试者的数量,但一个受试者可能有多个图像,例如,在不同的时间点拍摄的图像。为了简单起见,我们假设诊断任务为每个受试者提供一张图像/扫描。很少有临床问题会像能够被自然地框定为机器学习任务的恰当的判别任务那样。但是,即使是这些,更大的数据集也不能带来希望的进展。一个例子是阿尔茨海默病(AD)的早期诊断,由于人口老龄化,这是一个日益增长的健康负担。早期诊断将打开早期干预的大门,这最有可能是有效的。大量的研究工作已经获得了有患AD风险的老年人的大量脑成像群组,利用机器学习可以开发早期的生物标志物。因此,应用机器学习开发计算机辅助诊断AD或其前身轻度认知障碍的典型样本量稳步增加。这种增长在出版物中清晰可见,如图1a,一项荟萃分析汇编了来自6篇系统综述的478篇研究。
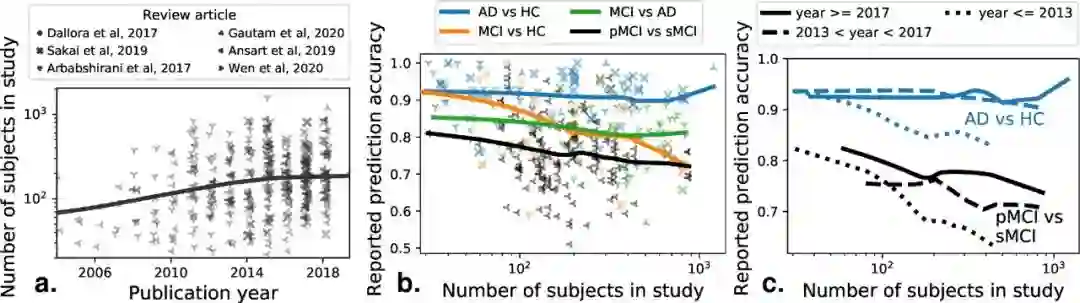
对6篇综述论文进行元分析,涵盖500多篇独立论文。机器学习问题通常被描述为区分各种相关的临床状况,阿尔茨海默病(AD)、健康控制(HC)和轻度认知障碍,这可能是阿尔茨海默病的前驱症状。从临床角度来看,区分进行性轻度认知障碍(pMCI)和稳定性轻度认知障碍(sMCI)是最相关的机器学习任务。
然而,数据量的增加(最大的数据集包含超过1000名受试者)并没有带来更好的诊断准确性,特别是在最相关的临床问题上,区分具有阿尔茨海默病前驱症状的患者的病理与稳定进化(图1b)。相反,样本量较大的研究往往报告较差的预测精度。这令人担忧,因为这些更大的研究更接近现实生活。另一方面,跨时间的研究工作甚至在大型异质性队列中也确实带来了改善(图1c),因为后来发表的研究显示了大样本量的改善(补充信息中的统计分析)。目前的医学成像数据集比那些为计算机视觉带来突破的数据集要小得多。虽然无法对大小进行一对一的比较,因为计算机视觉数据集有许多变化较大的类(与医学成像中变化较小的少数类相比),但要在医学成像中实现更好的泛化,可能需要组装大得多的数据集,同时避免由机会主义数据收集造成的偏见,如下所述。
现有的数据集只能部分反映特定医疗条件的临床情况,导致数据集存在偏差。例如,作为人口研究的一部分收集的数据集可能与转诊到医院治疗的人具有不同的特征(疾病发病率较高)。由于研究者可能不知道相应的数据集偏差是可能导致重要的研究缺点。当用于构建决策模型的数据(训练数据)与应用它的数据(测试数据)的分布不同时,数据集就会出现偏差。为了评估与临床相关的预测,测试数据必须与实际目标人群匹配,而不是与训练数据一样是同一个数据池的随机子集,这是机器学习研究中的常见做法。由于这种不匹配,在基准测试中得分高的算法在现实场景中的表现可能很差。在医学成像中,数据集偏差已在胸部x光片、视网膜成像、大脑成像、组织病理学或皮肤病学中得到证实。通过跨不同来源的数据集训练和测试模型,并观察不同来源的性能下降,可以揭示这些偏差。
数据集的可用性扭曲了研究
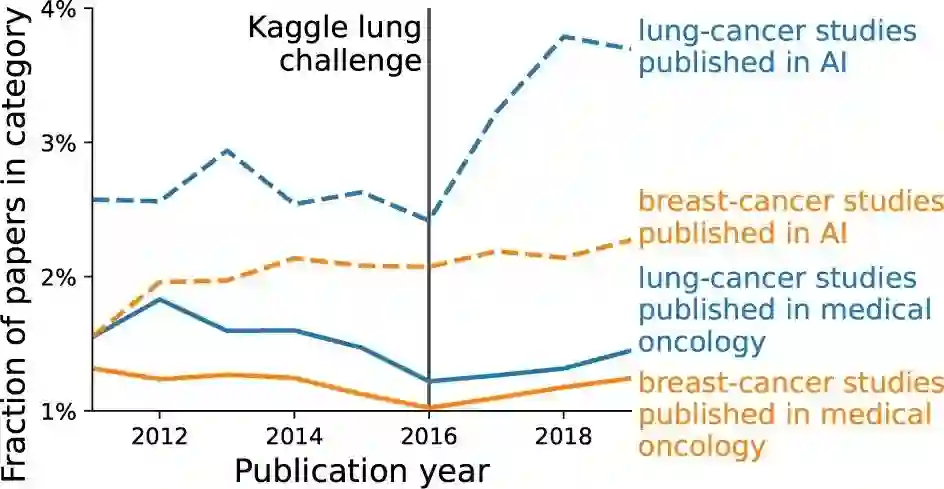
我们展示了肺癌(蓝色)和乳腺癌(红色)的论文占两个领域所有论文的百分比:医学肿瘤学(实线)和人工智能(虚线)。关于论文如何选择的细节在补充信息中给出)。这一比例相对稳定,但人工智能的肺癌患病率在2016年之后有所上升。
数据集的可用性会影响对哪些应用进行更广泛的研究。一个显著的例子可以在肿瘤学的两个应用中看到: 检测肺结节和在放射学图像中检测乳腺肿瘤。
让我们建立对数据局限性的认识
解决这些由数据引起的问题需要对数据集的选择进行判别性思考,在项目级别,即选择哪些数据集进行研究或挑战,在更广泛的级别,即我们作为一个社区使用哪些数据集。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“mlmi” 就可以获取《【NPJ|数字医药】医学影像的机器学习:方法学的失败和对未来的建议》专知下载链接






