CVPR 2022 | 华南理工提出VISTA:双跨视角空间注意力机制实现3D目标检测SOTA

©作者 | 邓圣衡、梁智灏、孙林、贾奎
来源 | 机器之心
本文提出了 VISTA,一种新颖的即插即用多视角融合策略,用于准确的 3D 对象检测。为了使 VISTA 能够关注特定目标而不是一般点,研究者提出限制学习的注意力权重的方差。将分类和回归任务解耦以处理不平衡训练问题。在 nuScenes 和 Waymo 数据集的基准测试证明了 VISTA 方法的有效性和泛化能力。该论文已被 CVPR 2022 接收。

简介
LiDAR(激光雷达)是一种重要的传感器,被广泛用于自动驾驶场景中,以提供物体的精确 3D 信息。因此,基于 LiDAR 的 3D 目标检测引起了广泛关注。许多 3D 目标检测算法通过将无序和不规则的点云进行体素化,随后利用卷积神经网络处理体素数据。然而,3D 卷积算子在计算上效率低下且容易消耗大量内存。为了缓解这些问题,一系列工作利用稀疏 3D 卷积网络作为 3D 骨干网络来提取特征。如图 1 所示,这些工作将 3D 特征图投影到鸟瞰图 (BEV) 或正视图 (RV) 中,并且使用各种方法从这些 2D 特征图生成对象候选 (Object Proposals)。
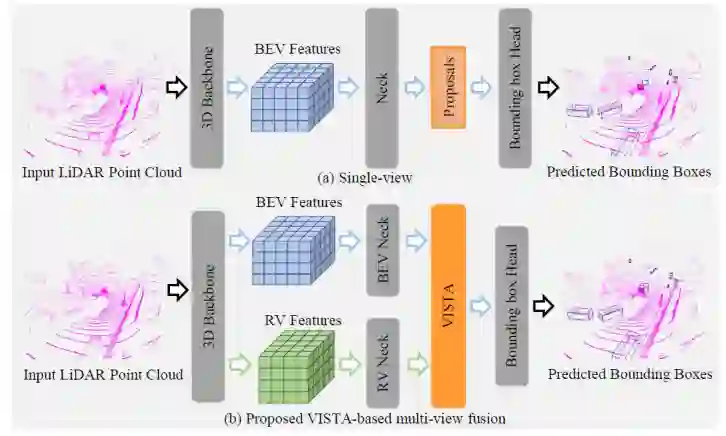
▲ 图1. 单视角检测和文章提出的基于 VISTA 的多视角融合检测的对比
不同的视角有各自的优缺点需要考虑。在 BEV 中,对象不相互重叠,每个对象的大小与距自我车辆 (ego-vehicle) 的距离无关。RV 是 LiDAR 点云的原生表征,因此,它可以产生紧凑和密集的特征。然而,无论是选择 BEV 还是 RV,投影都会不可避免地损害 3D 空间中传递的空间信息的完整性。例如,由于 LiDAR 数据生成过程自身的特性和自遮挡效应,BEV 表征非常稀疏,并且它压缩了 3D 点云的高度信息,在 RV 中,由于丢失了深度信息,遮挡和对象大小的变化会更加严重。
显然,从多个视角进行联合学习,也就是多视角融合,为我们提供了准确的 3D 目标检测的解决方案。先前的一些多视角融合算法从单个视角生成候选目标,并利用多视角特征来细化候选目标。此类算法的性能高度依赖于生成的候选的质量;但是,从单一视角生成的候选没有使用所有可用信息,可能导致次优解的产生。其他工作根据不同视角之间的坐标投影关系融合多视角特征。这种融合方法的准确性依赖于另一个视角的相应区域中可提供的补充信息;然而遮挡效应是不可避免的,这会导致低质量的多视角特征融合产生。
为了提高 3D 目标检测的性能,在本文中,给定从 BEV 和 RV 学习到的 3D 特征图,我们提出通过双跨视角空间注意力机制 (VISTA) 从全局空间上下文中生成高质量的融合多视角特征用于预测候选目标,如图 1 所示。所提出的 VISTA 利用源自 Transformer 的注意机制,其中 Transformer 已经被成功应用于各种研究环境(例如自然语言处理、2D 计算机视觉)中。与通过坐标投影直接融合相比,VISTA 中内置的注意力机制利用全局信息,通过将单个视角的特征视为特征元素序列,自适应地对视角间的所有成对相关性进行建模。
为了全面建模跨视角相关性,必须考虑两个视角中的局部信息,因此我们用卷积算子替换传统注意力模块中的 MLP,我们在实验部分展示了这样做的有效性。尽管如此,如实验部分所示,学习视角之间的相关性仍然具有挑战性。直接采用注意力机制进行多视角融合带来的收益很小,我们认为这主要是由于 3D 目标检测任务本身的特性导致的。
