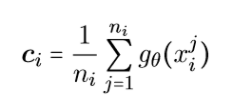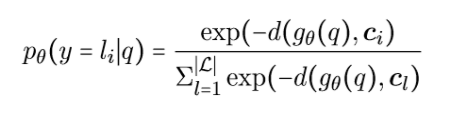分享嘉宾:曾敏 微软 高级技术总监
文章整理:Hoh Xil
内容来源:DataFunTalk·年终论坛
出品平台:DataFun
注:欢迎转载,转载请在留言区留言。
导读:微软小冰是领先的跨平台人工智能系统,本次分享将介绍微软小冰最新的对话技术框架,以及在这套框架的基础之上,如何一步步构建人格化的对话系统,并且在社交娱乐及实用场景当中的具体运用。主要包括:
如何构建基本的对话系统?
人格化的定义及如何部分实现人格化
如何构建基本的对话系统?
人机对话系统是在不断迭代演化的:之前大家对物理世界的交互主要通过信件,烽火传令等等,慢慢的进化到人机,通过键盘、电脑跟虚拟的物理世界进行交互,极大的加速了人类对信息的获取。随着互联网的兴起,极大的加速了人类对信息的获取,但是到了移动互联网时代,我们积累了大量的信息和知识,以及社会行业分工的更加具体化,大量的长尾知识隐含在互联网的各个角落中。由于信息非常的庞大,很难直接通过一个非常高效的方法检索到。因此,我们下一个可能潜在的方向:是否有可能存在一个agent ( 智能体 ),能帮助我们更便捷的、更快速的获取信息。
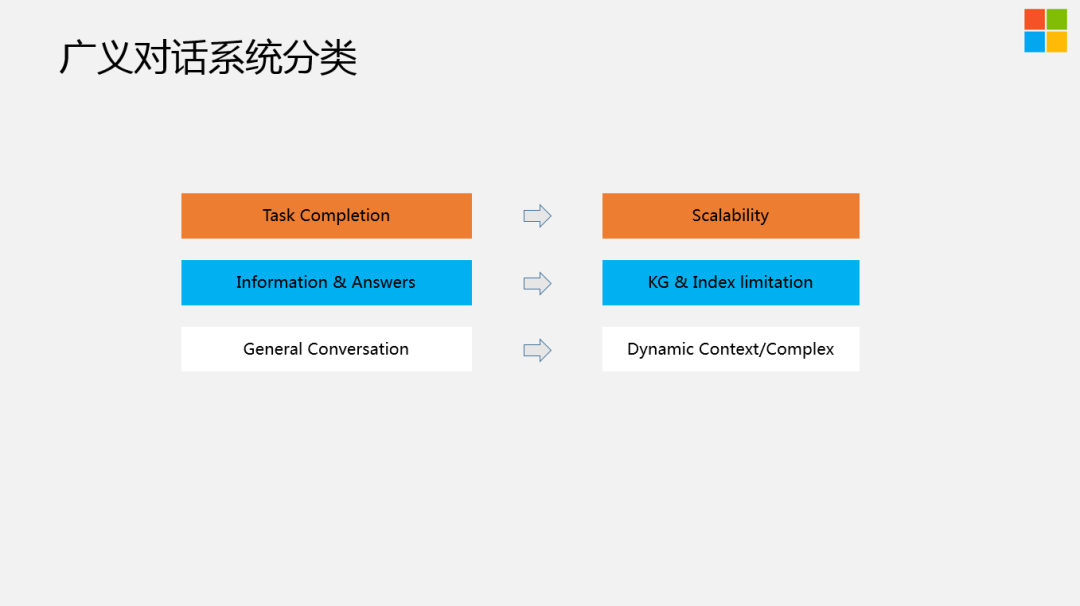
大家可能会发现,以前更多的是在搜索引擎上搜索各种各样的信息,但是慢慢的会尝试着在知乎、抖音、微博等渠道获取信息,这是为什么呢?这是因为大量垂域化的内容,相对来讲比较专业、比较有深度,大家形成了这种体验,在浏览某个页面之后,突然又有了一个意图,就会留在平台上,再做进一步搜索。所以我们的搜索行为会从搜索引擎迁移到各个垂域。目前,市场上也有非常多的产品,包括百度也在往feed流转化。大家打开手百的页面,会发现原来就是一个搜索框,现在他们把搜索框往上拉了,下面多了很多feed流的内容。在这个维度上讲,现在信息的丰富度越来越大,我们的假设是类似于这种搭建内容社区的维度,把更多的信息组织起来,用更好的搜索引擎推荐的做法,给到用户更好的获取信息的渠道。那么,是不是可能有另外一种形式的交互?而且是以这种自然语言的方式去问一个agent,能不能帮到我去获取背后的物理世界或者虚拟世界的信息,这其实就是Conversation AI的主要方向。Conversation AI主要包括三个方向:
第一个方向是Task Completion,这也是业界做的比较多的,包括客服机器人和各种代理等等,都定位在这个方向。这里存在一个问题,就是它的Scalability ( 可扩展性 ) 不是特别够。当你在做A场景的时候,可能产品设计思路、框架部分是能够复用的,但是你的模型、意图分类、serving,每个场景都会不一样。
第二个方向是做Information和Answers的攫取,有点类似于百度知道或者知乎上如何评价XX?这种话题。如果要搭建类似这样的系统,需要有很好的社区对内容进行维护,来尽可能的让知识库以及问题答案的丰富度和多样性在一个比较高的水平,它的局限性也在这个地方。
第三个方向是General Conversation ( 闲聊 ),也是小冰主要关注的方向。而这里比较大的问题是 ( Dynamic Context/Complex ) 长程的上下文非常的复杂,不仅仅是当前对话轮中会存在特别多的问题,包括用户昨天说过的话,一个月之前说过的话,可能都会对今天的对话内容造成比较大的影响,这是一个非常难的问题。
这里给大家分享下小冰为什么更多的关注在第三个方向,主要原因:
