学界 | 给动漫人物轻松换装、编舞,这家游戏公司用GAN做到了!
选自DeNA
作者:Koichi Hamada 等
机器之心编译
参与:李诗萌、路
日本游戏公司 DeNA 利用渐进式结构条件生成对抗网络(PSGAN)这一新框架生成高分辨率全身动漫人物图像,该方法能够生成高分辨率图像,且具备结构一致性。此外,该方法还可以轻松实现动漫人物换装和添加动作。
论文:Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks

论文链接:https://drive.google.com/file/d/1uLvdkEWUzb4Qgtg_abelaLoSkj3zcsD2/edit
摘要:我们提出的渐进式结构条件生成对抗网络(Progressive Structure-conditional Generative Adversarial Network,PSGAN)是一种根据结构信息生成高分辨率全身人物图像的新框架。最近的生成对抗网络可以通过渐进式训练生成高分辨率的图像。但是现有的方法无法同时满足高图像质量和结构一致性。我们提出的方法通过在训练过程中渐进地增强生成图像分辨率和结构条件,突破了之前方法的局限性。我们比较了现有方法和分辨率为 1024*1024 的不同动漫形象基于目标姿势序列生成的视频结果,论证了本文提出方法的有效性。我们还用 Unity 3D Avatar 模型创建了新的数据集,该数据集包含 1024*1024 的高分辨率全身图像以及精确的 2D 姿势关键词。
生成 1024*1024 的全身动漫人物
我们展示了使用测试姿势序列通过 PSGAN 生成的分辨率为 1024*1024 的不同动漫形象和动画视频示例。1. 我们先根据随机隐变量用 PSGAN 生成了许多动漫人物,通过插入这些人物来创建新的动漫形象。2. 接下来我们给 PSGAN 网络提供连续的姿势序列信息,通过这些信息为每一个动漫形象生成一段动画视频。在这段视频中我们多次重复了 1 和 2 步骤。
生成新的动漫人物全身图像

我们用 PSGAN 插入对应身穿不同服饰的动漫形象(人物 1 和人物 2)的隐变量,来生成新的动漫人物的全身图像。注意,这里只需要一个姿势。
给动漫人物的全身像添加动作
下图展示了使用特定动漫人物和目标姿势生成一段动画的示例:
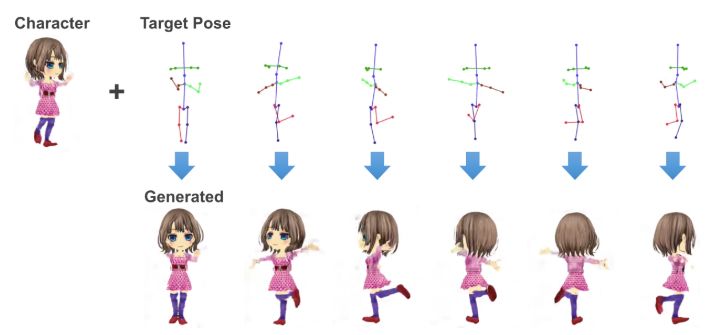
通过调整隐变量和给 PSGAN 提供连续的姿势序列,我们可以为每一个动漫人物生成一段动画。更具体地说,我们将特定的动漫人物的表征映射到隐空间的隐变量中,作为 PSGAN 的输入向量。
通过将指定的动漫人物映射到隐空间,并生成隐变量作为 PSGAN 的输入,就可以生成特定动漫形象的任意动画视频。
渐进式结构条件 GAN(PSGAN)
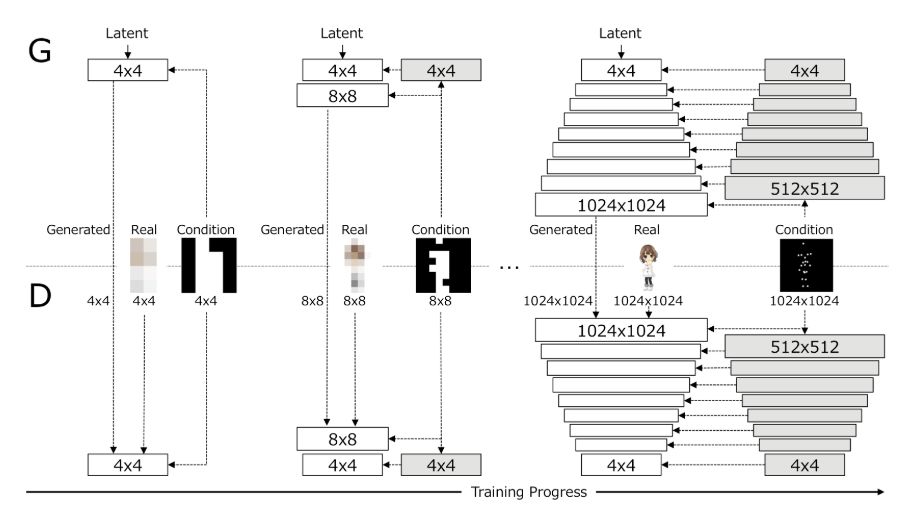
我们的关键思想是渐进地学习带有结构条件的图像表征。上图展示了 PSGAN 中生成器 G 和鉴别器 D 的结构。PSGAN 在每个尺度下根据结构条件增强了生成图像的分辨率,并生成了高分辨率的图像。我们采用了和 Progressive GAN [Karras+18] 中图像生成器和辨别器相同的结构,但我们通过添加每个尺度对应分辨率的姿势映射,在生成器和鉴别器上添加了结构性条件,这显著地稳定了训练。带有结构条件的 GAN 之前也有人提出过[Ma+17,Ma+18,Balakrishnan+18,Siarohin+18,Si+18,Hu+18,Qiao+18]。他们用的是单尺度条件,而我们用的是多尺度条件。具体而言,我们在每一个尺度上下采样了全分辨率的结构条件映射,组成多尺度条件映射。就每个尺度而言,生成器根据带有结构条件的隐变量生成一张图像,而鉴别器根据结构条件区分生成图像和真实图像。N*N 的白色框表示在 N*N 的空间分辨率上进行可学习的卷积层操作。N*N 的灰色框表示结构条件的不可学习下采样层,这样的操作将结构条件映射的空间分辨率降到了 N*N。我们用 M 个通道表示 M 维结构条件(例如 M 个关键点)。
AVATAR 动漫形象数据集
我们用包含 600 个姿势和 69 类服饰的 Unity 3D Avatar 模型创建了一个全新的数据集,该数据集包含分辨率为 1024*1024 的全身图像以及精准的 2D 姿势关键词。下图是创建数据的示例。动漫形象(每对图的左侧)和姿势图像(每对图的右侧)如下图所示。

