深度学习中,面对不可知攻击,如何才能做到防御「有的放矢」?
机器之心分析师网络
作者:仵冀颖
编辑:H4O
本文作者通过三篇论文从不同角度探讨了深度学习中的攻击不可知的防御措施,并得出结论:虽然研究人员努力做到「攻击不可知的」防御,但攻击方式的思想不同、结构不同、应用方法/模型不同,确实也无法做到彻底的防御「不可知攻击」,相同的模型在不同的场景/攻击策略下的效果还是有所差别。
0 引言
近年来,深度学习(Deep Learning,DL)技术取得了突飞猛进的发展,在一些人工智能任务(如图像分类、语音识别等)中取得了突破。互联网巨头,如谷歌、Facebook 和亚马逊,都在提供由 DL 驱动的服务和产品方面进行了大量投资[1]。然而,高度非线性、非凸函数建模的深度神经网络(Deep neural networks,DNNs)本质上非常容易受到对抗性输入(Adversarial inputs)的影响。对抗性输入是由对手(攻击者)设计的恶意样本,目的是触发 DNNs 的不当行为。
图 1 给出了一个攻击示例:DNN 可以正确识别两张原始图像。但在对原始图像进行几个像素的变化处理后,使用同一个 DNN 无法正确分类处理后的对抗性图像,尽管人眼几乎看不出这些对抗性图像和原始图像的差别。防御对抗性输入攻击的根本挑战来自于它们的适应性和可变性:这些攻击是为目标 DNN 量身定做的,防御措施因具体的攻击而大不相同。

图 1. (a)(c)原始图像输入 -- 都能够正确识别;(b)(d)对抗性输入 --(b)被误判为 "70mph",(d)被误判为 "30 mph"[1]
现有的解决方案主要是提高 DNN 对特定攻击的弹性。然而,一旦部署这种静态防御措施,攻击者往往可以通过适应性的工程输入或新的攻击变体来规避静态防御措施。例如,训练数据增强措施(Training data augmentation mechanism)建议基于对抗性输入训练 DNN,由此生成的模型往往对已知的攻击过度拟合,从而更容易受到未见过的变种攻击的影响。此外,还有一些解决方案需要对 DNN 架构或训练程序进行重大修改,这往往会影响 DNN 模型的分类准确度。事实上,一些理论探索已经证实了 DNN 鲁棒性和表现力之间的内在权衡、制约,这极大地阻碍了在一些准确性敏感的领域中应用现有的防御措施[2]。
本文关注另外一类针对深度学习的防御措施研究方向:攻击不可知的(Attack-Agnostic)防御机制,即防御目标不是提高深度学习模型 / 网络针对特定攻击的鲁棒性,而是建立一种攻击不可知的防御机制,对攻击做出最小假设,并随时适应其可变的性质。本文选择了三篇近期发表的研究论文对这一问题进行具体分析。其中,第一篇文章对目前主要的攻击方法进行了详细介绍,揭露了现有防御措施对对抗性输入攻击的局限性,同时提出了一种针对对抗性输入攻击的防御方法:EagleEye。第二篇文章提出了一种针对数据污染攻击的攻击不可知的防御措施 De-Pois。第三篇文章讨论的是联邦学习架构中的攻击不可知的防御措施。
EagleEye:一种针对对抗性输入的攻击不可知的防御方法, Technical Report, 2018 [1]
De-Pois:针对数据污染攻击的攻击不可知的防御措施, IEEE Transactions on Information Forensics and Security, 2021, [4]
Siren:基于主动报警的拜占庭鲁棒联邦学习, ACM SoCC 2021 [13]
1、EagleEye:一种针对对抗性输入的攻击不可知的防御方法[1]

本文提出了一个用于深度学习系统的攻击不可知的对抗性篡改分析引擎:EagleEye。EagleEye 利用了许多攻击所依据的最小化原则,即,为了最大限度地提高攻击的规避性,对手通常会做到尽可能小的失真,以将真正的输入转化为对抗性的输入。本文的工作主要包括两部分:(1)介绍目前主要的攻击方法,揭露了现有防御措施对对抗性输入攻击的局限性。(2)提出一种新的保护深度学习系统免受对抗性输入攻击的防御方法:EagleEye。作者通过经验和分析表明,通过引入 EagleEye,能够使得与真实输入相比,对抗性输入 "更接近" 输入流形空间中由 DNN 诱导的分类边界。利用这些特性,EagleEye 可以有效地分辨出对抗性输入,甚至发现其正确的分类输出。此外,作者还研究了对手通过放弃最小化原则可能采取的对策,这对于对手来说导致其进入了一个困境:为了逃避 EagleEye 的检测,会导致过度的失真,从而大大降低了该攻击相对于其他检测机制(例如人类视觉)的逃避性。
1. 1 主要攻击方法
对于一个 DNN:f,攻击者(对手)的目的是提供一个虚假的输入来触发 f 的错误行为。给定一个 f 能够正确分类的真实输入 x,对手通过以不明显的振幅(例如几个像素)扰动 x,生成一个对抗性的 x_ϵ。x 和 x_ϵ之间的差(r=x_ϵ-x)称为扰动向量(perturbation vector (PV))。作者考虑了两种攻击情况。在无目标攻击(untargeted attack)中,对手只想迫使 f 错误地分类。在有针对性的攻击(targeted attack)中,攻击者的目的是产生一个特定的目标产出。
1.1 .1 线性工艺攻击(Linear Crafting attacks)
线性攻击类通过线性近似估计扭曲不同输入成分对 f 的输出的影响,并找到使目标输出 o_ϵ的概率最大化的 PV:r。接下来我们详细介绍两个有代表性的攻击模型。
Goodfellow 攻击(Goodfellow’s Attack)。这是第一个线性攻击模型,它计算损失函数ℓ相对于输入 x 的梯度,并将 r 确定为增加目标输出 o_ϵ概率的方向上的梯度符号步骤。
黄氏攻击(Huang’s Attack)。这是另一个线性攻击模型,它是在对 softmax 层(即 DNN 模型的最后一层)的输出进行线性近似的基础上构建的(见图 2)。
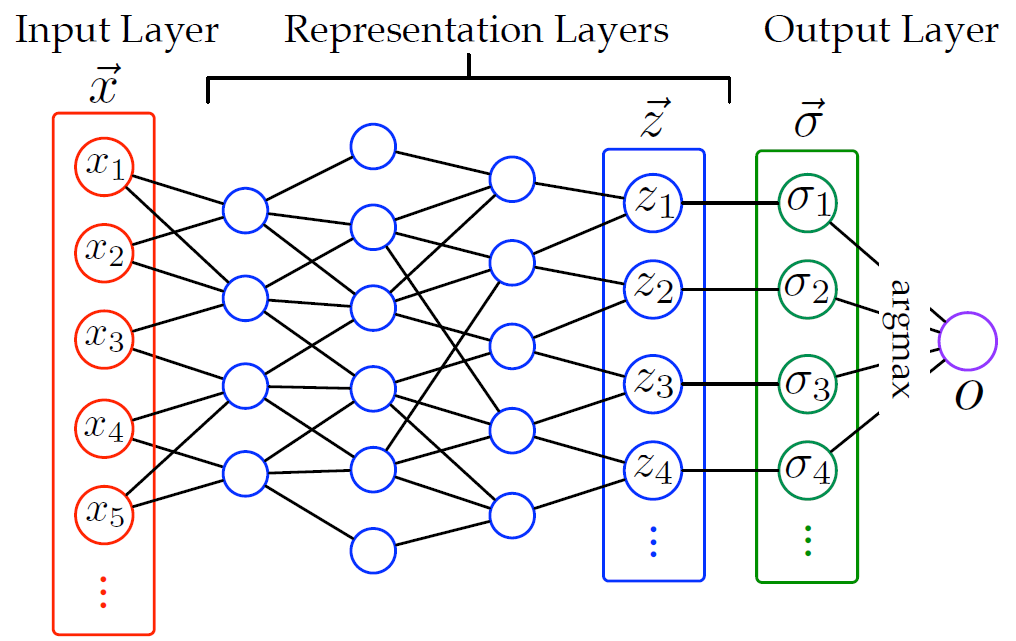
图 2. DNN 模型图示
1.1.2 非线性工艺攻击(Nonlinear Crafting attacks)
在线性攻击中,PV 是在一次尝试中找到的。相比之下,非线性攻击以迭代方式构建 PV。在每一轮中,对手估计每个输入组件对分类输出的影响,然后选择几个组件进行扰动,并检查更新的输入是否导致目标错误分类。接下来我们详细介绍两个有代表性的非线性攻击。
Papernot 攻击。这种攻击的形式是一张指导 crafting 过程的地图,这个地图描述了每个输入组件对输出的影响。
Carlini 攻击(Carlini’s Attack)。
与 Papernot 攻击相比,Carlini 攻击有两点不同:(1)为了补偿防御性蒸馏(defensive distillation,DD)造成的梯度消失[3],将 softmax 层的输入放大τ倍,其中τ是防御性蒸馏使用的 "温度"。(2)将输入组件的 saliency value 定义为 |α - β |,而不是(-α · β)。
防御性蒸馏(DD)是一种应用于防御训练的蒸馏变体。蒸馏(Distillation)是一种训练过程,使用从不同的 DNN 迁移的知识来训练 DNN,通过将知识从较大的架构迁移到较小的架构来降低 DNN 架构的计算复杂性。防御性蒸馏是指使用从 DNN 中提取的知识来提高其自身对对抗性样本的复原力,这与在不同的架构之间迁移知识的蒸馏方法是不同的。蒸馏法提取关于训练点的额外知识,作为 DNN 生成的类别概率向量反馈到训练方案中。蒸馏法通过降低分类器模型对输入扰动的敏感性,以生成更平滑的分类器模型。这些更平滑的 DNN 分类器对对抗性样本具有更强的适应性,并具有更好的类别泛化特性。
1.1.3 线性与非线性攻击对比
线性攻击只需要计算一次梯度或 Jacobian,而非线性攻击往往涉及多轮梯度或 Jacobian 的计算。鉴于其效率优势,可以利用线性攻击生成大量的对抗性输入。现有的线性攻击往往通过 PV 的 l_∞-norm 来衡量失真幅度,而非线性攻击则处理的是 PV 的 l_1-norm 或 l_2-norm。
1.2 主要防御措施
对于任何 “近似” 输入 x 和 x_ϵ(即 || x_ϵ-x|| 非常小),如果 DNN f 是稳定的,则有 f(x)和 f(x_ϵ)相似。因此,主要防御措施的思路都是提高 DNN 的稳定性。
数据增强(Data Augmentation)。这类方法通过主动生成一组对抗性输入并将其纳入训练过程,以提高 DNN 的稳定性。
稳健优化(Robust Optimization)。这类方法通过直接改变 DNN 的目标函数来提高其稳定性。
模型迁移(Model Transfer)。在该方法中,通过将 teacher DNN f 的知识迁移至 student DNN f′,以提高模型的稳定性。
1.3 现有防御措施的性能比较
