论文快报 | 推荐系统领域最新研究进展
本文总结推荐系统领域2022年1月7日到2022年1月16日之间的最新研究进展,主要内容包括:
基线/综述/可复现性
WSDM 2022 | On Sampling Collaborative Filtering Datasets【本文研究了数据集采样策略对推荐算法排序性能的实际影响】
Arxiv 2022 | An Evaluation Study of Generative Adversarial Networks for Collaborative Filtering【这项工作探索了CFGAN这类模型的可复现性】
Arxiv 2022 | RGRecSys: A Toolkit for Robustness Evaluation of Recommender Systems【提出了一个鲁棒性评估工具包】
序列/会话推荐
TKDE 2022 | Disentangled Graph Neural Networks for Session-based Recommendation【用户选择某个物品的意图是由该物品的某些因素驱动的(例如,电影的主角),本文的方法建模了这种细粒度的的兴趣来生成高质量的会话嵌入。】
新闻推荐
Arxiv 2022 | GateFormer: Speeding Up News Feed Recommendation with Input Gated Transformers【现有的基于Transformer或PLM的推荐模型对于超长新闻浏览历史相关的活跃用户来说,仍然无法及时给出推荐,本文提出了GateFormer,在将输入数据输入Transoformer之前对其进行门控。】
Multi-Behavior 推荐
ICDE 2021 | Multi-Behavior Enhanced Recommendation with Cross-Interaction Collaborative Relation Modeling【利用图神经网络建模Multi-Behavior 推荐】
Point-of-Interest推荐
IP&M journal 2022 | Leveraging Social Influence based on Users Activity Centers for Point-of-Interest Recommendation【将社交、地理和时间信息纳入矩阵分解(MF)技术来解决推荐系统交互数据稀疏的问题。】
对比学习+推荐
-
WSDM 2022 | C2-CRS: Coarse-to-Fine Contrastive Learning for Conversational Recommender System【提出了一种新的粗至细对比学习框架来改进会话式推荐系统(CRS)的数据语义融合】 -
Arxiv 2022 | Supervised Contrastive Learning for Recommendation【对比学习+图神经网络推荐】 因果推理+推荐
Arxiv 2022 | Deep Causal Reasoning for Recommendations【将推荐建模为一个多原因多结果(MCMO,multi-cause multi-outcome)推理问题】
损失函数
Arxiv 2022 | On the Effectiveness of Sampled Softmax Loss for Item Recommendation【本文回答了:1.sampled softmax loss是否适合推荐系统?2. 与普遍的损失相比,采样的softmax损失在概念上有什么优势?】
采样
-
TOIS 2021 | Collaborative Reflection-Augmented Autoencoder Network for Recommender Systems【为了解决推荐系统随机负采样的问题,本文开发了一个CRANet网络,它能够从观察到的和未观察到的用户-物品交互中探索可转移的知识。】
基线/综述/可复现性
WSDM 2022 | On Sampling Collaborative Filtering Datasets【本文研究了数据集采样策略对推荐算法排序性能的实际影响】
推荐系统通常是在大数据集的样本上进行训练和评估的。样本通常以一种简单或特别的方式获取:例如,通过随机采样数据集,或通过选择具有许多交互的用户或物品。正如我们所演示的,常用的数据采样方案可以对算法性能产生重大影响。
基于此,本文主要贡献如下:
-
(1)从算法和数据集特征(如稀疏性特征、序列动态等)方面描述采样对算法性能的影响; -
(2)设计SVP-CF,这是一种特定于数据的采样策略,旨在保持采样后模型的相对性能,特别适用于长尾交互数据; -