一般来说,3D 目标检测任务可以分为两个子任务:分类和回归。正如先前一些工作 (LaserNet, CVCNet) 中所阐述的,3D 目标检测器在检测整个 3D 场景中的物体时面临许多挑战,例如遮挡、背景噪声和点云缺乏纹理信息。因此,注意力机制很难学习到相关性,导致注意力机制倾向于取整个场景的均值,这是出乎意料的,因为注意力模块是为关注感兴趣的区域而设计的。
因此,我们显式地限制了注意力机制学习到的注意力图 (Attention Map) 的方差,从而引导注意力模块理解复杂的 3D 户外场景中的有意义区域。此外,分类和回归的不同学习目标决定了注意力模块中学习的 queries 和 keys 的不同期望。不同物体各自的回归目标(例如尺度、位移)期望 queries 和 keys 了解物体的特性。相反,分类任务推动网络了解物体类的共性。不可避免地,共享相同的注意力建模会给这两个任务的训练带来冲突。
此外,一方面,由于纹理信息的丢失,神经网络难以从点云中提取语义特征。另一方面,神经网络可以很容易地从点云中学习物体的几何特性。这带来的结果就是,在训练过程中,产生了以回归为主导的困境。为了应对这些挑战,我们在提出的 VISTA 中将这两个任务解耦,以学习根据不同任务整合不同的线索。
我们提出的 VISTA 是一个即插即用的模块,可以被用于近期的先进的目标分配 (Target Assignment) 策略中。我们在 nuScenes 和 Waymo 两个基准数据集上测试了提出的基于 VISTA 的多视角融合算法。在验证集上的消融实验证实了我们的猜想。提出的 VISTA 可以产生高质量的融合特征,因此,我们提出的方法优于所有已公布开源的算法。
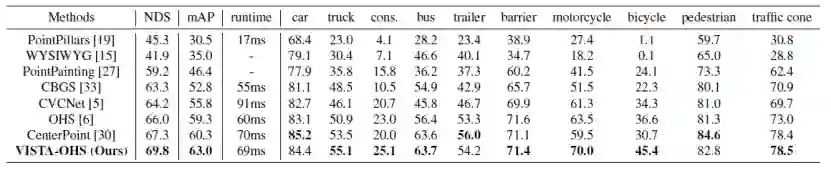
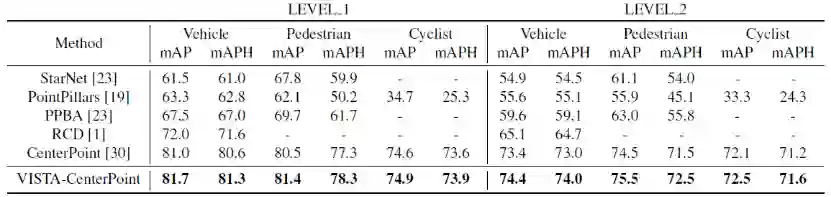
在提交时,我们的最终结果在 nuScenes 排行榜上的 mAP 和 NDS 达到 63.0% 和 69.8%。在 Waymo 上,我们在车辆、行人和骑自行车人上分别达到了 74.0%、72.5% 和 71.6% 的 2 级 mAPH。我们将我们的主要贡献总结如下:
1. 我们提出了一种新颖的即插即用融合模块:双跨视角空间注意力机制 (VISTA),以产生融合良好的多视角特征,以提高 3D 目标检测器的性能。我们提出的 VISTA 用卷积算子代替了 MLP,这能够更好地处理注意力建模的局部线索。
2. 我们将 VISTA 中的回归和分类任务解耦,以利用单独的注意力建模来平衡这两个任务的学习。我们在训练阶段将注意力方差约束应用于 VISTA,这有助于注意力的学习并使网络能够关注感兴趣的区域。
3. 我们在 nuScenes 和 Waymo 两个基准数据集上进行了彻底的实验。我们提出的基于 VISTA 的多视角融合可用于各种先进的目标分配策略,轻松提升原始算法并在基准数据集上实现最先进的性能。具体来说,我们提出的方法在整体性能上比第二好的方法高出 4.5%,在骑自行车的人等安全关键对象类别上高出 24%。

论文标题:
VISTA: Boosting 3D Object Detection via Dual Cross-VIew SpaTial Attention
