从DCGAN到SELF-MOD:GAN的模型架构发展一览

作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
事实上,O-GAN 的发现,已经达到了我对 GAN 的理想追求,使得我可以很惬意地跳出 GAN 的大坑了。所以现在我会试图探索更多更广的研究方向,比如 NLP 中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的 GAN 的学习结果都记录下来。
这篇文章中,我们来梳理一下 GAN 的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是 GAN 在图像方面的模型架构发展,跟 NLP 的 SeqGAN 没什么关系。
此外,关于 GAN 的基本科普,本文就不再赘述了。
话在前面
当然,从广义上来讲,图像领域的分类模型的任何进展,也算是判别器的进展(因为都是分类器,相关的技术都可能用到判别器中),而图像分类模型本质上从 ResNet 之后就没有质的变化,这也说明 ResNet 结构对判别器基本上是最优选择了。
但是生成器不一样,虽然从 DCGAN 之后 GAN 的生成器也形成了一些相对标准的架构设计,但远说不上定型,也说不上最优。直到最近也有不少工作在做生成器的新设计,比如 SAGAN 就是将 Self Attention 引入到了生成器(以及判别器)中,而大名鼎鼎的 StyleGAN 就是在 PGGAN 的基础上引入了一个风格迁移形式的生成器。
因此,很多工作都表明,GAN 的生成器的结果还有一定的探索空间,好的生成器架构能加速 GAN 的收敛,或者提升 GAN 的效果。
DCGAN
要谈到 GAN 架构发展史,肯定不得不说到 DCGAN 的,它在 GAN 史上称得上是一个标志性事件。
基本背景
众所周知,GAN 起源于 Ian Goodfellow 的文章 Generative Adversarial Networks [1],但早期的 GAN 仅仅局限在 MNIST 这样的简单数据集中。这是因为 GAN 刚出来,虽然引起了一波人的兴趣,但依然还处于试错阶段,包括模型架构、稳定性、收敛性等问题都依然在探索中。而 DCGAN 的出现,为解决这一系列问题奠定了坚实的基础。
DCGAN 出自文章 Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks [2]。要说它做了什么事情,其实也简单:它提出了一种生成器和判别器的架构,这个架构能极大地稳定 GAN 的训练,以至于它在相当长的一段时间内都成为了 GAN 的标准架构。
说起来简单,但事实上能做到这个事情很不容易,因为直观上“合理”的架构有很多,从各种组合中筛选出近乎最优的一种,显然是需要经过相当多的实验的。
而正因为 DCGAN 几乎奠定了 GAN 的标准架构,所以有了 DCGAN 之后,GAN 的研究者们可以把更多的精力放到更多样的任务之上,不再过多纠结于模型架构和稳定性上面,从而迎来了 GAN 的蓬勃发展。
架构描述
好了,说了这么多,我们回到架构本身的讨论之上。DCGAN 所提出的模型架构大致如下:
1. 生成器和判别器均不采用池化层,而采用(带步长的)的卷积层;其中判别器采用普通卷积(Conv2D),而生成器采用反卷积(DeConv2D);
2. 在生成器和判别器上均使用 Batch Normalization;