(3)开发一个oracle Data-Genie,它可以推荐最可能保持给定数据集的模型性能的采样方案。data-genie的主要好处是,它允许推荐系统实践者快速原型化和比较各种方法,同时保持对算法性能的信心,一旦算法被重新训练并部署在完整的数据上。详细的实验表明,使用data-genie,我们可以丢弃比任何相同性能水平的采样策略多5倍的数据。
Arxiv 2022 | An Evaluation Study of Generative Adversarial Networks for Collaborative Filtering【这项工作探索了CFGAN这类模型的可复现性】
这项工作探索了CFGAN[1]的可复现性(reproducibility)。
实验结果表明,CFGAN具有replicable and numerically stable性,但不具有reproducible,因为它可以被简单但适当调整的基线超越。这个结果补充了最近的证据,即适当调整的基线可以优于复杂的方法,并表明CFGAN还不是一个成熟的推荐算法。
[1] CFGAN: A generic collaborative filtering framework based on generative adversarial networks. CIKM, 2018
Arxiv 2022 | RGRecSys: A Toolkit for Robustness Evaluation of Recommender Systems【提出了一个鲁棒性评估工具包】
鲁棒机器学习是一个越来越重要的主题,它专注于开发能够适应各种形式的不完美数据的模型。由于推荐系统在在线技术中的广泛应用,研究人员针对数据稀疏性和配置文件注入攻击进行了多项稳健性研究。
相反,我们提出了一个更全面的推荐系统鲁棒性观点,它包含多个维度——关于sub-populations, transformations、分布差异、攻击和数据稀疏的鲁棒性。虽然有很多库可以让用户比较不同的推荐系统模型,但还没有一个软件库可以对不同场景下的推荐系统模型进行全面的鲁棒性评估。作为我们的主要贡献,我们提出了一个鲁棒性评估工具包(RGRecSys),它允许我们快速和一致地评估推荐系统模型的鲁棒性。
https://github.com/salesforce/RGRecSys
序列/会话推荐
TKDE 2022 | Disentangled Graph Neural Networks for Session-based Recommendation【用户选择某个物品的意图是由该物品的某些因素驱动的(例如,电影的主角),本文的方法建模了这种细粒度的的兴趣来生成高质量的会话嵌入。】
基于会话的推荐(SBR)仅利用当前会话中有限的用户行为历史,具有极大的实用价值,近年来受到越来越多的研究关注。现有的方法通常学习物品层面的会话嵌入,即在对物品分配注意权重或不分配注意权重的情况下对物品的嵌入进行聚合。然而,它们忽略了一个事实,即用户选择某个物品的意图是由该物品的某些因素驱动的(例如,电影的主角)。换句话说,他们没有在因素(factor)级探索用户更细粒度的兴趣来生成会话嵌入,导致性能不佳。
为了解决这一问题,我们提出了一种新的方法,称为解纠缠图神经网络(disengen-gnn),以捕获会话意图,并考虑对每个物品的因素级注意力。具体来说,我们首先采用解纠缠学习技术将物品嵌入分配到多个因素的嵌入空间中,然后利用门控图神经网络(GGNN)根据每个因素计算物品邻居相似度矩阵来准确地学习嵌入因素。
新闻推荐
Arxiv 2022 | GateFormer: Speeding Up News Feed Recommendation with Input Gated Transformers【现有的基于Transformer或PLM的推荐模型对于超长新闻浏览历史相关的活跃用户来说,仍然无法及时给出推荐,本文提出了GateFormer,在将输入数据输入Transoformer之前对其进行门控。】
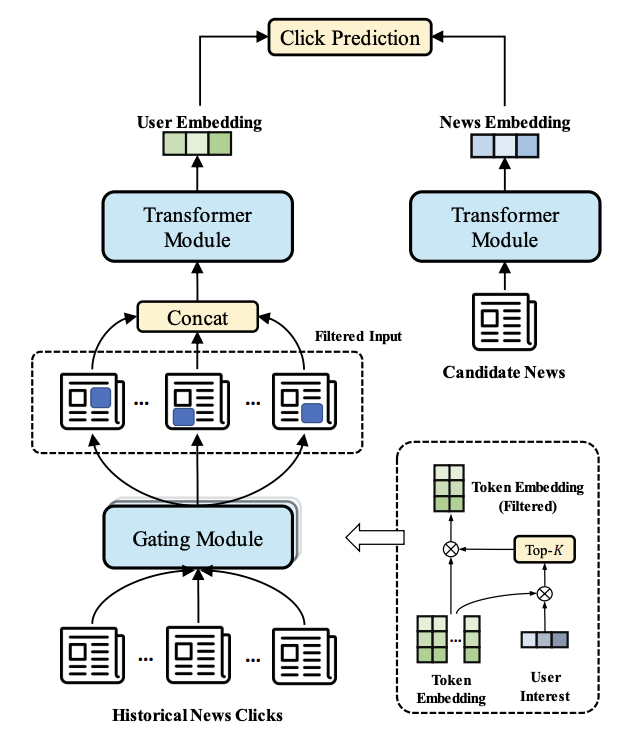
新闻流推荐是一项重要的网络服务。近年来,预训练语言模型(pre-training language model, PLMs)被广泛应用于提高推荐质量。但这些深度模型的利用在很多方面都存在局限性,如缺乏可解释性,与现有的倒排指标体系不兼容等。综上所述,基于PLM的推荐器效率低下,用户侧信息的编码将耗费巨大的计算成本。虽然使用高效的Transoformer或提炼的PLM可以加快计算速度,但对于与超长新闻浏览历史相关的活跃用户来说,仍然无法及时给出推荐。