小冰在刚立项时,我们发现目前市场上所做的产品都有比较大的局限性。在现有系统中,对比已有的任务或者搜索信息的方式,并不能带来更多的价值。比如订机票或者订外卖,包括国内一些大厂也在做,通过对话系统完成类似的事情,但是市场上其实已经有了很好的APP能够快速的完成类似的任务。快速不是说简单点两下就完成了,而是说对话系统本身是有局限性的,首先对话是基于时间的行为序列,是一步一步往下走的,但是我们在做task时,其实有很多的工具、界面,可以一目十行的看到非常多的文字、图片和视频等各种各样的信息跟我们进行交互。由于通过文字进行交互,信息被极大的压缩了,人在接受文字类信息的处理速度相对来讲会比图像、视频等要慢一些。站在这个维度,由于Scalability局限性,以及市场上已经有了成型的产品在做这件事情,所以这块的上限或者想象空间会稍微低一些。
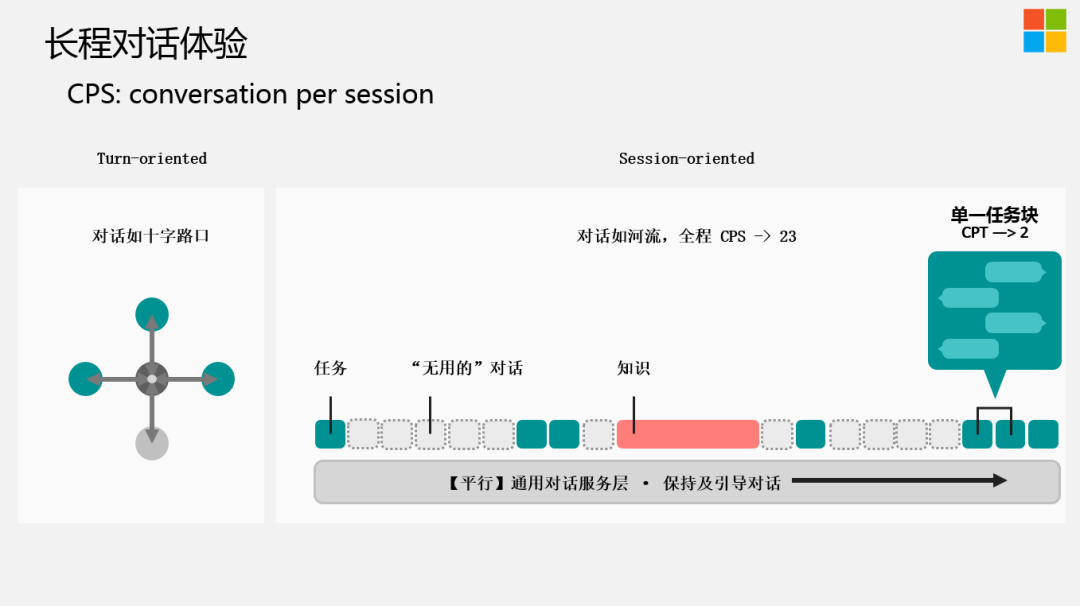
实际上,我们一直以Session-oriented来设计整个对话系统。左边是业界比较传统的做法,把它散漫出来,就是当用户站在对话的某一时间节点时,可能背后会有很多的意图,很多的分类,这时需要做一个决策,到底是往A、B、C哪个方向走?跟我们人与人之间的对话交流相似,对话应该像河流一样,在实际的沟通过程中,并不是每一句话都有特别的信息量,并不是每一句话都是在做任务或者搜索。这些无用的对话,由于穿插在这些任务或者知识的获取中,并且前面有些无用的对话可能会对后边的推荐或者任务有帮助,所以我们可以把这些潜在的意图给挖掘出来加以利用。举个例子,也是业界在做对话系统时忽略的一点,就是大家会把对话当做一个系统中单纯的技能来对待,把聊天,查天气,讲笑话等摆在同等的维度。我们觉得大家普遍低估了对话的魅力,以及对话场景下,可以挖掘到的宝藏,为什么?
因为对话本身是一个人跟人正常沟通的方式,在对话系统中可以挖掘到很多的有用的信息。比如给潜在的用户推荐一双耐克鞋,对于电商或者网站,可能通过推荐系统来做,而我们会根据很多的标签,很多的信息,采用挖掘的方式来获取到用户的显性/隐性的各种指标和标签,实际上,通过对话可以非常容易的完成这件事情。比如今天是周末,天气很好,你问用户周末干嘛去,用户说他可能是无聊闲着在家,这时,你可以主动的引导 ( 对话就像一个河流,站在后台系统角度来看,是一个非常大的决策树,可以把用户往A方向引导,也可以往B方向引导 ) 用户,平时没时间锻炼,周末正好去跑个步,如果用户接着follow对话的方向,系统就有可能把用户往健身运动这个方向引导,这时,就可以把耐克鞋以某种潜在的方式给推荐出来。可以通过对话的方式,比较自然的把有价值的信息推荐给用户。
另外,很多隐性的标签是没法通过点击的方式获取的,不管是搜索引擎还是推荐系统,大家或多或少是通过点击或者不点击的反馈得到用户对搜索结果或者推荐结果是否感兴趣,来反向的优化搜索引擎或者推荐系统。但是,通过对话可以比较直接的挖掘到用户的兴趣点。比如你想知道用户是男是女,我们可以通过问用户有没有男朋友来得到答案。这是一个很简单的问题,当被抛出来之后,用户也不觉得这个问题有多么的突兀,就是人跟人之间无意的对话,由于人类类似于一个复读机,每天会重复的聊比较相似的话题。如果用户回答说有,我们就知道这个用户是女性用户,反之,用户可能会说它是一个男的。其实这是一个NLP里面的text entailment,也就是有一个前提假设,然后扔出来一个action,看用户怎样响应,如果用户选择的是A路径,可能就符合你的A假设。所以我们可以在对话中挖掘到很多通过搜索引擎或者推荐系统挖掘不到的非常直观的信息。