3. 在生成器除输出层外的所有层上使用 RelU 激活函数,而输出层使用 Tanh 激活函数;
4. 在判别器的所有层上使用 LeakyReLU 激活函数;
5. 卷积层之后不使用全连接层;
6. 判别器的最后一个卷积层之后也不用 Global Pooling,而是直接 Flatten。
其实现在看来,这还是一种比较简单的结构,体现了大道至简的美感,进一步证明了好的必然是简洁的。
DCGAN 的结构示意图如下:
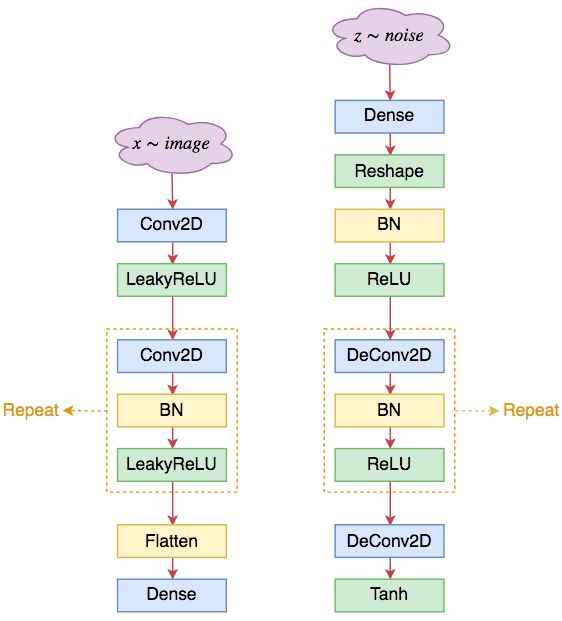
▲ DCGAN的判别器架构(左)和生成器架构(右)
个人总结
几个要点:
1. 卷积和反卷积的卷积核大小为 4*4 或者 5*5;
2. 卷积和反卷积的 stride 一般都取为 2;
3. 对于判别器来说,第一层卷积后一般不用 BN,而后面都是“Conv2D+BN+LeakReLU”的组合模式,直到 feature map 的大小为 4*4;
4. 对于生成器来说,第一层是全连接,然后 reshape 为 4*4 大小,然后是“Conv2D+BN+ReLU”的组合模式,最后一层卷积则不用 BN,改用 tanh 激活;相应地,输入图片都要通过除以 255 然后乘以 2 减去 1,来缩放到 -1~1 之间。
虽然从参数量看可能很大,但事实上 DCGAN 很快,而且占显存不算多,所以很受大家欢迎。因此虽然看起来很老,但至今仍然很多任务都在用它。至少在快速实验上,它是一种优秀的架构。
ResNet
随着 GAN 研究的日益深入,人们逐渐发现了 DCGAN 架构的一些不足之处。
DCGAN的问题
公认的说法是,由于 DCGAN 的生成器中使用了反卷积,而反卷积固有地存在“棋盘效应(Checkerboard Artifacts)”,这个棋盘效应约束了DCGAN的生成能力上限。关于棋盘效应,详细可以参考 Deconvolution and Checkerboard Artifacts [3](强烈推荐,超多效果图示)。

▲ 棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章 Deconvolution and Checkerboard Artifacts
准确来说,棋盘效应不是反卷积的问题,而是 stride > 1 的固有毛病,这导致了卷积无法“各项同性”地覆盖整张图片,而出现了交错效应,如同国际象棋的棋盘一般。而反卷积通常都要搭配 stride > 1 使用,因此通常认为是反卷积的问题。
事实上,除了反卷积,膨胀卷积也会有棋盘效应,因为我们可以证明膨胀卷积在某种转化下,其实等价于 stride > 1 的普通卷积。
另一方面,笔者估计还有一个原因:DCGAN 的非线性能力也许不足。分析过 DCGAN 结果的读者会留意到,如果输入的图片大小固定后,整个 DCGAN 的架构基本都固定的,包括模型的层数。
唯一可以变化的似乎就只有卷积核大小(通道数也可以稍微调整,但其实调整空间不大),改变卷积核大小可以在一定程度上改变模型的非线性能力,但改变卷积核大小仅仅改变了模型的宽度,而对于深度学习来说深度可能比宽度更重要。问题就是对于 DCGAN 来说,没有一种自然而直接的方法来增加深度。
ResNet模型
由于以上原因,并且随着 ResNet 在分类问题的日益深入,自然也就会考虑到 ResNet 结构在 GAN 的应用。事实上,目前 GAN 上主流的生成器和判别器架构确实已经变成了 ResNet,基本结果图示如下:
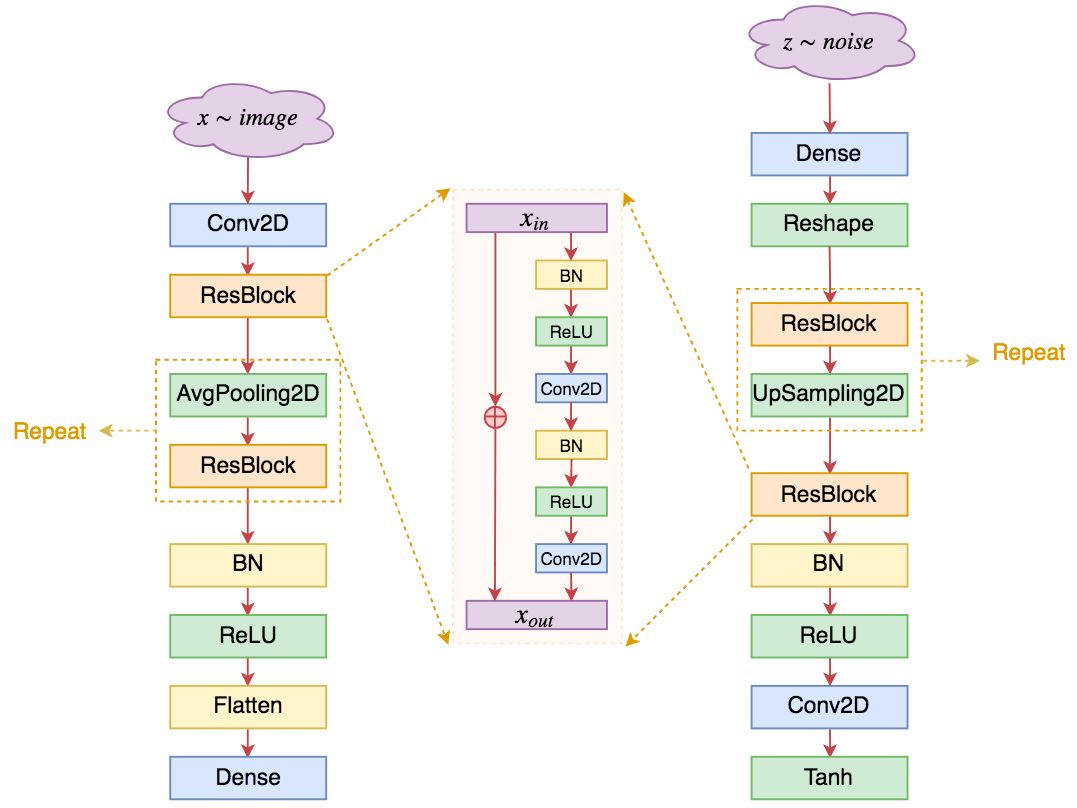
▲ 基于ResNet的判别器架构(左)和生成器架构(右),中间是单个ResBlock的结构
可以看到,其实基于 ResNet 的 GAN 在整体结构上与 DCGAN 并没有太大差别(这进一步肯定了 DCGAN 的奠基作用),主要的特点在于:
1. 不管在判别器还是生成器,均去除了反卷积,只保留了普通卷积层;
2. 卷积核的大小通常统一使用 3*3 的,卷积之间构成残差块;
3. 通过 AvgPooling2D 和 UpSampling2D 来实现上/下采样,而 DCGAN 中则是通过 stride > 1 的卷积/反卷积实现的;其中 UpSampling2D 相当于将图像的长/宽放大若干倍;
4. 由于已经有残差,所以激活函数可以统一使用 ReLU,当然,也有一些模型依然使用 LeakyReLU,其实区别不大;
5. 通过增加 ResBlock 的卷积层数,可以同时增加网络的非线性能力和深度,这也是 ResNet 的灵活性所在;
6. 一般情况下残差的形式是 x+f(x),其中 f 代表卷积层的组合;不过在 GAN 中,模型的初始化一般要比常规分类模型的初始化更小,因此稳定起见,有些模型干脆将其改为 x+α×f(x),其中 α 是一个小于 1 的数,比如 0.1,这样能获得更好的稳定性;
7. 有些作者认为 BN 不适合 GAN,有时候会直接移除掉,或者用 LayerNorm 等代替。
个人总结
我没有认真考究过首先把 ResNet 用在 GAN 中是哪篇文章,只知道 PGGAN、SNGAN、SAGAN 等知名 GAN 都已经用上了 ResNet。ResNet 的 stride 都等于 1,因此足够均匀,不会产生棋盘效应。
然而,ResNet 并非没有缺点。虽然从参数量上看,相比 DCGAN,ResNet 并没有增加参数量,有些情况下甚至比 DCGAN 参数量更少,但 ResNet 比 DCGAN 要慢得多,所需要的显存要多得多。
这是因为 ResNet 层数更多、层之间的连接更多,所以导致梯度更复杂,并且并行性更弱了(同一层卷积可以并行,不同层卷积是串联的,无法直接并行),结果就是更慢了,更占显存了。
还有,棋盘效应实际上是一种非常细微的效应,也许仅仅是在高清图生成时才能感受到它的差异。
事实上在我的实验中,做 128*128 甚至 256*256 的人脸或 LSUN 生成,并没有明显目测到 DCGAN 和 ResNet 在效果上的差异,但是 DCGAN 的速度比 ResNet 快 50% 以上,在显存上,DCGAN 可以直接跑到 512*512 的生成(单个 1080ti),而 ResNet 的话,跑 256*256 都有些勉强。
因此,如果不是要 PK 目前的最优 FID 等指标,我都不会选择 ResNet 架构。
SELF-MOD
正常来说,介绍完 ResNet 后,应该要介绍一下 PGGAN、SAGAN 等模型的,毕竟从分辨率或者 IS、FID 等指标上来看,它们也算是一个标志性事件。
不过我并不打算介绍它们,因为严格来讲,PGGAN 并不是一种新的模型架构,它只是提供了一个渐进式的训练策略,这种训练策略可以用到 DCGAN 或 ResNet 架构上;而 SAGAN 其实改动并不大,标准的 SAGAN 只不过在普通的 DCGAN 或 ResNet 架构中间,插入了一层 Self Attention,不能算生成器架构上的大变动。
