自动「脑补」3D环境!DeepMind最新Science论文提出生成查询网络GQN
选自DeepMind
作者:S. M. Ali Eslami、Danilo Jimenez Rezende
机器之心编译
给定立方体积木的几个侧面剪影,你能否「脑补」出它的整个 3D 形状?这看起来像是行测中的图形题,考验人们从 2D 画面到 3D 空间的转换能力。在 DeepMind 最新发表在顶级期刊 Science 的论文《Neural scene representation and rendering》中,计算机通过「生成查询网络 GQN」也拥有了这种空间推理能力。
DeepMind 创始人(同时也是该论文的作者之一)戴密斯·哈萨比斯表示:「我们一直着迷于大脑是如何在意识中构建空间图像的,我们的最新《Science》论文引入了 GQN:它可以从一些 2D 快照中重建场景的 3D 表示,并可以通过任何新的视角不断增强这一表示。」

理解视觉场景时,我们依赖的不仅仅是眼睛:我们的大脑利用已有知识来推理,并做出远远超过视线所及的推论。例如,当第一次进入一个房间时,你会立即认出里面的物品以及它们的位置。如果你看到一张桌子的三条腿,你会推断可能还有第四条腿,形状和颜色相同,只不过在视线之外。即使你看不到房间里的所有东西,你也可以勾画出它的布局,或者从另一个角度想象它的样子。
这些视觉和认知任务对人类来说似乎毫不费力,但对我们的人工智能系统来说却是一个重大挑战。如今,最先进的视觉识别系统需要使用由人类标注的大量图像数据来进行训练的。获取这些数据是一个成本高昂且耗时的过程,需要人工对数据集中每个场景中每个对象的每个方面进行标记。而实验结果通常只能捕获到整体场景内容的一小部分,这限制了根据该数据训练的人工视觉系统。随着我们开发出现实世界中更复杂的机器,我们希望它们可以充分理解周围的环境:最近的地面在哪里?沙发是用什么材料做的?哪一个光源产生了所有的阴影?电灯开关可能在哪里?