接下来,作者根据经验评估现有防御解决措施对各种攻击的有效性。作者表示,这项评估是迄今为止对一系列攻击和防御模型进行的最全面的研究。现有的防御系统本质上都是静态的。尽管它们通过不同方式来提高对特定攻击的防御能力,但一旦训练和部署完毕,所得到的模型就无法再去适应先验未知的攻击。因此,对手(攻击者)可以通过利用目标 DNN 的新漏洞生成输入来规避此类静态防御措施。
1.3.1 对比实验设置
数据集和 DNN 模型。为了保证实验中所展示的不同任务中攻击漏洞的普遍性,作者在对比实验中使用了三个基准数据集:MNIST、Cifar10 和 Svhn,这些数据集都被广泛用于评估图像分类算法。作者还考虑了三种不同的 DNN 体系结构,并将它们分别应用于上述数据集中。具体来说,作者分别使用卷积神经网络(convolutional neural network, CNN)、最大输出网络(maxout network,Mxn)和网络中网络(network-in-network,Nin)模型对 MNIST、Cifar10 和 Svhn 数据集进行分类。
攻击和防御。作者实现了第 1.1 章节中介绍的所有攻击模型,为简洁起见,分别记作 G-、H-、P - 和 C - 攻击。此外,作者从第 1.2 章节中介绍的每个防御类别中选择一个代表性解决方案具体实施。由于数据增强是 Attack-specific 的,作者将结果模型分别记作 G-、H-、P - 和 C - 训练的 DNN。由于鲁棒优化是范数特定的,作者在 l_∞-norm 和 l_1-norm 两种情况下训练鲁棒 DNN。
1.3.2 “No Free Lunch”
表 1 总结了原始 DNN 模型(CNN、Mxn、Nin)和防御增强 DNN 模型相对于基准数据集的分类准确度。其中,原始模型的准确度(即 99.5%、85.2%、95.2%)接近最先进水平。相比之下,他们的大多数防御增强型变体中训练得到的模型分类准确度显著下降。因此,作者得出结论,提高防御措施的有效性不是“免费午餐”(No Free Lunch),通常是以牺牲分类准确度为代价的。

表 1. 原始和防御增强 DNN 模型相对于基准数据集的分类准确度
1.3.3 “No Silver Bullet”
接下来,作者评估了不同 DNN 模型抵御攻击的表现。表 2 给出了原始和防御增强型 DNN 模型对对手输入攻击的抵抗能力实验结果,其中对每种情况下的最成功的攻击进行加粗展示。对于原始的 DNN 模型来说,大多数的攻击策略(尤其是 P - 和 C - 攻击)都取得了近乎完美的攻击成功率,这意味着 DNN 模型中普遍是存在漏洞的,无法有效抵御攻击。数据增强方法显著提高了 DNN 对线性攻击的抵抗能力。对于 G 训练的 CNN,G 攻击成功率下降到 6% 以下。然而,对于更复杂的 DNN 或非线性攻击,它的效果要差得多。针对数据增强的 Mxn 和 Nin,P 攻击和 C 攻击都取得了近乎完美的攻击成功率。作者分析,这是因为数据增强只能捕获简单的线性扰动,而用于非线性攻击和复杂 DNN 模型的 PVs 空间要大得多。此外,通过在训练的每一步都考虑最坏情况的输入,鲁棒优化方法对线性攻击具有更强的抵抗能力。模型迁移是唯一能够有效抵御非线性攻击的方法。与 CNN 相比,P - 攻击的成功率下降到 1%。C - 攻击旨在消除梯度消失效应,因此能够完全穿透防御蒸馏的保护。
由上述实验结果作者得出结论:现有的防御措施都“没有银弹”(No Silver Bullet)。虽然它们能够提高 DNN 对特定攻击的防御能力,但生成的模型无法适应新的攻击变体。因此,迫切需要引入攻击不可知的防御措施。
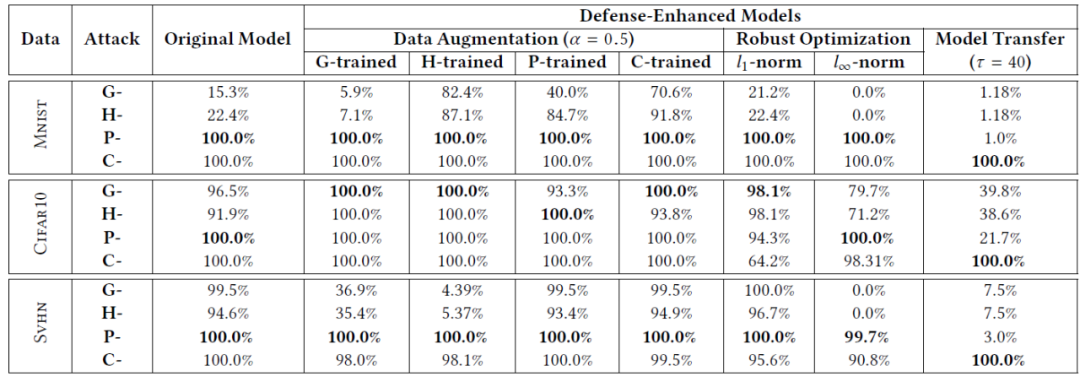
表 2. 原始 DNN 和防御增强型 DNN 模型对对手输入攻击的抵抗能力
1.4 利用 EagleEye 进行防御
与我们在前文中介绍的解决方案相比,EagleEye 采取了一种全新的方式:它尝试区分对手的输入;对于可疑情况,EagleEye 能够推断其正确的分类输出。因此,EagleEye 提供了比现有防御措施更丰富的诊断信息。如图 3 所示,在实际场景中可以将 EagleEye 部署为 DL 系统中的辅助模块,从而确保它对分类任务的干扰最小(1)。对于给定的输入 x(2)和 DNN(3),EagleEye 提供了按需对抗性篡改分析:(i) 它首先运行完整性检查,以评估 x 被恶意篡改的可能性;(ii)如果可疑,则进一步执行真值恢复以推断 x 的正确分类。最后,将分析结果与 DNN 分类相结合形成一份综合报告,供系统操作员决策(4)。显然,EagleEye 的设计满足了完整 DNN 模型的要求。
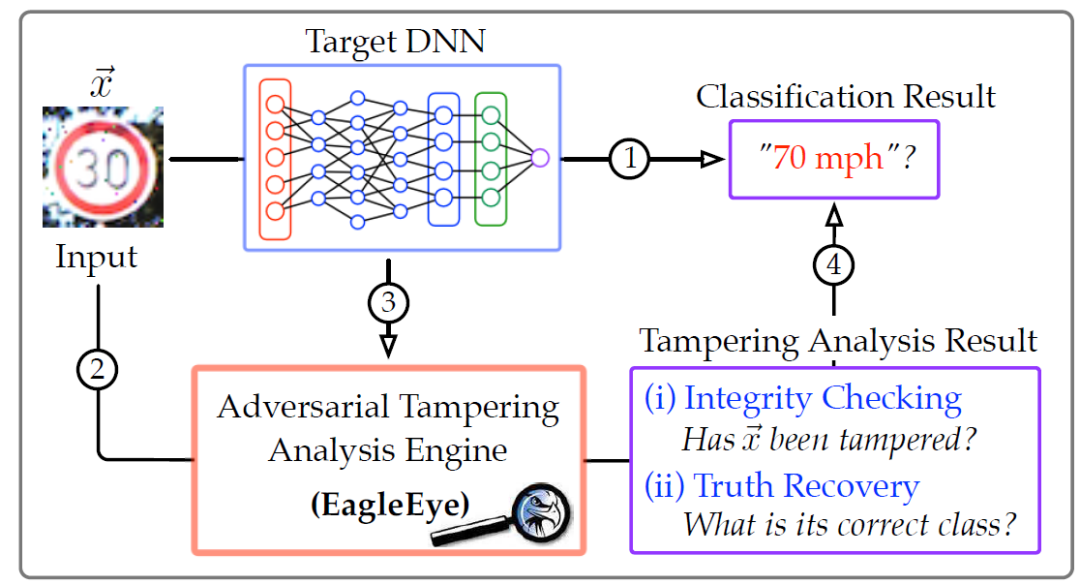
图 3. EagleEye 应用示例
1.4.1 最小化原则
作者构建攻击不可知的防御措施的基本依据是大多数攻击模型采用的最小化原则,即为了最大限度地提高攻击的规避性,对手在将真正的输入转化为对抗性的输入时,往往尝试造成尽可能小的失真。
定义 4.1(最小化原则)。给定目标 DNN:f、真实输入 x 和对抗性输出 o_ϵ,可以将攻击表征为解决一个优化问题,即:
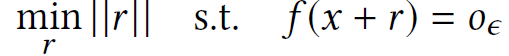
为了方便理解这一原则的内涵,作者介绍了几个关键概念(见图 4)。
定义 4.2(边界)。DNN f 将输入空间划分为不重叠的区域,f 将每个区域的输入划归入同一类别,相邻区域由边界分开。
定义 4.3(路径)。对于给定的输入 x、x_ϵ,x_ϵ=x+r,PV r 编码了从 x 到 x_ϵ的路径,其长度定义为 r 的数值大小:||r||。
定义 4.4(半径)。一个输入 x 到它在另一个类别 o_ϵ中的最近邻居 x_ϵ的路径长度称为 x 到类别 o_ϵ的半径,用ρ(x, o_ϵ)表示。
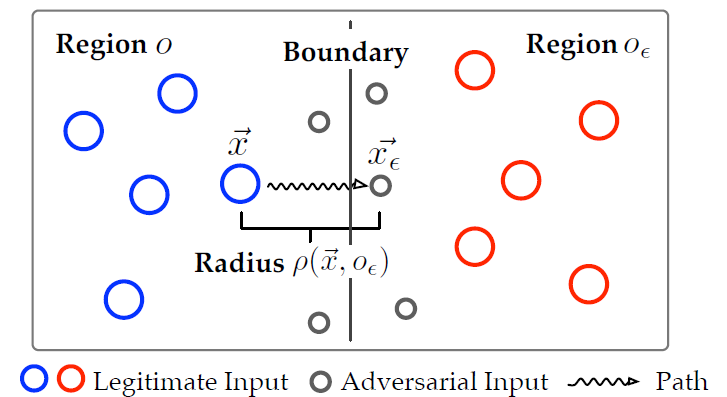
图 4. 边界、路径和半径的概念
然后,我们用边界、路径和半径语言来定义最小化原则:给定一个真正的输入 x,在目标类别 o_ϵ的所有可能的(对抗性)输入中,对手寻找的 x_ϵ为从 x 出发路径长度最短的 x_ϵ。因此,最小化原则包含了以下重要的属性:
属性 1:x 到 x_ϵ的路径长度近似于 x 到 o_ϵ的半径ρ(x, o_ϵ);
属性 2:x_ϵ倾向于分布在极其接近 o 和 o_ϵ的边界。
给定一个真正的输入 x(在类别 o 中)和一个由攻击 A 产生的对抗输入 x_ϵ(在类别 o_ϵ中),我们找到 x 在类别 o_ϵ中最接近的真正对应物 x∗(例如,满足 ||x-x∗|| 最小的 x∗)。然后计算 x 与 x_ϵ的距离之比:||x - xϵ ||/|x - x∗||。
图 5 显示了在 CIFAR10 上这种比率与 P - 和 C - 攻击的累积分布(在其他数据集和攻击上的结果类似)。我们可以看到,大多数比率值位于 [0, 0.01] 的区间内,与攻击无关。这表明 x 在 o_ϵ中与其最近的对抗性邻居比其真正的对应方更接近。因此,||x -x_ϵ|| 将 x 的半径近似为 o_ϵ。
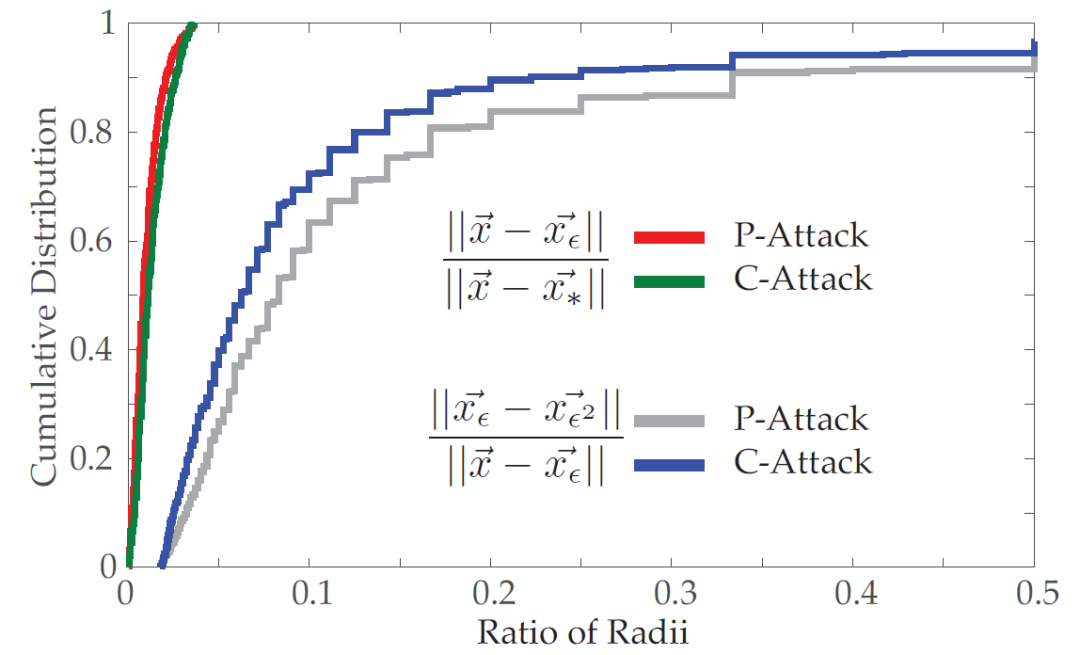
图 5. 输入 x 的最短距离与对手和真实输入之比的累积分布(在 Svhn 数据集上)
1.4.2 构建 EagleEye
上节介绍的特性为我们构建一个有效的区分器来识别对抗性输入提供了假设前提:对于一个给定的输入 x(被 f 分类为 o),我们测量它对所有其他类别的半径,在其中找到最小的一个:min o_ϵ≠o ρ(x, o_ϵ),称为其对抗性半径(adversarial radius, AR)。有了属性 1 和 2,我们就可以通过检查它们的 AR 来区分真正的输入和对手的输入。
然而,为了实现这个想法,我们还面临两个主要挑战。首先,半径指标是特定于攻击的,例如,G - 攻击和 P - 攻击的测量方式是不同的。直接测量半径最多只能对特定攻击有效。第二,即使对于已知的攻击,找到一个最佳的阈值也是很困难的;即使存在,它也往往会随着具体的数据集和 DNN 模型的不同而变化。
为了解决第一个挑战,作者提出了对抗性半径探测(adversarial radius probing,ARP)方法。ARP 是一种攻击中立(attack-neutral)的方法,可以间接近似 AR。具体来说,它采用了半随机扰动的方式,通过计算能够改变 x 分类输出所需的最小失真幅度确定为输入 x 的 AR。为了解决第二个挑战,作者采用了一种引导方法来避免调参。具体来说,对于给定的输入 x,通过半随机扰动方式生成一组影子输入 {x_ϵ}。通过比较 x 和{x_ϵ } 的探测结果来估计 x 被恶意破坏的可能性。如果可疑,则通过分析 {x_ϵ } 的共识,进一步推断 x 的正确分类输出。
EagleEye 的完整框架如图 6 所示。
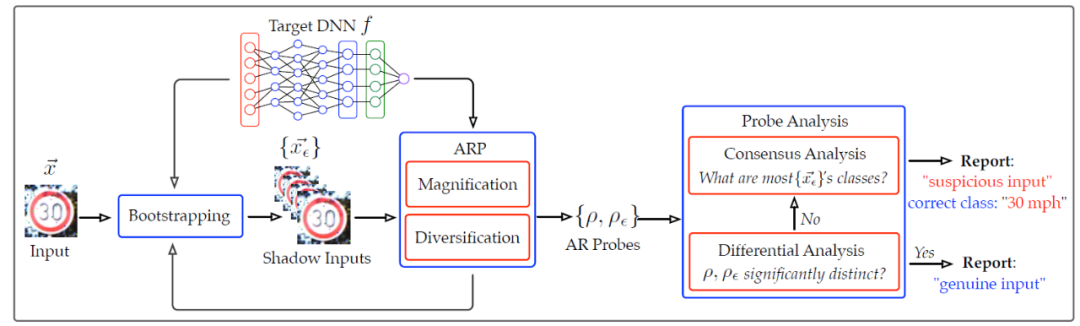
图 6. EagleEye 结构图。它通过对手半径分析来区分对手输入;对于可疑的输入,它进一步尝试发现其正确的分类输出
1.4.2.1 对抗性半径探测