CVPR 2022
https://arxiv.org/abs/2203.09704
https://github.com/Gorilla-Lab-SCUT/VISTA

对于大多数基于体素的 3D 目标检测器,它们密集地产生逐 pillar 的目标候选,经验上讲,生成信息丰富的特征图可以保证检测质量。在多视角 3D 目标检测的情况下,目标候选来自融合的特征图,因此需要在融合期间全面考虑全局空间上下文。为此,我们寻求利用注意力模块捕获全局依赖关系的能力进行多视角融合,即跨视角空间注意力。
在考虑全局上下文之前,跨视角空间注意力模块需要聚合局部线索以构建不同视角之间的相关性。因此,我们提出 VISTA,其中基于多层感知器 (MLP) 的标准注意力模块被卷积层取代。然而,在复杂的 3D 场景中学习注意力是很困难的。为了采用跨视角注意力进行多视角融合,我们进一步解耦了 VISTA 中的分类和回归任务,并应用提出的注意力约束来促进注意力机制的学习过程。
在本节中,我们将首先详细介绍所提出的双跨视角空间注意力机制(VISTA)的整体架构,然后详细阐述所提出的 VISTA 的解耦设计和注意力约束。
2.1 整体架构
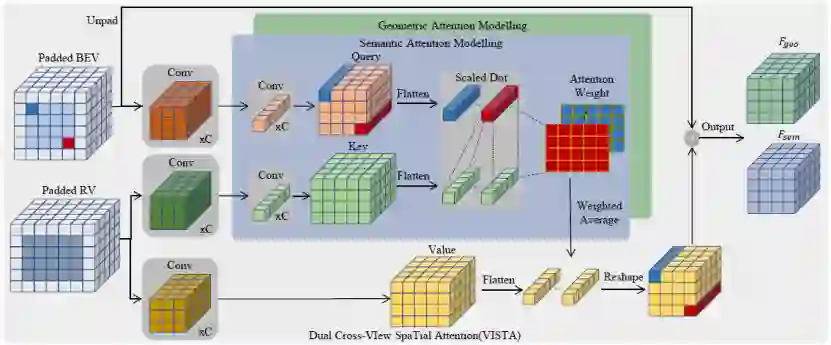
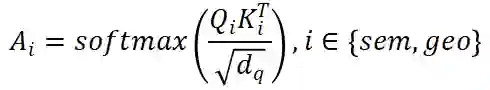
2.2 解耦分类和回归任务
给定场景中的 query 目标,为了分类,注意力模块需要从全局上下文中的对象中聚合语义线索,以丰富融合特征中传达的语义信息。这样的目标要求学习的 queries 和 keys 知道同一类别的不同对象之间的共性,以使同一类别的对象在语义上应该相互匹配。然而,回归任务不能采用相同的 queries 和 keys,因为不同的对象有自己的几何特征(例如位移、尺度、速度等),回归特征应该在不同的对象上是多样的。因此,在分类和回归的联合训练过程中,共享相同的 queries 和 keys 会导致注意力学习发生冲突。
此外,无论是单视角还是多视角,分类和回归结果都是从传统的基于体素的 3D 目标检测器中的相同特征图预测的。然而,由于 3D 场景的固有属性,3D 点云中不可避免地存在遮挡和纹理信息丢失,3D 检测器难以提取语义特征,给分类学习带来很大挑战。相反,3D 点云传达的丰富几何信息减轻了网络理解物体几何属性的负担,这是学习回归任务的基础。结果,在网络训练过程中,出现了分类和回归之间学习的不平衡现象,其中分类的学习被回归主导。
这种不平衡的学习是基于 3D 点云的,包含分类和回归任务的 3D 目标检测中的常见问题,这将对检测性能产生负面影响。具体来说,3D 检测器在具有相似几何特征的不同对象类别(例如卡车和公共汽车)上不会很鲁棒。
2.3 注意力约束
当学习从全局上下文中对跨视角相关性进行建模时,所提出的 VISTA 面临着许多挑战。3D 场景包含大量背景点(大约高达 95%),只有一小部分是有助于检测结果的兴趣点。在跨视角注意力的训练过程中,海量的背景点会给注意力模块带来意想不到的噪音。此外,复杂 3D 场景中的遮挡效应给注意力学习带来了不可避免的失真。因此,注意力模块倾向于关注不相关的区域。
注意力学习不佳的极端情况是全局平均池化(GAP)操作,正如我们在实验部分中所展示的,没有任何明确的监督,直接采用注意力模块进行多视角融合会产生类似于 GAP 的性能,这表明注意力模块不能很好地对跨视角相关性建模。
