报名 | 知识图谱前沿技术课程(苏州大学站)
知识图谱表达了各类实体、概念及其之间的各种语义关系,成为了大数据时代知识表示的主要形态之一。知识图谱是目前人工智能领域的一个重要支撑,已经在诸如智能问答、搜索、推荐等具体领域得到很好的应用。
苏州大学先进数据分析研究中心是2013年7月成立的苏州大学校级研究中心。现有教授3人,副教授5人,重点从事大数据和高性能海量实时数据分析研究,专注于数据库、信息检索、智能分析、数据质量管理、云计算与信息服务等方向的研发工作,目前正在开展对知识图谱构建、精化和应用等各方面的研究。
为此举办此次知识图谱前沿技术课程,邀请了复旦大学、中科院软件所、北京大学、华东师范大学、苏州大学等高校著名学者,及腾讯、中兴通讯、智言科技等业界领先企业代表,共济一堂,开堂授课,交流研讨。旨在集中展示知识图谱的当前在学术界和工业界的进展,讨论现有主要问题,为下一步知识图谱方向的研究工作做好规划。欢迎广大师生、研究人员参与。
活动时间
12月02日(周六)
9:00 - 17:30
活动地点
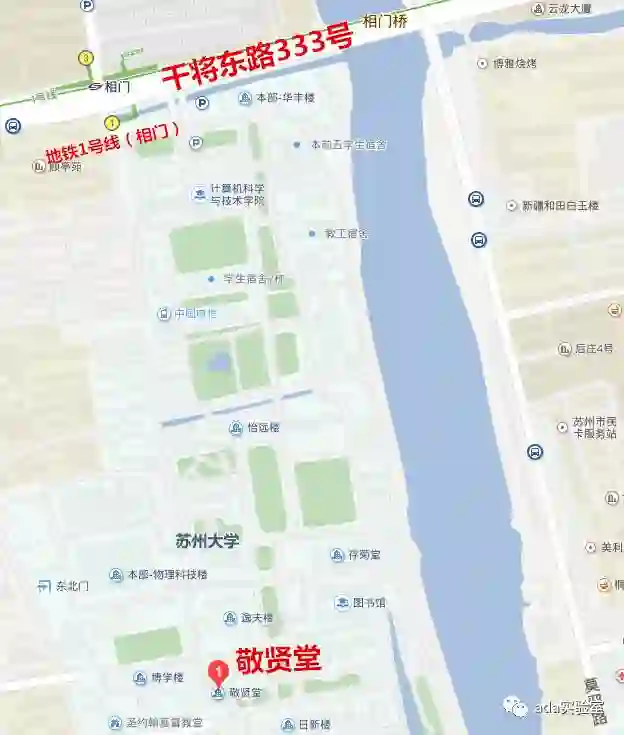
苏州大学本部(姑苏区干将路333号)敬贤堂
乘出租车请在干将东路333号苏州大学校本部北门下车,进入时告知保安参加本次会议。或者搭乘地铁1号线从相门站1号口出右转,步行至会场。
报名方式
本课程不收取任何费用,与会人员食宿自理。为更好为大家提供服务,需在线报名,并在与会时签到。请点击「阅读原文」进行报名。
日程安排

讲者简介
组织者简介

李直旭 苏州大学
李直旭,2013年毕业于澳大利亚昆士兰大学,获计算机科学博士学位。现为苏州大学计算机学院特聘副教授,硕导,江苏省“双创”博士入选者。研究方向为数据质量,众包技术和知识图谱。现为CCF数据库专委会通讯委员,人工智能学会智能服务专委会委员。IEEE TKDE, WWWJ等期刊长期审稿人,已发表论文50余篇。
报告人简介