通过对给定输入 x 执行随机扰动,EagleEye 估计了改变其分类结果所需的最小失真幅度。即,x 的探针(用ρ(x)表示)以攻击中立的方式(attack-neutral manner)表征其 AR。然而,考虑到ρ(x)的高维特性,通过对其所有分量进行随机扰动来估计ρ(x)通常是不可行的。因此,作者引入一种半随机扰动方法:(i)放大—EagleEye 首先动态识别 x 上的一组 saliency 区域,这些区域能够最大程度地影响其分类结果;(ii)多样化—EagleEye 在这些区域上执行随机扰动以估计ρ(x)。
放大。这一处理方式的出发点是人类的视觉会自动聚焦在 “高分辨率” 图像的某些区域,同时以 “低分辨率” 的方式感知周围区域。
对于给定的输入 x,定义一组 d×d 空间区域(在本文的实现中取值 d=4)。通过在 x 上应用大小为 d×d 的恒等核来生成 x 的所有可能区域,这种处理方式类似于卷积运算。为了选择对 x 分类影响最大的前 n 个 saliency 区域,作者采用贪婪计算方法。根据 x 的 saliency 程度(例如,其梯度或 Jacobian 值)按照降序对 x 的分量进行排序。区域π的 saliency 是π中包含的所有分量所贡献的 saliency 的聚合:
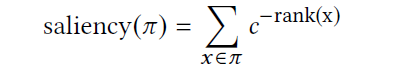
其中,c 为常量。根据此定义,我们可以控制选定区域的特征。对于较大的 c,我们关注覆盖最具影响力成分的区域;而对于较小的 c(即接近 1),我们找到包含影响力较小的成分的区域。平衡这两个因素的基本原理如下:当 x 被扰动为 x_ϵ时,saliency landscape 发生变化;由于 DNN 固有的连续性,这些变化往往是局部的。所以,通过适当设置 c 就可以适应这种变化,并且仍然能够捕获 x_ϵ中最有影响力的成分。
我们迭代选择前 n 个区域。设 R_i 为第 i 次迭代后的选定区域。通过移除 R_i 的区域中包含成分的贡献来更新每个剩余区域的 saliency:
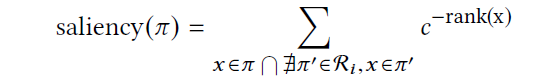
然后,我们选择剩余区域中 saliency 最大的区域。
多样化。在这一步骤中,给定 x 的 saliency 区域 R,对 R 执行随机扰动以估计 x 的探针ρ(x)。令π表征 R 区域中包含的成分集合。在每次运行中,按照预定义的分布 p(参数θ),随机选择π中的一个成分子集来构造扰动向量 r。将θ初始化为均匀分布,并假设翻转扰动为:将输入成分设置为 fully-on (‘1’)或 fully-off (‘1’)。因此,失真幅度可以通过 p 的采样率θ来测量。作者分析,这种初始化处理的优势在于(i)有效识别对手输入;(ii)易于控制。此外,均匀分布的较大熵增加了对手逃避检测的难度。
1.4.2.2 引导操作
通过随机扰动输入 x,引导操作生成一组对手输入{x_ϵ},我们称之为 x 的影子输入(shadow inputs)。直观地说,这样的影子输入代表 x 在其他类别中的近邻对手。为了生成{x_ϵ},作者采用了与节 1.4.2.1 相同的半随机扰动策略,只是将采样率固定为θ∗。这种做法能够确保生成的影子输入尽可能接近 x,也有助于识别 x 的正确分类(如果 x 是对抗性的)。
1.4.2.3 探测分析
通过分析输入 x 及其影子输入 {x_ϵ} 的探针,EagleEye 确定 x 被恶意篡改的可能性(差异性分析),并尝试恢复正确的分类结果(一致性分析)。
差异性分析。{x_ϵ}代表 x 在其他类别中的近邻对手。因此,如果 x 本身是对抗性的,那么可以将 x 和 x_ϵ视为彼此的对抗性样本,因此具有类似的 ARs。如果 x 是一个真正的输入,那么 x 和 {x_ϵ} 的 ARs 倾向于显示出显著的差异(见图 5)。在差异性分析中,作者正是利用这一特点,检查 x 的探针和每个影子输入 x_ϵ。给定 x_ϵ,x_ϵ为真的可能性为:
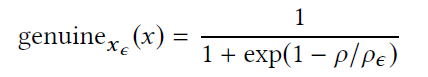
其中,sigmoid 函数将ρ/ρ_ϵ转换至 (0,1) 的区间,我们可以粗略地将其解释为 x 为真的“概率”。通过将所有输入的结果相加,计算得到 x 为真的总体可能性。
一致性分析。如图 6 所示,如果 x 通过了差异性分析,则报告为 “真”;否则,它将被视为“可疑” 实例并进入一致性分析阶段,而一致性分析阶段推断 x 正确的分类输出。由真实输入(类别 o_ϵ)创建的对抗性输入 x(类别 o)位于 o 和 o_ϵ的边界附近。因此,在其他类别的近邻中,大多数应该属于类别 o。通过利用这一观察,我们只需选择与影子输入 {x_ϵ} 关联的最常见类别作为 x 的最可能的正确分类输出。
1.5 对 EagleEye 的分析
进一步,作者将对抗半径分析(adversarial radius analysis,ARA)、DNN 的普遍性(DNN generalizability)和学习理论联系起来。此外,作者还讨论了对手可能采取的规避 EagleEye 的对策,即,如何应对不遵守最小化原则的对手。
1.5.1 半径分析的有效性
ARA 的假设前提是:与对手相比,真实输入倾向于具有更大的对抗半径。下面作者提供了针对该属性的理论基础。
从对抗性输入 x_ϵ的角度来看,攻击者 A 通过扰动真实输入 x 来生成 x_ϵ。A 本质上是为了解决优化问题而设计的:
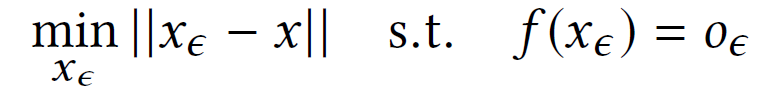
其中,|| x_ϵ− x || 表征扰动幅度。假设 A 利用 t 扰动序列扰动 x,r(i)表示第 i 次迭代结束时的扰动向量。最小化原则意味着 A 只有在第 t 次迭代后才能实现所需的错误分类:
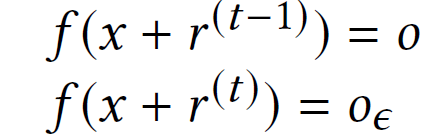
因此,(x+r^(t−1))和 (x+r^(t)) 表示位于 o 和 o_ϵ的类别边界之间的两个输入。还应注意,r^(t−1) 和 r^(t)的区别仅在于几个成分,这取决于 A 的具体实现。
接下来,作者从真实输入 x 的角度解释 ARA 的有效性。如果 x 被 DNN f 以高置信度分类为类别 o,则其由 f 引起的类别边界半径必须相当大。为了进一步验证这一问题,作者引入了关于分类置信度和 ARA 之间关系的统计学习理论。
定义 5.1(置信度)。输入 - 输出对 (x,o)(即 f 将 x 分类为 o)的分类置信度通过 f(x) 中最大和第二大概率的差值(例如 softmax 输出)来测量。
定理。 给定 DNN f 和真实输入 x,W^(l)是 f 的第 l 层的权重矩阵,x 的 AR 有以下界:
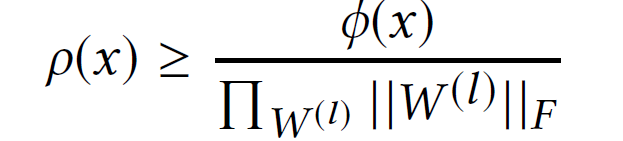
其中 ||·|| _F 表示 Frobenius 范数。由上述分析作者表示,高置信度只是大 ARs 的一个充分条件,提高 DNN 的分类置信度有助于识别对手输入。
1.5.2 对手困境
由于 EagleEye 是建立在各种攻击模型下的最小化原则之上的,因此规避其检测的一种可能方法是在进行对抗性干扰时(部分)放弃这一原则。
令 r(i)表征第 i 次迭代结束时的扰动向量,假设对手在第 t 次迭代后已经满足了所需的误分类要求:f(x+r^(t)=o_ϵ。对手没有停止而是继续扰动 x 以增加其 AR:ρ(x_ϵ)。即使在理想情况下,对手也需要至少扰动ρ(x)输入成分,从而产生 2·ρ(x)的近似扰动幅度。直观地说,如果随机选择 x,那么 2·ρ(x)的数值表示两个真实输入的距离,而在真实数据集中,不同输入的差异甚至对人眼来说也是相当容易辨别的。此外,由于 DNN 的高度非线性,额外的扰动振幅通常比这个下限大得多。
上述分析揭示了对手面临的一个难题:她希望保留对手输入的 AR 以逃避 EagleEye 的检测。为此,她被迫引入额外的扰动,以将一个真实输入转换为另一个很容易辨别出的伪输入。而这种处理显著降低了攻击对其他检测机制(例如人类的视觉能力)的躲避能力。
1.6 实验分析
首先,作者证明了 EagleEye 能够以攻击不可知的方式准确检测对手输入。作者在实验中使用的测试集如下:首先从每个数据集中随机抽取 5000 个输入从而得到真正的输入池。然后,将所有攻击应用于每个真实输入以生成其对手版本。这些成功构建的实例构成了对手输入池。由于对手攻击的成功率很高(见表 2),真正的攻击池和对手攻击池相当平衡。作者应用 EagleEye 检测对手输入,并使用以下指标衡量其性能:
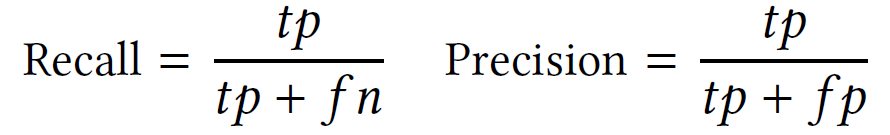
其中,tp、fp 和 fn 分别表示真阳性、假阳性和假阴性实例的数量(对抗性:+,真实性:-)。
表 3 总结了 EagleEye 在基准数据集上抵御各种攻击的性能。EagleEye 为 DNN 提供了通用的、攻击不可知的保护:在所有情况下,EagleEye 都实现了高准确度(87% 以上)和召回率(94% 以上),表明其对对手输入的强大鉴别能力。此外,在所有这些情况下,EagleEye 的召回率略高于准确率。我们假设这些假阳性实例是真实输入,分类置信度较低,而在最简单的 MNIST 数据集中,大多数输入具有相当高的置信度得分,从而导致其最低的假阳性率。
