ECCV 2022 | 面向高光和透明物体感知与抓取的域随机化增强的深度仿真与修复

关键词:深度仿真 深度修复 高光透明物体


导 读
本文是计算机视觉顶级会议 ECCV 2022入选论文 Domain Randomization-Enhanced Depth Simulation and Restoration for Perceiving and Grasping Specular and Transparent Objects 的解读。
该论文由北京大学王鹤课题组与阿里巴巴 XR Lab 和北京大学董豪课题组合作完成。文章研究了主动立体视觉深度相机在高光和透明材质物体上的深度修复问题并展示了深度修复对下游高光和透明物体抓取及位姿估计的重大帮助。
文章提出了基于域随机化增强的深度相机仿真方法,构造了囊括高光、透明、漫反射材质的 RGB-D 仿真数据集并采集了真实数据集。文章进一步提出了一种基于 Swin Transformer 进行 RGB-D 融合的实时深度修复算法(30 FPS),在域随机的仿真数据上训练的深度修复算法可以直接泛化到真实环境。实验证明我们的方法超过了已有的深度修复算法,可直接帮助已有三维视觉算法应用到高光和透明物体的抓取与位姿估计任务中。

论文地址:
https://arxiv.org/abs/2208.03792
项目主页:
https://pku-epic.github.io/DREDS/
代码与数据集地址:
https://github.com/PKU-EPIC/DREDS
01
引 言
在当前火热的 VR/AR 和机器人领域,深度相机是一种广泛应用的设备,能够便捷地获取深度和点云数据。但是现有的深度相机在深度采集过程不可避免会引入传感器噪声(sensor noise),特别是对高光和透明材质物体(specular and transparent objects),如图1所示,捕获的深度出现了严重错误甚至缺失。而实际上金属制品、玻璃器皿等高光或透明物体在生活中非常常见,这就给基于深度或点云的视觉感知与交互算法带来了严峻的挑战,也迅速引起了研究人员的关注。
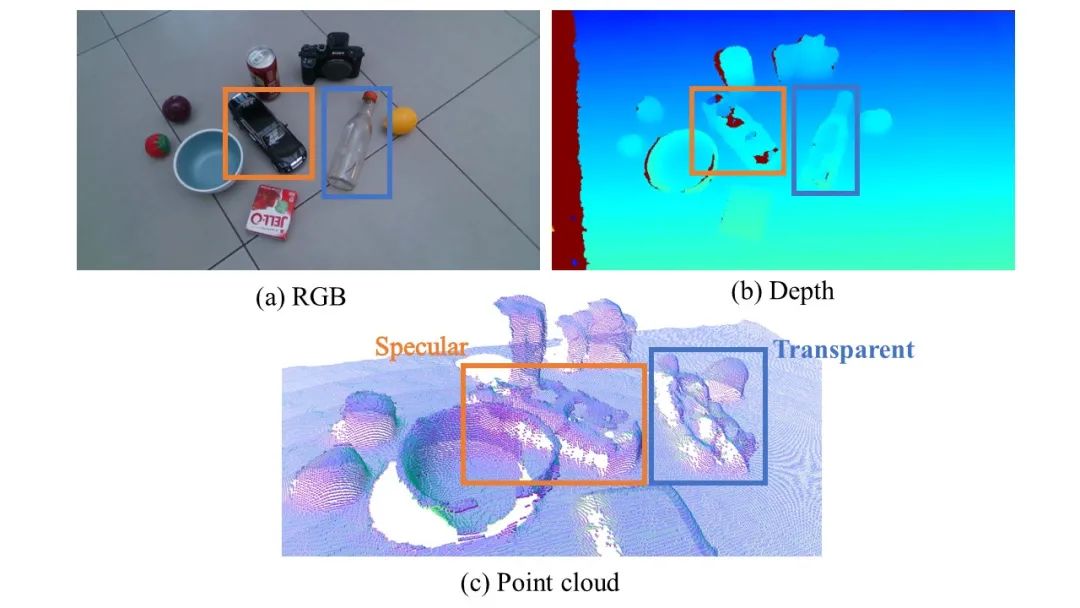
图1. 高光和透明物体的深度错误与缺失示例。
为应对这一挑战,我们设计了一个基于深度相机仿真的深度修复系统,如图2所示。对于深度修复,我们提出了一个有效的基于 Swin Transformer[1] 的 RGB-D 融合网络 SwinDRNet。然而,在数据方面,构建大规模成对传感器深度(sensor depth)和完美深度(perfect depth)的真实数据集通常费时费力,此前 ClearGrasp[2]、LIDF[3] 等透明物体深度补全工作都只使用合成的完美深度作训练。我们通过实验认识到,模型如果在训练时没见过具有现实传感器噪声的深度,在测试阶段就难以在真实传感器深度上达到更优的性能。此外,之前的工作都只考虑形状差异小的少数透明或高光物体,在没见过的物体和类别上泛化能力较差。
