基于TableStore的海量气象格点数据解决方案实战

作者 亦征,阿里云技术专家
前言
气象数据是一类典型的大数据,具有数据量大、时效性高、数据种类丰富等特点。气象数据中大量的数据是时空数据,记录了时间和空间范围内各个点的各个物理量的观测量或者模拟量,每天产生的数据量常在几十TB到上百TB的规模,且在爆发性增长。如何存储和高效的查询这些气象数据越来越成为一个难题。
传统的方案常常采用关系型数据库加文件系统的方式实现这类气象数据的存储和实时查询,这种方案在可扩展性、可维护性和性能上都有一些缺陷,随着数据规模的增大,缺点越来越明显。最近几年,业界开始越来越多的基于分布式NoSQL来解决这一问题,比如基于TableStore来实现气象格点数据的存储和查询。TableStore是一款阿里自研的分布式NoSQL服务,可以提供超大规模的存储容量,支撑超大规模的并发访问和低延迟的性能,可以很好的解决气象数据的规模和查询性能问题。
我们之前也写过相关的解决方案文章《基于云上分布式NoSQL的海量气象数据存储和查询方案》,也有一些客户基于这个方案进行了开发。出于减少客户开发难度,提供通用的实现的想法,我们最近开发了一个TableStore-Grid的Library,基于这个Library用户可以非常方便的实现气象格点数据的存储、查询和管理。本文作为一个实战文章,主要讲解这一解决方案的设计以及使用方式。
背景
格点数据的特点
格点数据具有明显的多维特点,以模式系统每次产生的数据为例,一般包含以下五个维度:
物理量,或者称为要素:温度、湿度、风向、风速等等。
预报时效:未来3小时、6小时、9小时、72小时等等。
高度。
经度。
纬度。
当我们固定某一要素某一预报时效,那么高度、经度、纬度就构成一个三维网格数据,如下图所示(图片来自互联网)。每个格点代表了一个三维空间上的点,上面的数值为该点在某一预报时效(比如未来三小时)下,某一物理量(比如温度)的预报值。
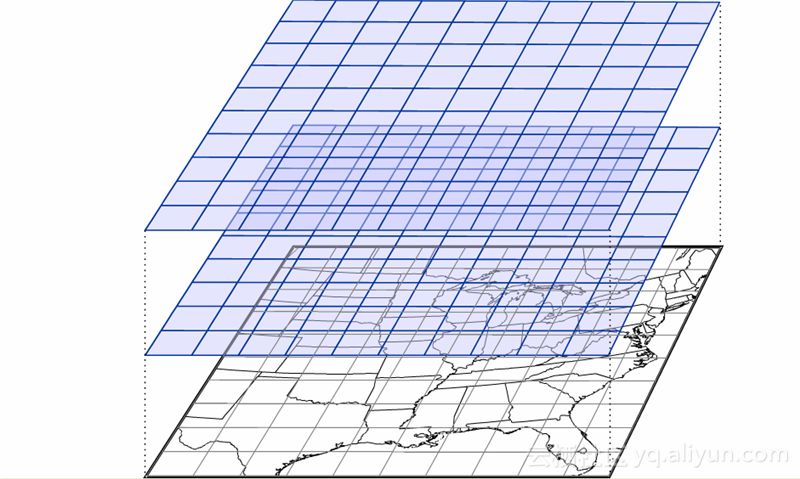
假设一个三维格点空间包含10个不同高度的平面,每个平面为一个2880 x 570的格点,每个格点保存一个4字节数据,那么这三维的数据量为2880 x 570 x 4 x 10, 大约64MB。这仅仅是某个模式系统对某个物理量某一时效下的一次预报,可见模式数据的总量是非常大的。
格点数据的查询方式
预报员会通过页面的形式浏览各种模式数据(格点数据),并进行数值模式预报。这个页面需要提供多种模式数据的查询方式,比如:
查询一个经纬度平面的格点数据:比如未来三小时全球地面温度的格点数据,或者未来三小时浙江省地面温度数据。
查询某个格点的时间序列数据:比如阿里云公司所在地未来3小时、未来6小时、一直到未来72小时的温度。
查询不同物理量的数据:比如查询某一预报时效、某一高度、某一点的全部物理量的预报数据。
查询不同模式系统产生的数据:比如同时查询欧洲中心的某一模式数据和中国气象机构产生的对应数据等。
上面提到,一个格点数据集一般是一个五维结构,各种查询方式实际上就是对这个五维数据进行切分,比如查询某个平面,每个剖面,某个点序列,某个三维、四维子空间等等。而我们的方案设计要保证在各种查询条件的查询性能,这是数据查询方面的主要技术难点。
基于TableStore的方案设计
标准化格点数据模型
首先,我们定义一个规整的五维网格数据为一个GridDataSet,表示一个格点数据集,按照维度顺序,其五维分别为:
variable:变量,比如各种物理量。
time:时间维度。
z: z轴,一般表示空间高度
x: x轴,一般表示经度或纬度。
y:y轴,一般表示经度或纬度。
GridDataSet = F(variable, time, z, x, y)。
一个GridDataSet除了包含五维数据,以及各个维度的长度等外,还包含一些其他信息:
GridDataSetId:唯一标记这个GridDataSet的Id。
Attributes:自定义属性信息,比如该数据的产生时间、数据来源、预报类型等等。用户可以自由定义自定义属性,也可以给某些属性建立索引,建立索引后就可以通过各种组合条件来查询符合条件的数据集。
举个例子来说,假设某种气象预报,每次预报未来72小时的每个整点的各个高度、各个经纬度的各种物理量,则这次预报就是一个标准的五维数据,是一个单独的数据集(GridDataSet),下一次相同的预报则是另一个数据集,这两个数据集需要有不同的GridDataSetId。这两个数据集比较类似,只是起报时间不同,但是因为起报时间不在五维模型中(五维内的时间为一次预报中的未来不同时刻),所以属于不同的数据集,起报时间可以作为数据集的自定义属性。本方案中,也支持对自定义属性设置条件进行检索。
数据存储方案
我们设计了两张表分别存储数据集(GridDataSet)的meta和data,meta表示这个数据集的各种元数据,比如GridDataSetId、各维度长度、自定义属性等等,data表示这个数据集里实际的网格数据。data相比meta在数据大小上要大很多。
为什么要分为meta和data两张表分开存储,主要是出于这样的考虑:
用户会有根据多种条件查询数据集的要求,比如查询最近有哪些数据集已经完成入库,或者查询表中有哪些某种类型的数据集等。传统方案中主要是通过MySQL等关系型数据库来存储,在本方案中我们通过单独的meta表来存储,并通过TableStore的多元索引功能来实现多条件的组合查询和多种排序方式,相比传统方案更加易用。
在查询格点数据之前,一般要知道格点数据中各维度的长度等信息,这些信息就是存储在meta表中的,即需要先查询meta表,再查询data表。因为meta数据一般都很小,因此查询效率相比查询data要高,多一次查询并不会明显增加延迟。
meta表设计
meta表的设计比较简单,主键只有一列,记录GridDataSetId,因为GridDataSetId就可以唯一标记一个GridDataSet。各种系统属性和自定义属性保存在meta表的属性列中。
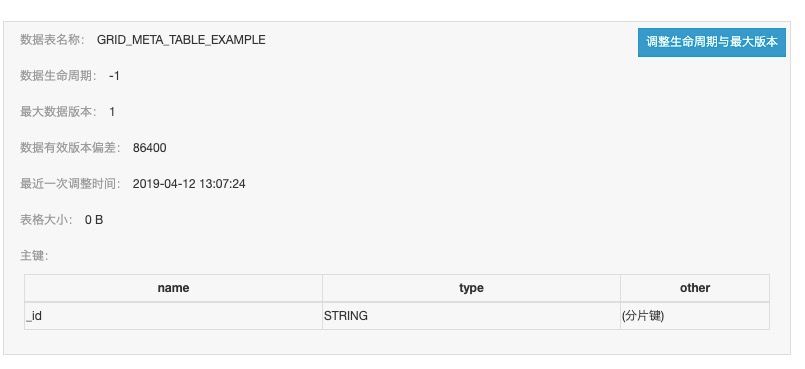
查询meta表有两种方式,一种是通过GridDataSetId直接查询,另外一种是通过多元索引,可以根据多种属性条件组合进行查询,比如筛选某种类型的数据,按照入库时间从新到老返回等。
data表设计
data表的设计要解决五维数据在不同的切分模式下的查询效率问题,不能简单直接的对数据进行存储。
首先,为了查询效率最高,我们要尽量减少一次查询需要扫描的数据量。一个数据集的数据量可能在几GB的级别,但是一次查询往往只需要其中的几MB的数据,如果无法高效的定位要查询的数据,那么就要扫描全部的几GB的数据,从中筛选出符合某个范围的数据,显然效率是很低的。那么怎么才能做到高效的定位到需要的数据之中呢?
