怎么科学有效的学习算法?分享我的算法学习经验

极市导读
非计算机科班出身,工作后通过自学转行做算法,来看看作者的学习经验总结。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
看到知乎上有很多人提问“怎么学习算法”?对于这个问题,我想我是非常有资格回答的,因为我不是计算机科班出身,工作几年后通过自学,不仅转行做了推荐算法,而且我的算法水平无论是在公司内部还是在网络上,也都得到了广泛认可,算是转行成功的,我的学习方法也算是“亲测有效”。
总结一下我的算法学习经验,分享给大家。正所谓“授人以鱼,不如授之以渔”,希望能够对准备投入算法行为开卷的同学,和已经在算法行业卷得不亦乐乎的同学,都有所帮助。
我的知识库工具
工欲善其事 ,必先利其器。每年人工智能领域出的文章汗牛充栋,如果对自己的记忆力抱有“迷之自信”而不做读书笔记,后果只能是“狗熊掰棒子”,时间一长,大概的思想可能还有印象,但是细节肯定是记不起来了,等于白白浪费了之前的功夫。等到要用的时候,才感叹起“书到用时方恨少”,我接下来要谈的“总结反思”更是无从谈起。
所以,读书笔记的重要性,是无论怎么强调也不过分的。笔记相当于我们的“第二大脑”、“知识库”,而一个合适的笔记工具要为这个“知识库”的正常运转提供一个高效可靠的物理基础。这里我介绍一下我正在使用的两款知识库工具。
笔记工具
我选择笔记工具,一个最重要的标准就是是否具备“内部链接”功能,就是允许我点击笔记中的某段文字、某张图片跳转到笔记的另一段文字或图片。这个功能非常非常重要,在接下来的段落中,我会一直强调避免孤立地学习单个知识点,而必须将知识点串联成脉络。而这种“内部链接”的功能,就是“脉络”的具体实现形式。我使用过很多笔记工具,还为其中好几款充了会员。
在我自学机器学习知识准备转行的时候,使用的是OneNote,那个时候就感觉到“内部链接”功能极大地提升了我的学习效率。后来,又切换到Notion,当时是真的被惊艳到,特别是利用Notion强大的表格功能,为我读过的论文建立了一个数据库,详细记录了每篇论文的用途、特点,还为每篇论文打了份,如下图所示。
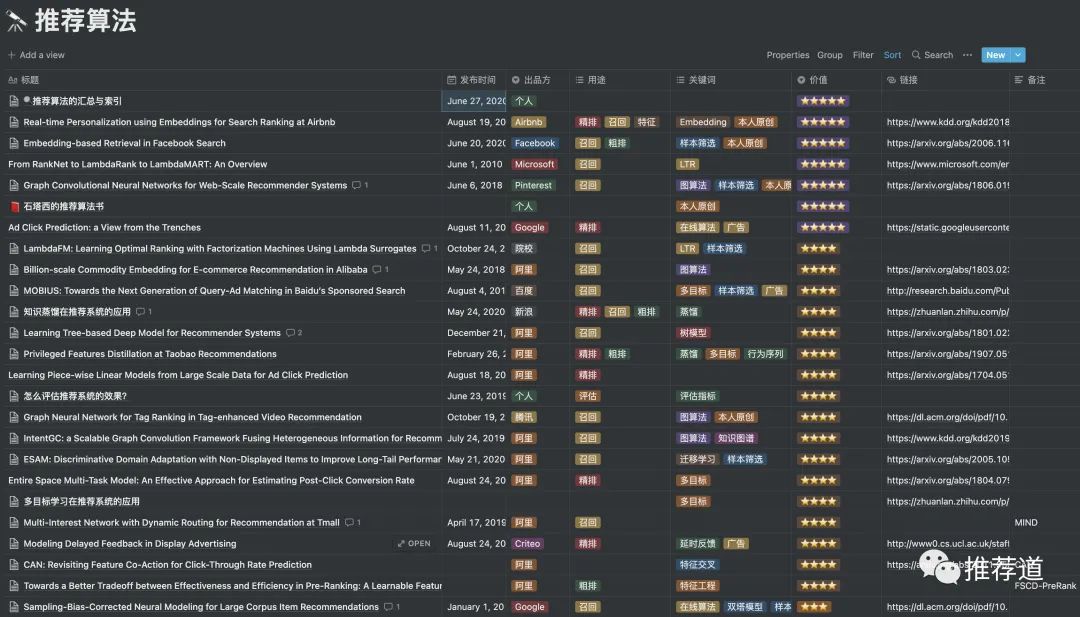
但是最终还是选择了思源笔记:
-
一是,Notion将笔记内容保存在服务器上,而且是在国外的服务器上,我担心哪天公司倒了或是被墙了,我辛苦积累的笔记也就找不回来了;而思源同时提供了“本地备份+网络备份”两种选择,我的笔记更加安全。(如果哪个小伙伴愿意尝试思源的订阅版,可以使用我的推荐码:EOIw9PL,你我都能额外多领取500M的网络空间) -
二来,思源笔记的“ 反向链接”功能也的确有吸引力,某个知识点不仅能够链接到其他知识点,而且还能让我们查看当前知识点被哪些知识点所引用,使我们的“知识脉络”更加顺畅。
思维导图工具
大段大段的笔记,我还是记录在思源笔记上,用思维导图的场合主要有两个:
-
一是做阅读源码时的笔记。根据我的经验,如果用笔记工具做源码笔记,很容易大段大段地复制粘贴源代码,贴得越多,不加以提炼,笔记的功效反而越弱。而思维导图的图形化方式,更容易让我们将代码结构“提纲挈领”地展示出来,方便日后重新阅读时把握重点。 -
