人工“碳”索意犹尽,智能“硅”来未可知(深度学习入门系列之二)
在前面的小节中,我们仅仅泛泛而谈了机器学习、深度学习等概念,在这一小节,我们将给出它的更加准确的形式化描述。
我们经常听到人工智能如何如何?深度学习怎样怎样?那么它们之间有什么关系呢?在本小节,我们首先从宏观上谈谈人工智能的“江湖定位”和深度学习的归属。然后再在微观上聊聊机器学习的数学本质是什么?以及我们为什么要用神经网络?
2.1 人工智能的“江湖定位”
宏观上来看, 人类科学和技术的发展,大致都遵循着这样的规律:现象观察、理论提取和人工模拟(或重现)。 人类“观察大脑”的历史由来已久,但由于对大脑缺乏“深入认识”,常常“绞尽脑汁”,也难以“重现大脑”。
直到上个世纪40年代以后,脑科学、神经科学、心理学及计算机科学等众多学科,取得了一系列重要进展,使得人们对大脑的认识相对“深入”,从而为科研人员从“观察大脑”到“重现大脑”搭起了桥梁,哪怕这个桥梁到现在还仅仅是个并不坚固的浮桥。
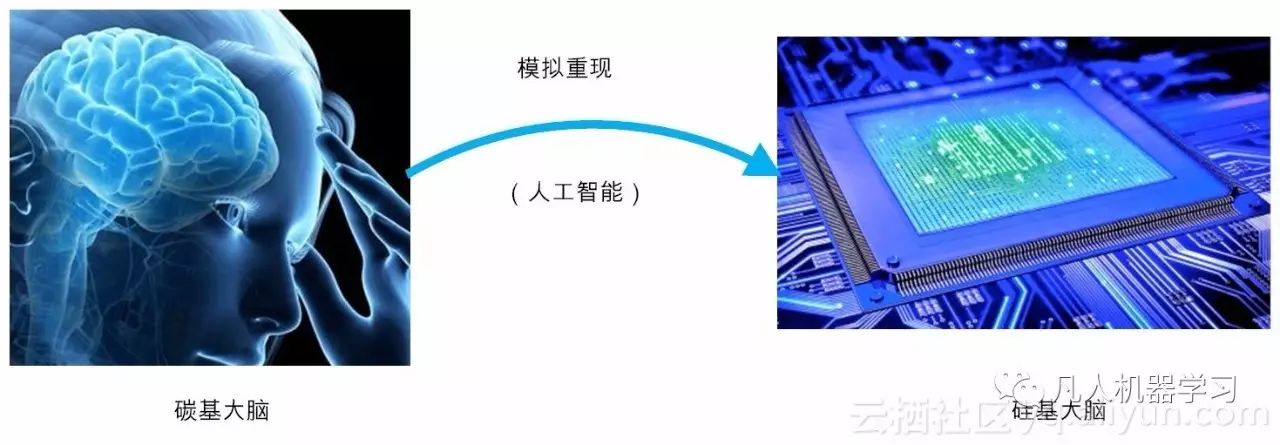
图2-1 人工智能的本质
而所谓的“重现大脑”,在某种程度上,就是目前的研究热点——人工智能。简单来讲,人工智能就是为机器赋予人类的智能。由于目前的机器核心部件是由晶体硅构成,所以可称之为“硅基大脑”。而人类的大脑主要由碳水化合物构成,因此可称之为“碳基大脑”。
那么, 现在的人工智能,通俗来讲,大致就是用“硅基大脑”模拟或重现“碳基大脑”。 那么,在未来会不会出现“碳硅合一”的大脑或者全面超越人脑的“硅基大脑”呢?
