复旦数据院副院长阳德青:知识图谱在个性化推荐系统中的应用

来源:启迪之星上海
本文约2700字,建议阅读5分钟。
本文为你着重介绍基于知识图谱的搜索与推荐方面的基本内容和应用,知识图谱领域的研究及前沿技术。
本次特邀嘉宾

阳德青
复旦大学大数据学院和大数据研究院
副院长、副教授
2013年在复旦大学计算机科学技术学院获得计算机软件与理论专业的博士学位。阳老师的主要研究领域为数据挖掘、知识图谱的构建与应用、推荐系统、社会网络分析等,其研究成果论文先后在WWW、ICDM、CIKM、ECML等数据科学领域的国际顶尖学术会议上发表,并拥有多项发明专利。同时,他先后主持、参加了多项国家科技部、自科基金委、上海市科委、经信委、教委等专项课题,并在与阿里、华为等科技公司的合作中取得了丰硕的实际应用成果。此外,阳老师先后担任过复旦大学学生工作部、研究说工作部副部长和学生职业发展教育服务中心主任,具有丰富的学生管理和大学生双创指导经验。
一、知识图谱的基本概念
什么是知识图谱呢?
知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。形式化的进行解释,知识图谱是一种海量知识表征形式,蕴含了各类实体、概念及其间的各种语义关系。通俗来讲就是一种数据库,本质上就是一种语义网路。相比于传统语义网络,知识图谱具有更高的实体、概念覆盖率,更为丰富的语义关系,自动化构建程度高以及较高的数据质量等。它研究的意义在于为语义匹配(消除语义鸿沟)、实现机器智脑提供了丰富的背景知识。