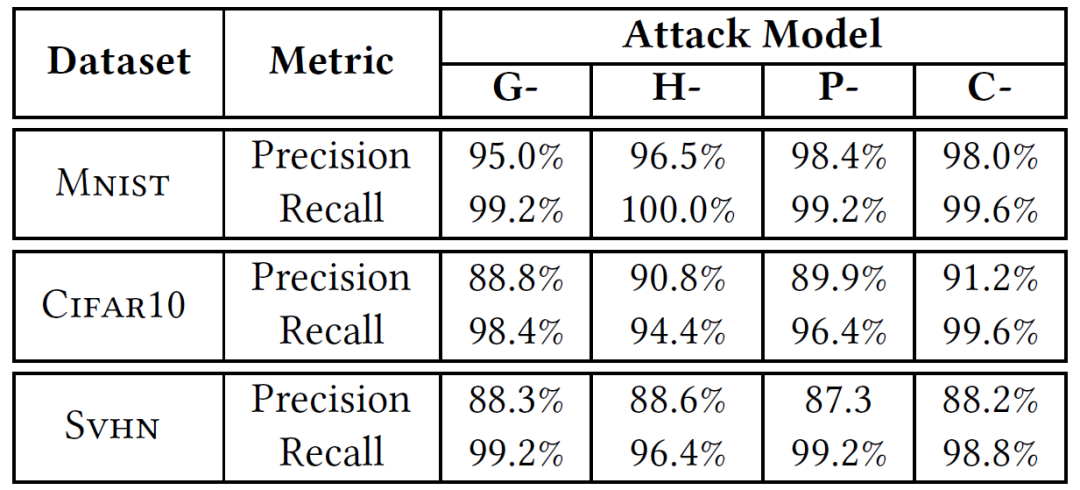
表 3. 针对不同基准数据集和攻击模型的 EagleEye 检测准确度
接下来,我们讨论对手可能采取的规避 EagleEye 检测的对策及其影响。EagleEye 的理论基础是各种对抗性输入攻击的最小化原则。因此,为了躲避 EagleEye 的检测,对手的一个最直观的选择是放弃这一原则,即,对手不再尝试尽可能小的失真,而是试图找到一个能够导致更大 ARs 的次优的扰动向量。作者首先研究在给定扰动幅度下无法达到期望 AR 的情况,对于 P - 和 C - 攻击,扰动幅度增加到 448,对于 G - 和 H - 攻击,扰动幅度增加到 1。表 4 列出了每个数据集上对手输入的失败率。例如,即使通过将失真幅度增加四倍,超过 40% 的输入也无法实现与 CIFAR10 上真正对应的 ARs 相当的 ARs。这可以解释为,由于 DNN 的高度非线性、非凸性,对抗性输入的 AR 也是失真幅度的非线性函数。因此,仅增加振幅不一定会得到期望的 AR。
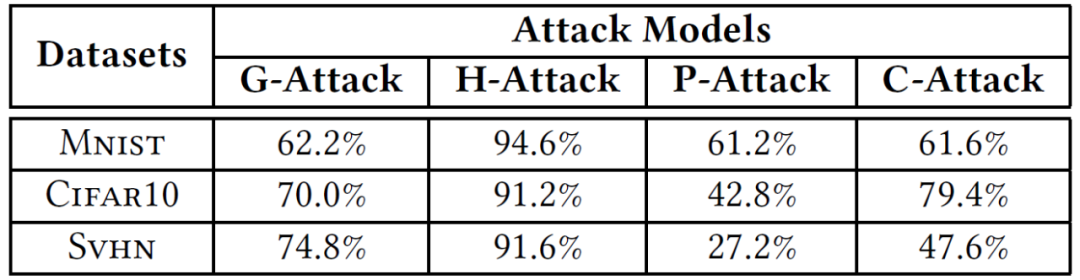
表 4. 针对基准数据集和攻击,对手输入达到理想 ARs 的失败率
EagleEye 的一个优点是它对现有系统 / 方法的影响最小(由图 6 中 EagleEye 完整架构图可见)。这一特点使其非常容易与其他防御机制进行整合,而整合后的系统往往会产生协同效应。在这组实验中,作者通过研究在防御蒸馏(defensive distillation,DD)之上应用 EagleEye 来验证这一假设[3]。回顾表 2 所示,虽然 DD 对 G、H 和 P 攻击有效,但它容易受到自适应设计的攻击的影响(例如 C 攻击)。首先,作者考虑 DD 能够成功防御的对手输入。对原始 DNN 应用 P 攻击,并收集通过原始 DNN 但由 DD 防御的所有对手输入。对于该类别中的每个对抗性输入 x_ϵ,DD 识别其正确的类别,但不知道 x_ϵ是对抗性的。表 5 的第一行列出了 EagleEye 将此类实例检测为对抗性实例的准确度。第二,作者考虑穿透 DD 保护的对抗性输入。对防御的 DNN 应用 C 攻击,并收集所有成功生成的对手输入。表 5 列出了 EagleEye 将此类实例视为对抗性实例的准确度。
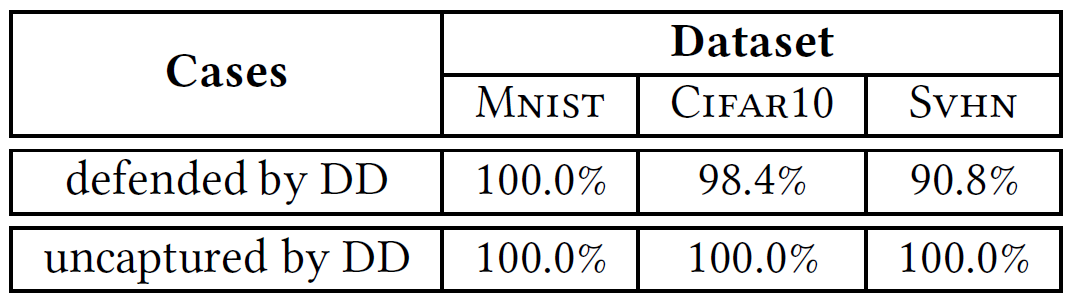
表 5. EagleEye 针对防御蒸馏(DD)防御 / 未捕获的敌对输入的准确性
作者在文章最后分析到,EagleEye 的一个局限性是其有效性在某种程度上取决于 DNN 的通用性水平。因此,作者认为,提高 DNN 通用性的研究与对抗性输入的防御机制的研究相辅相成,这也是作者的研究团队正在开展的研究,以提高 EagleEye 对模糊输入和弱 DNN 的有效性。
2、De-Pois:针对数据污染攻击的攻击不可知的防御措施[4]

这篇文章聚焦的是数据污染攻击(Data Poisoning Attacks)。数据污染攻击是指攻击者(对手)通过向训练数据集注入一部分恶意样本来破坏机器学习的性能。这类攻击可能会对各种安全关键领域构成严重风险,如自动驾驶汽车、生物识别身份和计算机视觉。为了应对数据污染攻击,研究人员已经提出了多种防御措施。然而,这些防御措施在很大程度上都是针对特定攻击的:它们是为一种特定类型的攻击而设计的,但对其他类型的攻击可能效果不佳,这主要是由于它们遵循的原则不同。
本文提出了De-Pois—一种防御污染攻击的攻击不可知方法。De-Pois 的基本思想是:攻击者注入污染样本(Poisoned samples)以操纵由清洁样本(Clean samples)训练的目标模型的决策边界,而且污染样本和清洁样本的特征空间之间存在差异。因此,De-Pois 的关键思想是训练一个模仿模型,该模仿模型能够模仿目标模型的行为。通过比较模仿模型和目标模型之间的预测差异,可以直接区分出污染样本和清洁样本。
虽然 De-Pois 的基本想法很简单,但有两个问题需要解决。第一是如何为模仿模型获得足够的有效训练数据。在许多实际场景中,特别是在用户提供的数据系统中,只能从可信的数据源获得极有限的清洁数据。第二是如何训练模仿模型使其能够达到与目标模型相当的预测性能。目标模型的结构或超参数是事先未知的。
为了应对上述挑战,De-Pois 在生成对抗网络(GAN)的基础上加入了两项新的设计:合成数据生成和模仿模型构建。具体来说,De-Pois 改进条件 GAN(conditional GAN,cGAN)[5],以更好地理解清洁数据的基本分布,从而可以从一小部分可信的清洁数据中生成数量足够的有效训练数据。作者进一步引入条件 Wasserstein GAN 梯度惩罚(Wasserstein GAN gradient penalty,WGAN-GP)[6]来学习增强的训练数据的预测分布,产生一个与目标模型具有相似预测功能的模仿模型。通过这种方式,De-Pois 最终可以采用模仿模型,通过比较模仿模型的输出和正确确定的检测边界之间的差异来识别检测样本中的污染数据。
2.1 De-Pois 设计
我们将本文研究的问题表述如下:对于一个包含潜在的污染数据集 Sp 和清洁数据集 Sc 的训练数据集 So,De-Pois 旨在在给定少量的(可信的)清洁数据 St 的情况下确定一个样本 s 是否在 Sp 中。De-Pois 依赖于这样的观点:污染样本比清洁样本更有可能有不同的预测。因此,De-Pois 通过估计它们的预测差异来利用具有与 Sc 训练的目标模型类似的预测行为的模仿模型测试出污染样本。De-Pois 主要包括三个步骤(参见图 7)。
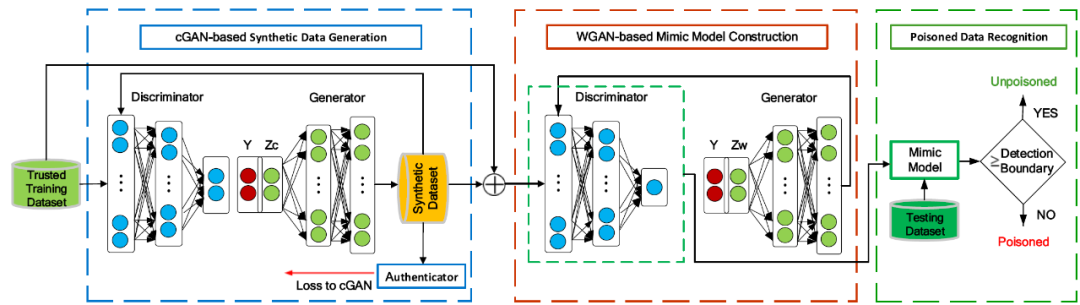
图 7. De-Pois 的框架包含三个部分:基于 cGAN 的合成数据生成、基于 WGAN 的模仿模型构建和污染数据识别
合成数据的生成。De-Pois 的第一步是生成具有类似 Sc 分布的足够的合成训练数据。为了更好地理解 Sc 的基本分布,De-Pois 利用 cGAN 来生成数据,并设计了一个验证器来监督数据增强处理过程。
模仿模型的构建。在获得足够的有效数据后,De-Pois 通过条件 WGAN-GP 来学习增强的训练数据的预测分布,从而建立模仿模型。当条件 WGAN-GP 训练完成后,将其判别器确定为模仿模型。
污染数据的识别。考虑到模仿模型,De-Pois 可以采用一个检测边界区分污染样本与清洁样本。如果模仿模型的输出低于预先确定的检测边界,那么该样本就被认为是污染数据。
2.1.1 合成数据的生成
合成数据生成模块由两部分组成:一个基于 cGAN 的生成器和一个验证器。
1)基于 cGAN 的生成器。原始 GAN 包含两个神经网络:生成器(G)和鉴别器(D)。其中,G 学习生成合成样本 G(z),从先验噪声分布 z 中捕捉训练数据 P_data(x)的分布。D 学习从 G(z)中区分真实数据样本 x。GAN 同时学习 G 和 D,以实现以下最小 - 最大目标:
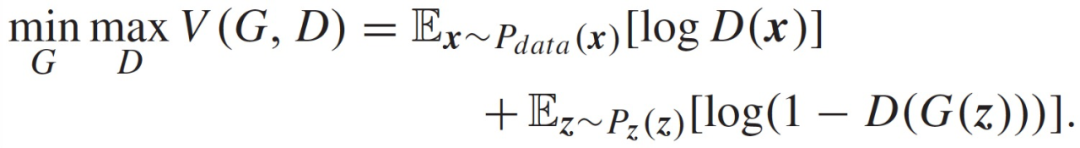
我们注意到,在原始的 GAN 中,没有对生成数据的模式(pattern)进行控制。在这种无条件的生成模型中,GAN 指导数据生成过程是无效的。因此,作者考虑通过使 G 以额外的信息(如类别标签)为条件,即构建 cGAN 引入随机噪声向量 z_c 和条件约束(如类别标签或其他模式)来训练模型,以合成新的训练样本。
为了利用 cGAN 的优势,作者提出将额外信息 y 输入 cGAN 的生成器和判别器(即 Gc 和 Dc),并以监督的方式生成以 y 为条件的样本。需要注意的是,对于回归任务来说向回归值 y 加入一个加性单模态噪声 z_r(如高斯噪声)是有条件的,需要尽可能地覆盖整个输出集合。目标函数如下:
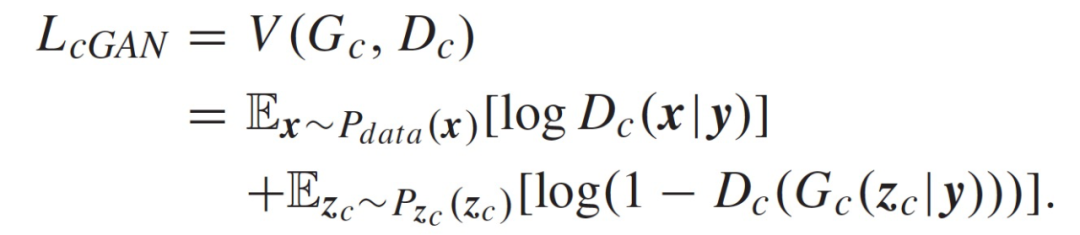
2)验证器。直观地说,cGAN 可以生成足够的数据。然而,生成的数据通常具有较差的多样性表达,这主要是由于输送到 Gc 的是单一分布(如高斯分布),并且不确定 cGAN 是否能够在低容量数据场景中生成保真度高和具备充足多样性的数据。为了得到更多有效的训练数据,作者引入了一个验证器来监督 cGAN 的数据增强过程。将 Gc 在每个迭代中产生的这些新合成的样本视为位于训练数据空间中的缺失潜变量的实例。然后,计算验证器的预测输出与每个合成样本的真实类别标签或回归值之间的损失 L_A。最后,将损失 L_A 反向传播到 cGAN 部分,Dc 的损失为 L_cGAN+ L_A。
针对不同的污染攻击任务(例如分类、回归),验证器通过不同方式计算损失 L_A。在分类任务中,将验证器设计成一个卷积神经网络(CNN)。我们首先得到验证器的输出ˆy,然后用交叉熵误差函数来计算分类的损失,其公式为:
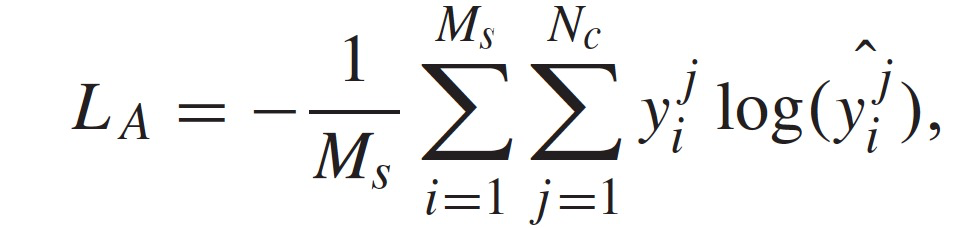