对比

结构一致性对比

上图所示是用 Progressive GAN [Karras+18] 和 PSGAN 在 DeepFashion [Liu+16] (256*256) 数据集上生成的图像。通过观察可以看出 Progressive GAN 不能生成与全局结构一致的自然图像(例如左边四张图)。而 PSGAN 可以通过在每个尺度上添加结构条件生成与全局结构一致的合理图像。
基于姿势条件生成图像的质量对比
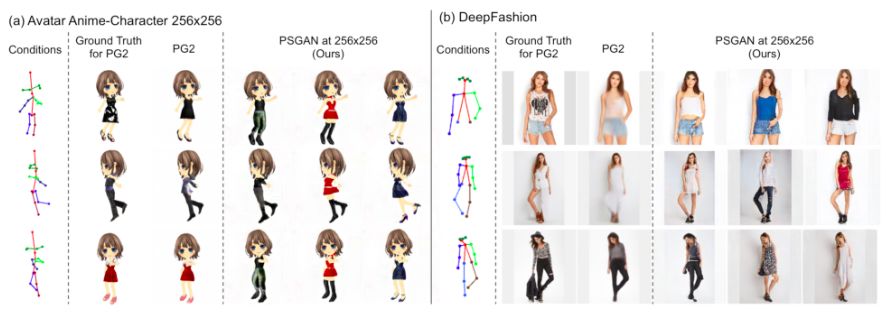
上图所示是 PSGAN 和姿势引导的人像生成模型(Pose Guided Person Image Generation,PG2)[Ma+17] 在 256*256 版的 Avatar 数据集和 DeepFashion 数据集上生成的图像。从上图可以看出,由于在每个尺度上添加了结构条件,PSGAN 生成的图像比 PG2 更清晰,细节也更多。
PG2 需要源图像和对应的目标姿势,来将源图像转换成具有目标姿势的图像。与此同时,PSGAN 利用隐变量和目标姿势生成带有目标姿势的图像,且无需成对的训练图像。

原文链接:https://dena.com/intl/anime-generation/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