二是创作时,帮我理清思路,比如这篇文章的提纲+草稿,我就是在思维导图上完成的。
一提到思维导图工具,大家肯定先想到的是XMind。XMind我也用过,也购买过订阅版,但是最终还是切换到了MindMaster。因为我感觉MindMaster的功能更强大,比如云盘功能、允许一个节点链接到导图内的多个节点、自定义图标、......,这些功能起码在一年前,我使用XMind Zen的时候,XMind Zen都是不具备的。文章的最后,我会提供一份我在阅读alphaFM源码时制作的笔记。感兴趣的同学可以下载MindMaster免费版打开。(嘿嘿,MindMaster打钱 :-) )
我的学习方法论
有了称手的工具,但是利用工具记录什么内容,如何将笔记中的内容转化为自己的知识,还是取决于个人对算法的理解水平。如果只是将原文翻译成中文贴在笔记上面,为某大厂取得在AI领域的“重大突破”喝彩,那可就真算是“听君一席话,如听一席话”了,对于提高自己算法水平没有丝毫帮助。
现在算法学习的痛点不在于信息的匮乏,而恰恰相反,现在的论文太多了,信息爆炸。每年KDD, SIGIR, CIKM上有那么多中外的王婆一起卖瓜,各种各样的NN、FM、Attention满天飞,其中不乏实打实的干货,更不缺乏湿漉漉的灌水文,让人不知道哪个方法才是解决自己问题的灵丹妙药,因为每篇文章都宣称自己的实验结果远超基线好几个点。而且绝大多数论文都像八股文一样,起承转合下来,才发现干货只有那么一点点。
如何练就一双慧眼,帮我们分辨干货与水文,或者把每篇文章中的水分挤干,把剩下的干货提取出来,丰富自己的知识体系?接下来,我将从5个方面介绍一下自己的经验。
坚持问题导向
不知道大家是否类似的经历,读完一篇算法论文,掩卷感叹好“精(fu)巧(za)”的一个网络结构。正准备点开另一篇PDF,等等,刚才那一篇是要解决一个什么问题来着?正所谓不知哪位名人说出的名言“正确提出问题,就已经解决了一半的问题”,学会了复杂的解决方法,却忽视了问题本身,正应合了那句成语“买椟还珠”。
正确的方法是,在读论文的过程中,坚持问题导向,看看作者提出的问题,是否也存在于我们自己的推荐系统中?如果存在的话,我们的解决方法与作者提出的方法相比,谁优谁劣?除了作者提出的方法,是否还有别的方法能够解决?很多时候,作者提出的问题给了我更大的启发。而作者的方法被我放弃,而代之以更符合我们系统实际的其他方法。
举个例子,阿里妈妈在SIGIR-2021发表了论文《Explicit Semantic Cross Feature Learning via Pre-trained Graph Neural Networks for CTR Prediction》。可能大多数人是被Graph Neural Network所吸引,毕竟GNN火嘛。但这篇文章给我最大的启发是,作者指出了目前推荐算法存在的一个大问题,即我们过于重视“隐式语义建模”,却忽视了“显式语义建模”。
-
要让user_age与item_id进行交叉,最常见的方法就是user_age和item_id分别表示成embedding,然后交叉的事就交给上面的FM/DNN/DCN等复杂结构,期待着能够让两个embedding碰撞出火花; -