二、基于传统知识的推荐
了解传统知识推荐的特点和缺点,才可以更清晰的明白知识图谱产生的必要性,更精准的把握知识图谱的特质,怎么样做到智能推荐。
1.基于知识的传统推荐
主要分为两种:
基于约束的知识化推荐通过用户的输入限定物品属性值形成规则集合,形成候选物品的范围约束——关于用户的知识。类似于输入条件的查询。
-
基于个案的知识化推荐是先通过某种算法产生一组候选物品给用户选择,将用户的选择作为参照物,再通过物品间的相似性计算找出其他与参照物品高度相似的候选物品,再让用户进一步选择,多次与用户的迭代交互,直至最终产生用户最想要的物品。类似问答式的搜索。
2.传统推荐算法的挑战
基于协同过滤的弊端
•冷启动 •数据稀疏 •可扩展性
当一个新用户进入一个网络时,我们对他的兴趣爱好还一无所知,这时如何做出推荐是一个很重要的问题。一般在这个时候,我们只是向用户推荐那写普遍反映比较好的物品,也就是说,推荐完全是基于物品的。
新用户问题还有一个变种就是长尾(long tail)问题,在Amazon中,不是所有的用户都对很多书给出了评分,很多用户只给少数的书给出了评分,这些用户就处在一个长尾中,如何处理那些不太表露自己兴趣的用户,也是推荐系统的一个主要问题。