为了使注意力模块能够专注于特定目标而不是一般的点,我们提出对学习的注意力权重的方差施加约束。利用提出的约束,我们使网络能够学习注意到特定目标。通过将注意力方差约束与传统的分类回归监督信号相结合,注意力模块专注于场景中有意义的目标,从而产生高质量的融合特征。我们将提出的约束设定为训练期间的辅助损失函数。
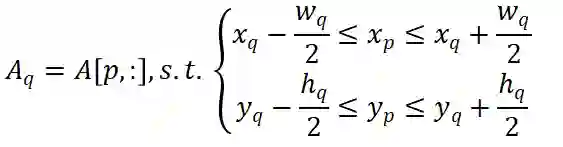
然后我们为所有 GT 框制定方差约束如下:
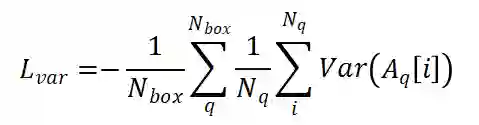

3.1 体素化
我们根据 x,y,z 轴对点云进行体素化。对于 nuScenes 数据集,体素化的范围是 [-51.2, 51.2]m, [-51.2,51.2]m 和 [-5.0,3]m,以 x,y,z 表示。对于 Waymo 数据集,范围为 [-75.2,75.2]m、[-75.2,75.2]m 和 [-2,4]m。除非特别提及,否则我们所有的实验都是在 x、y、z 轴的 [0.1,0.1,0.1]m 的低体素化分辨率下进行的。
3.2 数据增广
点云根据 x,y 轴随机翻转,围绕 z 轴旋转,范围为 [-0.3925,0.3925]rad,缩放系数范围为 0.95 到 1.05,平移范围为 [ 0.2,0.2,0.2]m 在 x,y,z 轴上。采用类别平衡分组采样和数据库采样来提高训练时正样本的比例。
3.3 联合训练
我们在各种目标分配策略 (CBGS, OHS, CenterPoint) 上训练 VISTA。为了训练网络,我们计算不同目标分配策略的原始损失函数,我们建议读者参考他们的论文以了解更多关于损失函数的细节。简而言之,我们将分类和回归考虑在内:
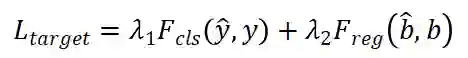

实验
我们在 nuScenes 数据集和 Waymo 数据集上评估 VISTA。我们在三种具有不同目标分配策略的最先进方法上测试 VISTA 的功效:CBGS、OHS 和 CenterPoint。
4.1 数据集和技术细节
nuScenes 数据集包含 700 个训练场景、150 个验证场景和 150 个测试场景。数据集以 2Hz 进行标注,总共 40000 个关键帧被标注了 10 个对象类别。我们为每个带标注的关键帧组合 10 帧扫描点云以增加点数。平均精度 (mAP) 和 nuScenes 检测分数 (NDS) 被应用于我们的性能评估。NDS 是 mAP 和其他属性度量的加权平均值,包括位移、尺度、方向、速度和其他框的属性。在训练过程中,我们遵循 CBGS 通过 Adam 优化器和单周期学习率策略 (one-cycle) 优化模型。
Waymo 数据集包含 798 个用于训练的序列,202 个用于验证的序列。每个序列的持续时间为 20 秒,并以 10Hz 的频率采样,使用 64 通道的激光雷达,包含 610 万车辆、280 万行人和 6.7 万个骑自行车的人。我们根据标准 mAP 和由航向精度 (mAPH) 加权的 mAP 指标来评估我们的网络,这些指标基于车辆的 IoU 阈值为 0.7,行人和骑自行车的人为 0.5。官方评估协议以两个难度级别评估方法:LEVEL_1 用于具有超过 5 个 LiDAR 点的框,LEVEL_2 用于具有至少一个 LiDAR 点的框。
4.2 与其他方法的比较