但是除此之外,还有另外一种显式交叉,就是看看比如“某个年龄段上的用户对某个商品的CTR”到底是多少。不像embedding那么晦涩,这种交叉特征所包含的信息是非常清晰和强有力的。这种特征本来在前深度学习时代还是非常受重视的,很可惜,受“DNN是万能函数模拟器”的神话影响,近年来被研究的越来越少了。
本来仅凭作者提出的这一个问题,就足够引起我的共鸣,因为我本身就是从前DNN时代过来的,对前DNN时代对手工交叉特征的重视还记忆犹新。而作者紧接着提出的问题,又再一次引起我的注意:
-
要得到“显式交叉的特征”,简单统计一下就可以。数数同时包含“用户:年龄20~30岁”和“商品:耐克鞋”的样本有多少,其中用户点击了又有多少,二者一除,不就得到了[20-30岁,耐克鞋]上的CTR是多少。之前手工交叉的统计特征就是这么得到的。 -
但是,作者指出这么做又有两个问题,一是要得到足够置信的统计量,该交叉特征在样本中出现的次数必须足够多,换句话说,我们无法得到“罕见交叉特征”上的统计量;二是,交叉特征的数量是巨大的,线上存储+检索都比较困难。
基于以上两个问题,阿里妈妈团队提出了“用模型预测代替索引检索”的方法。简言之,
-
就是离线训练一个GNN模型,这个模型输入两个特征,就能返回当两个特征同时存在时的CTR是多少; -
线上预测的时候,来了一个样本,提取出特征之后,直接喂给训练好的GNN模型就能得到交叉特征上的CTR,而不必去一个大的索引库中去检索。
你看,如果让我给别人讲阿里的这篇文章,我花了大量的笔墨详细介绍了作者提出的两个问题:一是大家对显式交叉特征重视不够;二是之前基于统计的方法存在缺陷。反而对作者使用的GNN模型一笔带过。因为要解决以上问题,未必要用GNN,用简单的FM也能work。离线用FM将每个特征的embedding训练好,线上预测时只要拿两个embedding点积一下,就能得到这两个特征组成的交叉特征上的click-logit,无论是理论还是工程上都是可行的。
也就是说,受作者的启发,使我们意味到了问题,就已经解决了一半的问题。至于如何解决,未必要机械照搬作者提出的方法,而要结合实际采取更适合的方法,没准更简单,效果更好。这方面的例子还有:
-
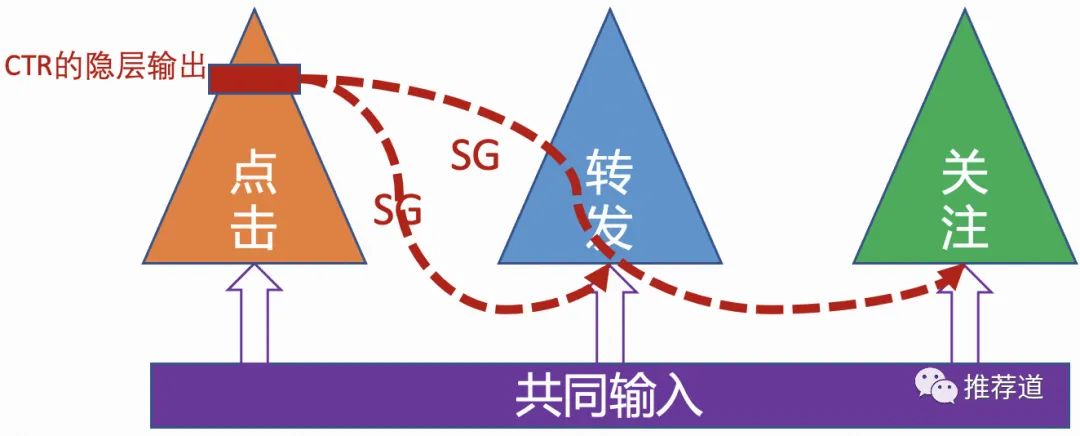
阿里的ESMM模型,大家熟知的公式,CTCVR=CTR*CVR。而这篇文章给我的启发在于作者发现的问题, click的数据多,而conversion的数据少,导致直接预测CTCVR有困难。 作者提出方法的精髓在于不同目标之间的信息迁移。而信息迁移未必只有写成数学公式这一种方法,转化链路上游任务的中间隐层传递给下游任务也能起到效果。
-
张俊林大佬提出SENet改进双塔模型。但背后的问题就是双塔模型的内在缺陷:user&item两侧信息交叉得太晚,等到最终能够通过dot或cosine交叉的时候,user & item embedding已经是高度浓缩的了,一些细粒度的信息已经在塔中被损耗掉,永远失去了与对侧信息交叉的机会 。
