关键点估计是一项计算机视觉任务,涉及定位图像中的兴趣点。
作为计算机视觉工作中研究最多的主题之一,关键点估计在相关应用中发挥着重要作用,包括人体姿态估计、手部姿态估计 、动作识别、目标检测、多人跟踪、运动分析等。
估计关键点位置最常用的方法是生成 target 场的热图(heatmap)方法。但热图回归作为检测和定位关键点的标准方法,也存在以下缺点:
首先,这种方法存在量化误差;关键点预测的精度本质上受到热图空间分辨率的限制。因此,较大的热图更优,但需要额外的上采样操作和昂贵的更高分辨率处理;并且即使使用大型热图,也需要特殊的后处理步骤来优化关键点预测,这会降低推理速度;
其次,当两个相同类型(即类别)的关键点彼此靠近时,重叠的热图信号可能会被误认为是单个关键点。
基于此,已有一些工作开始研究可替代的、无热图的关键点检测方法。
近日,来自加拿大滑铁卢大学的研究者提出了一种全新的单阶段多人关键点和姿态检测方法 KAPAO。使用一块 TITAN Xp GPU 实时运算,720p 视频的推理速度可以达到每秒 35 帧,1080p 的视频可达到每秒 20 帧。在不使用测试时增强 (TTA) 时,KAPAO 比此前的单阶段方法(如 DEKR 和 HigherHRNet)更快、更准确。
![]()
在滑铁卢大学的这项研究中,研究者提出了一种新的无热图关键点检测方法 KAPAO(Keypoints And Poses As Objects),并将其应用于单阶段多人人体姿态估计。其中单个关键点和空间相关的关键点(即姿态)集被建模为基于 anchor 的密集检测框架中的目标。这种把关键点和姿态视为目标的 KAPAO 方法可以同时检测关键点目标和姿态目标,并使用简单的匹配算法融合结果。通过检测姿态目标,该研究统一了人体检测和关键点估计,从而形成了一种高效的单阶段多人人体姿态估计方法。
![]()
论文地址:https://arxiv.org/abs/2111.08557
GitHub 地址:https://github.com/wmcnally/kapao
试玩地址:https://huggingface.co/spaces/akhaliq/Kapao