在这项发表在 Science 的研究中,DeepMind 引入了生成查询网络(Generative Query Network/GQN)的框架,其中机器通过到处走动并仅在由它们自己获取的数据中训练来感知周围环境。该行为和婴儿、动物很相似,GQN 通过尝试观察周围的世界并进行理解来学习。以此,GQN 得以学习合理的场景以及它们的几何性质,而不需要任何场景内容的人类标记。
GQN 模型由两部分构成:一个表征网络以及一个生成网络。表征网络将智能体的观察作为输入,并生成一个描述潜在场景的表征(向量)。然后生成网络从之前未观察过的视角来预测(想象)该场景。
表征网络不知道生成网络将被要求预测哪些视角,因此必须找到尽可能准确描述场景真实布局的有效方法。表征网络能通过简明的分布式表示捕获最重要的元素,例如目标位置、颜色和房间布局。在训练过程中,生成器学习环境中的典型目标、特征、关系和规律。这组共享的「概念」使表征网络能够以高度压缩、抽象的方式来描述场景,让生成网络在必要时填写细节。例如,表征网络将把「蓝色立方体」简洁地表示为一个小的数值集合,生成网络将知道从特定的角度来看,这是如何以像素的形式表现出来的。
我们在模拟 3D 世界里一组由程序生成的环境中对 GQN 进行了受控实验,这些环境包含随机位置、颜色、形状和纹理的多个目标,还有随机光源和严重遮挡。在这些环境下训练后,我们使用 GQN 的表征网络来生成新的、以前未见过的视角下的场景表征。我们在实验中表明,GQN 具有几个重要的特性:
GQN 的生成网络可以从新的视角非常精确地「想象」以前未见过视角下的场景。当给定场景表征和新视角时,它会生成清晰的图像,而不需要预先规定角度、遮挡或照明的规律。因此,生成网络是从数据中学习的近似渲染器(renderer):