对于对话系统特别是闲聊式的对话系统,该如何衡量?我们用CPS ( conversation per session ) 指标来衡量,也就是用户跟Chatbot聊天的turn数。这是一个相对来讲非常宏观的指标,并不能100%代表对话的质量,我们目前的平均值可以做到23。一般任务型的对话系统,基本2~3个turn可能就完成了。而且用户的粘性也不会特别好,用户有需求时,才会用一下。站在我们的立场,turn数越多,可以挖掘到的有用信息越多,给用户推荐引导的机会就越多。
其实小冰也能做很多的task,只不过我们在对外宣传时,不会特意去提,我们觉得很多基本的Task是一个对话机器人的标配,如果一个产品有下界跟上界,这个下界就是做一些基本的task。在我们内部,有一层通用的对话系统服务层,主要是为了保持及引导对话的过程。
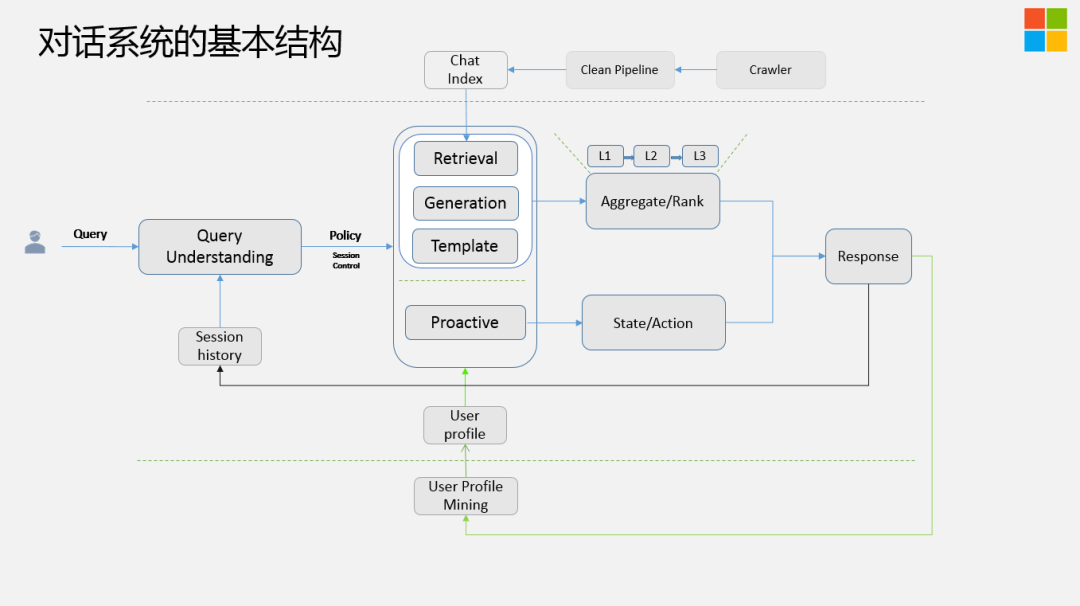
接下来分享下,我们对话系统的基本结构,宏观上,整体的架构跟搜索推荐的架构非常像:
首先Query来了,我们会对Query做分析,进行Query Understanding,不仅仅分析当前的Query,还会从Session里提取Session History来做分析,生成两大类的Policy,一类是被动式的,一类是主动式的。
被动式的:指的是当前的Query比较有信息量,这时需要尽可能的引导这个话题往更有意义,更深入的方向上走,这里有三个模块:基于模板,基于检索,基于生成的方式来做的,然后对这三个模块整体上会做Aggregation Ranking,这里包含三层:召回,排序,还有Post Process ( 后处理 ),需要把很多违背常识/违背逻辑的答案去除。
主动式的 ( Proactive ):指抛出新的话题。对话系统不是一个简单的NLP问题,它还是一个非常复杂的系统工程,需要在没话题聊的时候,尽可能的把问题弄回来或者抛出新的话题。需要维护State,以及下一步的Action应该怎样去take。
理论上这两个模块是并行跑的,当系统负载比较高时,它只走其中的一个分支。当Response ( 回复 ) 之后,我们会把它放到离线的用户画像挖掘模块。刚才我们提到,通过问用户有没有男朋友,来Mining出用户画像,用户画像又会反过来给到Ranking、Proactive非常多的信号来做进一步的决策,最后Response会回到Session模块中。
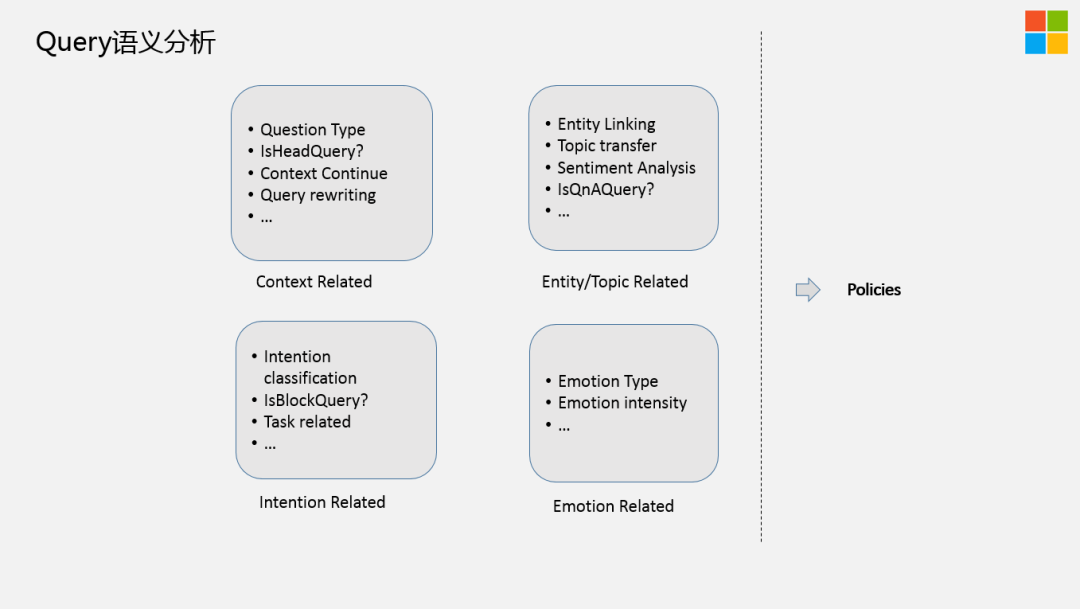
刚才提到当一个Query来了之后,第一步是做Query Understanding,在我们内部有四类信号:
上下文相关的,Entity ( 实体 ) 相关的,意图相关的,情绪相关的
,因为我们是一个对话机器人,需要特别的关注用户当前的状态。
上下文相关的信号:包括query改写,上下文,是不是头部Query,是不是在聊,以及当前的Query类型,是简单的问题,还是复杂的问题。
Entity相关的信号:这块大家都在做,特别提下Topic transfer,在对话中非常常见,因为对话的状态其实是一个open domain,是没有目标的,所以说有很大的概率会存在你在聊这个话题,机器人回答的是另外一个话题,然后用户再去顺着机器人的话题时,他又转移到另外一个话题上去了。所以,这里你需要有一个非常好的Transfer Detection模块,尽可能的把用户当前的topic 检测出来,以及做好话题生成、引导。我们内部有一个Graph叫做Topic Graph,跟业界提的KG有点类似,但又有点不同,我们是基于对话系统里面能聊的Topic本身来精心设计的。Topic之间就蕴含了我当前在聊A话题时,潜在其它话题的可能性。