接下来介绍一个比较新的改进:Self Modulated Generator,来自文章 On Self Modulation for Generative Adversarial Networks [4],我这里直接简称为“SELF-MOD”好了。
条件BN
要介绍 SELF-MOD 之前,还需要介绍一个东西:Conditional Batch Normalization(条件 BN)。
众所周知,BN 是深度学习尤其是图像领域常见的一种操作。说实话我不大喜欢 BN,但不得不说的是它在不少 GAN 模型中发挥了重要作用。常规的 BN 是无条件的:对于输入张量,其中 i,j,k,l 分别表示图像的 batch、长、宽、通道维度,那么在训练阶段有:
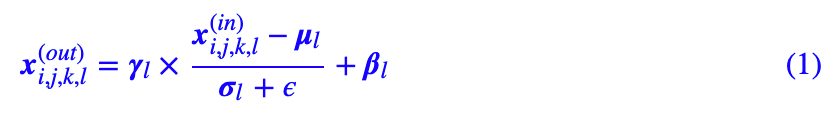
其中:
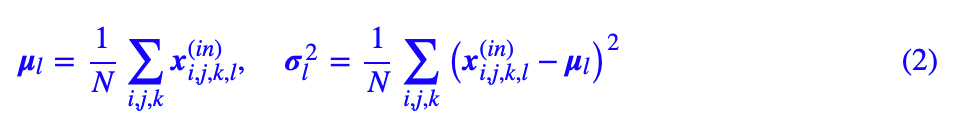
是输入批数据的均值方差,其中 N=batch_size×长×宽,而 β,γ 是可训练参数,ϵ 则是小的正常数,用来防止除零错误。除此之外,维护一组滑动平均变量,在测试阶段的使用滑动平均的均值方差。
之所以说这样的 BN 是无条件的,是因为参数 β,γ 纯粹由梯度下降得到,不依赖于输入。相应地,如果 β,γ 依赖于某个输入 y,那么就称为条件 BN:
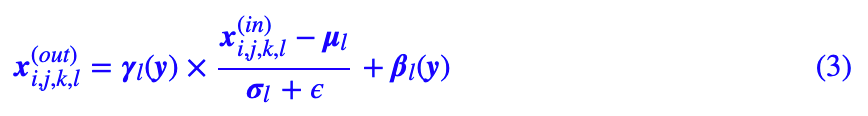
这时候 βl(y),γ(y) 是某个模型的输出。先来说说怎么实现。其实在 Keras 中,实现条件 BN 非常容易,参考代码如下:
def ConditionalBatchNormalization(x, beta, gamma):
"""为了实现条件BN,只需要将Keras自带的BatchNormalization的
beta,gamma去掉,然后传入外部的beta,gamma即可;为了训练上的稳定,
beta最好能做到全0初始化,gamma最好能做到全1初始化。
"""
x = BatchNormalization(center=False, scale=False)(x)
def cbn(x):
x, beta, gamma = x
for i in range(K.ndim(x)-2):
# 调整beta的ndim,这个根据具体情况改动即可
beta = K.expand_dims(beta, 1)
gamma = K.expand_dims(gamma, 1)
return x * gamma + beta
return Lambda(cbn)([x, beta, gamma])SELF-MOD GAN
条件BN首先出现在文章 Modulating early visual processing by language 中,后来又先后被用在 cGANs With Projection Discriminator 中,目前已经成为了做条件 GAN(cGAN)的标准方案,包括 SAGAN、BigGAN 都用到了它。
简单来说,它就是把条件 c 作为 β,γ 的条件,然后构成条件 BN,替换掉生成器的无条件 BN。也就是说,生成器的主要输入还是随机噪声 z,然后条件 c 则传入到生成器的每一个 BN 中。
说那么多条件 BN,它跟 SELF-MOD 有什么关系呢?