有人就认为,在很大程度上,这个答案可能是“会的”!比如说,未来预言大师雷·库兹韦尔(Ray Kurzweil)就预测,到2045年,人类的“奇点”时刻就会临近[1] 。这里的“奇点”是指,人类与其他物种(物体)的相互融合,更确切来说,是硅基智能与碳基智能兼容的那个奇妙时刻。
2.2 深度学习的归属
在当下,虽然深度学习领跑人工智能。但事实上,人工智能研究领域很广,包括机器学习、计算机视觉、专家系统、规划与推理、语音识别、自然语音处理和机器人等。而机器学习又包括深度学习、监督学习、无监督学习等。简单来讲,机器学习是实现人工智能的一种方法,而深度学习仅仅是实现机器学习的一种技术而已(如图2-2所示)。
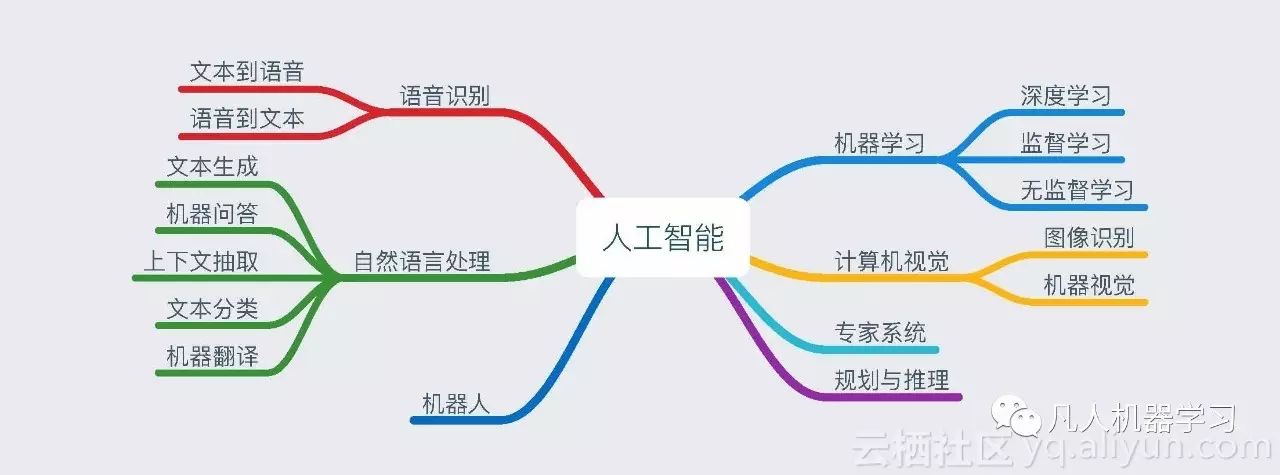
图2-2 深度学习的“江湖地位”
需要说明的是,对人工智能做任何形式的划分,都可能是有缺陷的。在图2中,人工智能的各类技术分支,彼此泾渭分明,但实际上,它们之间却可能阡陌纵横,比如说深度学习是无监督的。语音识别可以用深度学习的方法来完成。再比如说,图像识别、机器视觉更是当前深度学习的拿手好戏。
一言蔽之, 人工智能的分支并不是一个有序的树,而是一个彼此缠绕的灌木丛。 有时候,一个分藤蔓比另一个分藤蔓生长得快,并且处于显要地位,那么它就是当时的研究热点。深度学习的前生——神经网络的发展,就是这样的几起几落。当下,深度学习如日中天,但会不会也有“虎落平阳被犬欺”的一天呢?从事物的发展规律来看,这一天肯定会到来!