我们将提出的基于 VISTA 的 OHS 的测试结果提交给 nuScenes 测试服务器。为了对结果进行基准测试,我们遵循 CenterPoint 来调整训练分辨率并利用双翻转测试增强。由于我们的结果基于单一模型,因此我们的比较中不包括使用集成模型和额外数据的方法,测试性能见表一。
我们提出的 VISTA 在 nuScenes 测试集上实现了最先进的性能,在整体 mAP 和 NDS 中都大大优于所有已发布的方法。特别是在摩托车和自行车上的表现,mAP 上超过了第二好的方法 CenterPoint 高达 48%。具体来说,几何相似类别(例如卡车、工程车辆)的性能提升证实了我们提出的解耦设计的有效性。
为了进一步验证我们提出的 VISTA 的有效性,我们将提出的 VISTA 应用在 CenterPoint 上,并将测试结果提交到 Waymo 测试服务器。在训练和测试期间,我们遵循与 CenterPoint 完全相同的规则,测试性能见表二。VISTA 在所有级别的所有类别中为 CenterPoint 带来了显着改进,优于所有已发布的结果。
4.3 消融学习


如表三所示,为了证明所提出的 VISTA 的优越性,我们以 OHS 作为我们的基线 (a) 在 nuScenes 数据集的验证集上进行了消融研究。正如前文所述,如果没有注意力约束,注意力权重学习的极端情况将是全局平均池化(GAP)。为了澄清,我们通过 GAP 手动获取 RV 特征,并将它们添加到所有 BEV 特征上实现融合。
这种基于 GAP 的融合方法 (b) 将基线的性能 mAP 降低到 59.2%,表明自适应融合来自全局空间上下文的多视角特征的必要性。直接采用 VISTA 进行多视角融合 (d),mAP 为 60.0%。当将卷积注意力模块替换为传统的线性注意力模块 (c) 时,整体 mAP 下降到 58.7%,这反映了聚合局部线索对于构建跨视角注意力的重要性。
在添加提出的注意力方差约束后,如 (e) 所示,整体 mAP 的性能提高到 60.4%。从 (d) 到 (e) 行的性能提升表明注意力机制可以通过注意力约束得到很好的引导,使得注意力模块能够关注整个场景的兴趣区域。然而,共享注意力建模会带来分类学习和回归任务之间的冲突,在 3D 目标检测中,分类任务将被回归任务占主导地位。如(f)所示,在解耦注意力模型后,整体 mAP 的性能从 60.4% 提高到 60.8%,进一步验证了我们的假设。
所提出的 VISTA 是一种即插即用的多视角融合方法,只需稍作修改即可用于各种最近提出的先进目标分配策略。为了证明所提出的 VISTA 的有效性和泛化能力,我们在 CenterPoint、OHS 和 CBGS 上实现了 VISTA,它们是最近的先进方法。这些方法代表基于 anchor 或 anchor-free 的不同主流目标分配。我们在 nuScenes 数据集的验证集上评估结果,所有方法都是基于他们的官方代码库。如表四所示,所有三个目标分配策略在 mAP 和 NDS 分数中都实现了很大的性能提升(在 mAP 和 NDS 中分别约为 1.3% 和 1.4%),表明所提出的 VISTA 可以通过跨视角空间注意力机制融合普遍高质量的多视角特征。