情况是这样的:SELF-MOD 考虑到 cGAN 训练的稳定性更好,但是一般情况下 GAN 并没有标签 c 可用,那怎么办呢?干脆以噪声 z 自身为标签好了!这就是 Self Modulated 的含义了,自己调节自己,不借助于外部标签,但能实现类似的效果。用公式来描述就是:
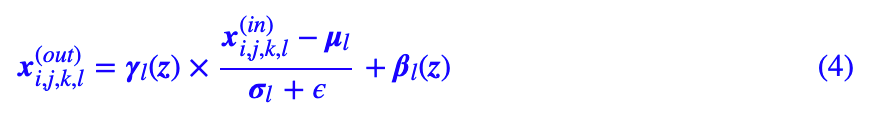
在原论文中,β(z) 是两层全连接网络:
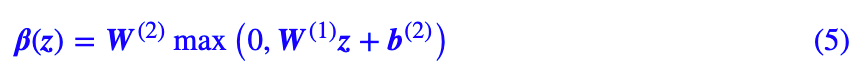
γ(z) 也是一样的,而且看了下官方源代码,发现中间层的维度可以取得更小一些,比如 32,这样不会明显增加参数量了。
这就是无条件 GAN 的 SELF-MOD 结构的生成器。
个人总结
我结合了自己的 O-GAN 实验了一下 SELF-MOD 结构,发现收敛速度几乎提升了 50%,而且最终的 FID 和重构效果都更优一些,SELF-MOD 的优秀可见一斑,而且隐隐有种感觉,似乎 O-GAN 与 SELF-MOD 更配(哈哈,不知道是不是自恋的错觉)。
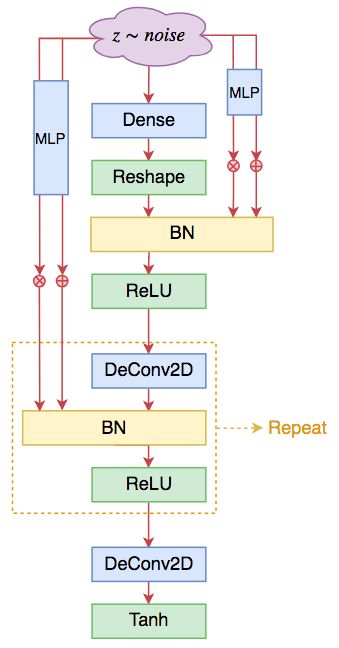
▲ SELF-MOD形式的DCGAN生成器。基于ResNet的也类似,都只是将BN替换成SELF-MOD版本的
Keras 参考代码如下:
https://github.com/bojone/o-gan/blob/master/o_gan_celeba_sm_4x4.py
另外,哪怕在 cGAN 中,也可以用 SELF-MOD 结构。标准的 cGAN 是将条件 c 作为 BN 的输入条件,SELF-MOD 则是将 z 和 c 同时作为 BN 的输入条件,参考用法如下:
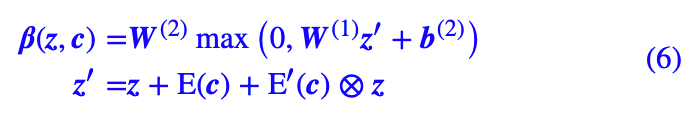
其中 E,E′ 是两个 Embedding 层,类别数比较少的情况下,直接理解为全连接层就行了,γ 同理。
其他架构
读者可能很奇怪,怎么还没谈到著名的 BigGAN [5] 和 StyleGAN [6]?
