一文搞懂转置卷积(反卷积)

极市导读
转置卷积在一些文献中也被称为反卷积,人们如果希望网络学习到上采样方法,就可以采用转置卷积。它不会使用预先定义的插值方法,而具有可以学习的参数。在文末,作者通过观察pytorch框架,解答了读者关于卷积矩阵参数优化的问题。>>>极市七夕粉丝福利活动:炼丹师们,七夕这道算法题,你会解吗?
前言
对于上采用的需求
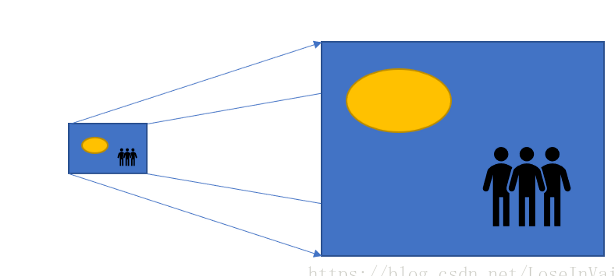
为什么是转置卷积
卷积操作
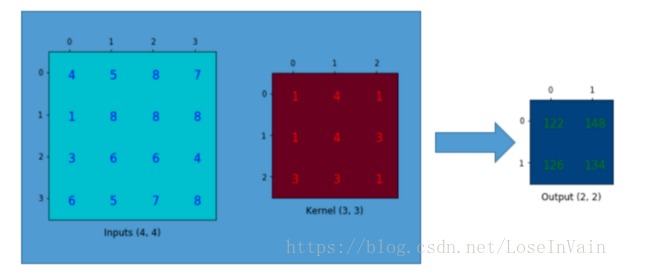
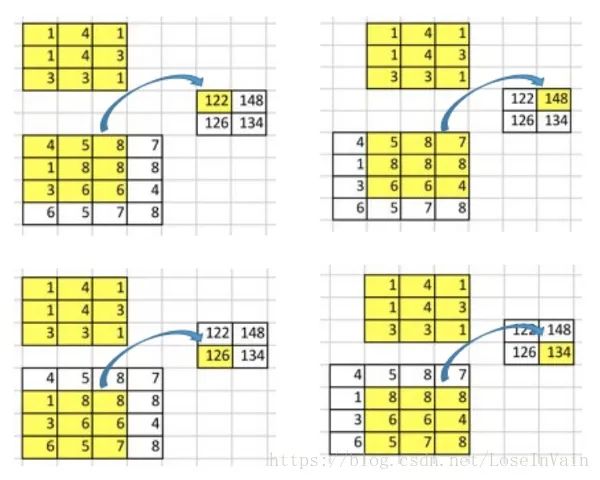
反过来操作吧
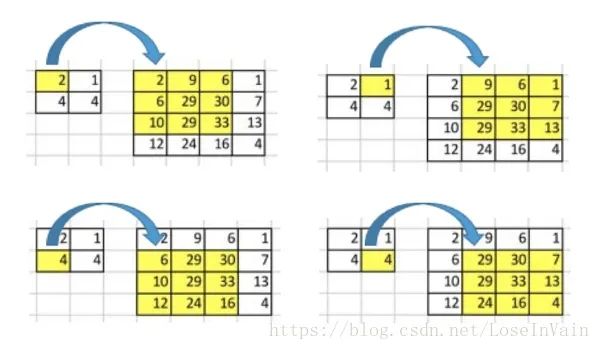

