ACL 2019 | 利用主题模板进行维基百科摘要生成
作者:Laura Perez-Beltrachini, Yang Liu, Mirella Lapata (爱丁堡大学)
论文原文:https://arxiv.org/pdf/.pdf
论文背景
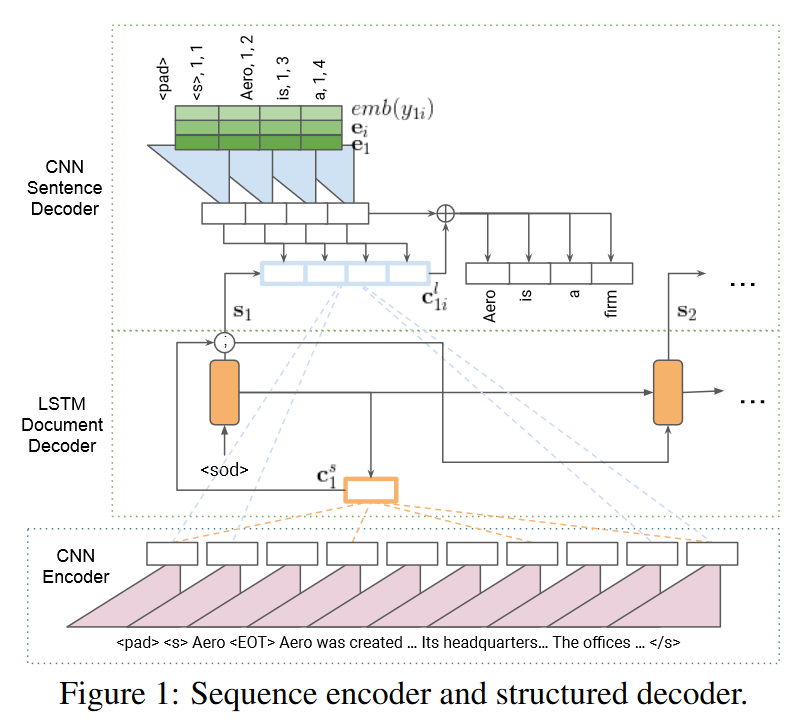
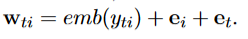
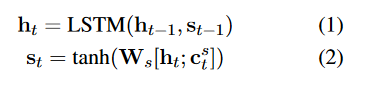
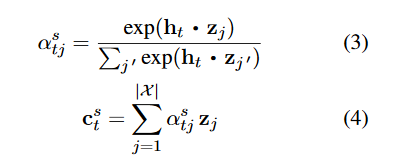
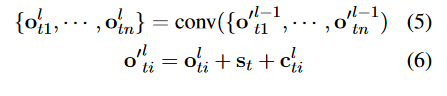
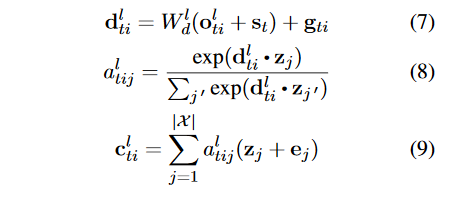
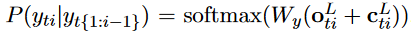
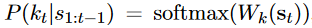
论文实验
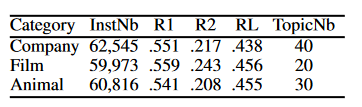
该文在自己构造的数据集WIKICATSUM上进行了实验,其中包含三类文档:公司,电影与动物。具体参数如下(R1,R2.RL分别代表ROUGE-1, ROUGE-2,ROUGE-L的召回率):
实验中将模型与谷歌2018年的工作进行了对比。结果如下表(TF-S2S为谷歌模型,A代表生成结果与标准结果的重合度,C代表生成结果与输入语料的重合度):
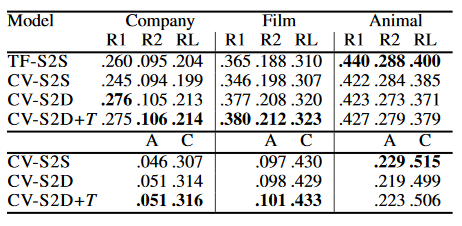
可以看出,此模型在公司与电影领域上对比之前工作将各个ROUGE分数提高了0.15分左右,且在动物领域上也有不错的表现。此外,结果还表明此模型生成的摘要覆盖内容面更广泛。
参考文献
[1] Thang Luong, Hieu Pham, and Christopher D. Manning. 2015. Effective approaches to attention-based neural machine translation. In Proceedings of the2015 Conference on Empirical Methods in Natural Language Processing, pages 1412-1421, Lisbon, Portugal.
[2] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. 2017. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, pages 1243-1252, Sydney, Australia.


 点击
阅读原文
下载
点击
阅读原文
下载