在图3-2中,既然我们把深度学习和传统的监督学习和无监督学习单列出来,自然是有一定道理的。这就是因为,深度学习是高度数据依赖型的算法,它的性能通常随着数据量的增加而不断增强,也就是说它的可扩展性(Scalability)显著优于传统的机器学习算法(如图2-3所示)。
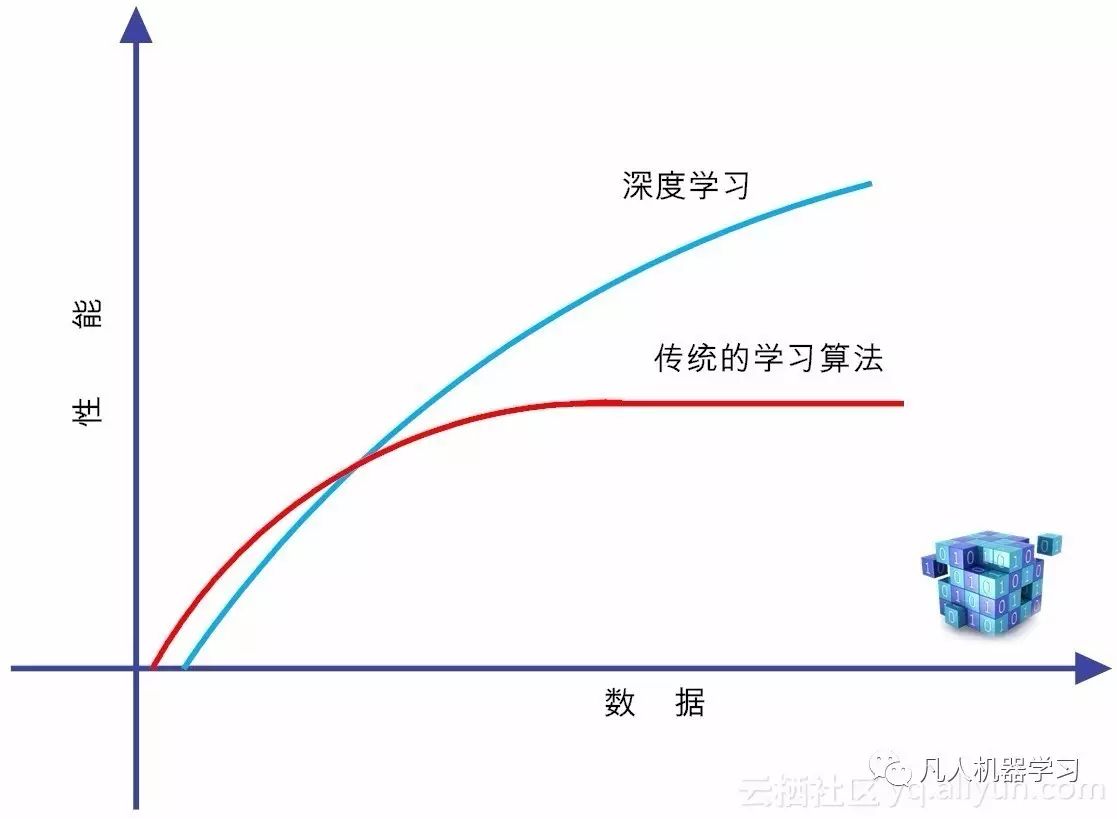
图2-3 深度学习和传统学习算法的区别
但如果训练数据比较少,深度学习的性能并不见得就比传统机器学习好。其潜在的原因在于,作为复杂系统代表的深度学习算法,只有数据量足够多,才能通过训练,在深度神经网络中,“恰如其分”地将把蕴含于数据之中的复杂模式表征出来。
不论机器学习,还是它的特例深度学习,在大致上,都存在两个层面的分析(如图2-4所示):
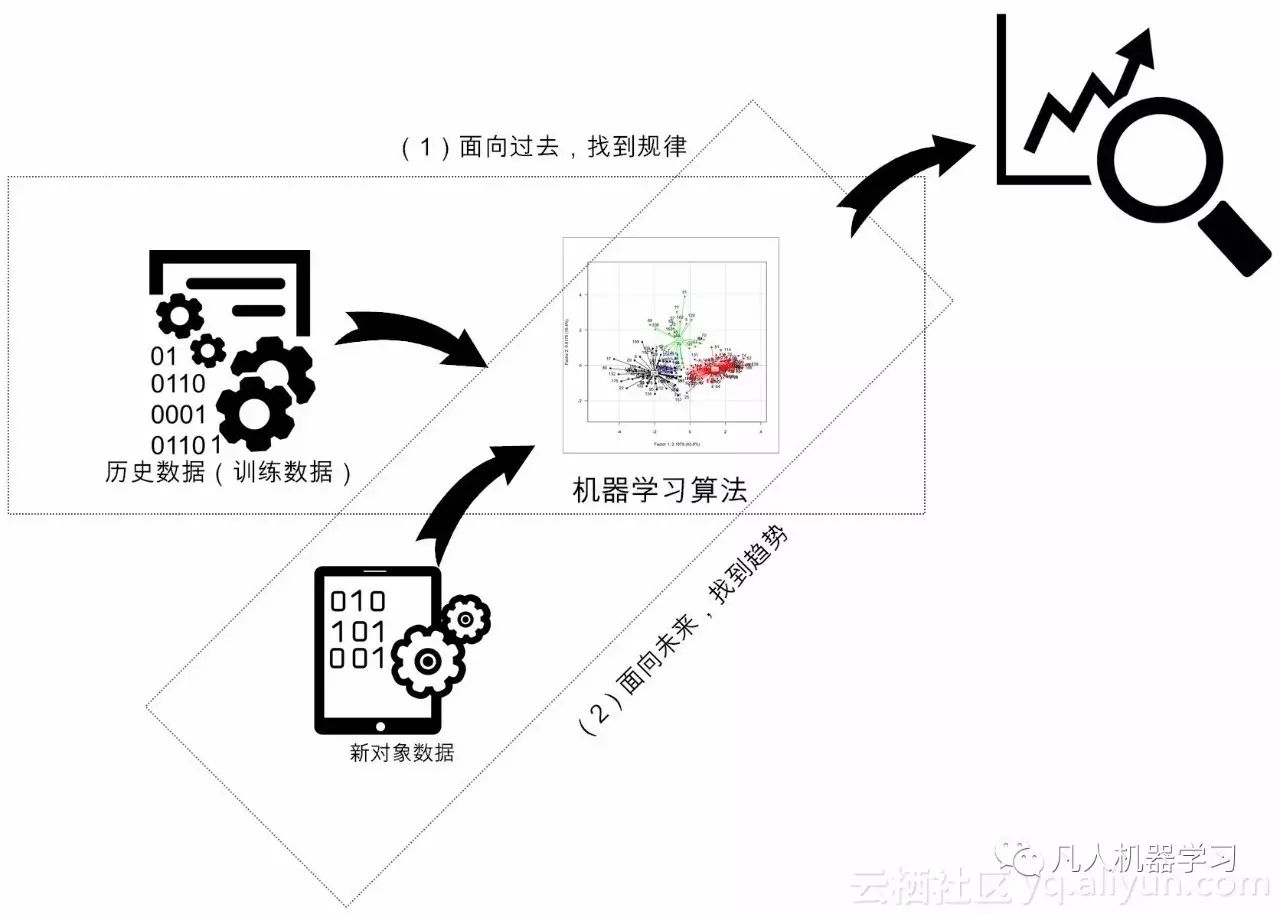
图2-4 机器学习的两层作用
(1)面向过去(对收集到的历史数据,用作训练),发现潜藏在数据之下的模式,我们称之为描述性分析(Descriptive Analysis);
(2)面向未来,基于已经构建的模型,对于新输入数据对象实施预测,我们称之为预测性分析(Predictive Analysis)。
前者主要使用了“归纳”,而后者更侧重于“演绎”。对历史对象的归纳,可以让人们获得新洞察、新知识,而对新对象实施演绎和预测,可以使机器更加智能,或者说让机器的某些性能得以提高。二者相辅相成,均不可或缺。
