f-GAN简介:GAN模型的生产车间

©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络

论文链接:https://arxiv.org/abs/1606.00709

整篇文章对 f 散度的处理事实上在机器学习中被称为“局部变分方法”,它是一种非常经典且有用的估算技巧。事实上本文将会花大部分篇幅介绍这种估算技巧在 f 散度中的应用结果。至于 GAN,只不过是这个结果的基本应用而已。
f散度
首先我们还是对 f 散度进行基本的介绍。所谓 f 散度,是 KL 散度的一般化:
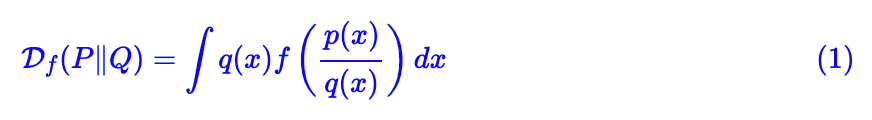

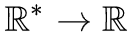 );
);
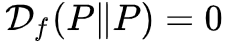 ,那第三点凸函数是怎么理解呢?
其实它是凸函数性质的一个最基本的应用,因为凸函数有一个非常重要的性质(詹森不等式):
,那第三点凸函数是怎么理解呢?
其实它是凸函数性质的一个最基本的应用,因为凸函数有一个非常重要的性质(詹森不等式):

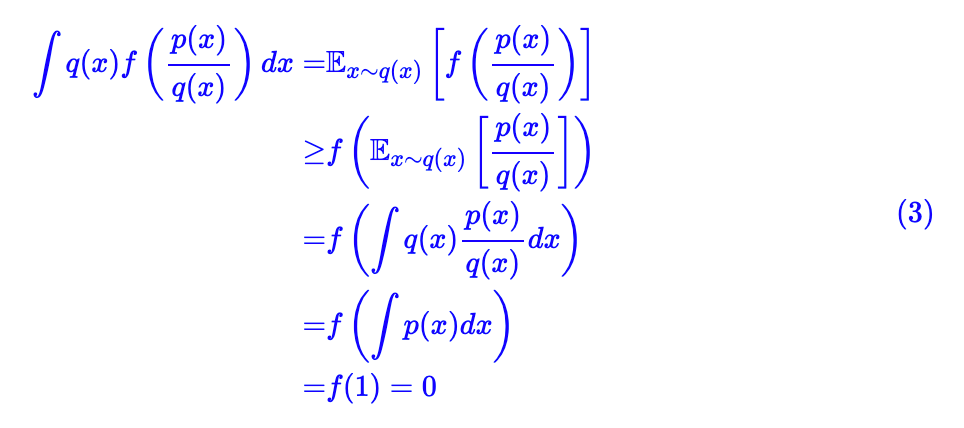
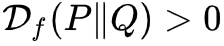 。
但通常我们会选择严格凸的 f(即 f′′(u) 恒大于 0),那么这时候可以保证 P≠Q 时
,也就是说这时候有
。
但通常我们会选择严格凸的 f(即 f′′(u) 恒大于 0),那么这时候可以保证 P≠Q 时
,也就是说这时候有
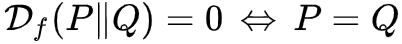 。
。
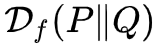 仍然不是满足公理化定义的“距离”,不过这个跟本文主题关系不大,这里只是顺便一提。
仍然不是满足公理化定义的“距离”,不过这个跟本文主题关系不大,这里只是顺便一提。


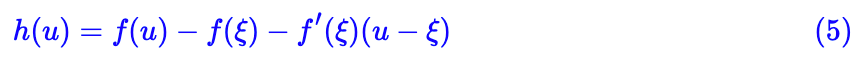
所谓凸函数,直观理解,就是它的图像总在它的(任意一条)切线上方,因此对于凸函数来说下式恒成立。
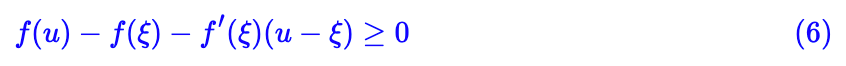
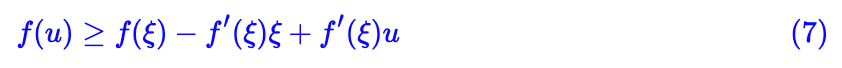
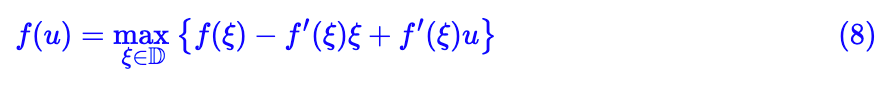