KAPAO 方法以 YOLO(You Only Look Once)密集检测框架近期的一种实现为基础,并包含一个高效的网络设计。此外,由于 KAPAO 不会产生大型且昂贵的热图,因此在准确性和推理速度方面,优于此前的单阶段方法,特别是在不使用 TTA 的情况下。
![]()
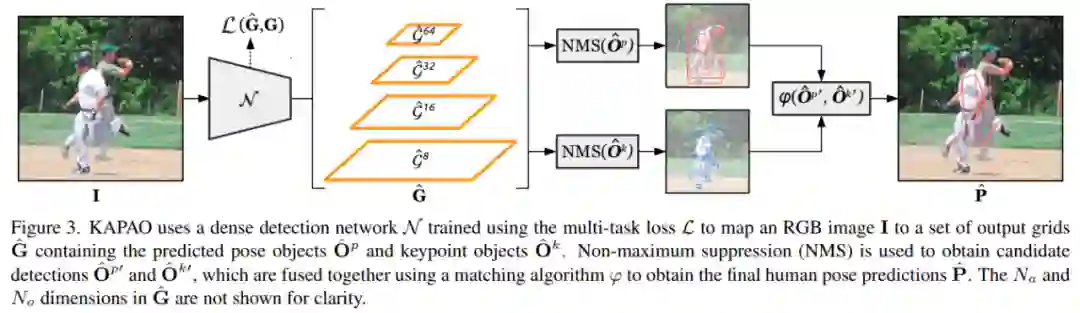
KAPAO 借助使用多任务损失函数 L 训练的密集检测网络 N ,将 RGB 图像 I 映射为一个输出网格
![]() 的集合,其中包含预测的姿态目标
的集合,其中包含预测的姿态目标
![]() 和关键
点目标
和关键
点目标
![]() 。
。
![]()
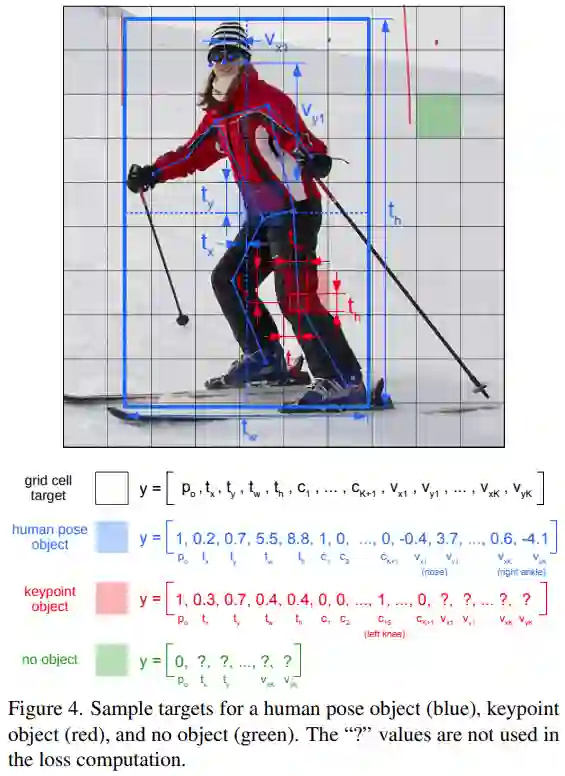
样本 target:人体姿态目标(蓝色)、关键点目标(红色)、无目标(绿色),「?」值不用于损失计算。
下图展示了在 TITAN Xp GPU 上实时运行 KAPAO-S 进行视频推理的效果:
![]()
KAPAO-S 在 TITAN Xp GPU 上可以实时运行,比本地每秒 25 帧的帧率还要快,不过图中未显示面部关键点。
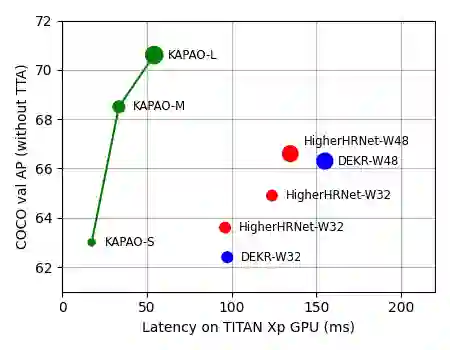
该研究用实验表明了 KAPAO 比之前的方法明显更快、更准确,热图后处理对之前的方法影响很大。此外,在不使用测试时增强(test-time augmentation,TTA)的实际设置中,KAPAO 在准确率 - 速度方面明显更优秀。大型模型 KAPAO-L 在没有 TTA 的情况下在 Microsoft COCO Keypoints 验证集上实现了 70.6 AP,并且比准确率低 4.0 AP 的单阶段模型还快了 2.5 倍。
![]()
图 1:在没有 TTA 的情况下,KAPAO 与单阶段多人人体姿态估计 SOTA 方法 DEKR、 HigherHRNet 的准确率 - 速度比较结果。
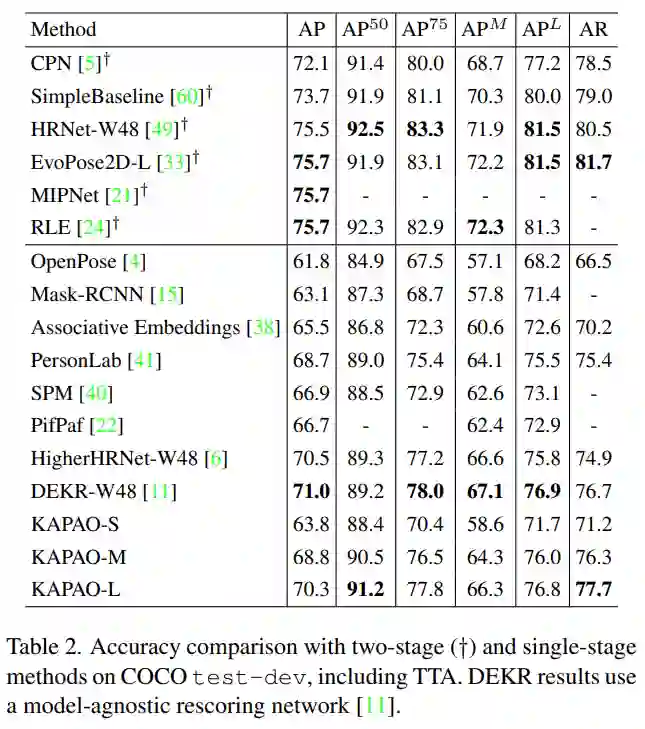