所以,双塔改建最重要的主线就是:如何保留更多的信息在tower的final embedding中,从而有机会和对侧塔得到的embedding交叉?
-
SENet的思路是,在将信息喂入塔之前,插入SEBlock。SEBlock动态学习各特征的重要性,增强重要信息, 弱化甚至过滤掉原始特征中的噪声,从而减少信息在塔中传播过程中的污染与损耗 ,能够让可能多的重要信息“撑”到final dot product那一刻。 -
但是要达成“让更多细粒度信息能够撑到最终交叉那一时刻”的目标,并不是只有“输入去噪”这一种思路。 -
我们可以 让那些重要信息抄近路,走捷径,把它们直接送到离final dot product更近的地方,避免在DNN层层流动中的信息损失。 -
SENet的解决方法是“堵”,而与之对应的思路是“疏”, 大家没必要都挤一个塔向上流动,不同的信息(甚至是相同的信息)可以沿适合自己的塔向上流动浓缩,避免相互干扰。最后由每个小塔的embedding聚合成final embedding。
举一反三,将知识点串联成脉络
据我了解,很多同学孤立地看论文,“看君一篇论文,如看一篇论文”,收获非常有限。正确的姿势是,读完一篇论文,要将这篇论文的知识点与之前的知识点串联起来,随着阅读论文的增多,孤立的知识点串联成脉络,将真正将别人的文章变成了你自己的知识。比如,很多同学喜欢我的《无中生有:论推荐算法中的Embedding思想》(https://zhuanlan.zhihu.com/p/320196402)一文。实际上,我之所以能够用“无中生有”刻画embedding的本质,也正是推荐系统中“矩阵分解”技术“串联”的结果。很多人以为embedding是深度学习引入的新技术,事实并非如此。矩阵分析作为早期的经典算法,就已经包含了embedding的思想,
-
即将一个概念(user_id/item_id)表示成一个“事先未知”的向量 -
然后让算法把这个向量学习出来,学习出来的向量就是这个user/item的特征表示 -
但是由于我们不知道向量中每位表示的具体含义,所以这个学习出来的特征向量被称为“ 隐向量”。
当你把Deep Learning中的embedding与Matrix Factorization中的latent vector联系起来,你就会发现,二者实际上是一回事。只不过,在Deep Learning时代,万物皆可embedding,而不局限于矩阵分解中使用的user_id/item_id。矩阵分解的结果是允许我们在向量空间中找到相似的user和item,而在万物皆可embedding后,使模型能够发现“科学”和“科技”原来是两个相似的标签,从而提高了模型的扩展能力。其他的例子还包括:
-
推荐系统中适当打压热门item是一个比较现实的问题。仔细想一下,这个问题和NLP中打压高频词,本质上是类似的。于是word2vec算法中打压高频词的方法就可以为我们所用,于是就有了我的回答《推荐系统传统召回是怎么实现热门item的打压?》。
-
阿里最近推出多篇讲multi-domain recommendation的文章。仔细想一下,multi-domain面临的问题,和新用户冷启问题,也有很多相似之处
-