其中,^(y_i)^j 表征第 i 个样本属于第 j 个类别的预测概率,N_c 为类别总数,M_s 为每轮合成样本的数目。如果第 i 个样本的标签属于第 j 个类别,则(y_i)^j=1;否则(y_i)^j=0。
在回归任务中,验证器要求使用特定的回归模块(如 LASSO),可以由下式使用每个合成样本的均方误差(MSE)来计算损失:
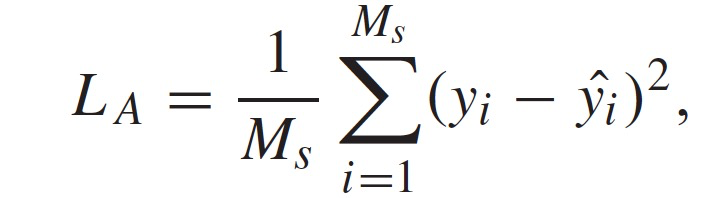
其中,y_i 代表第 i 个样本的回归值,^y_i 是每个迭代中第 i 个样本的验证器的预测值。通过这种方式,验证器鼓励更好地区分真实数据和生成的数据,从而可以加强数据增强过程。
3)合成数据的生成。合成数据生成的 cGAN 训练过程包括两个部分:对于判别部分,使用可信的清洁样本 St 作为其输入,目的是最小化 L_cGAN+L_A。对于生成部分,结合噪声先验 z_c 和附加信息 y 作为其输入,目的是使 L_cGAN-L_A 最小。在合成数据生成过程中,这两部分以对抗性的方式进行优化。
为了确定基于 cGAN 的合成数据生成过程中的参数,作者使用蒙特卡罗期望最大化(Monte Carlo Expectation Maximization,MCEM)方法并迭代运行。首先,使用蒙特卡罗(Monte Carlo,MC)根据上一次迭代的估计结果估计模型参数的值,然后在每次迭代中使用随机梯度下降(Stochastic gradient decent,SGD)更新这些参数。在期望最大化(expectation-maximization,EM)算法中,使用可信的清洁数据 St 来估计合成数据生成模型的参数,该数据对应于给定的数据 s=(x,y),其中,x 表示数据样本,y 表示真实标签(或回归值),Nt=|St|。训练过程可以形式化为以下优化问题:
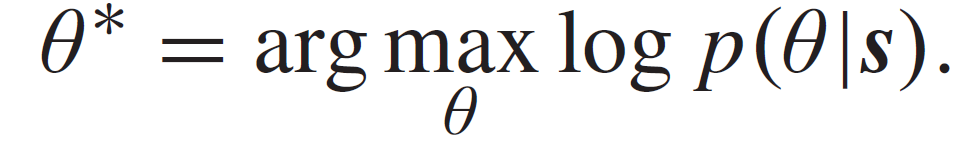
在缺乏先验和似然函数等信息的情况下,我们无法直接计算后验概率 p(θ | s)。因此,作者使用合成数据扩充训练数据。可以使用潜在变量 z_s=(x_s,y_s)表示合成数据,其中 x_s 表示合成数据,y_s 表示对应的类别标签(或回归值)。给定 s 和 z_s,我们可以在 E-step 的第 i 次迭代中估计增强后验 p(θ | s, z_s):
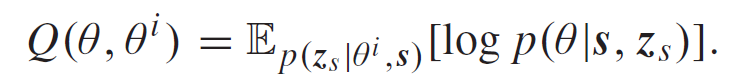
然后,M-step 在下一次迭代中最大化 Q 函数:
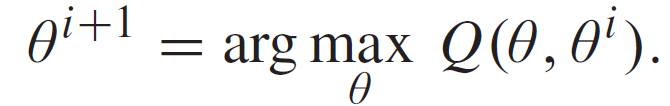
当满足 ||θ^(i+1)-θ^i || 足够小时,可以从上一次迭代中获取最优θ值 。
进一步采用 MC 策略,该策略使用重复随机抽样来近似 E-step 中的积分。此外,在 M-step 中,我们通过运行 SGD 来更新θ^( i+1),SGD 在每次迭代中仅使用一个子集的可信清洁数据和扩充数据,并且最终可以获得预期的合成数据生成模型,从而生成具有类似 Sc 分布的足够的合成训练数据 Ss。
我们的目标是获得增强数据 S_aug,以满足 | S_aug |=| St |+| Ss’ | 与 | So | 相当。在本文实验中,在大多数情况下,| Ss |>|S_aug |。因此作者随机选择 Ss 的一个子集作为 Ss’。
2.1.2 模仿模型的构建
在得到 S_aug 后,De Pois 的下一步目标是构建与目标模型具有相似预测性能的模仿模型。如果在 S_aug 上训练的模仿模型的预测输出与目标模型的预测输出无法区分,则可以将模仿模型视为与目标模型在功能上等价。
简单地使用 GAN 构建模仿模型似乎是可行的。然而,作者发现原始 GAN 存在训练不稳定的问题,这主要是由于最小化 Jensen-Shannon(JS)散度时生成器参数的不连续性所造成的。因此,作者提出了一种条件 WGAN-GP,使 WGAN-GP 的生成器和鉴别器部分都以附加信息 y 为条件。通过这种方式,可以以有监督的方式更好地构建模仿模型。
在 WGAN-GP 范式中,训练的不稳定性问题是通过对其判别器网络的随机样本的权重范数进行惩罚来解决的。通过这种处理方式,能够使其满足 Lipschitz 约束,以及将梯度惩罚直接加入到 Wasserstein 距离中。具体的目标函数如下:
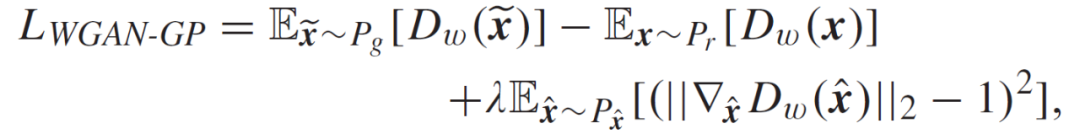
其中,最后一项为对梯度范数的惩罚项。P_r 和 P_g 分别代表真实和生成的数据分布。P_ˆx 表示从 P_r 和 P_g 中抽出的均匀抽样分布。WGAN-GP 模型提供了一个更稳定的训练环境。然而,如前所述,在无条件生成模型下,它也存在数据生成过程效率低下的问题。此外,深度学习模型可能导致在有限数据情况下的训练过拟合。通过在 WGAN-GP 设置中引入额外的信息,作者将 Y 输入到 Gw 和 Dw 中,从而能够以监督方式更好地模仿目标模型。由此,本文提出的结合 WGAN-GP 和 cGAN 的模仿模型的目标函数可以修改为:
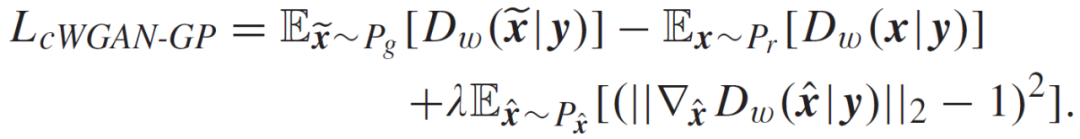
在模仿模型的训练过程中,交替优化 Dw 和 Gw。经过充分训练当两部分的目标都收敛后,就完成了模仿模型的构建,并将 Dw 视为预期的模仿模型。
2.1.3 污染数据识别
利用模仿模型,De-Pois 可以直接找出污染样本:只需设置一个检测边界,然后比较模仿模型的输出和检测边界之间的数值。如果输出值低于检测边界,则认为该样本污染;否则,该样本未污染。更具体地说,在分类和回归任务的背景下,将每个样本 x 送入模仿模型,输出其预测值 y_pre。
在模仿模型中,y_pre 代表生成的样本和真实样本之间的 Wasserstein 距离。一般来说,清洁样本的预测值 y_pre 要比污染样本的预测值大。因此,只要有适当的检测边界,就可以从清洁样本中识别出污染的样本。由于在工程实践中我们不能事先知道清洁样本 Sc,而一般会将增强样本 S_aug 的分布设计成与 Sc 相似,因此作者利用 S_aug 来确定检测边界。可以看出,S_aug 根据 Dw 的预测值的分布(表示为 P_Saug)几乎符合正态分布。因此,作者判断在不知道污染样本的情况下,只用 S_aug 来确定检测边界是可行的。
为了正确确定检测边界,首先要获得 P_Saug 的均值μ和标准偏差σ。然后,通过对 Dw 的测试样本的预测值的标准化处理来计算 z-scores(表示为 P_Stest )。然后我们可以获得对应于 N 个测试样本的 N 个 z-scores,从而区分不同均值和标准偏差的 P_Stest 的差异。作者将单边置信区间高于 z_s 的测试样本视为清洁样本,然后通过查询标准正态分布表来确定对应的 z_s 值。最后,我们可以建立检测边界 y_thr = z_s x σ+ μ,并将其与样本的预测值 y_pre 进行比较。如果满足下述不等式
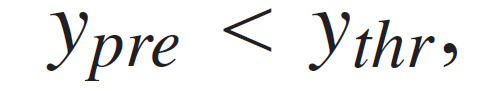
则将该样本视为污染样本。在测试了 So \ St 中的所有样本后,我们可以识别出污染数据,并将其进一步从 So 中排除。通过这种方式,可以将 De-Pois 作为在训练 ML 模型之前的过滤器来使用,从而保证训练后的模型不会受到污染样本的影响。
2.2 实验分析
为了验证 De-Pois 的有效性,作者使用四个不同领域的数据集进行实验,包括手写数字识别(MNIST)、图像分类(CIFAR-10)、非线性二值分类(Fourclass dataset)和房屋销售价格预测(House pricing dataset)。作者引入一些主流的 attack-specific 的防御措施与 De-Pois 进行性能比对,所采用的评价指标包括:准确度、召回率和 F1 分数。为了评估 De-Pois 合成数据生成的性能,作者采用以下指标:Inception Score(IS)、Fréchet Inception Distance(FID)、Wasserstein Distance(WD)和平均欧氏距离(Average Euclidean Distance,AED)。
对于合成数据生成,作者使用固定结构的 cGAN 来生成数据。在生成器网络 Gc 中,将具有 100 维正态分布和类别标签的噪声先验 z_c 或具有 128 个小批量大小的可信数据集的回归值 y 的组合确定为 Gc 最底层的输入。Gc 使用 3 个 Leaky ReLu 激活的全连接层和一个带 sigmoid 激活的全连接层。鉴别器网络 Dc 由 3 个全连接层和一个 sigmoid 单元层构成。在 Dc 的中间层应用 Dropout,Dropout 值设置为 0.4。在 Gc 和 Dc 中,Leaky ReLu 中的泄漏斜率均设置为 0.2。对于验证器,作者在分类任务中采用特定的分类器模块(即图像的 CNN),并使用交叉熵函数计算其损失。对于回归,验证器调用特定的回归模块(即 LASSO),并使用 MSE 计算损失。对于模仿模型构造,作者通过将类别标签或回归值 y(如 cGAN 中的 y)作为附加输入到 Gw 和 Dw 中来改进 WGAN-GP。将具有 100 维正态分布和类别标签的噪声先验 z_c 或最小批量大小为 32 的扩充数据集的回归值 y 的组合确定为 Gw 最底层的输入,在 Gw 和 Dw 中都使用全连接层和激活层。特别的,作者为图像添加了卷积层以获得更好的模仿模型。作者使用学习率等于 0.00005 的 RMSprop 优化器,当 Gw 迭代一次时,Dw 迭代 5 次。