意图相关的信号:在对话中,有很多潜在的意图,我们需要做意图分类,Task related等。
情绪相关的信号:包括情绪类型和情绪强度等。
① 针对当前的query,把上下文的key word抽取出来,和当前的query做一个combine,combine可以放在前边、后边、中间,可以按照不同的方法组合出来。
② 通过sequence建模的方式,把上下文query放到统一的model中建模,得到vector,甚至可以叠加一个Hierarchical层,把整个句子的Embedding表示出来。
对于①:由于生成模型会对序列产生很大影响,直接插入关键词是不科学的做法,比较简单粗暴;仅仅进行关键词抽取,可能会忽略掉一些信息,比如“否定”类的信息,就不会被挖掘到。
对于②:Embedding建模的方式是一个系统工程,需要的计算资源非常大;如果整个句子过长,则起不到很好的建模作用。
Unsupervised Context Rewriting for Open Domain Conversation
https://arxiv.org/abs/1910.08282
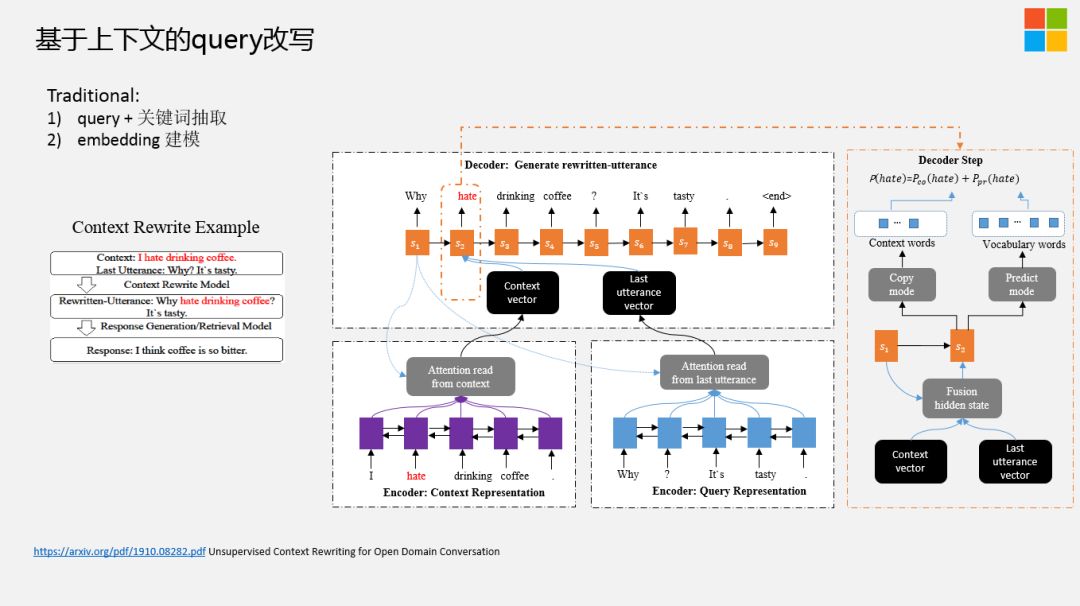
我们通过生成的方式来做Query改写,尽可能的补全当前的Query,采用2个Encoder+1个Decoder,其中一个Encoder会把Session中比较重要的信息通过Attention方式进行统一建模,同理,Query这块也是类似的处理,然后Decoder这块儿,我们会通过端到端的方式看当前生成的term是从Query端做拷贝。
对于这个Task,难点在于如何得到大量的训练数据。在互联网上,有大量的长片段的Session对话,但是你要把这种端到端的 ( 给定的Context跟当前的Query ) 改写好的response很好的抽出来,但是,数据量还不是特别大。
除了一些ground truth data让标注团队去标注一部分数据集,我们想端到端通过生成的方式做Query改写,还是需要大量的数据。我们的做法,分为以下几步:
Step1:首先使用 Pointwise Mutual Information ( PMI ) 算法根据Query和 response ( 回复的句子 ),抽取上下文中与其共现概率最大的若干词作为关键信息。
Step2:再使用语言模型将这些信息插入Query中,计算不同插入位置的得分,我们这里选取的是Top 3生成的句子,进而得到被改写的 query。
Step3:但是在实际的应用场景中,我们无法得到 response 的信息,所以我们采用一个基于复制网络 ( copy-net ) 的深度模型来学习这部分先验知识,并使用这些构造好的数据作为训练集,利用该训练集进行多轮对话上下文改写模型训练 ( Context Rewriting Network )。
Step4:使用强化学习来优化S*,也就是改写好的Query。不过强化学习的效果不是特别稳定,以及存在一些潜在的风险。
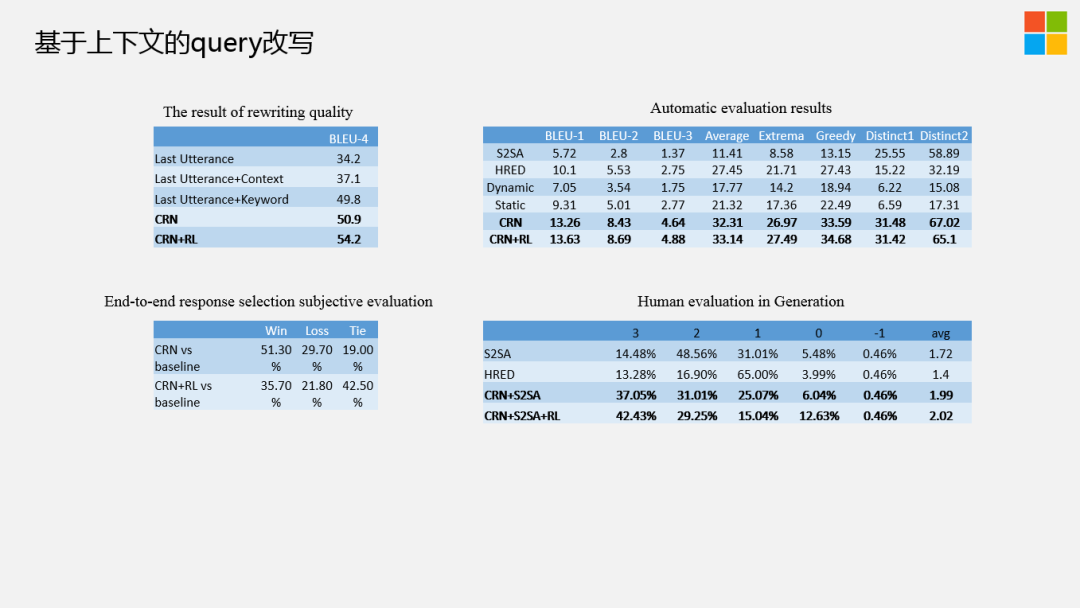
我们来看下,基于上下文的query改写结果,不管是人工评判,还是自动评判,都有比较好的结果。简单提一下,如图中左下角,我们用改写好的框架运行在实际的线上系统,端到端的衡量改写的Query,我们发现不做强化学习的模块,要高于baseline20个点,但是加入强化学习后的结果不是特别的多。我们再细致的看右边标注的结果,就是-1,0,1,2,3,其中1,2,3相对来讲是比较好的回复,大家可以看到0的比例会显着高于baseline也会高于不加LR的模块。在实际中,我们采用的是CRN的方法。
