【DCGAN】民科带你读文章: 用DCGAN补全图片
用DCGAN补全图片
作者:王栋
来源:硅谷程序汪
在七月初的长周末里,我去了加州北边的旅游景点转了转,发现到处人山人海,拍出来的照片也人头攒动。于是我想,如果能把这些人轻松地从图片中PS掉就好了。

Image CC licensed, https://www.flickr.com/photos/_belial/4574420578
进行了一些简单的研究,发现这件事情并不容易,因为风景图片太过于丰富,而我既没有足够的训练数据,也没有足够的计算资源(后来意识到我应该研究content aware image completion)。但我乘着这个机会读完了一年前收藏的一篇文章“Image Completion with Deep Learning in TensorFlow”,也跑了一下他们的程序,收获颇丰,于是今天来讲讲这篇文章是怎么利用DCGAN (Deep Convolutional Generative Adversarial Networks)来自动补全人脸。
原文较长,我这里会省略第一部分基础,将主要精力放在DCGAN的理论基础以及如何使用DCGAN补全人脸上,其中很多地方我会加上他们的程序注释,帮助大家更好的理解。
DCGAN入门
GAN是今天要讲的问题的算法基础,它是由Ian Goodfellow在2014年NIPS提出的,全名叫“Generative Adversarial Networks”,是通过机器学习自动生成图片的经典之作。
传统的机器学习都是在优化算法输出和目标输出之间的相似度,然而对于图片这一问题,每个像素之间的相似度其实对图片整体效果的影响并不大。于是GAN提出通过两个网络,G (Generator)和D (Discrimintor)来分别生成图片和评价图片好坏。
生成网络G的目标是生成尽量真实的图片去欺骗D,判别网络D的目标是尽量区别G生成的图片和真实图片,G和D一起构成了一个博弈过程(下文会提到)。
先来说说G,对于任意给定随机向量z,我们通过一段代码生成图片(函数G在下文中会提到)。
z=np.random.uniform(-1, 1, n)
def G(z):
...
Return image sample
image = G(z)
这里的G(z)就是一个深度生成网络,在2016年ICLR,Alec Radford,Luke Metz和Soumith Chintala发表了“Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”,提出了用深度卷积生成图片。
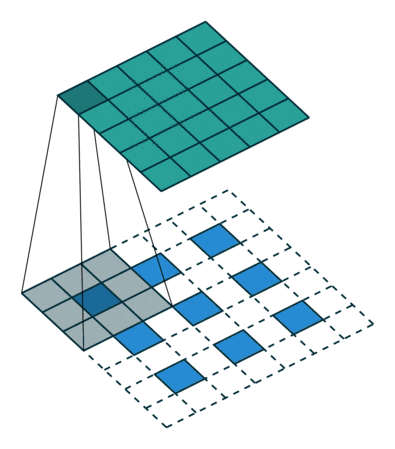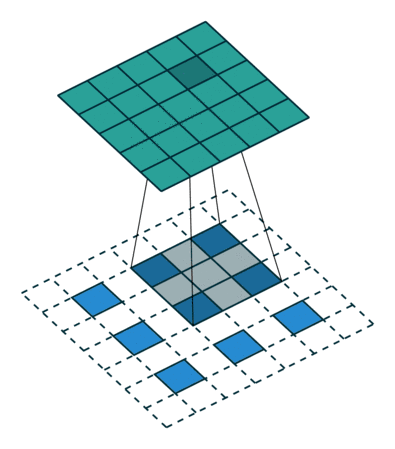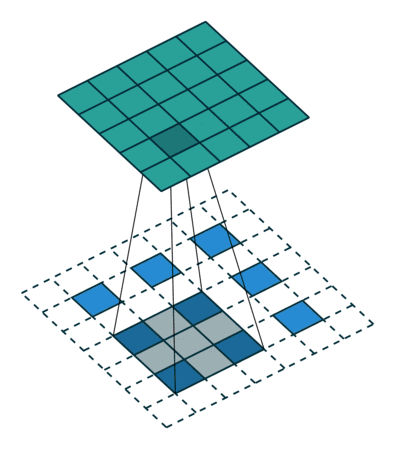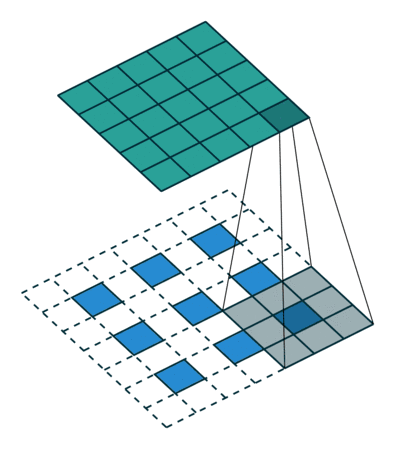
想要了解fractionally strided convolution的工作原理,首先要知道什么是基本的CNN,在我之前的一篇文章中有简要的介绍,但最好还是看一下“A guide to convolution arithmetic for deep learning”的介绍。下图就是一段利用3X3的矩阵对5X5的图片进行步长为2,padding为1的卷积的过程。
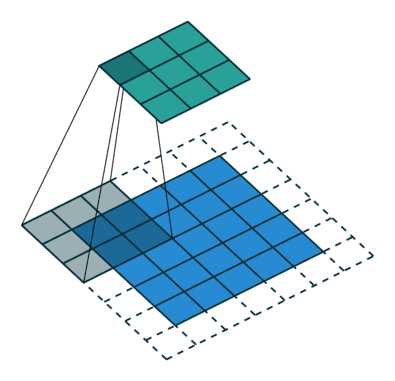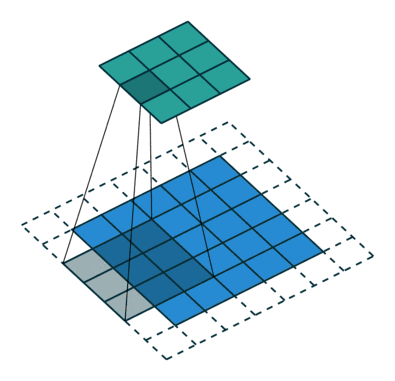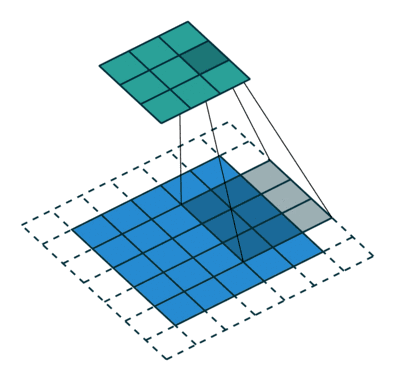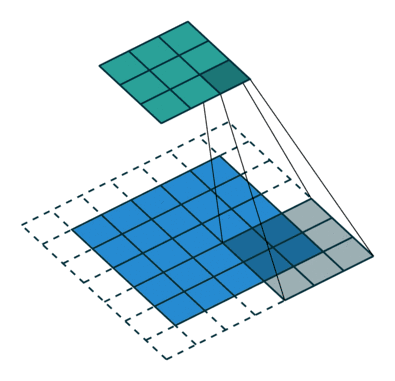
通常,对图片做卷积,得到的小矩阵可以看做一个小图片块,维度逐步减小,但是在生成网络中我们想要通过一个简单的向量生成一个大的图片。Fractionally strided convolution就是这样一个反向生成的过程,也是反卷积的一种。我们对卷积后的图片每一个点增加值为0的边界,然后用原先3X3的矩阵扫描,最终如下图一样将一个3X3的卷积后矩阵变成5X5的卷积前矩阵。