2.2.1 合成数据生成的有效性
首先,作者通过比较两个模型的准确性、召回率和 F1 分数来评估合成数据生成的有效性:在 S_aug 上训练的增强模型和在与 S_aug 大小相同的清洁数据集上训练的基线模型。在每个数据集上使用 cGAN 和验证器体系结构对这两个模型进行训练,并使用训练好的鉴别器来评估性能。为了统一分类和回归数据集的指标,作者使用清洁样本和污染样本对这两个模型进行了测试。对于回归数据集,我们可以获得通过模型处理的结果,然后计算分类数据集的准确度、召回率和 F1 分数。
表 6 给出了 CIFAR-10 数据集上的 IS 和 FID 结果、通过合成数据生成模型获得的 Fourclass 和 House pricing 数据集上的 WD 和 AED 结果,以及真实数据和 cGAN 模型上基线的比较结果。从表 6 给出的实验结果可以看出,本文模型可以达到真实数据的性能,并且优于 cGAN 模型,作者分析,这表明使用验证器有助于生成足够的有效数据。
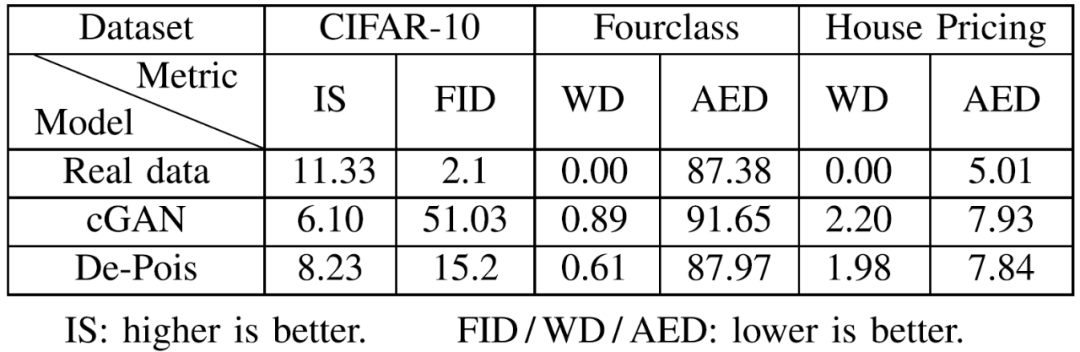
表 6. 合成数据生成的评价结果
2.2.2 清洁数据量的影响
为了评估 St 大小的影响,作者将 Rp 设置为固定值(例如,Rp=20%)进行实验。结果如表 7 所示,在不同攻击下,De Pois 的准确度、召回率和 F1 分数平均高于 0.9,并且随着 St 大小的增加波动小于 10%,从而验证了 De Pois 是攻击不可知的,并且对于分类和回归任务都是有效的。
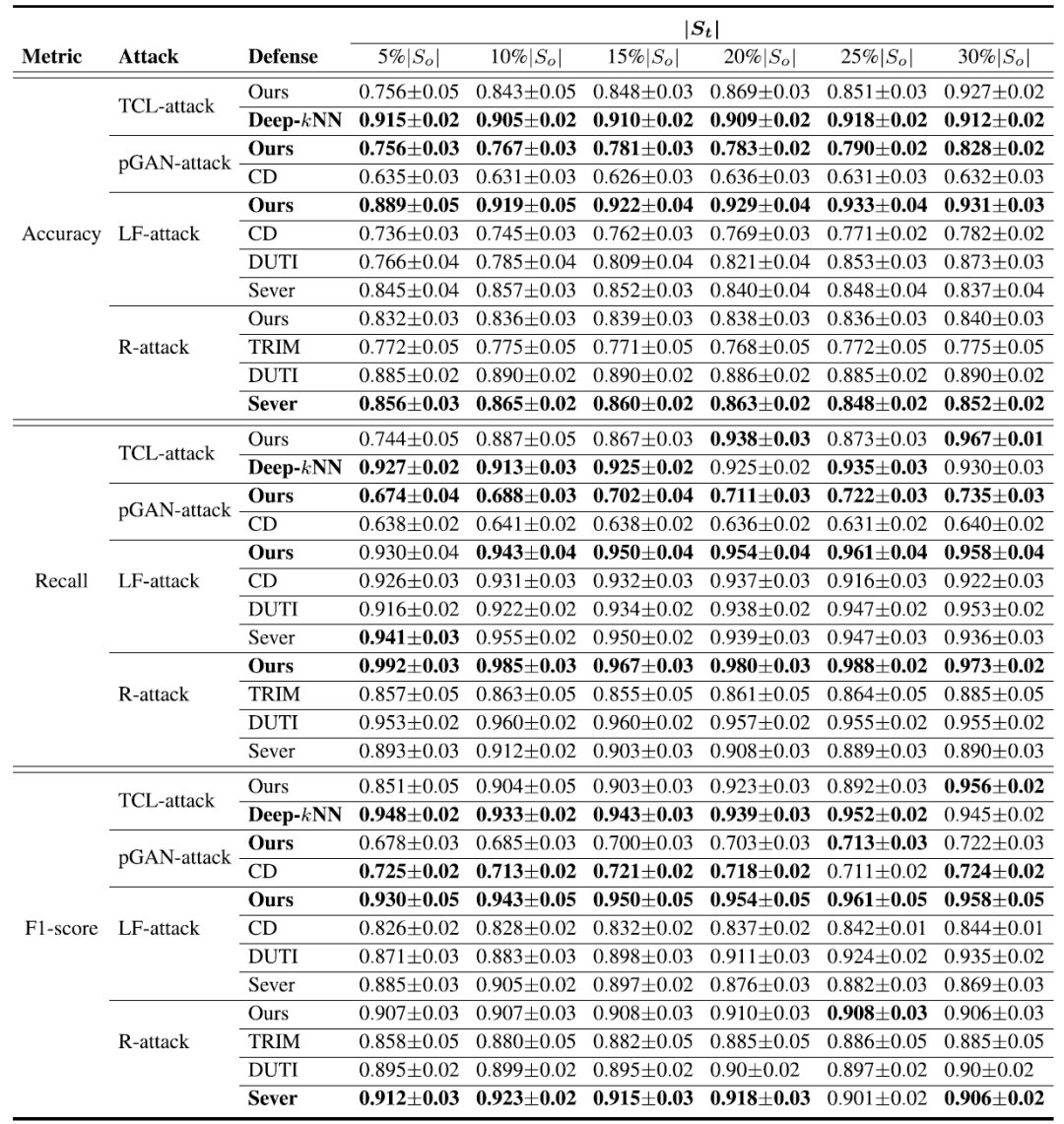
表 7. 固定污染率环境下准确度和 F1 评分的比较
2.2.3 De Pois 中不同组件的影响
作者评估了 De Pois 中不同组件的影响。作者将 De Pois 与其他三种不同的组合进行比较,即 cGAN+GAN、cGAN+cWGAN GP 和 cGAN_验证器 + GAN。在实验中,Rp=20%,| St |=20%| So |。结果如图 8 所示,本文提出的验证器在准确性、召回率和 F1 方面分别提高了至少 0.03、0.04 和 0.03。此外,本文提出的模仿模型构造部分在准确性、召回率和 F1 方面分别提高了至少 0.05、0.04 和 0.03。

图 8. De Pois 中不同组件的影响
3、Siren:基于主动报警的拜占庭鲁棒联邦学习 [13]

目前很多工作都是针对特定攻击进行防御,特别是在联邦学习(Federated Learning,FL)领域。但是在联邦学习的实际应用场景中,防御者并不能预先确定攻击者采用的是什么攻击方式,这就需要攻击不可知的防御措施了。与前几篇文章不同,这篇文章聚焦的是联邦学习的防御措施。
在联邦学习应用场景中,FL 通过松散连接的设备网络执行分布式机器学习,这些设备都是自主自发地参与训练过程,因此很难确定恶意客户端的具体数量。此外,客户端设备上的本地数据通常是非独立同分布的(Non-independent and identically distributed,Non-IID)。这些数据在参与的客户端设备之间的倾斜加剧了本地模型之间的差异,进一步混淆了恶意客户端和良性客户端之间的界限。因此,联邦学习很容易受到拜占庭式攻击:攻击者通过隐藏在联邦学习客户端之间的恶意客户端恶意更新模型,从而破坏联邦模型。
本文提出了一个拜占庭鲁棒的联邦学习系统 Siren,通过分析模型准确度和梯度协调客户端与 FL 服务器,以抵御 IID 和 Non-IID 数据上的各种攻击。作者设计了一个主动分布式报警系统,使客户端能够与 FL 服务器协作进行攻击检测。Siren 客户端保留一小部分本地数据集以测试全局模型的准确度并触发警报,FL 服务器联合分析客户端警报、模型权重更新和准确度以检测攻击。在分布式报警系统的基础上,作者提出了一个决策过程来检测恶意客户端并有效净化模型的聚合结果。
3.1 Siren 介绍
3.1.1 整体结构分析
在深度学习架构中,客户端和 FL 服务器之间的唯一通讯参数是权重更新,因此,恶意客户端只能通过修改这些权重更新来攻击全局模型。在这种情况下,大多数当前的只进行权重分析和只在服务器上部署防御措施的拜占庭鲁棒聚合规则使得 FL 系统极易受到攻击。
为了解决上述问题,本文提出了一种攻击不可知的防御方法 Siren。图 9 显示了 Siren 的整体结构。在客户端上有两个过程,即训练过程和报警过程。Siren 在每个客户端上保留本地数据集的一小部分作为本地测试数据。相比之下,在标准 FL 系统和使用其他聚合规则的系统中,客户端只执行一个训练过程。Siren 中的训练过程与标准 FL 中的训练过程相同,负责使用本地数据进行本地模型训练,而报警过程负责测试全局权重。在每一轮通信中,每个客户端上的报警过程都使用本地权重和本地测试数据集检查全局权重。如果客户端将全局权重视为污染权重,则会向 FL 服务器报警,FL 服务器会根据每个客户端的报警状态启动检测过程以排除恶意权重更新。
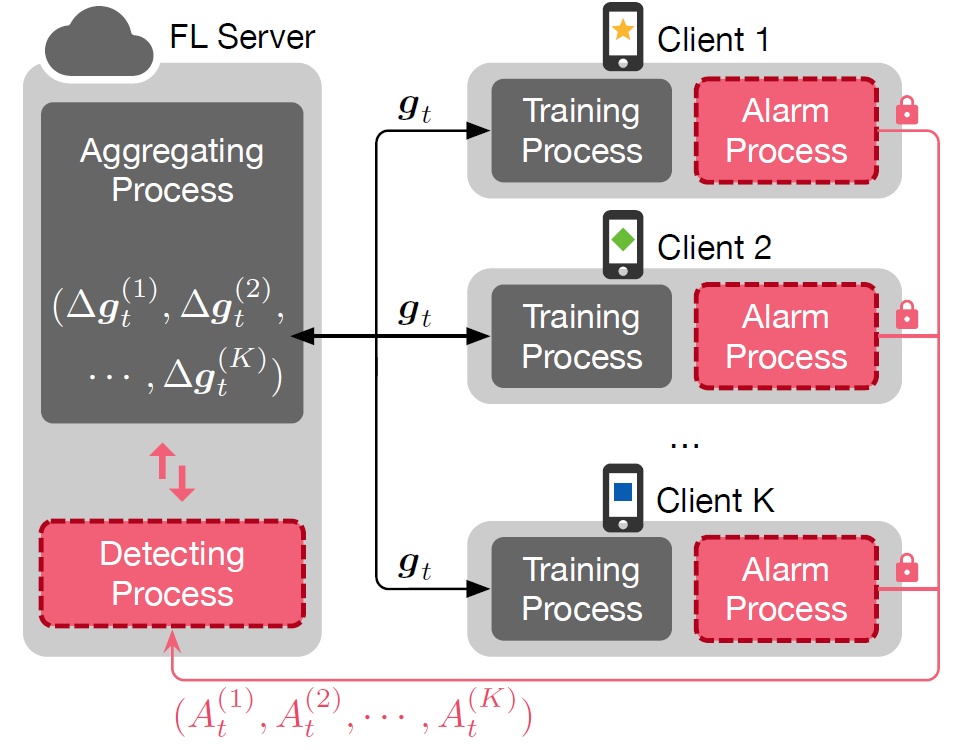
图 9. FL 架构。灰色块属于默认的 FL 组件,带点边框的红色块是 Siren 的组件
3.1.2 客户端侧分析
图 10 给出了 Siren 的客户端工作流程,即客户端执行报警流程以验证全局模型𝒈_𝑡是否污染,并在每一轮通信中向 FL 服务器上传报警状态 (𝐴_t)^(𝑖) 和模型权重更新Δ(𝒈_𝑡)^(𝑖)。Siren 要求每个客户端保留一个本地测试数据集和一份在上一轮生成的本地模型权重的副本。报警过程比较本地模型和全局模型在本地测试数据集上的准确度以证明全局模型是否可信,同时保证客户端可以在下一轮本地训练过程中使用该全局模型。
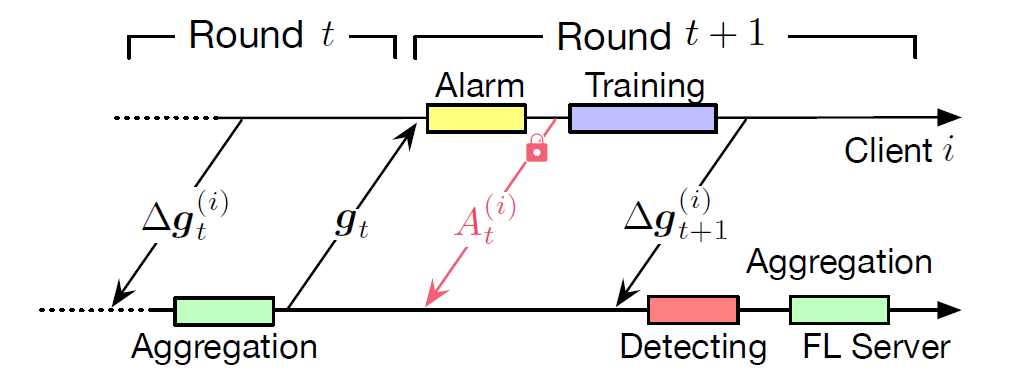
图 10、 Siren 客户端和 FL 服务器之间的交互说明
为了简单起见,我们用客户端𝑖来代表一个一般的参与客户端,它可能是恶意的,也可能是良性的。客户端算法的详细描述如下。
步骤 1:当第 (𝑡+1) 轮通信开始时,客户端𝑖收到 FL 服务器在上一轮(即第𝑡轮)通信中汇总的全局模型权重𝒈_𝑡。
步骤 2:与默认的 FedAvg 算法直接用全局模型𝒈_𝑡开始局部训练不同,每个 Siren 客户端首先启动报警程序,评估全局模型𝒈_𝑡和上一轮通信中训练的局部模型 (𝒈_t)^(𝑖)。全局模型𝒈_𝑡的准确度为𝜔_𝑡,局部模型(𝒈_t)^(𝑖) 的准确度为(𝜔_t)^(𝑖)。
步骤 3:为了论证全局模型𝒈_𝑡是否污染,报警过程进一步比较准确度𝜔_𝑡和 (𝜔_t)^(𝑖)。如果全局模型𝒈_𝑡比局部模型(𝒈_t)^(𝑖) 更准确,即𝜔_𝑡 - (𝜔_t)^(𝑖) ≥ 𝐶𝑐 ,其中𝐶𝑐 是预先定义的正阈值,则客户端𝑖在第 (𝑡 + 1) 轮通信训练中用𝒈_𝑡初始化本地模型𝒈^(𝑖)。客户端𝑖将报警状态 (A_t)^(𝑖) 设置为 0。相反,如果𝜔_𝑡 - (𝜔_t)^(𝑖) < 𝐶𝑐 ,由于全局模型的性能异常,则客户端𝑖用 (𝒈_t)^(𝑖) 而不是𝒈_𝑡初始化局部模型𝒈^(𝑖)。客户端𝑖将报警状态 (A_t)^(𝑖) 设置为 1。
步骤 4:客户端𝑖通过安全隧道(例如基于 Diffie-Hellman 算法的 IPsec 隧道)向 FL 服务器发送报警状态 (A_t)^(𝑖),这样可以防止报警状态在网络传输中被篡改。客户端𝑖通过在其本地数据上训练模型(𝒈_t)^(𝑖) 以获得新的模型 (𝒈_(t+1))^(𝑖),其中报警状态(A_t)^(𝑖) 决定了𝒈^(𝑖)在步骤 3 中是 (𝒈_t)^(𝑖) 或𝒈_𝑡。然后,客户端𝑖计算并发送本地权重更新Δ(𝒈_(t+1))^(𝑖) = (𝒈_(t+1))^(𝑖)- 𝒈_𝑡到 FL 服务器,并储存本地模型 (𝒈_(t+1))^(𝑖) 用于下一轮计算。
下面的 Algorithm 1 给出了上述客户端报警和训练过程的伪代码。这种客户端报警机制保证了污染的全局模型总是会触发良性的客户端报警。还应该注意的是,即使在模型没有污染的情况下,恶意的客户端也可以故意伪造警报来欺骗 FL 服务器。不过,Siren 能够识别来自 FL 服务器端的恶意客户端的这种报警。

3.1.3 服务器侧分析
由于联邦学习的固有脆弱性,FL 服务器既不相信本地模型的更新,也不相信任何参与客户端发出的警报。在汇总本地模型更新并像 FedAvg 那样更新全局模型之前,Siren 的 FL 服务器首先启动一个检测过程,分析警报状态并评估本地模型权重,以识别潜在的攻击。
