YOLOv7-Pose尝鲜!基于YOLOv7的关键点模型测评

极市导读
本文主要围绕以YOLO为基线的关键点检测器,介绍了该框架的演变,并提供了在onnxruntime的推理框架下实现YOLOv7-Pose的具体代码和相应解释。 >>极市七夕粉丝福利活动:搞科研的日子是364天,但七夕只有一天!
前言
演变
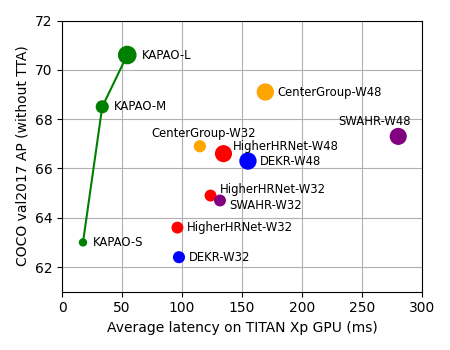
KaPao
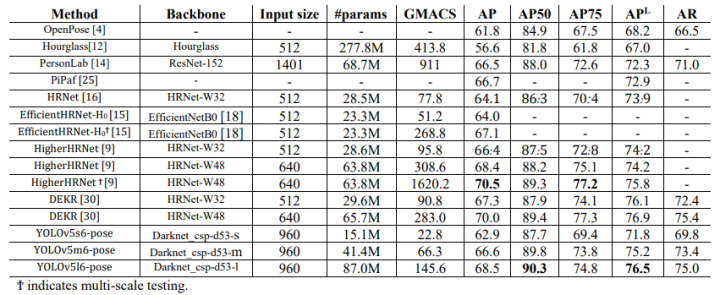
yolov5-pose

if self.kpt_label:
#Direct kpt prediction
pkpt_x = ps[:,
6::
3] *
2. -
0.5
pkpt_y = ps[:,
7::
3] *
2. -
0.5
pkpt_score = ps[:,
8::
3]
#mask
kpt_mask = (tkpt[i][:,
0::
2] !=
0)
lkptv += self.BCEcls(pkpt_score, kpt_mask.float())
#l2 distance based loss
#lkpt += (((pkpt-tkpt[i])*kpt_mask)**2).mean() #Try to make this loss based on distance instead of ordinary difference
#oks based loss
d = (pkpt_x-tkpt[i][:,
0::
2])**
2 + (pkpt_y-tkpt[i][:,
1::
2])**
2
s = torch.prod(tbox[i][:,
-2:], dim=
1, keepdim=
True)
kpt_loss_factor = (torch.sum(kpt_mask !=
0) + torch.sum(kpt_mask ==
0))/torch.sum(kpt_mask !=
0)
lkpt += kpt_loss_factor*((
1 - torch.exp(-d/(s*(
4*sigmas**
2)+
1e-9)))*kpt_mask).mean()
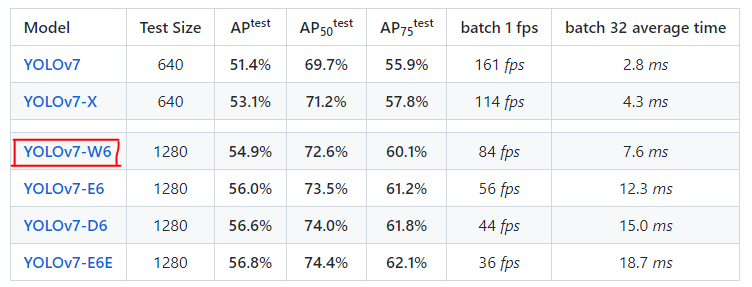
yolov7-pose
yolov7-pose + onnxruntime
% weigths = torch.load(
'weights/yolov7-w6-pose.pt')
% image = cv2.imread(
'sample/pose.jpeg')
!python pose.py