我们首先设计一种表结构设计方式,我们使用四列主键列,分别为:
GridDataSetId:数据集Id,唯一标记这个数据集。
Variable:变量名,即五维模型中的第一维。
Time:时间,即五维模型中的第二维。
Z:高度,即五维模型中的第三维。
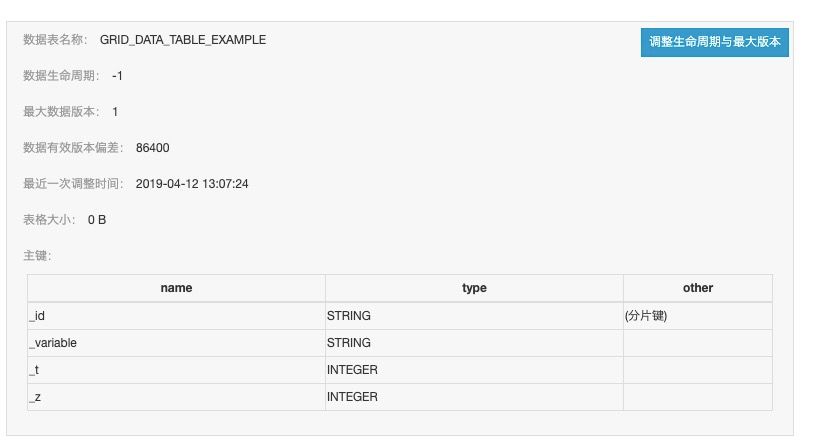
这四列主键列标记一行TableStore中的数据,这行数据需要保存后两维的数据,即一个格点平面。
这种设计下,对于五维中的前三维,我们都可以通过主键列的值来定位,即对于前三维的每一种情况,都对应TableStore中的一行。因为前三维分别代表变量、时间和高度,一般而言不会特别的多,每个维度在几个到几十个的级别,我们可以通过一些并行查询的方法来加速查询速度。
剩下的问题就在于后两维数据如何存储和查询。首先后两维代表了一个水平的平面,一般是一个经纬度网格,这两维的大小是比前三维要大很多的,每维在几百到几千的级别,随着数值预报越来越精细化,这个网格的大小还会成倍增加。这样的一个稠密的网格数据,我们不能把每个格点都用一列来保存,这样列的数量会非常多,存储效率也会非常的低。另一方面,如果我们把一个平面的格点数据存储到一列中,在整读整取时效率比较高,但是如果只读取某个点,就会读取很多的无效数据,效率又会变得比较低。因此我们采取一种折中的方案,对平面的二维数据再次进行切分,切分成更小的平面数据块,这样就可以做到只读取部分数据块,而不总是读取整个平面,因此极大的提高了查询性能。
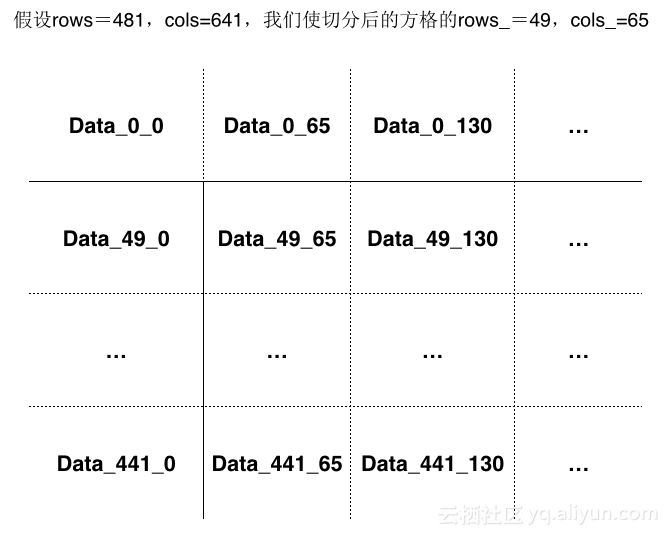
方案实现
基于上面的存储方案,我们实现了一个TableStore-Grid的library,提供以下接口:




下面我们分别给出数据录入、数据查询、数据集检索方面的示例。
数据录入
数据录入流程可以分为三部分:
写入putDataSetMeta接口写入数据集的meta信息。
通过GridDataWriter录入整个数据集的数据。
通过updateDataSetMeta接口更新数据集的meta信息,标记数据已经录入完成。