在一个通信回合𝑡中,FL 服务器执行两个阶段的检测。1)检查前一轮聚合中生成的全局模型是否污染。2)测试在当前回合中收集的客户端模型更新是否污染。下面的步骤说明了 FL 服务器在每一轮通信中的两阶段检测过程。
步骤 1:在第 t 轮通信中,FL 服务器通过安全隧道从所有参与的客户端检索报警状态(A_t)^(𝑖),并收集客户端模型权重更新Δ(𝒈_(𝑡+1))^(𝑖),其中𝑖∈𝐾。
步骤 2:FL 服务器按照图 11 所示的决策过程分析所有客户端的报警。如果没有客户端报警,FL 服务器直接汇总来自客户端的模型权重更新并更新全局模型。然而,如果有任何报警,FL 服务器会进一步评估来自发出报警的客户端的模型更新{Δ(𝒈_(𝑡+1))^(𝑖) |𝑖 ∈𝑆𝑎}。其中𝑆𝑎⊆𝐾,𝑆𝑎是报警客户端的集合。

图 11. FL 服务器的决策过程。FL 服务器做出的决定以红色和斜体突出显示
步骤 3:FL 服务器使用 (𝒈_(𝑡+1))^(𝑖)= Δ(𝒈_(𝑡+1))^(𝑖) + 𝒈_𝑡恢复客户端模型权重,并使用根测试数据集(root test dataset)评估客户端模型(𝒈_(𝑡+1))^(𝑖) 是否污染以及客户端𝑖是否是恶意的,其中𝑖∈𝑆𝑎。如果在𝑆𝑎中没有发现恶意客户,FL 服务器将把模型权重评估扩展到所有参与的客户端。
步骤 4:FL 服务器在汇总模型权重更新时过滤掉被识别为污染的客户端模型更新,以更新第(𝑡-1)轮通信中的全局模型𝒈_(𝑡+1),而不是𝒈_𝑡,因为后者被识别为污染。因此,全局模型更新为:
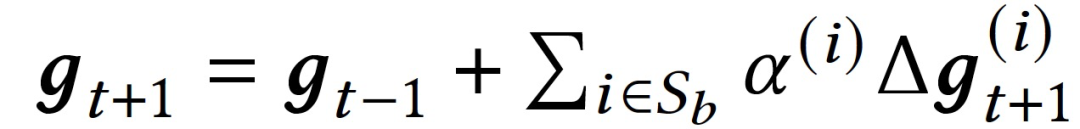
其中,𝑆𝑏是被识别为良性的客户端集合。
步骤 5:FL 服务器丢弃𝒈_𝑡,并将模型权重𝒈_(𝑡+1)复制到𝒈_𝑡中。在全局模型𝒈_𝑡被推送给所有客户端后,开始启动第 (𝑡) 轮通信。作者还在 FL 服务器上制作了黑名单,以排除已经被认定为恶意的客户端参与训练。
下述 Algorithm 2 展示了 FL 服务器的检测和聚合过程的伪代码。

3.1.4 决策过程和安全性分析
作者进一步对 FL 服务器的决策过程进行推理分析。如果 FL 服务器在第 t 轮收到 0 个警报,存在如图 18 所示的两种情况:情况 1 ,𝒈_𝑡没有污染,{Δ(𝒈_(𝑡+1))^(𝑖) |𝑖 ∈𝐾}都是良性更新。情况 2,𝒈_(𝑡-1)没有污染,但在 {Δ(𝒈_(𝑡+1))^(𝑖) |𝑖∈𝐾} 中存在污染的模型更新。如果𝒈_𝑡污染,只要有一个良性的客户端存在客户端报警机制就会保证激活报警。此外,情况 2 只发生在恶意客户端在第一轮被攻击的通信中对全局模型𝒈_1 发送污染信息时。良性客户端将通过比较全局模型和本地模型在下一轮通信中的准确度来检测这种污染的更新。因此,FL 服务器选择在没有报警时直接汇总模型更新。
当出现激活报警时,FL 服务器首先测试发出激活报警的客户端(即𝑖∈𝑆𝑎)中模型的准确性,并在其中寻找准确度最大的客户端 max{(𝜔_t)^(𝑖) |𝑖∈𝑆𝑎}。作者使用用户定义的阈值𝐶𝑠来衡量最大准确度和每个报警客户端的准确度之间的差异。报警客户端要么与情况 3 有相似的准确度,即∀𝑖∈𝑆𝑎,max{(𝜔_t)^(𝑖) |𝑖∈𝑆𝑎} -(𝜔_t)^(𝑖) < 𝐶𝑠 ,或者具有发散的准确度,即∃𝑖∈ 𝑆𝑎,max{(𝜔_t)^(𝑖) |𝑖∈ 𝑆𝑎}-(𝜔_t)^(𝑖) ≥ 𝐶𝑠作为情况 4(如图 11)。
对于情况 3,如果没有攻击—无论是全局模型𝒈_(𝑡-1)还是客户端更新 {Δ(𝒈_t)^(𝑖) |𝑖 ∈ 𝐾} 都没有污染,那么激活的报警一定是恶意客户端故意产生的假信号。如果存在攻击,而报警客户端的模型更新具有类似的准确度,则应该测试沉默客户端的模型更新,以进一步验证报警客户端的模型更新是全部污染还是全部良性。因此,对于情况 3,应该始终测试所有沉默客户端的模型更新{Δ(𝒈_t)^(𝑖)|𝑖∈𝑆𝑠 },其中𝑆𝑠是沉默客户端集合。如果沉默客户端的最高准确度接近或甚至优于报警客户端的最高准确度:
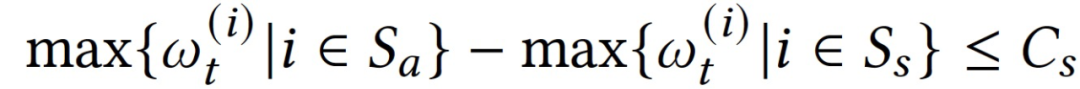
则 FL 服务器可以保证良性客户端是沉默的,因此,所有发出报警的客户端的更新都是污染的。如果一个沉默客户端的更新准确度接近所有沉默客户端的最大准确度,则认为这个客户端是良性的。因此,当一个沉默客户端的准确度符合 max{(𝜔_t)^(𝑖) |𝑖 ∈ 𝑠 }-(𝜔_t)^(𝑖) < 𝐶𝑠 ,其中𝑖 ∈ 𝑠 ,则将该沉默客户端加入良性客户端集合𝑆𝑏。由于所有的良性客户端都是沉默的,因此恶意客户端发出的报警是假报警,而上一轮得到的全局模型𝒈_𝑡并没有污染。
相反,对于情况 3,如果沉默客户端的最大准确度低于报警客户端的最大准确度:max{(𝜔_t)^(𝑖) |𝑖 ∈ 𝑆𝑎}- max{(𝜔_t)^(𝑖) |𝑖 ∈ 𝑆𝑠 }> 𝐶𝑠,则所有沉默客户端的模型更新都污染,而发出报警的所有客户端由于其准确度相似,所以是良性的。
对于情况 4,报警客户端的准确度存在发散现象,表明良性和恶意客户端都在报警。同样,我们使用所有报警客户端的最大准确度来过滤掉报警的恶意客户端。如果一个报警客户端的准确度满足 max{𝜔_t)^(𝑖) |𝑖 ∈𝑆𝑎}-𝜔_t)^(𝑖) <𝐶𝑠,那么我们将其加入良性客户端集合𝑆𝑏。由于良性客户端在检测到污染𝒈_𝑡时总是会报警,所以在沉默的客户端中不存在良性客户端。因此,在这种情况下,我们将忽略所有的沉默客户端。
3.1.5 权重分析
由于大多数攻击的目的是产生恶意的权重更新,与良性的权重更新相比,它可以对全局模型产生反向影响。与良性更新相比,这些恶意的权重更新通常代表了模型的反向变化方向。本节作者对 Siren 进行权重分析。
然而,与 FL Trust 使用由服务器端数据训练的辅助模型不同(这意味着系统对全局模型有一个预定义的期望)[14],Siren 只使用来自客户端的信息。通过 Siren 的权重分析,服务器不仅要比较具有最大准确度的更新和其他更新之间的准确度,还要比较这些更新之间的角度。如果更新𝜔_𝑖与最大准确度 max{(𝜔_t)^(𝑖) |𝑖∈𝑆𝑎}之间的角度大于𝜋/2,那么𝜔_𝑖将被服务器视为一个恶意更新。否则,𝜔_𝑖被认为是良性更新,可以纳入到全局模型的计算过程中。通过权重分析,服务器可以从另一个角度检查客户端的更新,同时保持其客观性。
3.1.6 辅助机制
为了进一步改进 Siren 的性能,作者在本节中讨论向 Siren 结构中引入一些辅助机制。所有这些辅助机制都只在服务器端使用,因此并不会向客户端引入任何额外的计算负担。而服务器本身可以根据服务器上的计算资源以及从更好的安全性和性能的需求角度出发,灵活地决定是否使用这些辅助机制。
惩罚机制。作者设计了一个惩罚机制来提高 Siren 的稳定性。恶意客户端可以持续攻击服务器,而与之对应的持续检查会浪费大量的计算资源。通过惩罚机制,服务器记录每个客户端被视为恶意客户端的次数。如果一个客户端的计数大于阈值𝐶𝑝,那么服务器将不再接受来自该客户端的更新且不再检查,因为此时已经默认该客户端为恶意客户端。通过这种方法,服务器可以有效地节省计算资源,提高系统的稳定性。
奖励机制。由于每个客户端的数据存在差异,惩罚机制可能会将良性客户端误判为恶意客户端。因此,服务器可以利用奖励机制,让被禁止的客户端有机会重新加入到训练中来。在某一个通信回合中,如果一个被禁止的客户端被服务器视为良性客户端,则可以通过奖励机制将这个客户端的惩罚计数减少𝐶𝑎。如果这个被禁止的客户端的惩罚次数小于𝐶𝑝,那么可以令这个客户端再次参与训练过程。有了这个机制,服务器就可以减轻惩罚机制的副作用。
3.2 实验分析
作者实现了一个基于 Tensor-Flow 的 Siren 原型,共有 2000 多行 Python 代码,以及使用 multiprocessing library 来启动多个进程模拟多个客户端。作者通过在两个公共基准数据集上运行实际的 FL 任务来验证 Siren 的有效性:Fashion-MNIST 和 CIFAR-10。作者使用三种攻击方法评估 Siren:符号翻转攻击、标签翻转攻击和有针对性的模型污染,并比较了两种流行的拜占庭鲁棒方法:Krum 和 coordinate-wise median。所有的评估实验都是在一个具有六个 vCores 和一个 NVIDIA Tesla V100 GPU 的 NVIDIA DGX-2 虚拟实例上运行的。
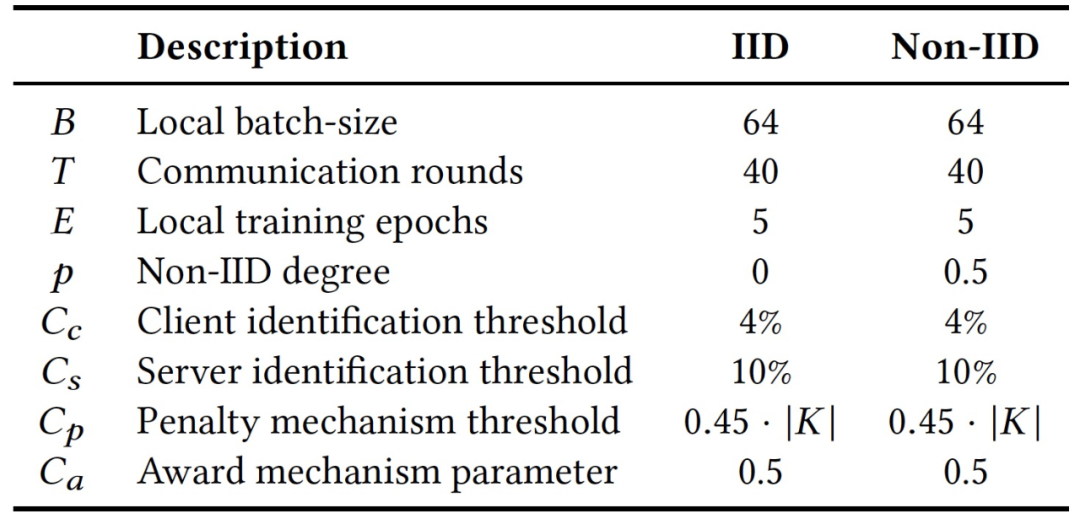
表 8. 本文实验中的参数设置
我们对抵御符号翻转攻击的实验进行详细介绍,关于标签翻转攻击和有针对性的模型污染的实验可见作者原文 [13]。图 12 显示了当 |𝐾|=10 时,FL 系统在符号翻转攻击下利用 Siren、Krum 和 coordinate-wise median 防护的训练效率。图 12(a)、图 12(c)、图 12(b) 和 12(d)分别描述了客户端集合中有 40% 和 80% 的客户端为恶意的情况下 FL 的准确性。在 80% 的客户端是恶意的情况下,无法启动 Krum,所以图 12(b)和 12(d)中省略了 Krum。