对此,我们提出了域随机化增强的深度仿真(Domain Randomization-Enhanced Depth Simulation)方法,通过模拟主动立体视觉深度相机(active stereo vision depth camera)成像原理,生成具有真实传感器噪声的深度图像,并进一步对场景中的物体类别、物体材质、物体布局、背景、光照、相机位姿等做域随机化(domain randomization)以增强泛化性能,合成了规模达130K 的 RGB-D 仿真数据集 DREDS。我们还构造了一个 RGB-D 真实数据集 STD,囊括了50个高光、透明或漫反射材质物体。
我们通过大量实验,展示了 SwinDRNet 仅在 DREDS 仿真数据训练,就能在 STD 真实数据的深度修复上泛化到高光、透明、漫反射等多种材质的新物体实例和新类别物体,超越各基线算法;能够泛化到没见过的 ClearGrasp[2] 数据集,超越之前训练在该数据集的最优方法 LIDF[3];并且支持实时深度修复(30 FPS)。类别级物体位姿估计与机械臂抓取实验进一步验证了我们的深度修复能显著提升下游任务性能,并且是可泛化的。
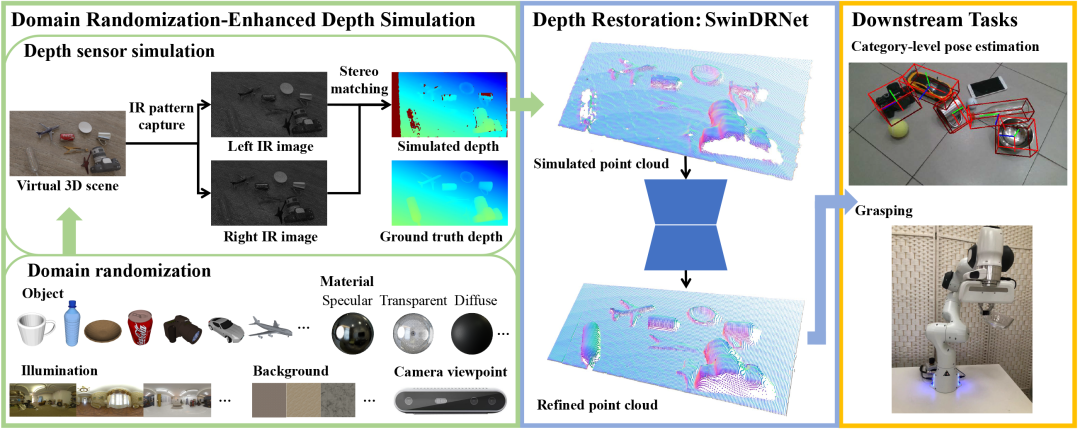
图2. 本工作的系统流程图。
02
域随机化增强的深度仿真
图3. 本工作的仿真数据生成流程介绍。
我们基于 Blender 搭建了仿真数据生成流程,如图3所示,采用了域随机化技术构建虚拟场景:使类别、大小、数量随机的物体自由落体到地面,随机产生物体布局和位姿;向物体随机分配高光、透明或漫反射材质,并变换 BSDF 材质模型参数;为背景平面随机分配砖、木、水泥等地面材质;使用随机的室内或室外环境贴图提供场景光照;随机变化相机位姿和视角,等等。通过随机扰动数据生成流程的参数,合成足够多样的训练数据,使模型在测试时将真实数据视为训练数据的一种变化,实现虚拟到真实的域迁移。
在深度仿真方面,我们对主动立体视觉深度相机进行了系统辨识,构建了深度相机仿真器:首先红外投射器(IR projector)将红外散斑(IR pattern)投射到虚拟场景;之后左右红外立体相机(IR stereo camera)利用光线追踪技术渲染双目 IR 图像,这里通过可见光渲染来模拟红外图像;最后通过立体匹配(stereo matching)算法计算左右 IR 图的视差,即可得到仿真的传感器深度。该仿真器能够正确建模高光、透明、漫反射材质的传感器噪声。