对一个凸函数给出了线性近似,并且通过最大化里边的参数就可以达到原来的值。
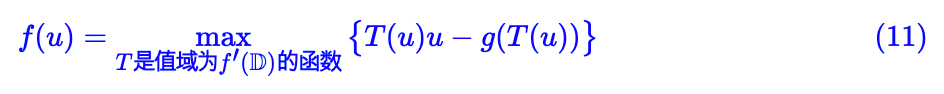


计算 f 散度有什么困难呢?根据定义 (1) ,我们同时需要知道两个概率分布 P , Q 才可以计算两者的 f 散度,但事实上在机器学习中很难做到这一点,有时我们最多只知道其中一个概率分布的解析形式,另外一个分布只有采样出来的样本,甚至很多情况下我们两个分布都不知道,只有对应的样本(也就是说要比较两批样本之间的相似性),所以就不能直接根据 (1) 来计算 f 散度了。
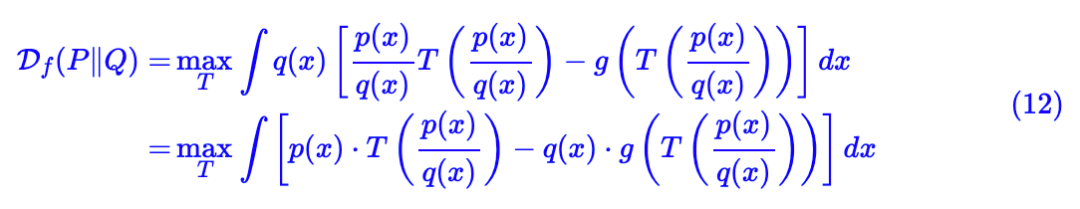
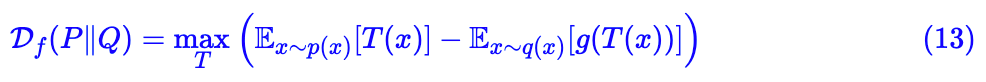
式 (13) 就是估计 f 散度的基础公式了。意思就是说:分别从两个分布中采样,然后分别计算 T(x) 和 g(T(x)) 的平均值,优化 T,让它们的差尽可能地大,最终的结果就是f散度的近似值了。显然 T(x) 可以用足够复杂的神经网络拟合,我们只需要优化神经网络的参数。
注意在对凸函数的讨论中,我们在最大化目标的时候,对 T 的值域是有限制的。因此,在 T 的最后一层,我们必须设计适当的激活函数,使得 T 满足要求的值域。当然激活函数的选择不是唯一的,参考的激活函数已经列举在前表。注意,尽管理论上激活函数的选取是任意的,但是为了优化上的容易,应该遵循几个原则:
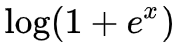 ;
;
GAN 希望训练一个生成器,将高斯分布映射到我们所需要的数据集分布,那就需要比较两个分布之间的差异了,经过前面的过程,其实就很简单了,随便找一种 f 散度都可以了。然后用式 (13) 对 f 散度进行估计,估计完之后,我们就有 f 散度的模型了,这时候生成器不是希望缩小分布的差异吗?最小化 f 散度就行了。所以写成一个表达式就是:
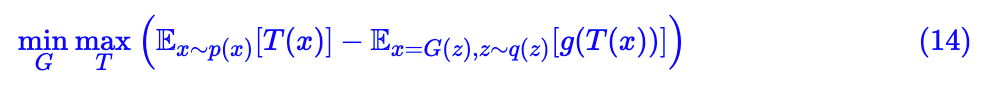
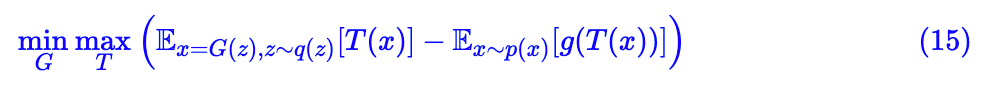
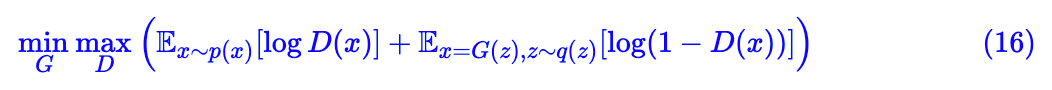
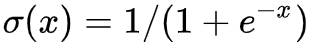 激活。
这就是最原始版本的 GAN 了。
激活。
这就是最原始版本的 GAN 了。
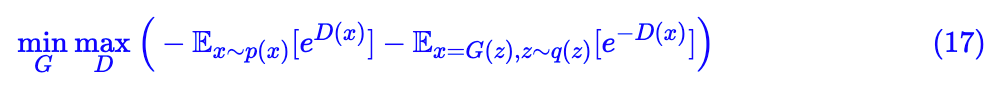
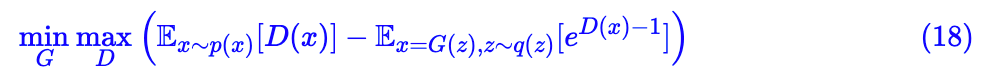
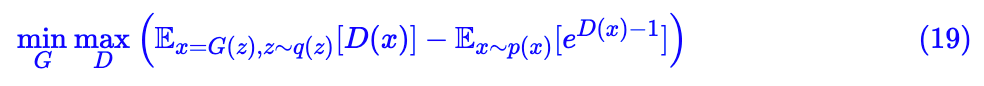

说白了,本文主要目的还是介绍 f 散度及其局部变分估算而已。所以大部分还是理论文字,GAN 只占一小部分。
当然,经过一番折腾,确实可以达到“GAN 生产车间”的结果(取决于你有多少种f散度),这些新折腾出来的 GAN 可能并不像我们想象中的 GAN,但它们确实在优化 f 散度。不过,以往标准 GAN(对应 JS 散度)有的问题,其实 f 散度照样会有,因此 f-GAN 这个工作更大的价值在于“统一”,从生成模型的角度,并没有什么突破。

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客