在前面的部分,我们给予机器学习的概念性描述,下面我们给出机器学习的形式化定义。
2.3.机器学习的形式化定义
在《未来简史》一书中[2],尤瓦尔•赫拉利说,根据数据主义的观点,人工智能实际上就是找到一种高效的“电子算法”,用以代替或在某项指标上超越人类的“生物算法”。那么,任何一个“电子算法”都要实现一定的功能(Function),才有意义。
在计算机术语中,中文将“Function”翻译成“函数”,这个多少有点扯淡,因为它的翻译并没有达到“信达雅”的标准,除了给我们留下一个抽象的概念之外,什么也没有剩下来。但这一称呼已被广为接受,我们也只能“约定俗成”地把“功能”叫做“函数”了。
根据台湾大学李宏毅博士的说法,所谓机器学习,在形式上,可近似等同于在数据对象中,通过统计或推理的方法,寻找一个适用特定输入和预期输出功能函数(如图2-5所示)。习惯上,我们把输入变量写作大写的X ,而把输出变量写作大写的Y 。那么所谓的机器学习,在形式上,就是完成如下变换:Y= f(X) 。

图2-5 机器学习近似等同于找一个好用的函数
在这样的函数中,针对语音识别功能,如果输入一个音频信号X,那么这个函数Y就能输出诸如“你好”,“How are you?”等这类识别信息。
针对图片识别功能,如果输入的是一个图片X,在这个函数Y的加工下,就能输出(或称识别出)一个猫或狗的判定。
针对下棋博弈功能,如果输入的是一个围棋的棋谱局势(比如AlphaGO)X,那么Y能输出这个围棋的下一步“最佳”走法。