通过一系列fractionally strided convolution,我们最终可以得到一个64X64的图片。
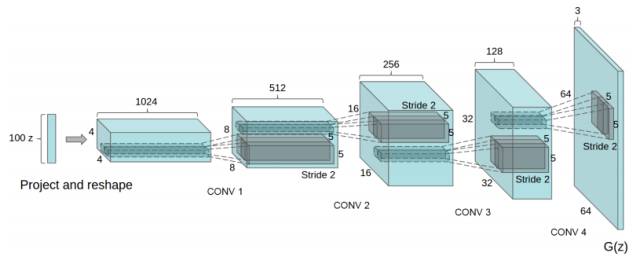
这一过程写成代码大致是这样:
def generator(self, z):
# 将输入映射到gf_dim*8*4*4大小的conv nn上
self.z_, self.h0_w, self.h0_b = linear(
z, self.gf_dim*8*4*4, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
# 不断地缩小conv nn层数,增加dimension
self.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,
[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = conv2d_transpose(h1,
[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = conv2d_transpose(h2,
[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
# 将最终conv nn转化成3色图片
h4, self.h4_w, self.h4_b = conv2d_transpose(h3,
[self.batch_size, 64, 64, 3], name='g_h4', with_w=True)
return tf.nn.tanh(h4)
反卷积被应用到各种模型生成当中,大家对这方面有疑问可以看看Ldy在github上的文章“Transposed Convolution, Fractionally Strided Convolution or Deconvolution”。
从G到D
有了生成网络,下一步就需要能够评价生成图片的评价系统D。这个评价系统D(x)输入是图像x,返回x来自真实图片分布P_data的可能性。评价网络应该在数据来自P_data的情况尽量返回1,在来自生成网络分布P_g的情况下返回0。最简单的DCGAN采用convolutional network来进行评价。
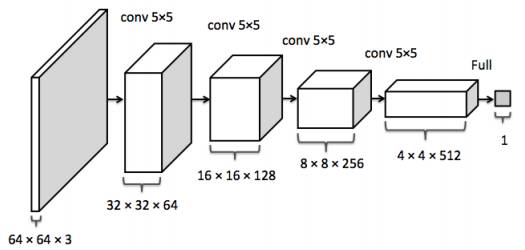
代码如下:
def discriminator(self, image, reuse=False):
if reuse:
tf.get_variable_scope().reuse_variables()
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [-1, 8192]), 1, 'd_h3_lin')
return tf.nn.sigmoid(h4), h4
训练GAN
在我们训练这个评价函数D(x)的时候,我们需要
- 对于每一个来自P_data的x,最大化D(x)
- 对于每一个不是来自P_data的x,最小化D(x)
生成网络G(z)试图欺骗D,所以会根据D的反馈优化输出的图像,也就是最大化D(G(z)),相当于优化1-D(G(z)),因为D的返回值在(0,1)区间内。整体过程就和GAN论文中提到的一样,是一个极小极大值过程(Minimax game),一方面我们最大化D的判断准确率,令一方面我们最小化G生成图片和真实图片的差异。
在训练过程中,我们会分别更新判别网络D和生成网络G中的参数,具体过程伪代码可以参见GAN论文。

定义loss和optimizer的代码大致如下:
# 针对真实图片的Loss
self.d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.D_logits, labels=tf.ones_like(self.D)))