我们在表三中展示了提出的 VISTA 在一个 RTX3090 GPU 上的运行时间。未经任何修改,基线 (a) 以每帧 60 毫秒运行。在基线中采用卷积注意力模块 (d) 后,运行时间增加到 64 毫秒。我们可以从 (e) 和 (f) 中观察到,虽然应用所提出的注意力方差约束不会影响推理速度,但解耦设计花费了 5ms,但额外的延迟仍然可以忽略不计。以这样的效率运行,我们认为所提出的 VISTA 完全符合实际应用的要求。
4.4 VISTA分析

▲ 图3. 具有((a)和(c))和没有((b)和(d))注意方差约束的 VISTA 学习到的注意力权重的可视化。每行呈现一个场景,Query 框以红色显示,点的颜色越亮,点的注意力权重越高。
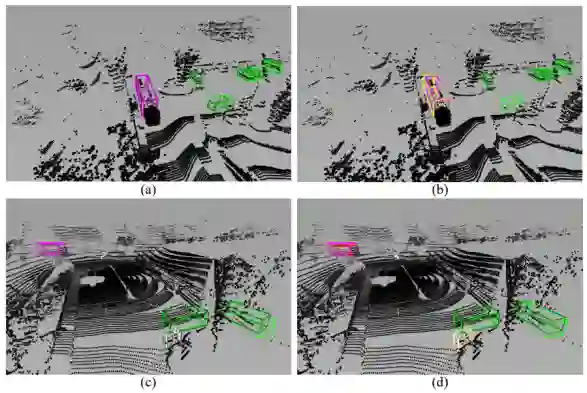
▲ 图4. 在有和没有解耦设计的情况下的检测结果的可视化。每行代表一个场景。浅色表示的框指的是 GT 框,深色表示的框表示正确的预测结果,不同强调色表示的框表示错误的预测。
我们认为,通过所提出的注意力约束训练的 VISTA 可以捕捉 BEV 和 RV 之间的全局和局部相关性,从而可以有效地执行多视角融合以进行准确的框预测。为了生动地展示注意力方差约束在训练 VISTA 中的有效性,我们在图 3 中可视化了网络在有和没有注意力方差约束情况下构建的的跨视角相关性。给定包含目标视角(BEV)的框的区域以 query 源视角(RV),我们得到上述区域中每个 pillar 的相应跨视角注意力权重,并将权重映射回原点云以可视化。我们观察到,在没有注意力方差约束的情况下,学习到的注意力权重对于 RV 中的几乎每个 pillar 都保持较小的值,从而导致近似的全局平均池化操作。
在图 3(b)和 (d) 中,注意力模块关注远离 query 汽车和行人的背景点,每个聚焦区域的注意力权重相对较低。相反,用注意力方差约束训练的注意力模块突出显示具有相同 query 类别的物体,如图 3(a)和 (c) 所示。特别是对于 query 汽车,通过注意力方差约束训练的注意力模块成功地关注了场景中的其他汽车。
我们提出的 VISTA 的另一个关键设计是分类和回归任务的解耦。这两个任务的各自的注意力建模缓解了学习的不平衡问题,因此检测结果更加准确和可靠。为了展示我们设计的意义,我们在图中展示了解耦前后的检测结果。每行代表一个场景,左列显示解耦后的结果,另一列显示未解耦的结果。
如图 4(b)和 (d) 所示,没有解耦设计的 3D 目标检测器很容易将物体 A 误认为具有相似几何特性的另一个物体 B,我们将这种现象称为 A-to-B,例如公共汽车(紫色)到卡车(黄色)、公共汽车(紫色)到拖车(红色)和自行车(白色)到摩托车(橙色),证明了分类和回归任务之间存在不平衡训练。此外,当将右列与左列进行比较时,混淆的预测并不准确。相反,具有解耦设计的 VISTA 成功区分了对象的类别,并预测了紧密的框,如图 4(a)和 (c) 所示,证明了所提出的解耦设计的功效。

在本文中,我们提出了 VISTA,一种新颖的即插即用多视角融合策略,用于准确的 3D 对象检测。为了使 VISTA 能够关注特定目标而不是一般点,我们提出限制学习的注意力权重的方差。我们将分类和回归任务解耦以处理不平衡训练问题。我们提出的即插即用 VISTA 能够产生高质量的融合特征来预测目标候选,并且可以应用于各种目标分配策略方法。nuScenes 和 Waymo 数据集的基准测试证明了我们提出的方法的有效性和泛化能力。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧





