斯坦福发布3D街景数据集:8个3D城市模型+2500万图像+1.18亿图像配对
斯坦福大学最新发布了一个3D街景数据集,该数据集包括2500万个谷歌街景图像,8个城市的3D模型以及 1.18亿个图像配对。
研究人员通过开发一个系统,将城市的地理参考3D模型与谷歌街景图像及其地理元数据集成,自动收集数据集而无需人工标注。
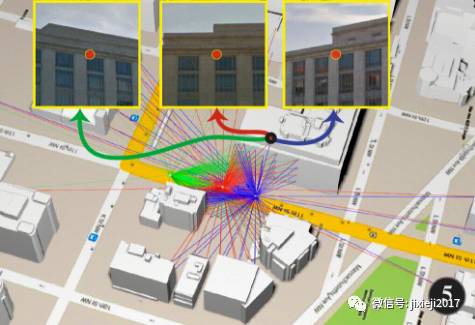
研究人员在8个城市的密集网格上收集图像。
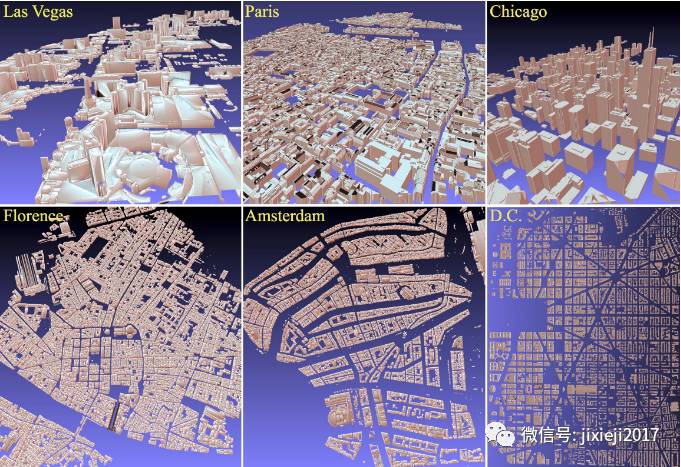
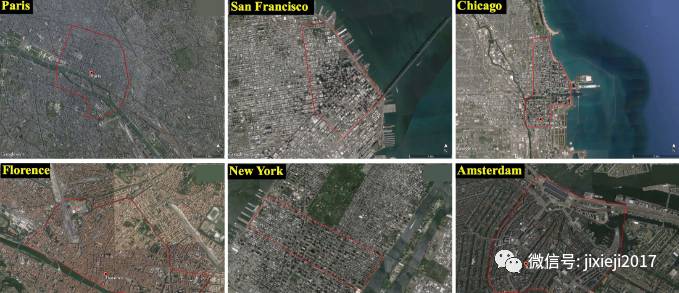
数据集涵盖了纽约、芝加哥、华盛顿、拉斯维加斯、佛罗伦萨、阿姆斯特丹、旧金山和巴黎的市中心和周边地区。研究人员将发布这些城市的3D模型以及街景图像和元数据。这些模型是地理标记和手动生成的。在下面你可以看到3D模型的快照。
基于城市的3D模型,在外墙上密集采样点,并进行光线跟踪,查找所有不影响目标点的街景全景。针对每张图像,来确定街景摄像机的地理位置以及聚焦目标点的位置。
google街景视图提供360全景,计算航向和俯仰角度,以便我们可以捕获显示其中心的、各个目标点的640x640图像(全景图)。如果它们显示相同的物理目标点,则两个图像形成一对。
每个目标点通常由2-7个相应的街景图像观察到。图像由640x640 jpg格式以及同名命名的文本文件提供,其中包含元数据,例如相机和目标点的地理位置,与目标的距离或相机的姿态。
图片的文件名会标记为街景视图位置和目标点的唯一ID。因此很容易识别相应的图像。图像被压缩成多个zip文件,使得文件大小不超过最大值。
你可以下载数千个随机选取的测试数据点的可视化和精度分析。下面你可以看到两个图像的中心应该匹配的几个示例测试对,三个Turkers通过点击来验证。
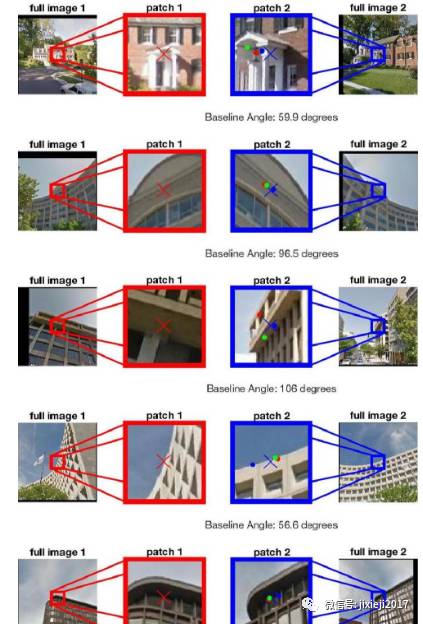
该数据集还可用于学习6DOF摄像机姿态估计/视觉测距,图像匹配和各种3D估计。

数据集下载:http://suo.im/2PqSN4
项目介绍:http://3drepresentation.stanford.edu/
论文地址:http://suo.im/10CmG4
★推荐阅读★
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang





