【普林斯顿陈丹琦团队】使预训练语言模型成为更好的少样本学习器

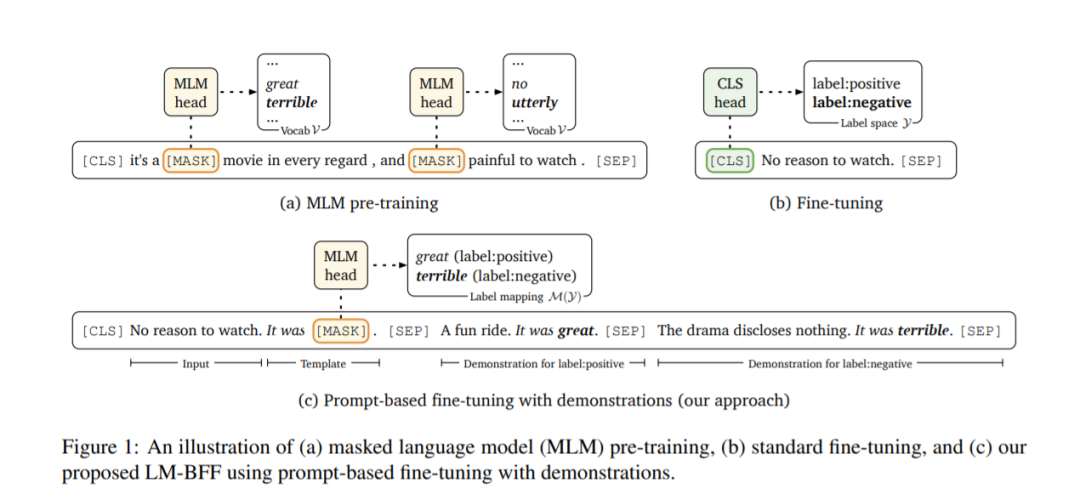
最近的GPT-3模型仅利用自然语言提示和一些任务演示作为输入上下文,就实现了显著的少样本学习性能。受该工作的发现启发,作者在一个更实际的场景中研究了少次学习,我们使用更小的语言模型,以便在微调时更具有计算效率。我们提出了LM-BFF——更好的面向语言模型的少样本微调,这是一套简单且互补的技术,用于在少量带注释的示例上微调语言模型。我们的方法包括:(1)基于提示的微调,以及一个自动化提示生成的新管道;(2)动态和有选择地将演示整合到每个上下文中的精炼策略。最后,我们提出了一个系统的评价,以分析在一系列的自然语言处理任务的少数射击性能,包括分类和回归。我们的实验表明,在这种低资源设置下,我们的方法结合起来显著优于标准微调程序,实现了高达30%的绝对改进,在所有任务中平均达到11%。我们的方法对任务资源和领域专家知识做了最小的假设,因此构成了一个强大的任务不可知的方法,用于少样本学习。
https://www.zhuanzhi.ai/paper/8e74c666bc3760903ca59fe301bf7493
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LMBF” 可以获取《【普林斯顿陈丹琦团队】使预训练语言模型成为更好的少样本学习器》专知下载链接索引



登录查看更多
相关内容
专知会员服务
33+阅读 · 2020年2月29日



相关VIP内容
专知会员服务
33+阅读 · 2020年2月29日
相关资讯
相关论文