基于内容的弊端
•特征描述 •同义/多义词 •“十面埋伏”是电影?小说?还是成语? •结果的同质性(缺乏多样性)
在物品知识的获取上,系统需要人工构建知识,对长尾实体的覆盖有限。
-
在用户知识的获取上,系统需要用户输入信息,甚至要反复交互,体验感差。
3.推荐系统中引入知识图谱的优势
首先,能够提高推荐的精确性。知识图谱中蕴含了用品直接丰富的语义信息,能够更好的发现用户的兴趣点。
其次,还能提高推荐的多样性。在很多的推荐场景中,比如新闻推荐,我们知道多样性是一个很大的问题,我们很容易发现推荐算法发现了你的兴趣点之后,给你推荐的东西越来越像,比如你点了几个NBA的新闻,后面来的全是NBA新闻,一开始可能觉得还不错,时间稍微长一点,就会觉得厌烦了,阅读的视野也会越来越窄。这是因为很多算法是根据文本里面抽取出来的关键字和主题来猜测用户偏好,这样推荐的时候就会产生比较类似的结果。
而知识图谱作为一种全局信息,里面有丰富的语义信息,每个物品对应的节点通常都能扩散到很多其他的信息节点上去,比如用户喜欢霸王别姬这部电影,可能是因为主演、题材或者导演,每种都有可能,推荐的时候就不会过于集中到一种类型中去,增加了多样性。
第三,能增加推荐的可解释性。可解释性是推荐系统的非常重要的因素,其重要性甚至在很多场景中要远远大于推荐的准确性等效果指标,可以被很好解释的推荐系统才能增加用户对系统的信任感。