肖仰华 复旦大学
肖仰华博士,复旦大学计算机学院副教授、博导,复旦大学知识工场实验室创始人、负责人,上海市互联网大数据工程技术中心副主任,兼任多家规模企业高级顾问或首席科学家。主要研究兴趣包括知识图谱、大数据管理与挖掘。在SIGMOD,VLDB, ICDE, IJCAI, AAAI等国际顶级学术会议发表论文100多篇。领导构建国内首个知识库云服务平台(知识工场平台kw.fudan.edu.cn),以API形式对外服务4亿次。
报告题目:大规模概念图谱构建与应用
报告摘要:
概念是人类认知世界的基石,是思维活动借以开展的基本单元。建立概念分类体系,并为数以千万计的实体建立概念图谱,是让机器具备认知能力的至关重要的一步。传统概念分类体系大都由专家手工构建、质量精良,但是构建代价高昂,规模有限。本报告结合知识工场实验研发的大规模英文概念图谱ProbasePlus以及当前最大规模的中文概念图谱CN-Probase,介绍大规模高质量概念图谱的自动化构建方法,并介绍大规模概念图谱的应用场景以及相应的关键技术。

韩先培 中科院软件所
韩先培,博士,中国科学院软件研究所副研究员。主要研究方向是信息抽取、知识库构建、语义计算以及智能问答系统。在ACL、SIGIR、AAAI、EMNLP等重要国际会议发表论文30余篇。韩先培是中国中文信息学会语言与知识计算专业委员会副主任及中国中文信息学会青年工作委员会执行委员。于2016年获得中国中文信息学会汉王青年创新奖一等奖,入选2017-2019中国科协青年人才托举计划。
报告题目:面向知识图谱构建的信息抽取
报告摘要:
语义关系描述了实体及概念之间的关联与交互,是人类知识的核心组成部分。构建知识图谱的核心任务之一是从Web文本中抽取海量的语义关系。同时,每一段有意义的文本都描述了一组实体(时间、地点、人物、事件)以及这些实体相互之间的关联和交互,如何抽取文本中的实体和它们之间的语义关系也就成为了理解文本意义的基础。
针对上述任务,本报告将介绍近年来文本语义关系抽取技术上的相关进展,特别关注如何在Web环境下构建一个高性能的语义关系抽取系统。具体内容包括自扩展技术、远距离监督技术、半监督技术和自学习技术。同时本报告也对关系抽取技术在知识图谱和智能问答系统中的作用做一些个人思考。

邹磊 北京大学
邹磊,北京大学计算机科学技术研究所副教授、国家自然科学基金委优秀青年基金项目获得者,北京大学大数据科学研究中心主任助理。目前的主要研究领域包括图数据库,RDF知识图谱,尤其是基于图的RDF数据管理。邹磊及其团队构建了面向海量RDF知识图谱数据(超过100亿三元组规模)的开源图数据库系统。邹磊已经发表了30余篇国内外学术论文,包括数据库领域国际顶级期刊/会议论文(SIGMOD,VLDB等)近20余篇;其论文被引用超过1200多次(根据Google Scholar的统计),单篇最高被引用298余次。邹磊获得2009年中国计算机学会优秀博士学位论文提名奖和2014年中国计算机学会自然科学二等奖(排名第一)。
报告题目:面向知识图谱的自然语言问答研究
报告摘要:
自然语言问答(QA)是指利用各种技术和数据对用户提出的自然语言问题直接给出问题答案。QA任务根据所依赖的数据形态可以分成三类,分别是基于知识库的问答(KB-QA)、基于文档的问答(DB-QA)和社区问答(C-QA)。本次报告主要关注面向知识图谱的问答系统。知识图谱是目前知识库的一种常见的表达形式,是以图形(Graph)的方式来展现“实体”、实体“属性”,以及实体之间的“关系”。近年来随着大数据,人工智能等概念与技术的兴起,知识图谱和KB-QA相关的研究工作和工业应用逐渐引起重视。例如由Amazon收购的EVI系统(原名为TrueKnowledge)[1],就是一种面向开放领域的结构化知识的问答系统。Facebook定义的Facebook Social Graph,用于连接社交网络的用户,用户分享的照片,电影,评论;在所构建的Social Graph基础上,Facebook推出了Graph Search(图搜索)功能,即将用户的自然语言问题,转化为面向Social Graph上的图搜索问题,从而回答用户的自然语言问题。另外越来越多的chatbot(聊天机器人)产品中也引入了面向知识图谱的问答功能,使得chatbot和人交互时用户可以获得更多知识方面的回答。 IBM的Watson系统在参加智力问答节目《危险边缘》(Jeopardy)的比赛时,也同样采用DBpedia和Yago知识图谱数据来回答某些自然语言问题。本次报告主要介绍目前学术界和工业界面向知识图谱问答的主要关键技术和我们组在面向知识图谱的自然语言问答系统方面的工作gAnswer。