事实上,BigGAN 并没有做模型架构做出特别的改进,而且作者本身也承认这只不过是“暴力出奇迹”罢了;而对于 StyleGAN,它确实改进了模型架构,但是理解了前面的 SELF-MOD 之后,其实也就不难理解 StyleGAN 了,甚至可以将 StyleGAN 看成是 SELF-MOD 的一个变种。
AdaIN
StyleGAN 的核心,是一个叫做AdaIN(Adaptive Instance Normalization)的玩意,来源于风格迁移的文章 Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization [7]。它其实跟条件 BN 差不多,甚至比条件 BN 还简单:
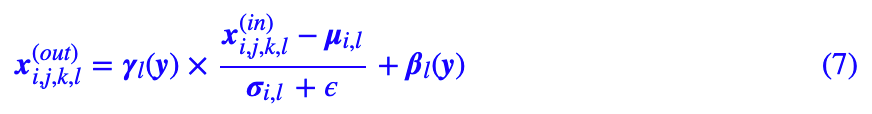
跟条件 BN 的差别是:条件 BN 是 μl 和 σl,而 AdaIN 则是 μi,l 和 σi,l,也就是说 AdaIN 仅仅是在单个样本内部算统计特征,不需要用一批样本算,因此 AdaIN 也不用维护滑动平均的均值和方差,所以其实它比条件 BN 还简单。
StyleGAN
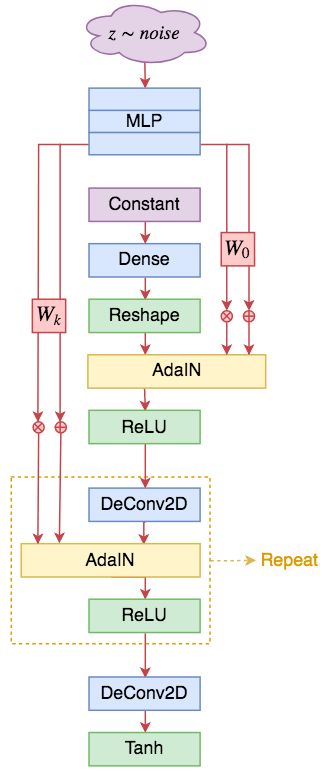
▲ StyleGAN形式的DCGAN生成器。基于ResNet的也类似,大体的改动就是将条件BN换成AdaIN
有了 SELF-MOD 和 AdaIN 后,其实就可以把 StyleGAN 说清楚了,StyleGAN 的主要改动也就是生成器,相比于 SELF-MOD,它的不同之处在于:
1. 取消顶部的噪声输入,换成一个可训练的常数向量;
2. 将所有条件 BN 换成 AdaIN;
3. AdaIN 的输入条件是将噪声用多层 MLP 变换后,再用不同的变换矩阵投影为不同 AdaIN 的 β 和 γ。
就这么简单~
个人总结
我自己也实验过一个简化的 StyleGAN 形式的 DCGAN,发现能收敛,效果也还行,但有轻微的 Mode Collapse。
由于官方的 StyleGAN 是用了 PGGAN 的模式进行训练的,而我没有,所以我猜测是不是 StyleGAN 要配合 PGGAN 才能训练好呢?目前还没有答案。只是在我的实验里,SELF-MOD 要比 StyleGAN 好训练得多,效果也更好。
文章汇总
本文简单地梳理了一下 GAN 的模型架构变化情况,主要是从 DCGAN、ResNet 到 SELF-MOD 等变动,都是一些比较明显的改变,可能有些细微的改进就被忽略了。
一直以来,大刀阔斧地改动 GAN 模型架构的工作比较少,而 SELF-MOD 和 StyleGAN 则再次燃起了一部分人对模型架构改动的兴趣。Deep Image Prior [8] 这篇文章也表明了一个事实:模型架构本身所蕴含的先验知识,是图像生成模型可以成功的重要原因。提出更好的模型架构,意味着提出更好的先验知识,自然也就有利于图像生成了。
本文所提及的一些架构,都是经过自己实验过的,所作出评价都是基于自己的实验和审美观,如有不到位之处,请各位读者斧正。
参考文献
[1] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Networks. NIPS, 2014.
[2] Alec Radford, Luke Metz, Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. ICLR, 2016.
[3] Odena, et al., "Deconvolution and Checkerboard Artifacts", Distill, 2016. http://doi.org/10.23915/distill.00003
[4] Ting Chen, Mario Lucic, Neil Houlsby, and Sylvain Gelly. On self Modulation for Generative Adversarial Networks. arXiv preprint arXiv:1810.01365, 2018.
[5] Andrew Brock, Jeff Donahue and Karen Simonyan. Large Scale GAN Training for High Fidelity Natural Image Synthesis. ICLR 2019.
[6] Tero Karras, Samuli Laine, and Timo Aila. A Style-Based Generator Architecture for Generative Adversarial Networks. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019.
[7] Huang, Xun and Belongie, Serge. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. ICCV 2017.
[8] Ulyanov, Dmitry and Vedaldi, Andrea and Lempitsky, Victor. Deep Image Prior. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018.

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客