03
RGB-D仿真数据集和真实数据集
图4. 本工作的DREDS和STD数据集介绍。
如图4所示,我们基于所提出的深度仿真方法,构造了囊括高光、透明和漫反射材质的 RGB-D 仿真数据集 DREDS;为验证算法的真实世界性能,还构造了多材质真实数据集 STD。
1) 仿真数据集 DREDS:含有两个子集,a) DREDS-CatKnown,包括1801个来自 ShapeNetCore[4] 7个类的物体实例,含119K 训练和测试数据;b) DREDS-CatNovel,包括60个新类别物体实例,含11K 测试数据,其场景和物体迁移自 GraspNet-1Billion[5],用于评价算法的泛化能力。
2) 真实数据集 STD:a) STD-CatKnown,包含22.5K 采自25个场景的42个类别已知物体数据;b) STD-CatNovel,包含4.5K 采自5个场景的8个新类别物体数据。其中,我们三维重建了所有50个物体的 CAD 模型,标注了物体的6D 位姿、标准深度和实例分割标签。
04
深度修复模型SwinDRNet
图5. SwinDRNet框架图。
我们提出了基于 Swin Transformer 进行 RGB-D 融合的深度修复网络 SwinDRNet,输入 RGB 和原始深度图,输出修复的深度图,框架如图5所示,分为三个阶段:
1) 基于 SwinT 的特征提取:基于性能强大且高效的 SwinT 构造独立的编码器,分别从 RGB 和深度这两种模态提取多尺度特征,以充分利用视觉和几何信息。
2) 基于交叉注意力 Transformer 的 RGB-D 特征融合:使用多层次双向交叉注意力(cross-attention)机制融合双流特征。具体地,从 RGB 特征获取 query,从深度特征获取 key 和 value,计算 RGB 到深度的交叉注意力特征;反向地,可以得到深度到 RGB 的交叉注意力特征。之后,双向交叉注意力特征与原始 RGB 和深度特征分层拼接,得到融合的多层次特征。
3) 基于置信度图插值的最终深度预测:接收融合的特征后,深度解码器输出初始的修复后深度图,置信度解码器预测初始修复深度图的置信度图(confidence map)。之后根据置信度图对原始深度图和初始修复深度图插值,使得网络既能选择修复过的深度,又能保留原有的正确深度。最后,输出修复完成的深度图。
05
任务与实验结果
我们通过一系列实验,展示了仅在 DREDS-CatKnown 训练集训练的 SwinDRNet 在深度修复、类别级物体位姿估计、机械臂物体抓取等任务的性能。
在深度修复任务上,如表1和图6所示,SwinDRNet 在定量和可视化评价上都超越了基线方法 NLSPN[6] 和 LIDF[3];能够泛化到新物体实例和新类别物体;训练时只见过仿真数据,就能在真实测试数据上性能领先,证明了模型从虚拟到真实(sim-to-real)的泛化能力。