# 针对假图片的Loss
self.d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.D_logits_, labels=tf.zeros_like(self.D_)))
# 针对生成网络G的Loss
self.g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.D_logits_, labels=tf.ones_like(self.D_)))
# 针对网络D和G的分别优化函数
d_optim = tf.train.AdamOptimizer(
config.learning_rate,
beta1=config.beta1).minimize(
self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(
config.learning_rate,
beta1=config.beta1).minimize(
self.g_loss, var_list=self.g_vars)
我进行了几千轮训练,这里是运行https://github.com/bamos/dcgan-completion.tensorflow代码后得到的人脸生成效果,感觉还不是很好,由于没有GPU,所以训练花费时间很长,我还需要等几天。
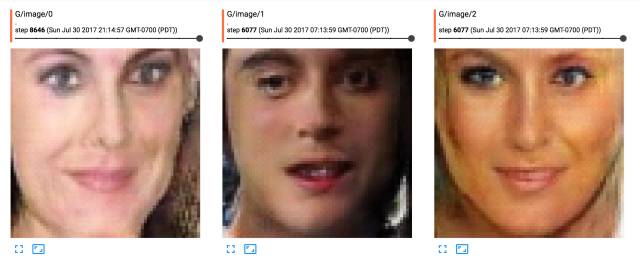
图片补全的过程
现在我们有了判别网络D(x)和生成网络G(z),接下来我们会用到“Semantic Image Impainting with Perceptual and Contextual Losses”中提到的方法补全图片。
想要补全一张图片y,一种听起来比较合理但实际上不太可行的方法就是直接优化D(y)。论文中给出了一个样例我并没有完全看懂,大意是说这样的做法可能得到的图片既不满足原始数据分布P_data,也不满足生成概率P_g。希望对这一部分认识深刻的人可以给我留言讲解一下。
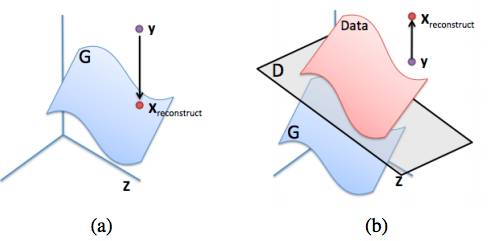
为了解决图片补全这一问题,该论文提出了一个binary mask的概念,也就是一个只包含0和1的矩阵M,我们将原始图片y和这一矩阵M每一个元素相乘,矩阵M中为1的位置就会透过原始图片。如果我们的生成函数G产生了图片G(z),就可以与(1-M)中每一个元素相乘,得到补全部分。全图则是M⊙y+(1-M)⊙G(z)。
为了找到这样的图片G(z),我们定义两种不同形式的loss:
Contextual Loss:也就是上下文相关的Loss,这里我们需要补全的图片上下文就是原图中我们可以看到的部分M⊙y,我们需要最小化||M⊙G(z)-M⊙y||,这种情况写成代码就是:
self.contextual_loss = tf.reduce_sum(tf.contrib.layers.flatten( tf.abs(
tf.multiply(self.mask, self.G) - tf.multiply(self.mask, self.images))), 1)
Perceptual Loss,也就是关于生成图片多么像真实图片的Loss,也就对应着上文中提到的log(1-D(G(z)))。
我们将Contextual Loss和Perceptual Loss通过一个lambda合并到一起,就得到了全新的Loss,结合上面提到的Perceptual Loss,这段代码可以写为:
self.perceptual_loss = self.g_loss
self.complete_loss = self.contextual_loss + self.lam * self.perceptual_loss
将这上面所有的东西合并到一起,我们就可以不断地生成新的图片,计算最终loss对应生成向量z的导数,然后通过自己实现的Adam Optimizer对placeholder z进行调整,一切都在代码里:
for idx in xrange(0, batch_idxs):
batch_images = ...