林欣 华东师范大学
林欣,男,博士,现担任华东师范大学计算机系副教授。目前主要致力于异构大数据管理研究。先后在该领域发表论文30余篇,其中近三年在中国计算机学会推荐的A类顶级期刊TKDE和A类会议ICDE发表论文8篇。2011年入选首批“香江学者计划”,赴香港浸会大学从事为期2年的访问研究。2014年回国后入选上海市“浦江人才计划”。现担任SCI杂志《Frontier of Computer Science》青年副主编,担任TKDE、TPDS等权威学术期刊的审稿人,并多次担任WAIM,ICPADS等国际会议的PC member。
报告题目:知识图谱的众包构建与精化
报告摘要:
知识图谱的构建是知识图谱领域中最受关注,也是最难的问题之一。由于语料来源杂乱不堪、自然语言处理技术存在瓶颈,完全靠机器并不能实现覆盖度和准确率双高。在构建的过程中,加入众包可以实现知识图谱的精化, 尤其在对计算机难以完成而人较容易完成的任务中,如实体对齐、范式匹配和关系判定等,众 包可以发挥更大的作用。本次课程从众包的基本原理展开,讲授其中若干关键子问题,如众包问题设计、质量控制等。结合知识图谱构建中面临的若干问题,分析各个众包的例子,讨论深智众包的设计原则。

陈文亮 苏州大学
陈文亮是苏州大学计算机科学与技术学院教授。2013年1月回国加入苏州大学计算机科学与技术学院。2005年-2010年在日本国立情报通信研究所担任专家研究员。2011年-2012年在新加坡国立信息通讯研究院担任研究科学家。目前担任中国中文信息学会知识与计算专委会委员、中国中文信息学会青年工作委员会委员、江苏省计算机学会青年工作委员会副主任委员、苏州计算机学会理事会秘书长。在研主持江苏省高校自然科学研究重大项目一项、国家自然科学基金一项,大型产业项目一项。主要研究领域包含语言分析、推荐系统、信息抽取、知识图谱。目前主要专注于建设基础语言分析平台和构建知识图谱。
报告题目:基于噪音训练数据的中文信息抽取研究
报告摘要:
中文信息抽取任务面临最大问题是缺乏相应人工标注语料,特别是在一些新领域和新应用里。如何有效利用一些噪音数据用于构建高性能系统成为迫在眉睫的问题。本报告将介绍:1)基于众包噪音数据的中文实体识别。利用苏州大学的自然语言处理任务标注系统(SNAP),普通标注人员可以完成多种实体类别的标注任务。这些众包数据和专家标注相比获取代价较低但存在大量的不一致标注。基于这种众包噪音数据,我们有效地搭建了中文实体识别系统,并在对话和电商领域测试中取得良好效果。2)基于远程监督数据的关系抽取。远程监督通过将知识库用于非结构化文本对齐来自动构建大规模训练数据,从而减轻对人工构建数据的依赖程度。在构建语料过程中,仅仅利用实体名称进行对齐,而不同实体在不同关系下应该具有更加丰富多样的语义表示,因此会造成错误标注等问题。针对该问题,我们提出基于句法上下文的实体表示来丰富实体在不同关系模式下的语义,并结合神经网络模型处理关系抽取任务。

赖坤锋 腾讯
赖坤锋博士,2013年毕业于香港理工大学,当前为腾讯MIG移动浏览产品部自然语言处理团队的负责人。主要研究兴趣包括:自然语言处理,用户画像,以及个性化推荐技术等。曾经在TMM,CIKM,NossDav,以及ICC等国际顶级会议发表文章。