在我们的对话系统中会有很多的意图,与task不同点在于task的query表达相对清晰、句式结构以及用词相对明确,但在对话系统中我们会发现有很多的Query潜在的意图可能是一样的,甚至有些Intention可能还没有Entity,场景比较随机。另外,我们能得到的样本其实非常少的,特别是小意图,基本上还是通过人工标注的方式来得到训练数据。
在小样本学习中,有一个比较经典的领域,就是Meta Learning,Meta Learning又分为:基于model based方法,metric based方法。基于Metric based中又有一种方法是基于原型的网络。
简单解释下原型网络:假设,现在的样本比较少,我们可以通过原型网络来建模。由于每一类都有一些小样本,在建模过程中,每一次都是随机的挑一些类别,每一类中也尽可能的挑一些样本出来,然后通过原型网络进行建模。每一个样本我们挑出来之后,都会得到一个表达,经过多次的训练,就会得到每个样本的不同表达。然后对某一类中,所有的样本做平均:
我们认为C1 ( 见上图 ) 是对应的类的中心点,同样C2,C3也是各自对应的类的中心点。当一个新的Query来了之后,我们会对新的Query也进行建模,得到一个表达X,当前的X跟已有类别的distance,可以通过下面的方式,进行衡量:
然后进行归一化操作得到概率,即x属于每一个类的概率。
这样做有一个好处:当有新的类别加进来之后,整个模型并不需要进行特别多的改动,对于这种比较随机的场景,每天可能新增十几种新的意图,但是增加一个新的意图,并不需要再显示的重新训练模型。因为原型网络这种方式,已经在帮你尽可能的对样本做很好的建模。所以在实际系统中,我们基本上能做到20分钟以内,只要把意图构建好之后,就能把整个model重新推上线,非常的快。
我们发现,Ci是根据样本的个数来做均等的分配,我们认为这不是一个特别好的思路。所以说我们做了Hierarchical Attention,这样的原型网络。具体细节大家可以看论文:
Hierarchical Attention Prototypical Networks for Few-Shot Text Classification
https://www.aclweb.org/anthology/D19-1045/
在这里,我们认为样本空间中的每一个样本对中心点的贡献都是不一样的。所以我们会有一个βij的表达,通过中间的Word Level Attention以及Instance Level Multi Cross Attention尽可能分出来每个样本对中心点Contribution。最后用当前的Query,类似的,通过Encoder layer得到q'。每个样本Ci的表达,用上面新的表达来进行更新,对每一类的标签,也会有一个新的Class Feature Extractor,也就是新的向量的表达。因为样本本身也是分布不均匀的,所以λi也是需要做建模的。
![]()
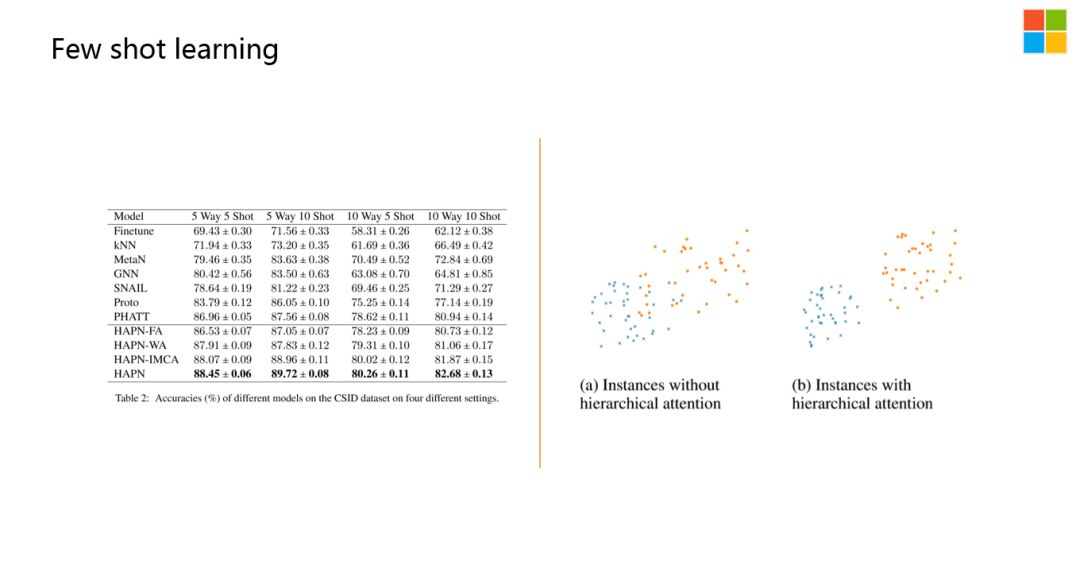
整体的效果,如上图所示,最后一行是基于新的方法来做的。可以看到相比以前的基于原型网络的方法有了很大的提升。
我们对结果做了一个降维的分析,发现正如我们所理解的那样:
有一些样本点,比较难分的一个原因是它的用词和句式跟另外一个类别中的表达,相对来讲是比较像的。通过这种更深层次的建模,每一类中的每一个样本,对样本中心点的贡献都会不一样,把那些不太重要的样本筛掉之后,处在边界的样本会拉得更开一些。