batch_mask = np.resize(mask, [self.batch_size] + self.image_shape)
zhats = np.random.uniform(-1, 1, size=(self.batch_size, self.z_dim))
v = 0
for i in xrange(config.nIter):
fd = {
self.z: zhats,
self.mask: batch_mask,
self.images: batch_images,
}
run = [self.complete_loss, self.grad_complete_loss, self.G]
loss, g, G_imgs = self.sess.run(run, feed_dict=fd)
v_prev = np.copy(v)
v = config.momentum*v - config.lr*g[0]
zhats += -config.momentum * v_prev + (1+config.momentum)*v
zhats = np.clip(zhats, -1, 1)
以下是一段最终效果动画,我目前还处于人脸生成阶段,还没有对补全进行测试,所以暂时没有什么心得可以分享。

小结
感谢大家阅读今天的民科与你分享环节。突然想起之前收藏的这篇文章,于是试了试里面的算法,学到了不少东西但也发现简单的GAN在我现有的计算资源和数据上并不能得到很好的效果,经过一番调查我又发现了不少有趣的文章:
1. Neural Fill: Content Aware Image Fill with Generative Adversarial Neural Networks
2. Globally and Locally Consistent Image Completion
3. Scene Completion Using Millions of Photographs
4. Image Completion with Structure Propagation
等我再给自己充充电,再与大家继续分享,希望喜欢程序汪的朋友多多关注和分享我的内容,也希望大家与我多多交流,支持我的贡献一个GPU机器吧。
☞ 【学界】清华朱军团队探索DNN内部架构,采用对抗性例子监督网络生成及错误
☞ 【几何图景】GAN的几何图景:样本空间的Morse流,与鉴别网络D为何不可能真正鉴别真假
☞ 【应用】生成式对抗网络GAN有哪些最新的发展,可以实际应用到哪些场景中?
☞ 【从头开始GAN】Goodfellow开山之作到DCGAN等变体
☞ 【智能自动化学科前沿讲习班第1期】上海交大倪冰冰副教授:面向图像序列的生成技术及应用初探
☞ 【智能自动化学科前沿讲习班第1期】University of Central Florida 的Guojun Qi:LS-GAN
☞ 【智能自动化学科前沿讲习班第1期】微软秦涛主管研究员:从单智能体学习到多智能体学习
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【原理】十个生成模型(GANs)的最佳案例和原理 | 代码+论文
☞ 【教程】经得住考验的「假图片」:用TensorFlow为神经网络生成对抗样本
☞ 【模型】基于深度学习的三大生成模型:VAE、GAN、GAN的变种模型
☞ 【大会】还记得Wasserstein GAN吗?不仅有Facebook参与,也果然被 ICML 接收
☞ 【学界】邢波团队提出contrast-GAN:实现生成式语义处理
☞ 【专栏】阿里SIGIR 2017论文:GAN在信息检索领域的应用
☞ 【学界】康奈尔大学说对抗样本出门会失效,被OpenAI怼回来了!