下面的例子中,我们读取一个NetCDF(气象格点数据常用的格式)文件,然后将其中的数据通过GridDataWriter录入到TableStore中。通过GridDataWriter每次写入时,只能写入一个二维平面,所以我们需要在外层进行3层循环,分别枚举变量维、时间维、高度维的值,然后读取对应的二维平面的数据进行录入。

数据查询
GridDataFetcher支持对五维数据进行任意维度的查询。第一维是变量维,通过setVariablesToGet接口设置要读取哪些变量,其余四维通过设置起始点(origin)和读取的大小(shape)就可以实现任意维度读取。

多条件检索数据集
本方案中,对Meta表建立多元索引后,可以支持通过各种组合条件来进行数据集检索,查询出符合条件的数据集,这个功能对于气象管理系统来说非常重要。
下面举一个例子,假设我们要查询已经完成入库的,创建时间为最近一天的,来源为ECMWF(欧洲中期天气预报中心)或者NMC(全国气象中心),精度为1KM的气象预报,并按照创建时间从新到老排序,可以用以下代码实现:
查询条件:
(status == DONE) and (create_time > System.currentTimeMillis - 86400000) and (source == "ECMWF" or source == "NMC") and (accuracy == "1km")
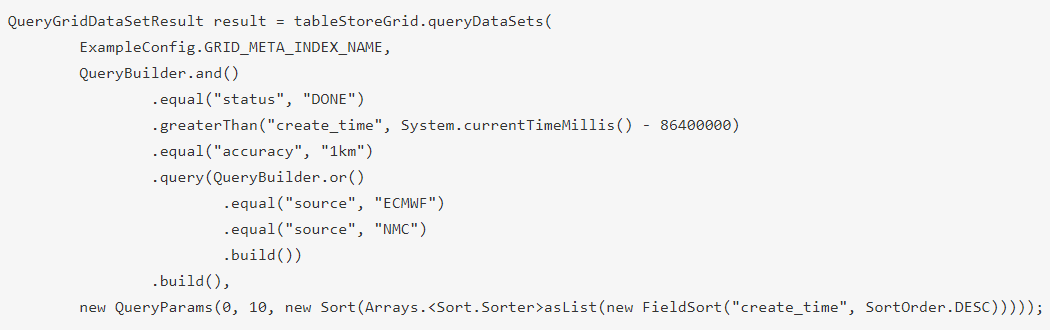
是不是非常简单?这一部分功能利用了TableStore的多元索引,多元索引可以实现多字段组合查询、模糊查询、全文检索、排序、范围查询、嵌套查询、空间查询等功能,给元数据管理场景提供了强大的底层能力。
相关代码的获取
可以在github上获取TableStore-Grid的实现代码和示例代码,欢迎大家体验、使用以及给我们提出建议。
代码链接:
https://github.com/aliyun/tablestore-examples/tree/master/demos/TableStore-Grid
更多精彩