刚才介绍的两个工作都是在Query端做的工作。接下来介绍下Aggregation Ranking。
L1,Inverted Index ( 倒排索引 )。我们内部也在做ANN search,尽可能的把当前的Query和Session向量化,再通过ANN的方法,做一个比较粗的大规模的召回。
L2,Ranking ( 排序 )。整体分四类Feature:
2018年,预训练技术开始大规模的应用。我们把谷歌的Bert技术用到对话系统中做Ranking,上线后的效果非常好。由于Bert是基于Transformer它的速度相对来说较慢,需要进行大量的模型压缩和蒸馏等相关工作。
L3,Post Process进行Filter/Modify ( 过滤和调整 )。如时间调整,profile entailment ( 性别、星座、位置等 ),字符调整等操作,将不该出现的Response去掉。
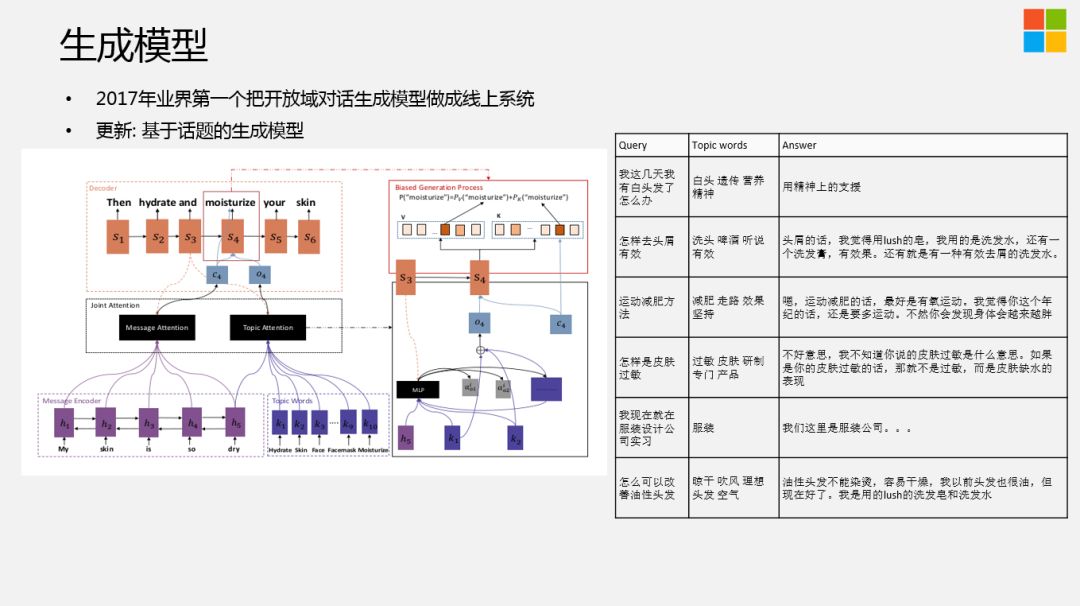
在2017年,我们的开放域对话系统生成模型就已经上线,甚至包括基于语音的交互系统中。最近我们会有一个基于话题 ( 也包括情绪、知识等 ) 生成的模型,在内部已经取得了比较直观的效果,但是整个模型结构可能会不太一样。我们在做生成时,尽可能把一些Topic words加进去。Topic words的来源有很多的方法。这篇论文是通过LDA的方式,还有很多其它的方法,比如LDA+Topic Graph+Knowledge Graph等,受限于篇幅,这里不再展开。
Topic在生成时,会作为Decoder生成的Context其中的一部分。以前Encoder部分,可能有很多的隐藏状态,会对它进行Attention,这时,我们也把基于topic的表达也放到context中,不仅能看到Message Attention,也能看到Topic Attention。
实际的效果,见右图。我们给美妆护肤领域做的Chatbot,一个定制化的生成模型,效果还是不错的。
在做垂域的对话系统时,我们并没有很多质量比较高的数据。所以我们是在一个比较大的数据集中,端到端来做的,然后选择系统中具有代表性的term做生成。在Long Tial问题中,这种端到端的方法效果是非常好的。
从系统整体的对话结构上来看,其实就是QA。但在QA中间,是存在一些策略的,也就是说,对当前的上下文,对用户来讲,机器人要不要引入一些新的话题。整个对话相当于是商检的过程,因为对话本身是无序的,如果回答的不好,就会东扯一下西扯一下。从商业的角度来讲,整个系统的稳定性不是特别好,用户聊了两句可能就走了,所以需要尽可能的获取对话的节奏。那么,有没有可能更显式的控制对话的节奏?
Towards Explainable and Controllable Open Domain Dialogue Generation with Dialogue Acts
https://arxiv.org/pdf/1807.07255.pdf
我们引入了Dialogue Act概念,在这里,我们有比较宽泛的七大类的Act,比如我们是应该follow用户的问题,还是针对用户的问题,问一个新的问题,或者直接拒绝回答用户的问题,这是一大类。还有一大类,是发现当前的Session聊得不太好了,需要更多的引入新的话题,新的话题有可能是饭,也有可能是问题等等。通过这样的方式,我们可以比较好的建模对话的节奏。
![]()
上图是从百度百科中摘取的一段关于人格化的定义,简单来讲,就是人格化的Chatbot。这里我们能够通过技术手段可以实现的是能力、性格、兴趣、一致性、连续性,对Chatbot实现人格化,提供了很好的借鉴方向。