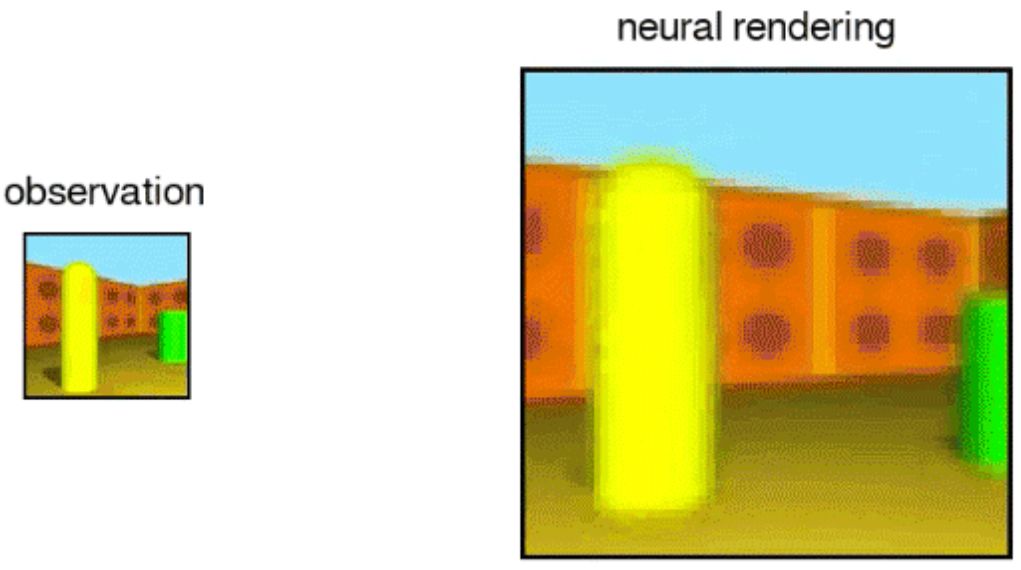
GQN 的表征网络可以学习计数、定位和分类目标,并且不需要任何目标级的标注。即使它的表征可能是很小的,GQN 在查询视角的预测也能达到很高的准确率,几乎和真实场景无法分辨。这意味着该表征网络可以准确地感知,例如识别积木块的精确配置:
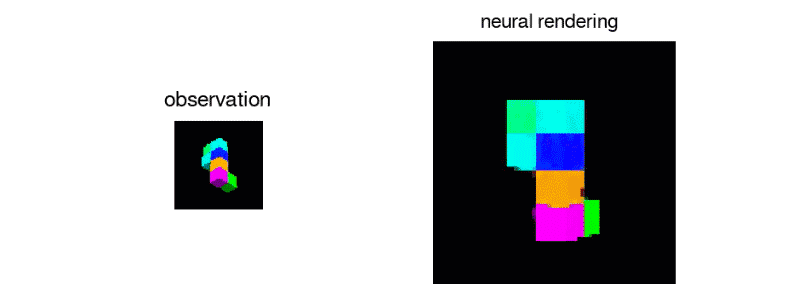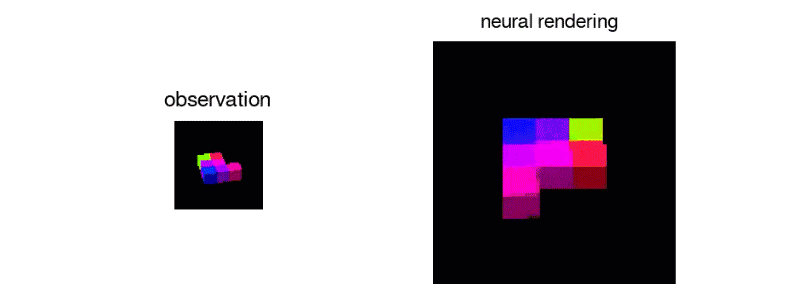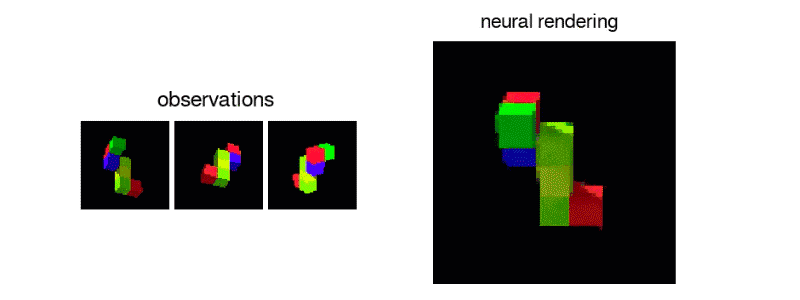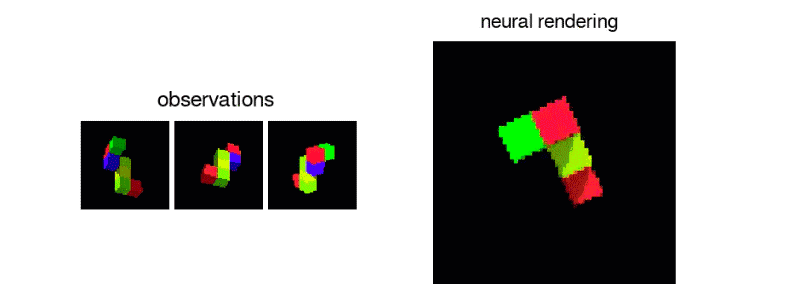
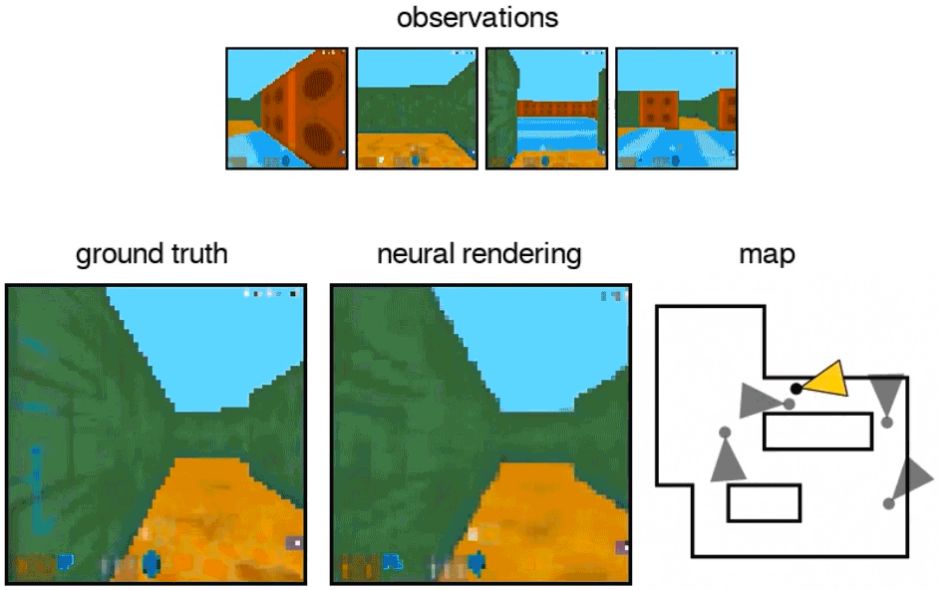
GQN 可以表征、测量和减少不确定性。它可以计算关于场景可信度的不确定度,即使其内容不是完全可见的,并且它可以组合一个场景的多个部分视角来构建一致的整体。下图中展示了它的第一人称视角和自顶向下视角的预测。该模型通过预测的易变性来表达不确定度,并随着它在迷宫中移动而逐渐减小(灰色椎体表示观察位置,黄色椎体表示查询位置)。
GQN 的表征允许实现鲁棒性的、数据效率高的强化学习。当给定 GQN 的紧凑型表征时,如下所示,当前最优的深度强化学习智能体相比于 model-free 的基线智能体在学习完成任务上有更高的数据效率。对于这些智能体,通用网络中编码的信息能被视为环境的先验知识:
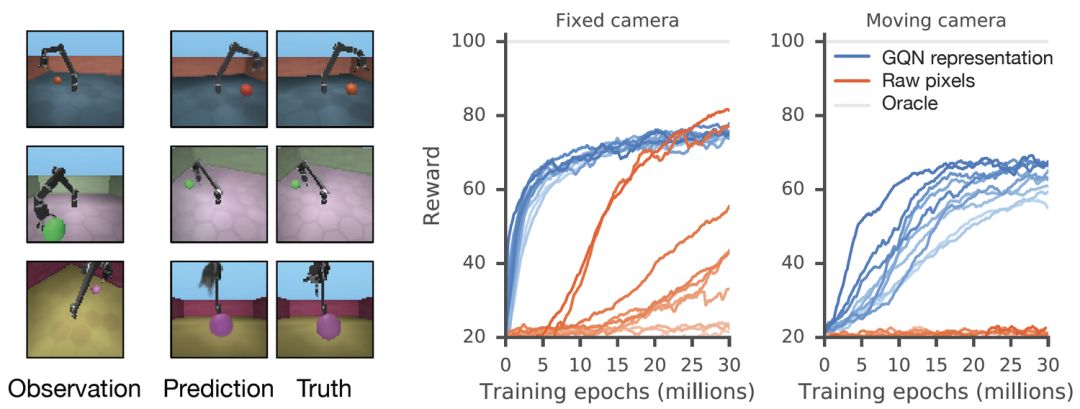
相比于使用原像素的标准方法,使用 GQN 迭代次数少了 4 倍,但收敛表现一致且有更加数据高效的策略学习。