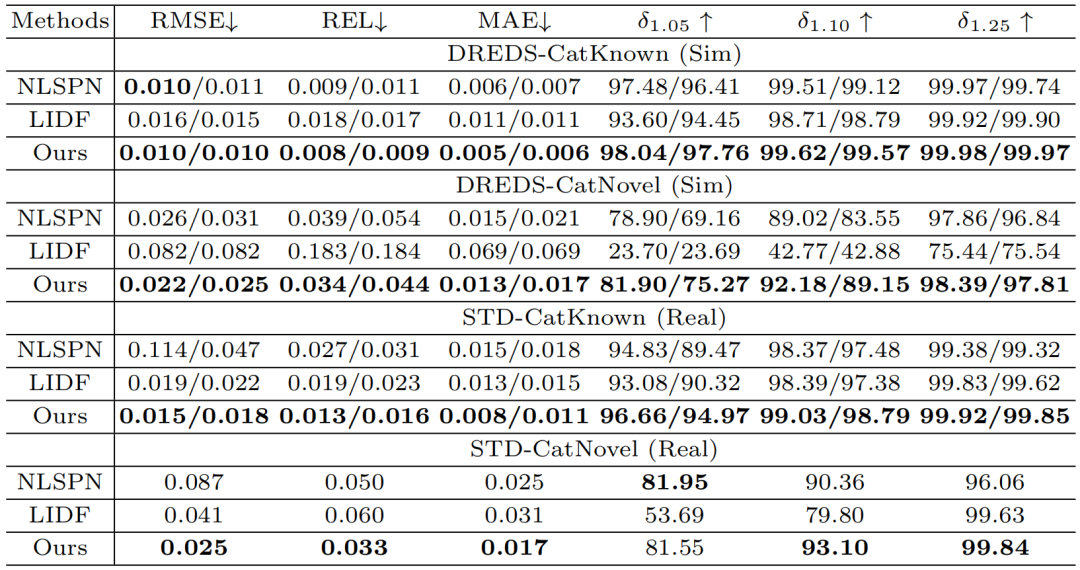
表1. 深度修复实验定量结果。其中"/"左边表示所有物体的评估结果,右边表示仅评估高光和透明物体的结果。STD-CatNovel只含高光和透明物体,因此仅报告一项结果。
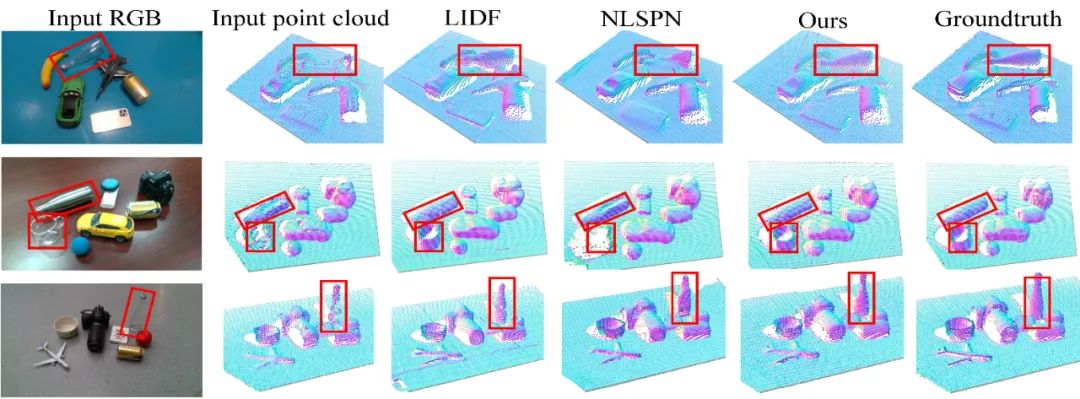
图6. 深度修复实验可视化结果。
在下游任务方面,对于类别级物体位姿估计,将 SwinDRNet 与有或没有深度修复的两种基线方法NOCS[7] 和 SGPA[8] 进行比较。如表2所示,经 SwinDRNet 深度修复显著提升了位姿估计的性能,优于各基线方法。
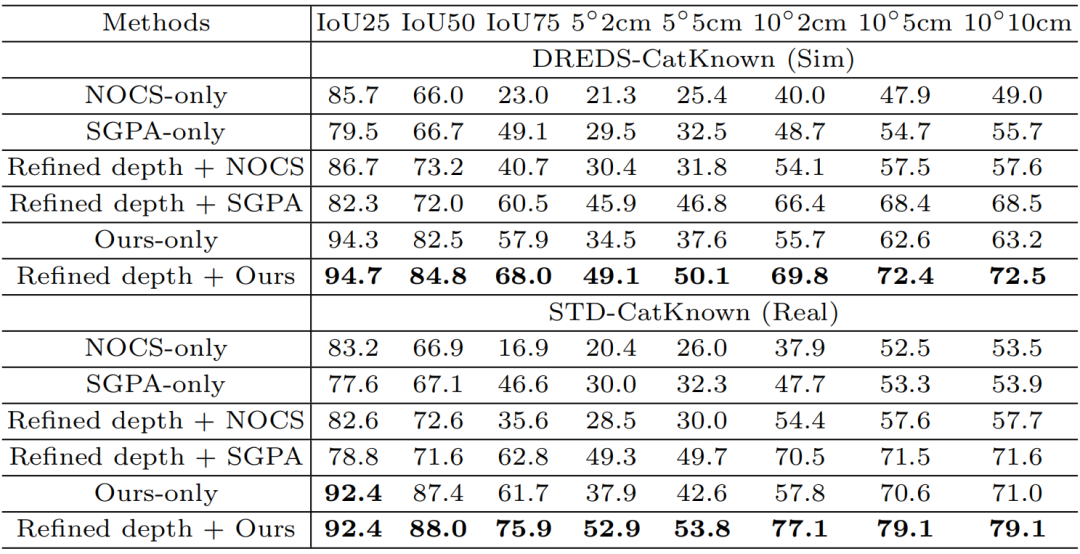
表2. 类别级姿态估计的定量结果。
对于高光和透明物体抓取实验,采用预训练 GraspNet-baseline[5] 模型预测6D 抓取位姿。如表3和 demo 所示,使用 SwinDRNet 修复的点云作为输入,相比于直接使用原始点云,抓取高光和透明物体的成功率和清台率都得到了显著提升。

表3. 机械臂抓取高光和透明物体的实验结果。
06
总 结
本工作研究了主动立体视觉深度相机在高光和透明物体上的深度仿真与修复及下游任务性能的问题。我们提出了 RGB-D 融合网络 SwinDRNet 用于实时的、多材质的深度修复;提出了域随机化增强的深度仿真方法,合成具有现实传感器噪声的大规模 RGB-D 仿真数据集 DREDS,能够缩小高光和透明物体的虚拟与真实域间差距,增强算法在没见过的物体和类别上的泛化性能。我们还构造了多材质真实数据集 STD 用于真实世界的性能评估。高光和透明物体抓取与位姿估计的实验进一步验证了我们提出的方法的有效性和泛化能力。
参考文献
[1] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows. ICCV 2021.
[2] Sajjan S, Moore M, Pan M, et al. Clear grasp: 3d shape estimation of transparent objects for manipulation. ICRA 2020.
[3] Zhu L, Mousavian A, Xiang Y, et al. RGB-D local implicit function for depth completion of transparent objects. CVPR 2021.