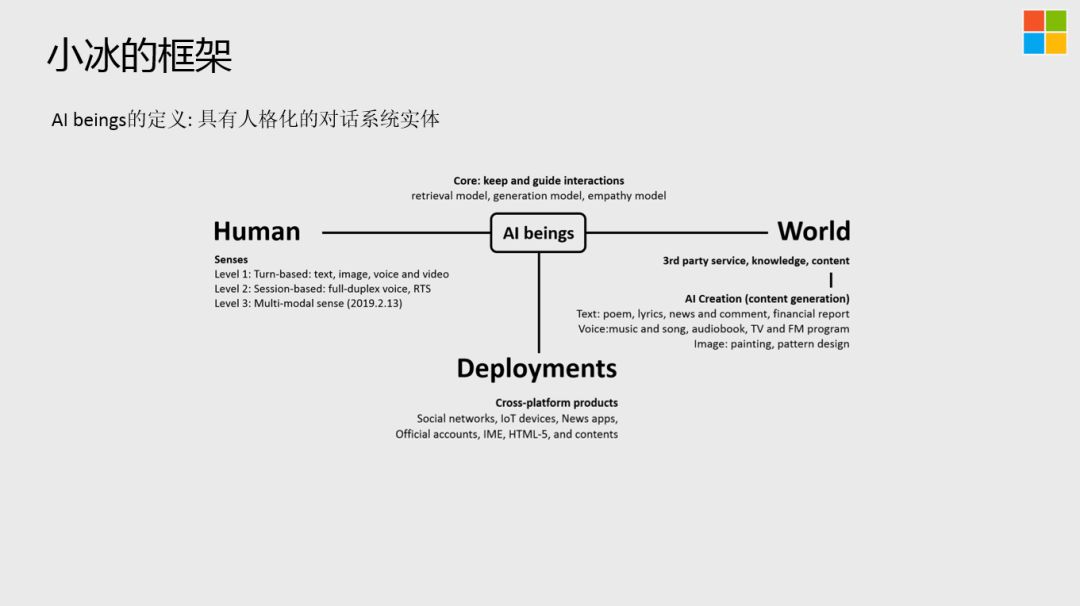
AI beings的定义:具有人格化的对话系统实体。
AI beings是处在T字形中间的状态,左边是Human与人的交互,这里存在3个Level的Senses,基于文本、图像、声音,基于全双工,以及基于多模态的;右端是尽可能的把物理世界的知识、content加进来,在这里还有AI创作的模块,根据人格化的定义,赋予AI beings自己的能力和气质,可以写诗。写歌、唱歌等等,相比于决策,AI创作更容易实现;最后是Deployments,跨平台。
AI beings
最大的困局,在于不能获得对等的地位:
在AI beings之前,已经有大量的工具在或多或少的在完成对应的任务,并且做的还不错;
AI beings需要避免被工具化或者仅仅成为管道 ( 否则被替代的可能性相当大 );
AI beings一旦被赋予主体资格,就有可能建立长期信任关系;
AI beings的终极价值,在于长程陪伴的关系。
-
价格:为了竞争市场,市场上各家相对来讲都会把价格打的非常低。
-
工艺:音箱本身都有各种各样的设计,并且有些音箱的设计确实非常的具有想象力。
-
内容丰富:音箱中内容资源的丰富度,不管是音乐播放、相声、儿童教育,还是其它领域的内容,在内容上的丰富度也是智能音箱的一个卖点。
但是大家仔细一想,AI在其中起到的作用,其实不多。很多技术,如让音箱去播音乐,理论上,在十几年以前的技术就能做到。大家购买音箱的原因主要还是上面的3点,而不是其中的AI技术点。所以,AI如果仅仅是以一个上限不是那么高的实现方式呈现给大家,那么接下来很可能被其他形态的产品所替代,因为AI在系统中的价值并不是很大。
整个Session其实是我们的一些理念,并不是所有的模块都做到了,也希望业界,特别是做开放领域对话的同行,能一块来探讨相关的细节。这是我们的方法论:
我们会认为所有的AI beings首先需要定义她的Profile人格,包括基础属性和兴趣属性,构成一个基本的个体,再给她加上交互的能力,包括对话、声音、视觉,让她有拟人化的声音,可以清楚的看到外面的世界。于是,我们就有了一个基本的AI beings,这时我们可能需要加三观,三观这个词可能用的不是特别的好,我们大致想表达的意思是让AI beings有自己的观点,这个观点不是强行加给她的,而是在给一个初始设定之后,能通过Entailment或者Inference,做Response跟AI beings的观点一致性校验,尽可能让AI beings能体现出自己独特的存在,而不只是帮你完成任务。加入三观之后,后面还会加入创造力、技能与知识,如果有可能的话,可以做一个跨平台的部署,不管是实体的硬件中,还是虚拟的网络里,得到一个统一的交互切入点,体现出无处不在的形态。
在我们内部机器人的基本特征如上,主要包括四部分:Conversation Content/Style、Domain Knowledge/Skill、Opinion、Relation。
重点介绍下Conversation Content/Style:
在我们内部的index中,主要是基于检索的方式对每一句话打上标签 ( tagging ),Tagging是基于性格特点,比如内向、外向、活泼、高冷,进行性格维度的刻画,需要在index中让对话语料体现出这种特点。所以我们会在L3 Post Process模块,加强人设的体现。
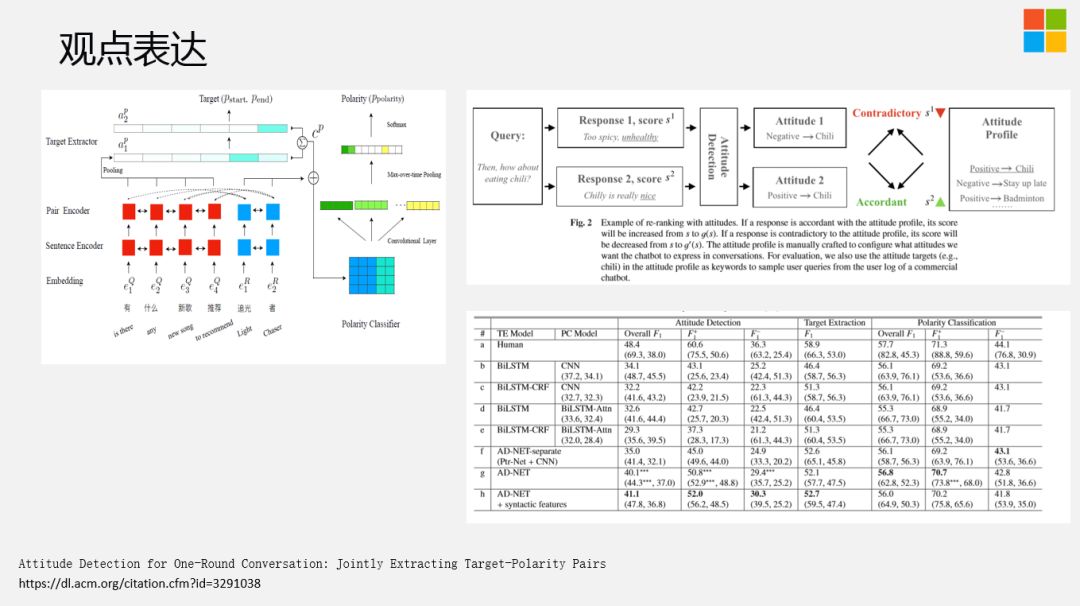