☞ 警惕人工智能系统中的木马、病毒 ——深度学习对抗样本简介
☞ 【生成图像】Facebook发布的LR-GAN如何生成图像?这里有一篇Pytorch教程
☞ 【智能自动化学科前沿讲习班第1期】国立台湾大学(位于中国台北)李宏毅教授:Anime Face Generation
☞ 【变狗为猫】伯克利图像迁移cycleGAN,猫狗互换效果感人
☞ 【论文】对抗样本到底会不会对无人驾驶目标检测产生干扰?又有人发文质疑了
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【专栏】基于对抗学习的生成式对话模型的坚实第一步 :始于直观思维的曲折探索
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【最新】OpenAI:3段视频演示无人驾驶目标检测强大的对抗性样本!
☞ 【论文】CVPR 2017最佳论文出炉,DenseNet和苹果首篇论文获奖
☞ 【深度学习】解析深度学习的局限性与未来,谷歌Keras之父「连发两文」发人深省
☞ 苹果重磅推出AI技术博客,CVPR合成逼真照片论文打响第一枪
☞ 【Ian Goodfellow 五问】GAN、深度学习,如何与谷歌竞争
☞ 【巨头升级寡头】AI产业数据称王,GAN和迁移学习能否突围BAT垄断?
☞ 【高大上的DL】BEGAN: Boundary Equilibrium GAN
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【最全GAN变体列表】Ian Goodfellow推荐:GAN动物园
☞ 【DCGAN】深度卷积生成对抗网络的无监督学习,补全人脸合成图像匹敌真实照片
☞ 【开源】收敛速度更快更稳定的Wasserstein GAN(WGAN)
☞ 【Valse 2017】生成对抗网络(GAN)研究年度进展评述
☞ 【开源】谷歌新推BEGAN模型用于人脸数据集:效果惊人!
☞ 【深度】Ian Goodfellow AIWTB开发者大会演讲:对抗样本与差分隐私
☞ 论文引介 | StackGAN: Stacked Generative Adversarial Networks
☞ 【纵览】从自编码器到生成对抗网络:一文纵览无监督学习研究现状
☞ 【论文解析】Ian Goodfellow 生成对抗网络GAN论文解析
☞ 【推荐】条条大路通罗马LS-GAN:把GAN建立在Lipschitz密度上
☞【Geometric GAN】引入线性分类器SVM的Geometric GAN
☞ 【GAN for NLP】PaperWeekly 第二十四期 --- GAN for NLP
☞ 【Demo】GAN学习指南:从原理入门到制作生成Demo
☞ 【学界】伯克利与OpenAI整合强化学习与GAN:让智能体学习自动发现目标
☞ 【人物 】Ian Goodfellow亲述GAN简史:人工智能不能理解它无法创造的东西
☞ 【DCGAN】DCGAN:深度卷积生成对抗网络的无监督学习,补全人脸合成图像匹敌真实照片
☞ 带你理解CycleGAN,并用TensorFlow轻松实现
☞ PaperWeekly 第39期 | 从PM到GAN - LSTM之父Schmidhuber横跨22年的怨念
☞ 【CycleGAN】加州大学开源图像处理工具CycleGAN
☞ 【SIGIR2017满分论文】IRGAN:大一统信息检索模型的博弈竞争
☞ 【贝叶斯GAN】贝叶斯生成对抗网络(GAN):当下性能最好的端到端半监督/无监督学习
☞ 【贝叶斯GAN】贝叶斯生成对抗网络(GAN):当下性能最好的端到端半监督/无监督学习
☞ 【GAN X NLP】自然语言对抗生成:加拿大研究员使用GAN生成中国古诗词
☞ ICLR 2017 | GAN Missing Modes 和 GAN
☞ 【学界】CMU新研究试图统一深度生成模型:搭建GAN和VAE之间的桥梁
☞ 【专栏】大漠孤烟,长河落日:面向景深结构的风景照生成技术
☞ 【开发】最简单易懂的 GAN 教程:从理论到实践(附代码)
☞ 【论文访谈】求同存异,共创双赢 - 基于对抗网络的利用不同分词标准语料的中文分词方法
☞ 【LeCun论战Yoav】自然语言GAN惹争议:深度学习远离NLP?
☞ 【争论】从Yoav Goldberg与Yann LeCun争论,看当今的深度学习、NLP与arXiv风气
☞ 【观点】Yoav Goldberg撰文再回应Yann LeCun:「深度学习这群人」不了解NLP(附各方评论)
☞ PaperWeekly 第41期 | 互怼的艺术:从零直达 WGAN-GP
☞ 【谷歌 GAN 生成人脸】对抗创造新艺术风格,128 像素扩展到 4000
☞ 【原理】只知道GAN你就OUT了——VAE背后的哲学思想及数学原理