在本研究中,我们从一个独特的视角来处理有效的新闻推荐问题。我们认为,用户的兴趣可以完全被那些具有代表性的关键字所捕获,而不是依赖于整个输入(即用户曾经浏览过的新闻文章的集合)。基于此,我们提出了GateFormer,在将输入数据输入Transoformer之前对其进行门控。门控模块是个性化的、轻量级的和端到端可学习的,这样它可以执行准确和高效的信息用户输入过滤。GateFormer在实验中取得了令人印象深刻的性能,在准确性和效率方面明显优于现有的加速方法。我们还惊奇地发现,即使对原始输入进行了超过10倍的压缩,GateFormer仍然能够保持与SOTA方法相同的性能。
Multi-Behavior 推荐
ICDE 2021 | Multi-Behavior Enhanced Recommendation with Cross-Interaction Collaborative Relation Modeling【利用图神经网络建模Multi-Behavior 推荐】
以往的许多研究旨在利用深度神经网络技术增强协同过滤,以获得更好的推荐性能。然而,现有的基于深度学习的推荐系统大多是针对奇异(singular)类型的用户-物品交互行为进行建模,很难提取出用户与物品之间的异构关系。在实际的推荐场景中,存在多种用户行为,如浏览、购买等。由于忽略了用户对不同物品的多行为模式,现有的推荐方法不足以从用户多行为数据中捕捉到异构的协同信号。
受图神经网络在结构化数据建模方面的强大能力的启发,本工作提出了一个图神经网络多行为增强推荐(GNMR)框架,该框架在基于图的消息传递体系结构下明确地对不同类型的用户-物品交互之间的依赖关系建模。GNMR设计了一个关系聚合网络来模拟交互异构性,并递归地在用户-物品交互图上执行相邻节点之间的嵌入传播。
Point-of-Interest推荐
IP&M journal 2022 | Leveraging Social Influence based on Users Activity Centers for Point-of-Interest Recommendation【将社交、地理和时间信息纳入矩阵分解(MF)技术来解决推荐系统交互数据稀疏的问题。】
推荐系统(RSs)的目标是建模和预测用户的偏好,如兴趣点(POIs)。这些系统面临着一些挑战,例如数据稀疏性,限制了它们的有效性。在本文中,我们通过将社交、地理和时间信息纳入矩阵分解(MF)技术来解决这个问题。
对比学习+推荐
WSDM 2022 | C2-CRS: Coarse-to-Fine Contrastive Learning for Conversational Recommender System【提出了一种新的粗至细对比学习框架来改进会话式推荐系统(CRS)的数据语义融合】
会话式推荐系统(CRS)旨在通过自然语言对话向用户推荐合适的物品。为了开发有效的CRS算法,一个主要的技术问题是如何从非常有限的会话上下文中准确地推断出用户偏好。为了解决这个问题,一个很有前途的解决方案是合并外部数据来丰富上下文信息。然而,以往的研究主要是针对特定类型的外部数据设计融合模型,对于多类型的外部数据建模和利用并不普遍。
为了有效利用多类型的外部数据,我们提出了一种新的粗至细对比学习框架来改进CRS的数据语义融合。在我们的方法中,我们首先从不同的数据信号中提取和表示多粒度的语义单元,然后以粗到细的方式将相关的多类型语义单元对齐。为了实现这个框架,我们设计了粗粒度和细粒度的过程来建模用户偏好,其中粗粒度过程侧重于更一般的粗粒度语义融合,而细粒度过程侧重于更具体的细粒度语义融合。这种方法可以扩展为包含更多种类的外部数据。
Arxiv 2022 | Supervised Contrastive Learning for Recommendation【对比学习+图神经网络推荐】
与传统的协同过滤方法相比,图卷积网络可以显式建模用户-物品二部图节点之间的交互,并有效利用高阶邻域,使图神经网络获得更有效的推荐嵌入,如NGCF和LightGCN。然而,它的表示很容易受到相互作用的噪声的影响。针对这一问题,SGL研究了用户-物品图的自监督学习,以提高GCN的鲁棒性。虽然它有效,但我们发现SGL直接应用了SimCLR的比较学习框架。这个框架可能不能直接应用到推荐系统的场景,并没有充分考虑用户物品交互的不确定性。
这项工作,我们的目标是在应用对比学习时充分考虑推荐系统场景的特性,使其更适合推荐任务。我们提出了一个监督对比学习框架来预训练用户-物品二部图,然后对图卷积神经网络进行微调。具体来说,我们将在数据预处理过程中比较用户与物品之间的相似度,然后在应用对比学习时,不仅将扩增视图视为正样本,还将一定数量的相似样本视为正样本,这与SimCLR不同,SimCLR将一批中的其他样本视为负样本。我们将这种学习方法称为监督对比学习(SCL),并将其应用于最先进的LightGCN。此外,为了考虑节点交互的不确定性,我们还提出了一种新的数据增强方法——节点复制。