卷积矩阵


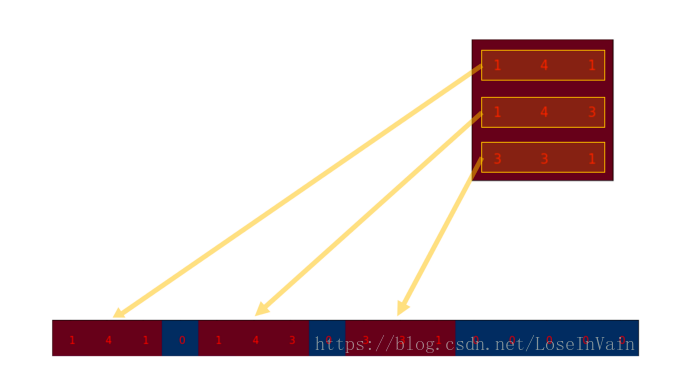



转置卷积矩阵
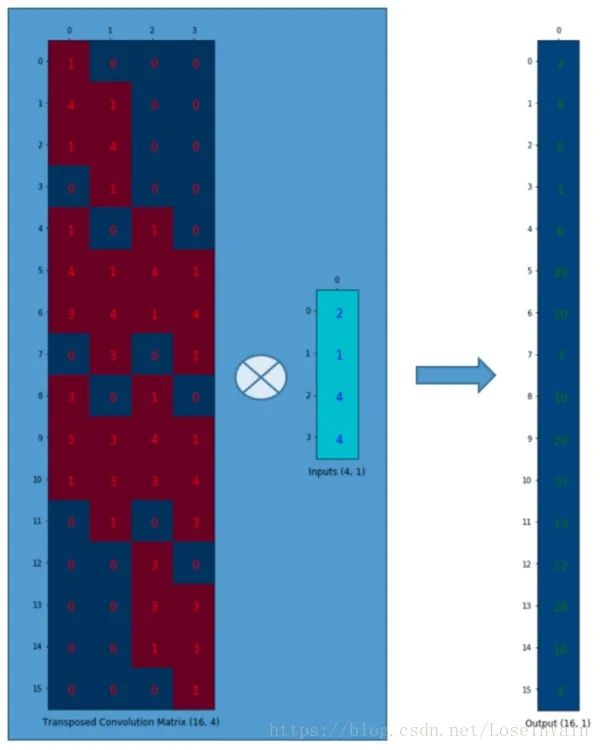

总结
补充内容
博主您好,我觉的转置卷积矩阵的参数随着训练过程不断被优化,但是它是在随机初始化的基础上进行优化,还是在原始卷积矩阵的基础上进行优化? ——CSDN user
pytorch,我们打开
torch.nn.ConvTranspose1d的源码,发现有:
class ConvTranspose1d(_ConvTransposeMixin, _ConvNd):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, output_padding=0, groups=1, bias=True, dilation=1):
kernel_size = _single(kernel_size)
stride = _single(stride)
padding = _single(padding)
dilation = _single(dilation)
output_padding = _single(output_padding)
super(ConvTranspose1d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
True, output_padding, groups, bias)
@weak_script_method
def forward(self, input, output_size=None):
# type: (Tensor, Optional[List[int]]) -> Tensor
output_padding = self._output_padding(input, output_size, self.stride, self.padding, self.kernel_size)
return F.conv_transpose1d(
input, self.weight, self.bias, self.stride, self.padding,
output_padding, self.groups, self.dilation)
weights其实是在超类中定义的,我们转到
_ConvNd,代码如:
class _ConvNd(Module):
__constants__ = ['stride', 'padding', 'dilation', 'groups', 'bias']
def __init__(self, in_channels, out_channels, kernel_size, stride,
padding, dilation, transposed, output_padding, groups, bias):
super(_ConvNd, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
if out_channels % groups != 0:
raise ValueError('out_channels must be divisible by groups')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.transposed = transposed
self.output_padding = output_padding
self.groups = groups
if transposed:
self.weight = Parameter(torch.Tensor(
in_channels, out_channels // groups, *kernel_size))
else:
self.weight = Parameter(torch.Tensor(
out_channels, in_channels // groups, *kernel_size))
if bias:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self.reset_parameters()
weights或者是
bias的初始化就是一般地初始化一个符合一定尺寸要求的
Tensor即可了,我们也可以发现其在
forward过程中并没有所真的去根据输入进行权值的所谓“转置”之类的操作。因此我认为只要一般地进行随机初始化即可了。
torch.nn.Conv2d的类的话,其实也可以发现,其参数都是通过
_ConvNd去进行初始化的,因此
Conv2d和
ConvTranspose2D的参数初始化除了尺寸的区别,其他应该类似。
推荐阅读




登录查看更多
相关内容

专知会员服务
63+阅读 · 2020年7月12日
Arxiv
7+阅读 · 2018年10月31日

相关VIP内容
专知会员服务
63+阅读 · 2020年7月12日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年10月31日