该研究在 COCO test-dev 上比较了 KAPAO 与单阶段和两阶段方法的准确性,结果如下表所示。
![]()
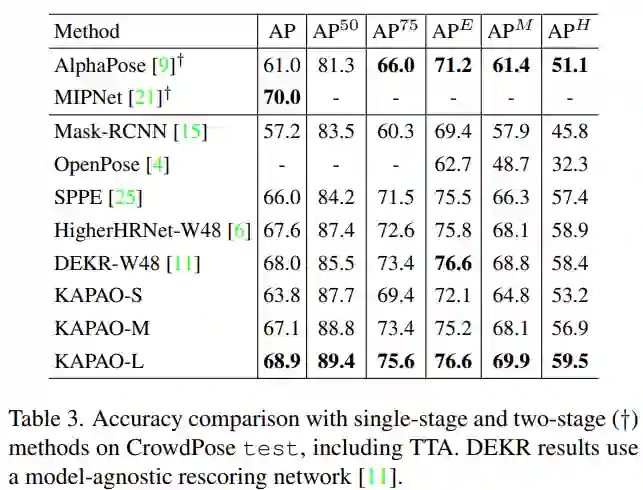
为了探究 KAPAO 在拥挤场景中的性能,该研究在 CrowdPose 测试集上对几种模型进行了比较,结果表明 KAPAO 在存在遮挡的情况下同样表现出色,在所有指标上超过了所有此前的单阶段方法。在分析 APE、APM 和 APH 时,KAPAO 对拥挤场景的优势是显而易见的。
![]()
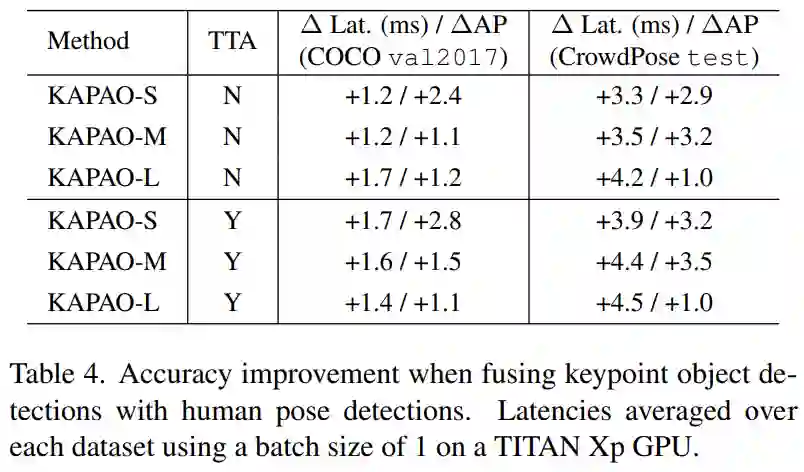
具体而言,KAPAO融合关键点目标和姿态目标所带来的准确率改进如下表4所示:
![]()
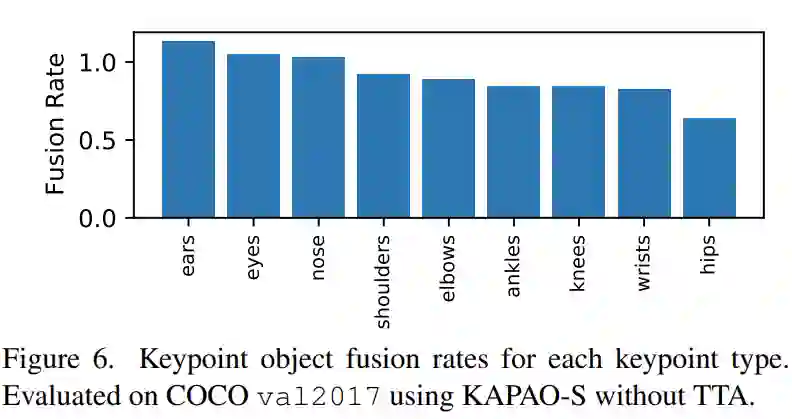
为了显示在没有 TTA 的情况下KAPAO的优势,图 6 绘制了在 COCO val2017 上,KAPAO-S 对每个关键点类型的融合率:
![]()
感兴趣的读者可以阅读论文原文了解更多细节。
详解NVIDIA TAO系列分享第2期:
基于Python的口罩检测模块代码解析——快速搭建基于TensorRT和NVIDIA TAO Toolkit的深度学习训练环境
第2期线上分享将介绍如何利用NVIDIA TAO Toolkit,在Python的环境下快速训练并部署一个人脸口罩监测模型,同时会详细介绍如何利用该工具对模型进行剪枝、评估并优化。
TAO Toolkit 内包含了150个预训练模型,用户不用从头开始训练,极大地减轻了准备样本的工作量,让开发者专注于模型的精度提升。本次分享摘要如下:
-
-
-
利用TAO Toolkit快速训练人脸口罩检测模型
-
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


 的集合,其中包含预测的姿态目标
的集合,其中包含预测的姿态目标
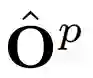 和关键
点目标
和关键
点目标
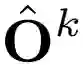 。
。