因果推理+推荐
Arxiv 2022 | Deep Causal Reasoning for Recommendations【将推荐建模为一个多原因多结果(MCMO,multi-cause multi-outcome)推理问题】
传统的推荐系统的目标是基于观测到的评分估计一个用户对一个物品的评价。与所有的观察性研究一样,隐藏的混杂因素,即影响物品曝光和用户评分的因素,会导致估计中的系统偏差。因此,从因果关系的角度来否定混杂因素的影响是推荐系统研究的一个新趋势。
观察到推荐中的混杂物通常在物品之间共享,因此是多原因混杂物,我们将推荐建模为一个多原因多结果(MCMO, multi-cause multi-outcome)推理问题。具体来说,为了纠正混淆偏差,我们估计用户特定的潜在变量,使物品曝光于独立的伯努利试验。生成型分布由一个具有阶乘逻辑似然的DNN参数化,而棘手的后验则由变分推理估计。将这些因素控制为替代混杂物,在温和的假设下,可以消除多原因混杂物产生的偏差。此外,我们表明,由于缺乏与高维因果空间相关的观测,MCMO建模可能导致高方差。幸运的是,我们从理论上证明,引入用户特征作为预处理变量可以极大地提高样本效率,缓解过拟合问题。在模拟和真实数据集上的实证研究表明,提出的深度因果推荐方法对未观察到的混杂具有比最先进的因果推荐方法更强的鲁棒性。
代码:https://github.com/yaochenzhu/deep-deconf
损失函数
Arxiv 2022 | On the Effectiveness of Sampled Softmax Loss for Item Recommendation【本文回答了:1.sampled softmax loss是否适合推荐系统?2. 与普遍的损失相比,采样的softmax损失在概念上有什么优势?】
推荐模型的学习目标在很大程度上仍未被探索。大多数方法通常采用point-wise损失或pair-wise损失训练模型参数,但由于计算成本高,很少关注softmax损失。sampled softmax损失作为softmax损失的一种有效替代品出现了。它的特殊例子InfoNCE loss在自监督学习中得到了广泛的应用,并在对比学习中表现出了显著的性能。然而,仅有有限的研究使用采样的softmax loss作为学习目标来训练推荐模型。更糟糕的是,据我们所知,他们中没有人探究它的属性,也没有人回答“采样softmax损失是否适合物品推荐?”和“与普遍的损失相比,采样softmax损失在概念上有什么优势?”
在这项工作中,我们的目标是更好地理解采样softmax损失的物品推荐。具体而言,我们首先从理论上揭示了模型无关的「三个优势」:(1)减轻流行度偏差,有利于长尾推荐;(2)挖掘难负样本,为优化模型参数提供信息梯度;(3)最大化排序指标,促进排名Top-K的表现。此外,我们在各种推荐模型的顶部探讨了模型特定的特征。
实验结果表明,「采样softmax损失函数对基于历史和基于图的推荐器(如SVD++和LightGCN)更友好,但对基于id的模型(如MF)性能较差」。
采样
TOIS 2021 | Collaborative Reflection-Augmented Autoencoder Network for Recommender Systems【为了解决推荐系统随机负采样的问题,本文开发了一个CRANet网络,它能够从观察到的和未观察到的用户-物品交互中探索可转移的知识。】
随着深度学习技术扩展到现实世界的推荐任务,许多基于深度神经网络的协同过滤(CF)模型已经被开发出来,以基于各种神经结构,如多层感知器、自动编码器和图神经网络,将用户-物品交互投射到潜在特征空间。然而,大多数现有的协同过滤系统并没有很好地设计来处理缺失的数据。特别是,为了在训练阶段注入negative信号,这些解决方案很大程度上依赖于从未观察到的用户-物品交互中进行负采样,并简单地将其视为负面实例,从而导致推荐性能下降。
为了解决这些问题,我们开发了一个协同反射增强自动编码器网络(CRANet),它能够从观察到的和未观察到的用户-物品交互中探索可转移的知识。CRANet的网络结构是一个由reflective receptor网络和信息融合自动编码模块组成的一体化结构,这使得我们的推荐框架具有对隐式用户对交互和非交互物品的两两偏好进行编码的能力。此外,设计了一种基于参数正则化的系权方案,用于两阶段CRANet模型的鲁棒关节训练。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