一、yolov7-w6 VS yolov7-w6-pose
-
首先看下yolov7-w6使用的检测头
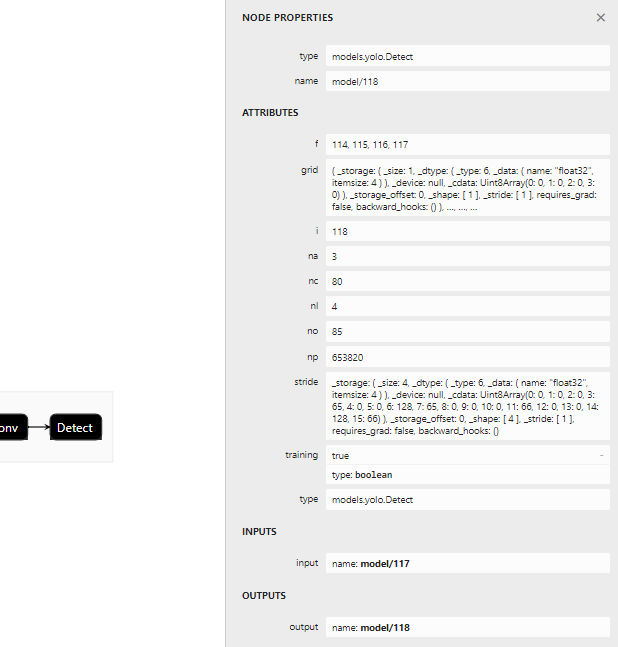
-
表示一共有四组不同尺度的检测头,分别为15×15,30×30,60×60,120×120,对应输出的节点为114,115,116,117 -
nc对应coco的80个类别 -
no表示
-
再看看yolov7-w6-pose使用的检测头:
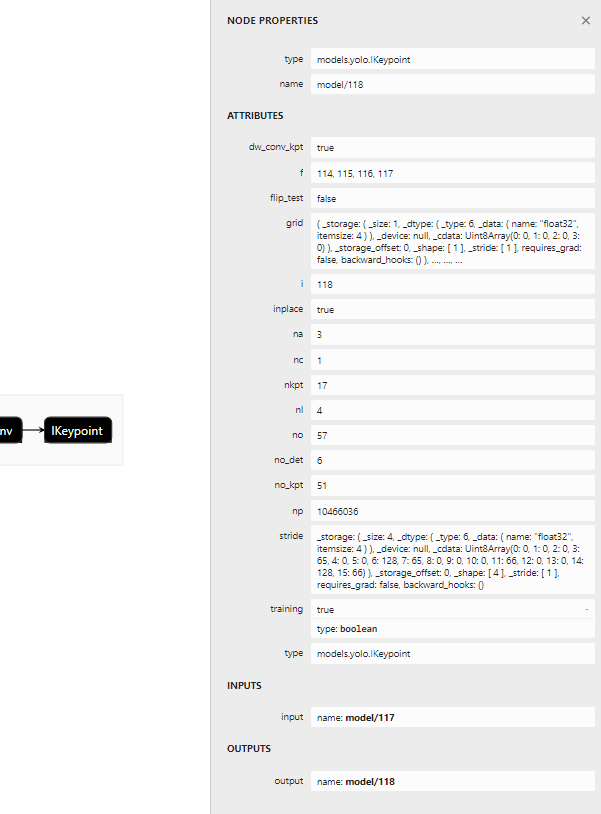
-
代表person一个类别 -
nkpt表示人体的17个关键点 -
二、修改export脚本
# 原代码:
for k, m
in model.named_modules():
m._non_persistent_buffers_set = set()
# pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv):
# assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
model.model[
-1].export =
not opt.grid
# set Detect() layer grid export
# 修改代码:
for k, m
in model.named_modules():
m._non_persistent_buffers_set = set()
# pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv):
# assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, models.yolo.IKeypoint):
m.forward = m.forward_keypoint
# assign forward (optional)
# 此处切换检测头
model.model[
-1].export =
not opt.grid
# set Detect() layer grid export
python export.py --weights
'weights/yolov7-w6-pose.pt' --img-size 960 --simplify True

三、onnxruntime推理
import onnxruntime
import matplotlib.pyplot
as plt
import torch
import cv2
from torchvision
import transforms
import numpy
as np
from utils.datasets
import letterbox
from utils.general
import non_max_suppression_kpt
from utils.plots
import output_to_keypoint, plot_skeleton_kpts
device = torch.device(
"cpu")
image = cv2.imread(
'sample/pose.jpeg')
image = letterbox(image,
960, stride=
64, auto=
True)[
0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
print(image.shape)
sess = onnxruntime.InferenceSession(
'weights/yolov7-w6-pose.onnx')
out = sess.run([
'output'], {
'images': image.numpy()})[
0]
out = torch.from_numpy(out)
output = non_max_suppression_kpt(out,
0.25,
0.65, nc=
1, nkpt=
17, kpt_label=
True)
output = output_to_keypoint(output)
nimg = image[
0].permute(
1,
2,
0) *
255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
for idx
in range(output.shape[
0]):
plot_skeleton_kpts(nimg, output[idx,
7:].T,
3)
# matplotlib inline
plt.figure(figsize=(
8,
8))
plt.axis(
'off')
plt.imshow(nimg)
plt.show()
plt.savefig(
"tmp")

-
image = letterbox(image, 960, stride=64, auto=True)[0] 中stride指的是最大步长,yolov7-w6和yolov5s下采样多了一步,导致在8,16,32的基础上多了64的下采样步长 -
output = non_max_suppression_kpt(out, 0.25, 0.65, nc=1, nkpt=17, kpt_label=True) ,nc 和 kpt_label 等信息在netron打印模型文件时可以看到 -
所得到的onnx相比原半精度模型大了将近三倍,后续排查原因 -
yolov7-w6-pose极度吃显存,推理一张960×960的图像,需要2-4G的显存,训练更难以想象
公众号后台回复“ECCV2022”获取论文分类资源下载~

“
点击阅读原文进入CV社区
收获更多技术干货
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年9月30日
Arxiv
0+阅读 · 2022年9月30日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月30日
Arxiv
0+阅读 · 2022年9月30日