GQN 建立在最近大量多视角的几何研究、生成式建模、无监督学习和预测学习的基础上,它展示了一种学习物理场景的紧凑、直观表征的全新方式。重要的是,提出的这种方法不需要特定域的工程以及消耗时间对场景内容打标签,使得同一模型能够应用到大量不同的环境。它也学习了一种强大的神经渲染器,能够产生准确的、全新视角的场景图像。
DeepMind 认为,相比于更多传统的计算机视觉技术,他们的方法还有许多缺陷,目前也只在合成场景下训练工作的。然而,随着新数据资源的产生、硬件能力的发展,DeepMind 希望探索 GQN 框架应用到更高分辨率真实场景图像的研究。未来,探索 GQN 应用到更广泛的场景理解的工作也非常重要,例如通过跨空间和时间的查询来学习物理和移动等常识概念,还有应用到虚拟和增强现实等。
虽然在我们的研究能够实践部署之前,还有很多研究需要完成,但我们相信该研究是迈向自动场景理解相当大的一步。
论文:Neural scene representation and rendering

论文链接:http://science.sciencemag.org/content/360/6394/1204
摘要:场景表征,即将视觉传感数据转换为简明描述的过程,是智能行为的基本要求。最近的研究工作表明在为神经网络提供大型标注数据集的情况下,它在场景表征中有优秀的性能,但是移除神经网络对人力标注的依赖仍然是一个重要的开放性问题。为此,我们引进了生成查询网络(Generative Query Network /GQN),机器在这个框架中将学习如何仅使用自己的传感器表征场景。GQN 将从不同视角拍摄的场景图作为输入,并用来构建内部表征,然后模型会根据这样的表征预测以前没见过视角下的场景外观。GQN 展示了在没有人类标注或领域知识下的表征学习,为机器的自动学习及其对周围世界的理解铺平了道路。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