[4] Chang A X, Funkhouser T, Guibas L, et al. Shapenet: An information-rich 3d model repository. arXiv:1512.03012, 2015.
[5] Fang H S, Wang C, Gou M, et al. Graspnet-1billion: A large-scale benchmark for general object grasping. CVPR 2020.
[6] Park J, Joo K, Hu Z, et al. Non-local spatial propagation network for depth completion. ECCV 2020.
[7] Wang H, Sridhar S, Huang J, et al. Normalized object coordinate space for category-level 6d object pose and size estimation. CVPR 2019.
[8] Chen K, Dou Q. Sgpa: Structure-guided prior adaptation for category-level 6d object pose estimation. ICCV 2021.
具身感知与交互实验室
北京大学具身感知与交互实验室 EPIC Lab(Embodied Perception and InteraCtion Lab)由王鹤博士于2021年在北京大学创立。该实验室立足三维视觉感知与机器人学,重点关注机器人具身在三维复杂环境中的交互和涉及的感知问题,研究目标是以可扩增的方式发展可泛化的机器人视觉系统和物体操控策略。
Embodied Perception and InteraCtion (EPIC) Lab is found by Dr. He Wang at Peking University in 2021, where research revolves around 3D vision and robotics with special focus on embodied AI. The mission is to endow robots working in complex real-world scenes with generalizable 3D vision and interaction policies in a scalable way.
实验室 PI 简介:王鹤 助理教授
实验室相关新闻:#PKU EPIC
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
点击“阅读原文”转论文链接