类似地,对于具备智能交互功能的系统(比如微软的小冰),当我们给这个函数X输入诸如“How are you?”,那么Y就能输出诸如“I am fine,thank you?”等智能的回应。
每个具体的输入,都是一个实例(instance),它通常由特征空间(feature vector)构成。在这里,所有特征向量存在的空间称为特征空间(feature space),特征空间的每一个维度,对应于实例的一个特征。
但问题来了,这样“好用的”函数并不那么好找。当输入一个猫的图像后,这个函数并不一定就能输出它就是一只猫,可能它会错误地输出为一条狗或一条蛇。
这样一来,我们就需要构建一个评估体系,来辨别函数的好坏(Goodness)。当然,这中间自然需要训练数据(training data)来“培养”函数的好品质(如图6所示)。在第一小节中,我们提到,学习的核心就是性能改善,在图6中,通过训练数据,我们把f1改善为f2的样子,性能(判定的准确度)得以改善了,这就是学习!很自然,这个学习过程如果是在机器上完成的,那就是“机器学习”了。
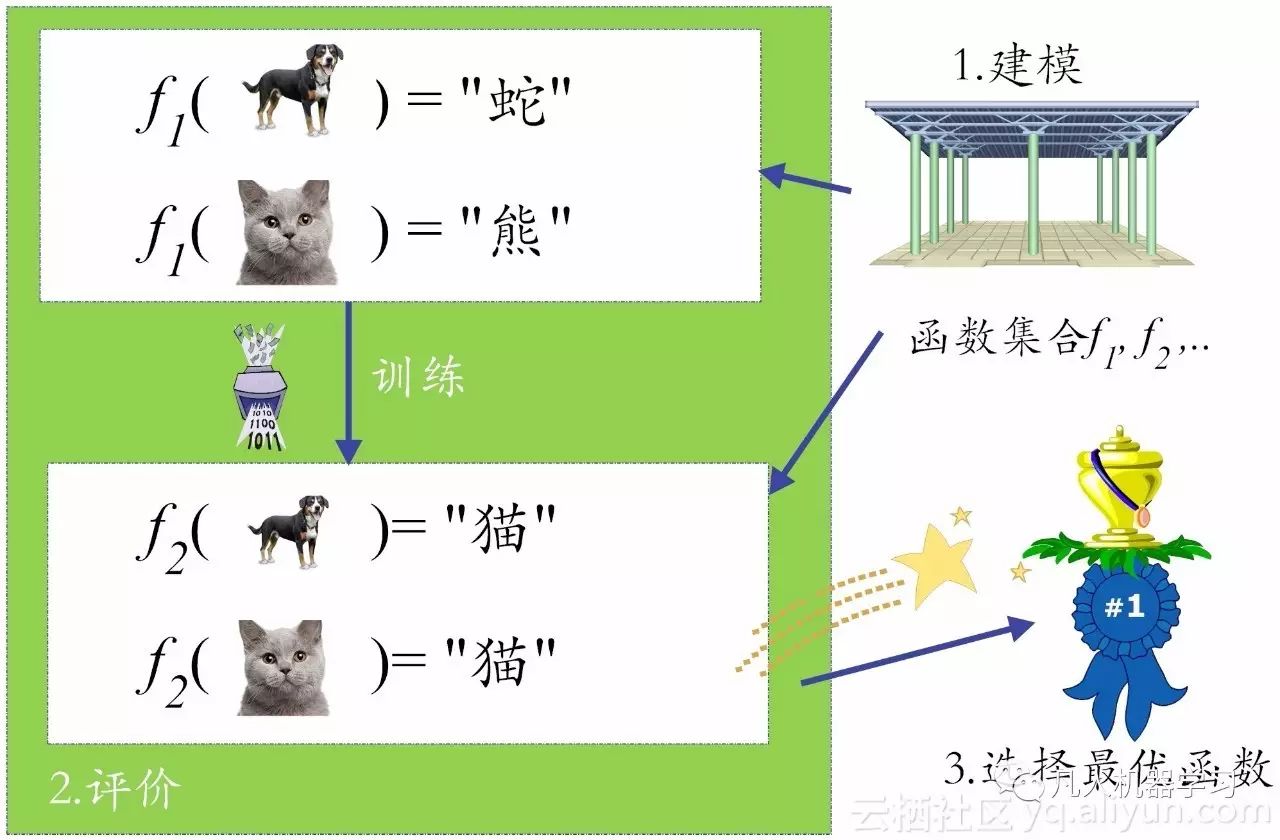
图2-6 机器学习的三步走
具体说来,机器学习要想做得好,需要走好三大步:
(1) 如何找一系列函数来实现预期的功能,这是建模问题。
(2) 如何找出一组合理的评价标准,来评估函数的好坏,这是评价问题。
(3) 如何快速找到性能最佳的函数,这是优化问题(比如说,机器学习中梯度下降法干的就是这个活)。
2.4 为什么要用神经网络?