那么实现一个好的推荐关键在于什么?去做好物品和用户的画像,这两个画像寻找准确之后他们特征就可以精准的把握,然后去找一些匹配的算法,那这样的结果就是就八九不离十了。以及一些比较有挑战的,比如说跨领域的推荐。
三、基于知识图谱的物品画像
显式画像:从知识图谱中直接找到的关联(例如两部电影的共同属性)作为刻画两个物品相关性的依据。有基于向量空间模式和基于异构信息网络两种模式。
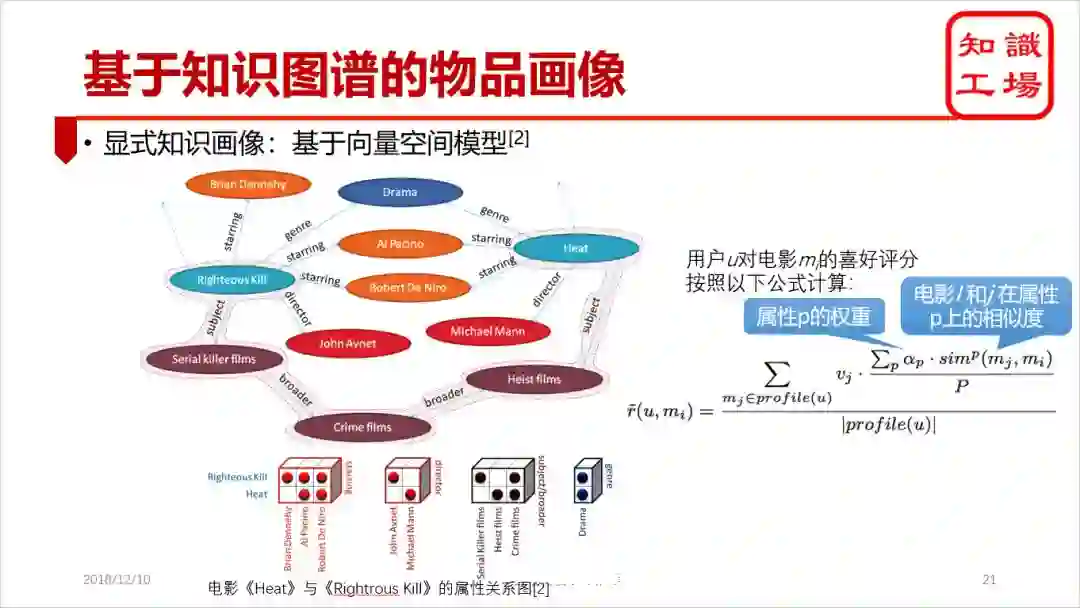
为每种属性生成一个表示向量,每一维对应该属性的某个值的权重。例如,电影的演员属性可以表示成一个向量,第一维的值可以是第1号演员对该电影的TF-IDF权重值。
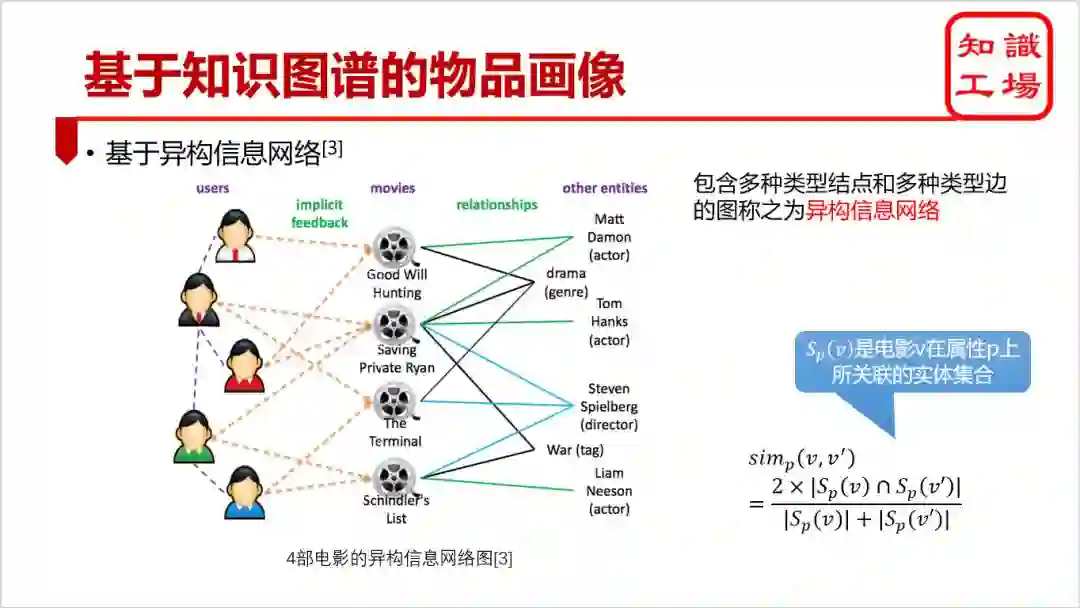
将物品和其每种属性值对应的实体都表示成异构信息网络的一类结点,它们之间构成各种类型的边。例如,每部电影和其每个演员都由一条表示“参演”的边相连。
不同物品间会共享某些属性对应的实体,所以会有一条经过该共享实体的元路径meta-path将两个物品相连。例如,成龙主演的不同电影之间都通过一条“电影-演员(成龙)-电影”的元路径相连
由不同类型的元路径相连的两个物品都具有一定的相似度。
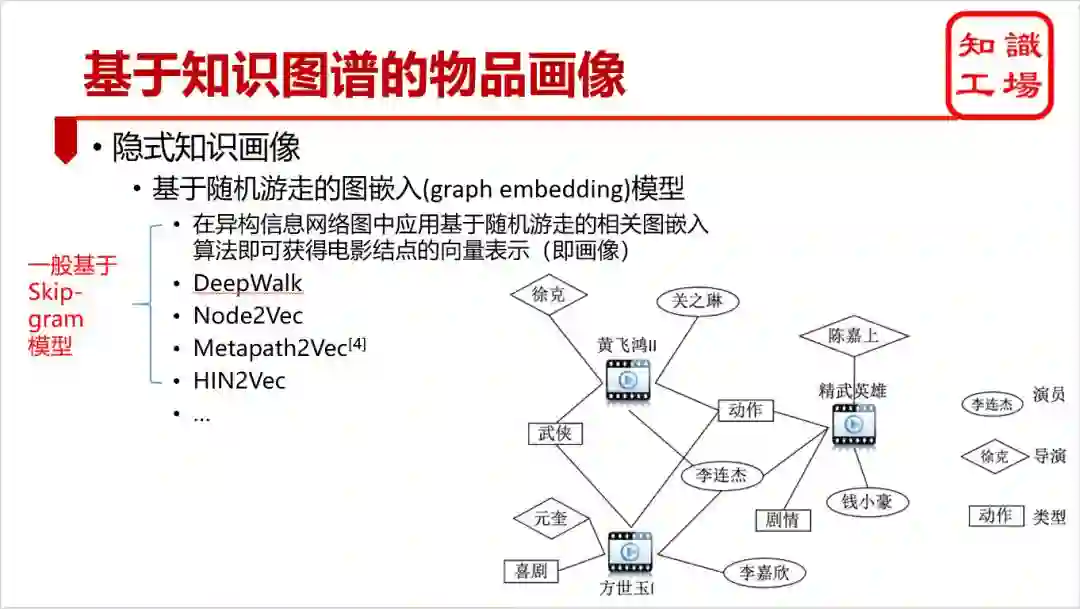