钭伟雨 腾讯
钭伟雨,男,腾讯手机QQ浏览器知识图谱组负责人。2010年加入腾讯,主要专注于海量后台架构设计与开发,知识图谱的构建,包括大型爬虫网络设计,图存储,在线引擎,推理引擎,信息抽取,关系挖掘等。
报告题目:腾讯大规模知识图谱的构建与在自然语言理解中的应用
报告摘要:
知识图谱旨在描述真实世界中存在的各种实体、概念以及它们之间的关联关系,在语义搜索、智能问答、知识发现,个性化推荐等领域得到了广泛应用,随着人工智能技术的发展,知识图谱将扮演着越来越重要的角色。本报告结合腾讯手机QQ浏览器业务,介绍大规模高质量知识图谱的自动化构建方法,图存储及图谱开放平台的搭建,并介绍大规模知识图谱在腾讯手机QQ浏览器资讯业务上的应用。

陈虹 中兴通讯
陈虹,中兴通讯股份有限公司,NLP技术预研高级工程师,认知智能项目经理,长期专注于人工智能、智能问答、知识图谱和NLP等方向的研究,并且在NLP落地产品实际应用有6年以上的丰富项目经验,目前已有多款智能客服、语音助手等产品上线商用;同时也是公司大数据与人工智能委员会专家委员和NLP组组长、公司南京研究院人工智能委员会常务委员,江苏省大数据专委会委员和江苏省人工智能协会会员,发表专利和论文十余篇。
报告题目:Application and thinking of knowledge graph and its variants in industry practice (知识图谱及其“变种”在行业实践中的应用与思考)
报告摘要:知识是人工智能时代的基石,而知识图谱是蕴含人类大量先验知识的宝库,有人将其比喻为“通往强人工智能之路的石油”,可见其不可或缺的地位。知识图谱的应用价值在于,它能够改变现有的信息检索方式,一方面通过推理实现概念检索;另一方面以图形化方式向用户展示经过分类整理的结构化知识。在数据多维异构、领域模式多样化等现状中,将知识图谱的价值最大化,工业界责无旁贷。
本报告将介绍知识图谱在行业实践中的应用场景,面对不同的场景,现有的知识图谱scheme是否具有普适性?针对特定场景,工业界需要如何“定制”自己的知识图谱,从而形成哪些“变种”?同时知识图谱还有哪些疑难问题是需要学术界和工业界共同探索研究的?

周柳阳 智言科技
周柳阳博士,2014年毕业于香港城市大学,毕业后于某大数据公司负责基于深度学习的语义理解和智能推理的产品化等工作。2016年作为联合创始人成立了智言科技有限公司。智言科技是一家专注于深度学习和文本语义理解技术突破的人工智能公司,致力于智能对话技术的研发和创新,以知识图谱构建整个问答体系,为企业提供更懂用户需求的智能问答系统,以用于智能客服、虚拟助理、智能家居等对话交互场景。智言科技的研发团队博士占比为30%,与国内外高校保持紧密的学术合作,其人工智能语义理解平台(Webot),为企业提供国际领先、定制化的语义理解解决方案。目前,智言科技的产品已在互联网金融、在线教育、保险、在线旅游等新兴行业以及物流等传统行业落地。
报告题目:知识图谱在工业界智能问答系统中的应用
报告摘要:
基于知识图谱的智能问答受到工业界和学术界的大力关注,其在提高企业效率、变革交互方式等方面发挥着重要作用。在企业实际落地的过程中,面临着初期数据缺少(冷启动)以及在获取大量数据后模型持续更新等问题。此外,客户数据的多样性、业务逻辑的复杂性,使得单一的基于结构化数据(知识图谱)的问答难以覆盖所有业务场景。本报告首先详细介绍智言科技在冷启动时,如何使用无监督方法落地单轮、多轮对话、图谱构建和基于图谱的问答系统。此外,在获取一定量的标注数据后,该报告进一步介绍了基于深度神经网络的模型在语义匹配、知识图谱构建、对话管理以及非结构化文本问答等方面的落地实施。最后,会简要的讨论如何在生产环境中持续优化模型。
主办单位
苏州大学先进数据分析研究中心
http://ada.suda.edu.cn
复旦大学知识工场实验室
http://kw.fudan.edu.cn
赞助单位
国家自然科学基金
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 进行报名