在系统中有 40% 的恶意客户端的情况下,Siren 和 Krum 都成功地在 IID 和 Non-IID 训练数据上进行了防御。但是,coordinate-wise median 受到了攻击的较大影响,特别是在 Non-IID 数据中。在系统中有 80% 的恶意客户端的情况下,Krum 和 coordinate-wise median 都无法保护 FL 系统。然而,图 12(b)和图 12(d)显示,Siren 成功地保护了全局模型免受 80% 的恶意客户端的攻击。图 12(b)和图 12(d)比较了有和无权重分析的 Siren。没有权重分析的 Siren 的全局模型准确度曲线突然下降,而有权重分析的 Siren 的全局模型准确度曲线没有这种问题。此外,图 12 显示,所有防御方法的准确度随着恶意比例的增加而下降,因为当恶意比例增加时,可用的训练数据样本较少。
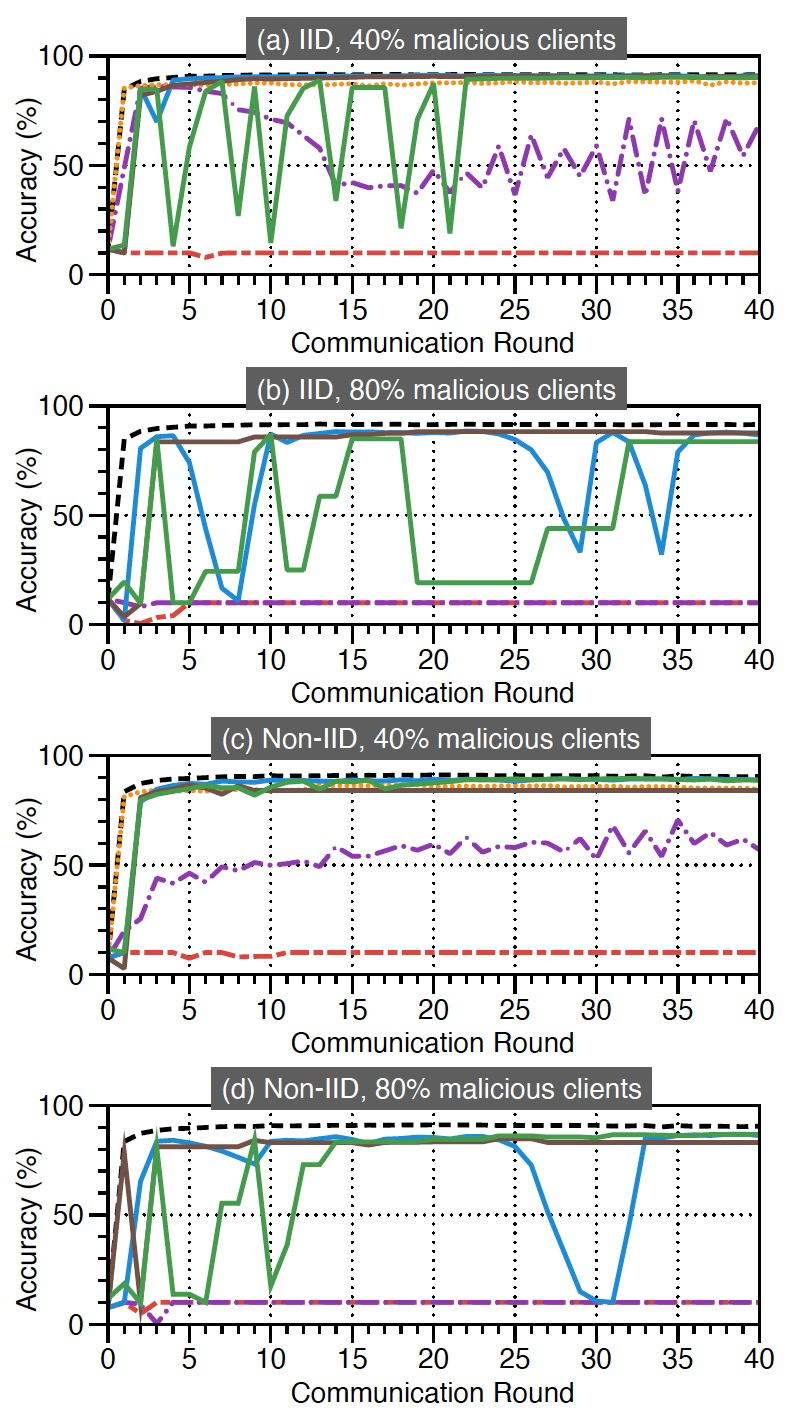
图 12. 当 |𝐾|=10 时,符号翻转攻击的训练效率
图 13 直观展示了每个客户端的恶意指数,该指数由 Siren 服务器维护,通过惩罚机制来确定 Siren 是否能检测到恶意客户端。恶意指数越高,意味着这个客户端更有可能是恶意的,因为它被服务器视为恶意客户端的次数更多。图 14 显示,奖励机制增强了良性更新和恶意更新之间的区别,减少了服务器的误判。
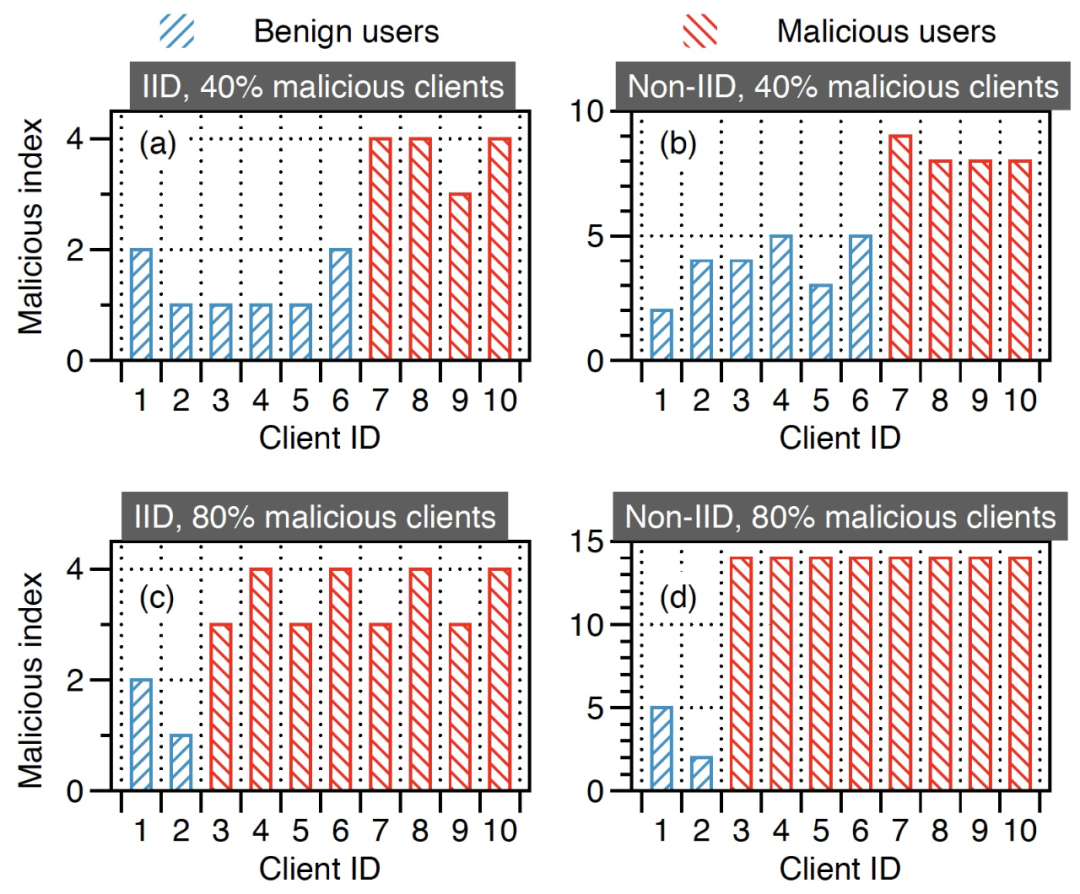
图 13. 当 |𝐾|=10 时,使用 Siren 的符号翻转攻击下服务器上每个客户端的恶意索引
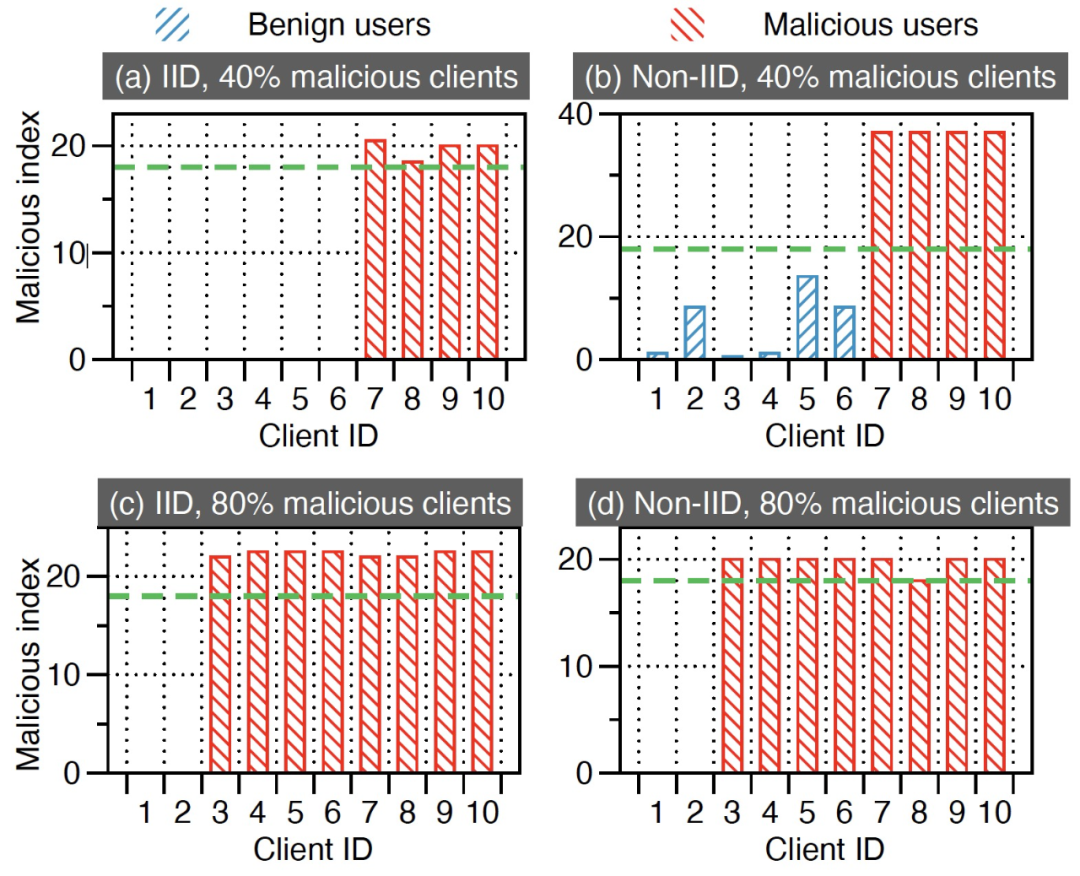
图 14. 当 |𝐾|=10 时,使用 Siren 的惩罚和奖励机制,每个客户端在服务器上的恶意指数(绿色虚线表示𝐶𝑝)
作者进一步探讨 FL 在 CIFAR-10 上运行时 Siren 的性能。作者将 Siren 与 Krum、coordinate-wise median 在符号翻转攻击和标签翻转攻击下进行比较,同时在部署在十个客户端上的 IID 分布式训练数据中进行实验。表 9 显示,无论攻击类型和恶意客户端的比例如何,与 Krum 和 coordinate-wise median 相比,Siren 总是能获得最佳性能。不过,在表 9 中给出的各种情况下,Siren 的准确度都比较低,作者分析这是由于本文中使用的模型比较简单。
作者还利用 CIFAR-10 数据集,用一个更强大的具有更多核的三层 CNN 模型来评估模型污染攻击下的效果。根据这一结果,Krum 和 coordinate-wise median 都失效了,模型的性能随着 Krum 的出现而严重下降,错误分类的置信度会收敛到 1。虽然通过 coordinate-wise median 训练的模型可以达到 67.69% 的准确度,但错误分类的置信度一直等于 1。然而,Siren 成功抵御了这些攻击,并训练了全局模型,达到了 65.47% 的准确度。
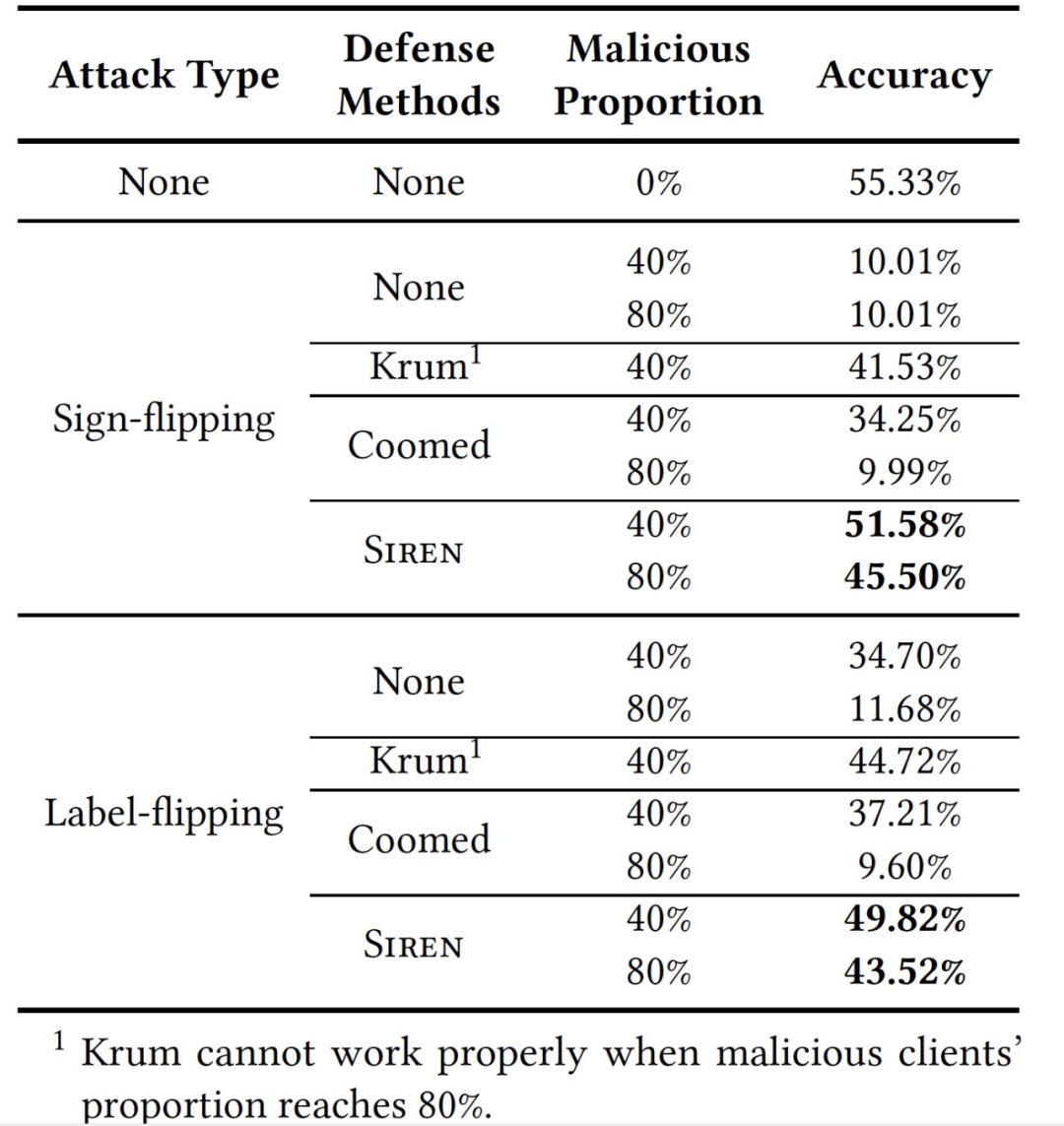
表 9. 当 |𝐾|=10 时,使用 IID 数据分布对 CIFAR-10 的训练效率
4、小结
我们选取的三篇文章从不同角度探讨了深度学习中的攻击不可知的防御措施。从这三篇文章也可以看出,在不同的应用场景下、针对不同类型的攻击策略,尽管我们努力做到 “攻击不可知的” 防御,但是攻击方式的思想不同、结构不同、应用的方法 / 模型不同,确实也无法做到彻底的防御“不可知攻击”,相同的模型在不同的场景 / 攻击策略下的效果还是有所差别。但是,攻击不可知的措施能够有效适应攻击可变的性质,具有更广阔的应用前景,值得进一步的关注和研究。
分析师介绍:Jiying,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
本文参考引用的文献:
[1] Ji, Y. , X. Zhang , and T. Wang . "EagleEye: Attack-Agnostic Defense against Adversarial Inputs (Technical Report)." (2018).
[2] Fawzi, A., Fawzi, O., and Frossard, P. Analysis of classifiers’ robustness to adversarial perturbations. ArXiv e-prints (2015).
[3] Papernot, N., McDaniel, P., Wu, X., Jha, S., and Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In S&P (2016).
[4] Chen J , Zhang X , Zhang R , et al. De-Pois: An Attack-Agnostic Defense against Data Poisoning Attacks[J]. IEEE Transactions on Information Forensics and Security, 2021, PP(99):1-1.
[5] M. Mirza and S. Osindero, “Conditional generative adversarial nets,” 2014, arXiv:1411.1784. [Online]. Available: http://arxiv (http://arxiv/).org/abs/1411.1784
[6] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C. Courville, “Improved training of Wasserstein GANs,” in Proc. NIPS, 2017, pp. 5767–5777.
[7] Chou, E. , F Tramèr, and G. Pellegrino . "SentiNet: Detecting Physical Attacks Against Deep Learning Systems." (2018).
[8] B. Zhou, A. Khosla, A` . Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” CoRR, vol. abs/1512.04150, 2015. [Online]. Available: http://arxiv.org/abs/1512.04150
[9] A. Chattopadhyay, A. Sarkar, P. Howlader, and V. N. Balasubramanian, “Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks,” CoRR, vol. abs/1710.11063, 2017. [Online]. Available: http://arxiv.org/abs/1710.11063
[10] T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnerabilities in the machine learning model supply chain,” CoRR, vol. abs/1708.06733, 2017. [Online]. Available: http://arxiv.org/abs/1708.06733
[11] Y. Liu, S. Ma, Y. Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning attack on neural networks,” in NDSS, 2018.
[12] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” CoRR, vol. abs/1409.1556, 2014. [Online]. Available: http://arxiv.org/abs/1409.1556
[13] H.Guo, H. Wang, et al. Siren: Byzantine-robust Federated Learning via Proactive Alarming,SoCC' 21.
[14] Xiaoyu Cao, Minghong Fang, Jia Liu, and Neil Zhenqiang Gong. 2020. FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping. arXiv preprint arXiv:2012.13995 (2020).

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