隐式画像:利用基于深度神经网络的嵌入embedding向量来表示物品,物品间的相似度计算基于其对应嵌入向量在向量空间中的距离。有基于随机游走的图嵌入(graph embedding)和基于KG embedding两种模型。
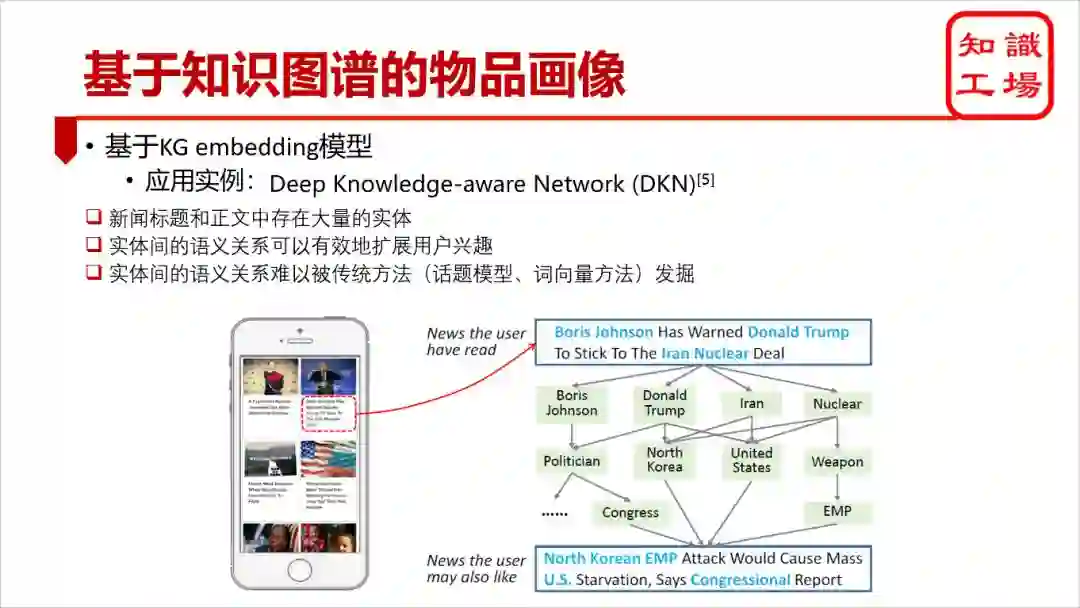
四、基于知识图谱的用户画像
基于概念标签的用户画像
•算法目标:根据输入一组标签(词袋),生成的概念标签数尽量少,同时在语义上尽量全地覆盖所有原始标签的语义。
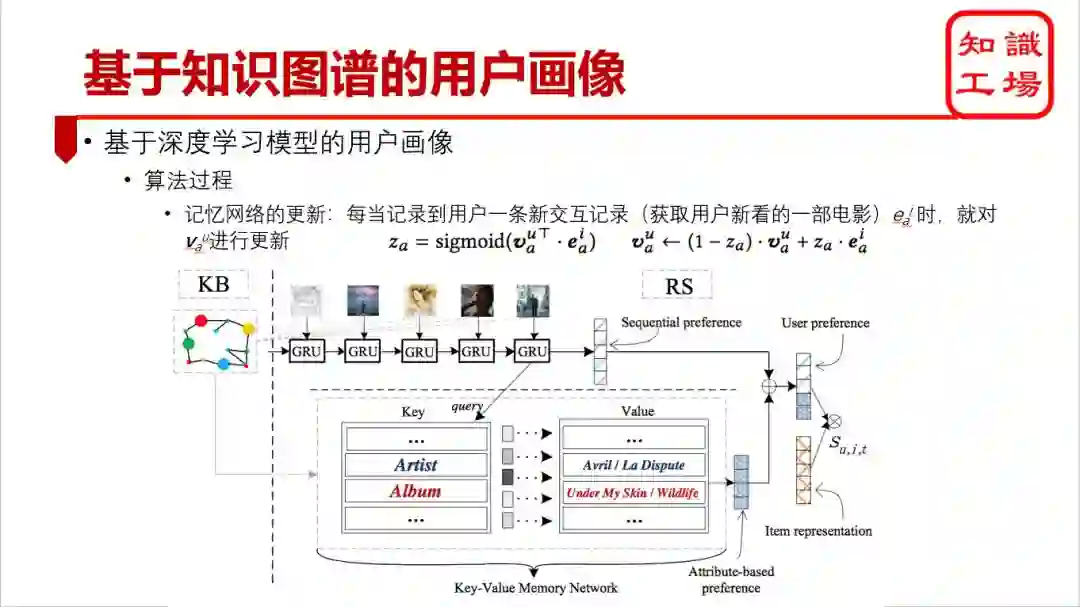
利用记忆网络存储刻画用户对物品属性的偏好特征,比纯基于用户历史上的偏好物品刻画用户特征要更加准确、丰富。
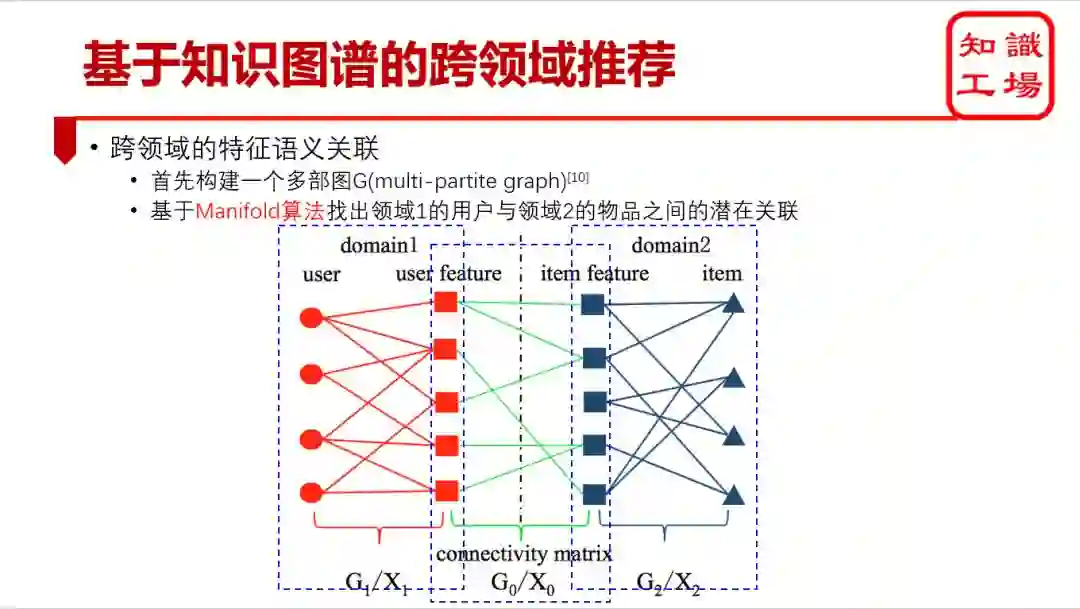
五、基于知识图谱的跨领域推荐
跨领域推荐的主要任务
•缓解冷启动问题,为新用户推荐提供选择和帮助提高推荐精准度,缓解数据稀疏问题 •增加推荐多样性
跨领域推荐面临的挑战
•数据海量性 •数据异构性 •数据稀疏性 •数据相依性数据低质性
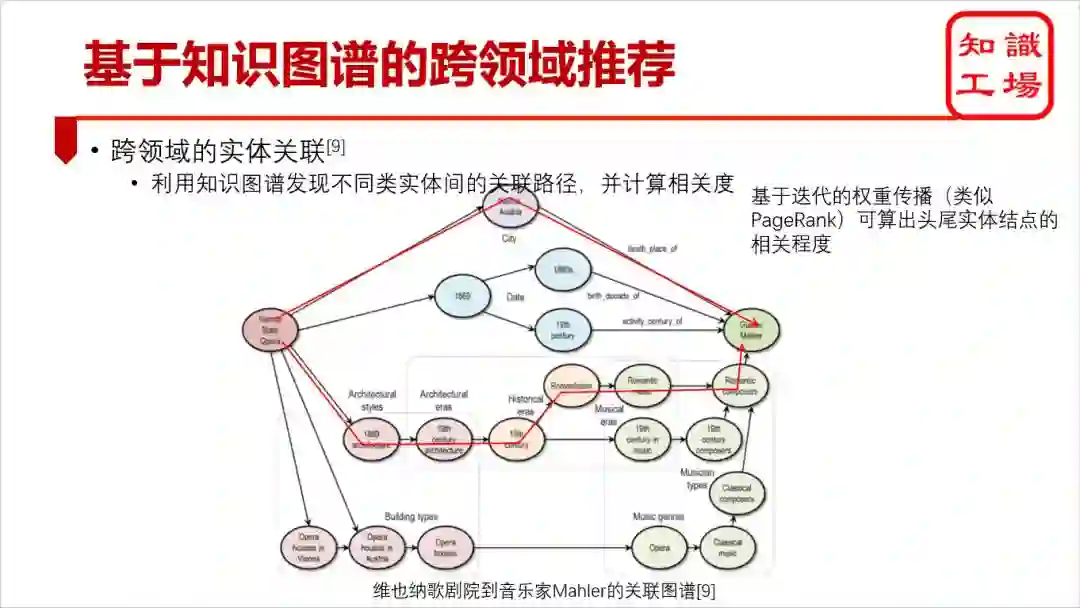
主流的跨领域推荐算法
基于协同过滤 •基于语义关系 •基于深度学习
实现跨领域推荐的关键假设
用户的兴趣偏好或项目特征在领域之间存在一致性或相关性(通过知识图谱发现)