Attitude Detection for One-Round Conversation: Jointly Extracting Target-Polarity Pairs
https://dl.acm.org/citation.cfm?id=3291038
业界在做系统时,会把TAG提取和意图分开。特别是在做slot filling ( 槽位填充 ) 时,会先分意图,再做slot抽取。我们发现,如果把这两个工作组合在一起做,会有更好的效果提升。右上角是我们的一个做法,可以给她的观点根据不同的Entity,不同事物做设定,当有新的Response回来之后,会跟当前的设定做逻辑一致性校验,比如喜欢吃辣的或者不喜欢吃辣的,Response如果是吃火锅,对应的就是喜欢吃辣的,如果人设是不喜欢吃辣的,那么这种Response需要尽可能的去掉。更多详情可参考原论文。
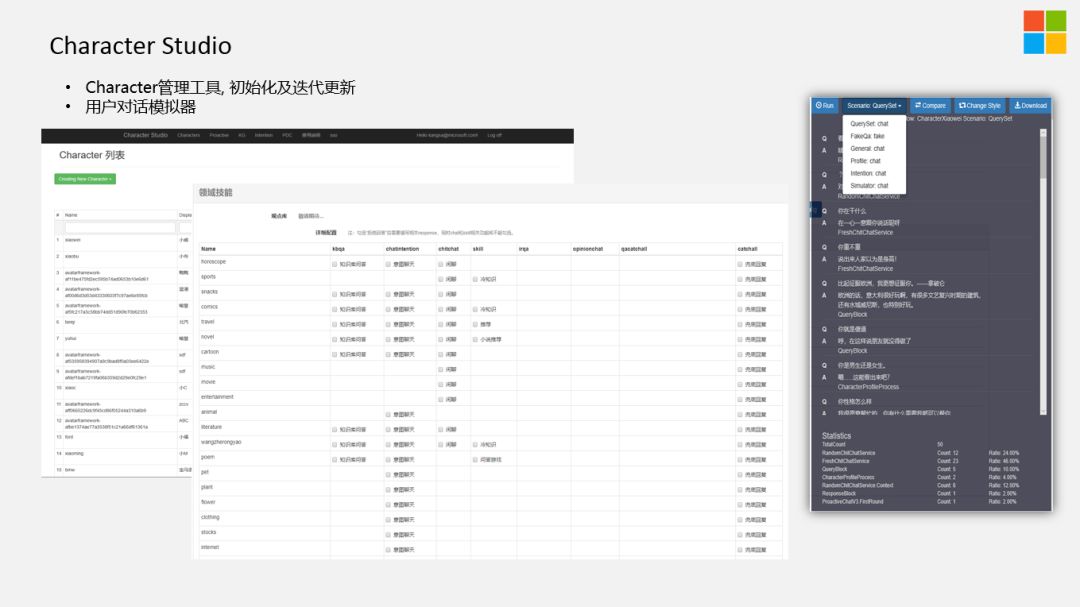
Character Studio主要是用来管理AI beings的存储。简单提下我们的用户模拟器:
对话系统是一个比较复杂的过程,如果依靠人的力量做交互,是一个不太合理的方法,所以我们开发了一个对话模拟器。在里边有两个bot,一个是真实的Character bot,一个是Policy bot,Policy bot会利用共感模型等方法,分析当前的状态,来模拟用户控制对话的节奏,我们会对打造的AI beings的各种回复进行打分,哪些模块覆盖到了,哪些模块没有覆盖到。通过模拟器,我们可以非常快速的校验不同IP的Chatbot做的好不好,每个模块会有自己恒定的指标,可以检测出每个模块的具体情况。
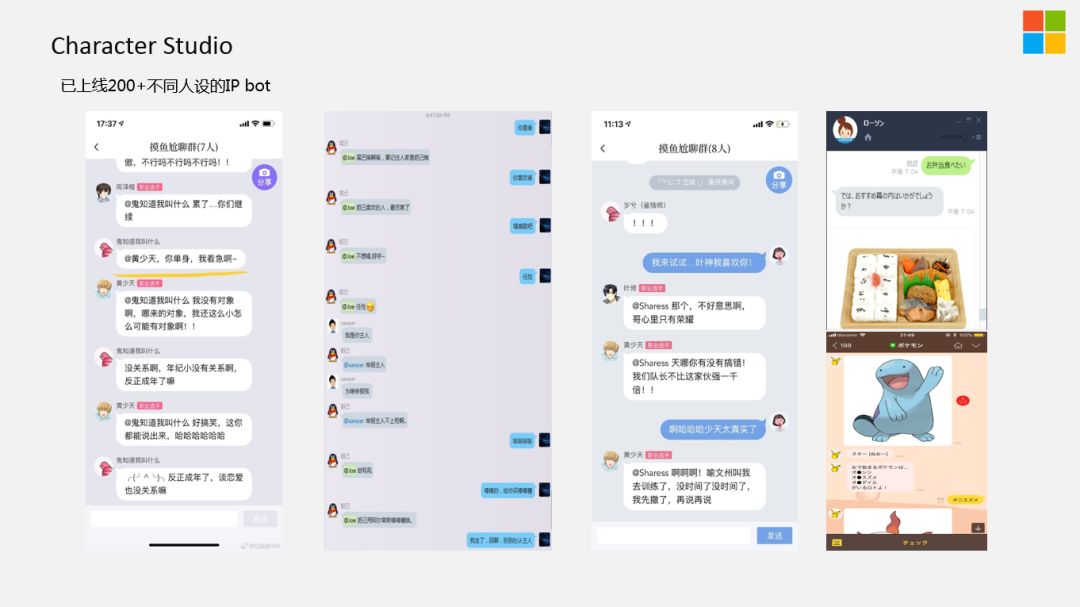
目前,我们已经上线了200+不同IP的Chatbot,如第二个,是"妲己"对话机器人,是我们跟QQ一起合作的,妲己除了是历史人物,也是王者荣耀游戏中的角色。为了活跃整个游戏群的生态,我们就做了"妲己"对话机器人,把历史上的妲己跟游戏中的妲己叠加起来,既可以问和游戏中技能相关的问题,也可以聊历史中关于妲己的话题。
最右边,是我们在日本做的一个Case,在对话中做美食推荐。这个美食推荐,并不是用户想要什么,就给推荐什么,而是基于对话的节奏,尽可能的符合之前对话的过程。
今天的分享主要给大家站在业界的角度,展示了小冰的产品设计思路,基础的对话系统设计,以及如何打造具有人格化的对话系统,由于时间关系,很多模块没有展开分析。在实践当中有太多难题等着我们去攻克,这是一项非常有挑战性的工作,希望能看到业内更多的小伙伴加入到这条战线当中来
,谢谢大家。
欢迎加入DataFunTalk NLP技术交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信(微信号:DataFunTalker),回复:NLP,逃课儿会自动拉你进群。
分享嘉宾
▬
曾敏
微软 | 高级技术总监
——END——
DataFunTalk
专注于大数据、人工智能技术应用的分享与交流。发起于2017.12,至今已在全国7个数据智能企业和人才聚集的城市( 北京、上海、深圳、杭州等)举办超过100场线下技术分享和数场千人规模的行业论坛及峰会,邀请300余位工业界专家和50位知名学者参与分享,30000+从业者参与线下交流。合作企业包括BATTMDJ等知名互联网公司和数据智能方向的独角兽公司,旗下DataFunTalk公众号共生产原创文章300+,百万+阅读,5万+精准粉丝。
注:
左侧关
注"社区小助手"加入各种技术交流群,右侧关注"DataFunTalk"公众号最新干货文章不错过👇👇
一个在看,一段时光!👇