我们知道,深度学习的概念源于人工神经网络的研究。含多隐层的多层感知机就是一种深度学习结构。所以说到深度学习,就不能不提神经网络。
那么什么是神经网络呢?有关神经网络的定义有很多。这里我们给出芬兰计算机科学家Teuvo Kohonen的定义(这老爷子以提出“自组织神经网络”而名扬人工智能领域):“神经网络,是一种由具有自适应性的简单单元构成的广泛并行互联的网络,它的组织结构能够模拟生物神经系统对真实世界所作出的交互反应。”
在机器学习中,我们常常提到“神经网络”,实际上是指“神经网络学习”。学习是大事,不可忘记!
那为什么我们要用神经网络学习呢?这个原因说起来,有点“情非得已”。
我们知道,在人工智能领域,有两大主流门派。第一个门派是符号主义。符号主义的理念是,知识是信息的一种表达形式,人工智能的核心任务,就是处理好知识表示、知识推理和知识运用。这个门派核心方法论是,自顶向下设计规则,然后通过各种推理,逐步解决问题。很多人工智能的先驱(比如CMU的赫伯特•西蒙)和逻辑学家,很喜欢这种方法。但这个门派的发展,目前看来并不太好。未来会不会“峰回路转”,现在还不好说。
还有一个门派,就是试图编写一个通用模型,然后通过数据训练,不断改善模型中的参数,直到输出的结果符合预期,这个门派就是连接主义。连接主义认为,人的思维就是某些神经元的组合。因此,可以在网络层次上模拟人的认知功能,用人脑的并行处理模式,来表征认知过程。这种受神经科学的启发的网络,被称之人工神经网络(Artificial Neural Network,简称ANN)。目前,这个网络的升级版,就是目前非常流行的深度学习。
前面我们提到,机器学习在本质就是寻找一个好用的函数。而人工神经网络最“牛逼”的地方在于,它可以在理论上证明:只需一个包含足够多神经元的隐藏层,多层前馈网络能以任意精度逼近任意复杂度的连续函数[4]。这个定理也被称之为通用近似定理(Universal Approximation Theorem)。这里的“Universal”,也有人将其翻译成“万能的”,由此可见,这个定理的能量有多大。换句话说,神经网络可在理论上解决任何问题,这就是目前深度学习能够“牛逼哄哄”最底层的逻辑(当然,大数据+大计算也功不可没,后面还会继续讨论)。
2.5 小结
在本小节中,我们首先谈了谈人工智能的“江湖定位”,然后指出深度学习仅仅是人工智能研究的很小的一个分支,接着我们给出了机器学习的形式化定义。最后我们回答了为什么人工神经网络能“风起云涌”,简单来说,在理论上可以证明,它能以任意精度逼近任意形式的连续函数,而机器学习的本质,不就是要找到一个好用的函数嘛?
在下小节,我们将深度解读什么是激活函数,什么是卷积?(很多教科书真是越讲越糊涂,希望你看到下一小节,能有所收获)
2.6 请你思考
学完前面的知识,请你思考如下问题(掌握思辨能力,好像比知识本身更重要):
(1)你认可库兹韦尔“到2045年人类的奇点时刻就会临近”的观点吗?为什么?库兹韦尔的预测,属于科学的范畴吗?(提示:可以从波普尔的科学评判的标准——是否具备可证伪性分来析。)
(2)深度学习的性能,高度依赖性于训练数据量的大小?这个特性是好还是坏?(提示:在《圣经》中有七宗原罪,其中一宗罪就是暴食,而原罪就是“deadly sin”,即死罪。目前,深度学习贪吃数据和能量,能得以改善吗?)
写下你的心得体会,祝你每天都有进步!
【参考文献】
1 雷·库兹韦尔, 李庆诚等译. 奇点临近.机械工业出版社.2012.12
2尤瓦尔·赫拉利,未来简史. 出版社:中信出版社.2017.1
[3] 李航.统计学习方法.清华大学出版社.2012.3
[4] Hornik K, Stinchcombe M, White H. Multilayer feedforward networks are universal approximators[J]. Neural networks, 1989, 2(5): 359-366.
文章作者:张玉宏(著有《品味大数据》),审校:我是主题曲哥哥。
本文转载已经得到张玉宏老师允许,原文链接为云栖社区原文地址。