multi-domain(比如“首页推荐”vs. “猜你喜欢”,再比如多国家场景)面临的问题是,多个场景下用户的行为模式有区别,简单混在一起训练,有可能相互干扰;但是,如果多个场景单独训练+部署一个模型,一来,数据少的场景有可能训练不好;二来,又浪费资源。 -
新老用户的行为模式有很多不同,简单混在一起训练,老用户的行为模式会主导模型,忽略新用户;但是,如果为新用户单独训练+部署一个模型,一来,新用户的数据少,担心训练不好;二来,又浪费资源。 -
既然二者面临的问题如此相似,那么阿里提出的STAR和HMoE等multi-domain推荐模型,也不妨在新用户冷启场景试一试。
勤于总结与反思
每隔一段时间,可以总结回顾一下之前学习到的知识。希望你能够发现,随着自己功能的提高,对先前知识的理解也提高了一个层次。比如召回算法,品类众多而形态迥异,看似很难找出共通点。如今比较流行的召回算法,比如:item2vec、DeepWalk、Youtube的召回算法、Airbnb的召回算法、FM召回、DSSM、双塔模型、百度的孪生网络、阿里的EGES、Pinterest的PinSAGE、腾讯的RALM和GraphTR、......
-
从召回方式上分,有的直接给user找他可能喜欢的item(u2i);有的拿用户喜欢的item找相似item(i2i);有的给user找相似user,再把相似user喜欢的item推出去(useru2u2i)。 -
从算法实现上分,有的来自“前深度学习”时代,有的基于深度学习,有的基于图算法(基于图的,又可细分为游走类和卷积类)。 -
从优化目标上分,有的属于一个越大规模的多分类问题,优化softmax loss;有的基于Learning-To-Rank(LTR),优化的是hinge loss或BPR loss。
但是,如果你仔细总结一下就会发现,以上向量化召回算法,其实可以被一个统一的算法框架所囊括,即“如何定义两个样本相近”、“如何定义两个样本距离远”、“如何生成embedding”、“如何成对优化”。
总结出这样一套算法体系:
-
一是能够 融会贯通,不仅能加深对现有算法的理解,还能轻松应对未来出现的新算法; -
二是能够 取长补短。大多数召回算法,只是在以上四个维度中的某个维度上进行了创新,而在其他维度上的做法未必是最优的。我们在技术选型时,没必要照搬某个算法的全部,而是博采多家算法之所长,组成最适合你的业务场景、数据环境的算法。

-
记忆与扩展是推荐算法两大经典、永恒的主题。如何实现扩展?靠的是Embedding和特征之间的交叉。 -
Embedding化“精确匹配”为“模糊查找“,大大提升了推荐算法的扩展能力,是”深度学习应用于推荐系统“的基石 。 -
高维、稀疏的类别特征是推荐系统中的一等公民 。为了弥补单个类别特征表达能力弱的问题,需要Embedding扩展其内涵,需要交叉扩展其外延。 -
高维特征空间直接接入DNN,会引发参数规模的膨胀。为解决这一难题,Field & Pooling应运而生。
通过以上梳理,你会发现某篇文章只不过是在某一环上进行的小改进,而在其他环上的所采用的方法可能还有瑕疵,不值得借鉴。而当你面临实际问题时,可以先将问题的难点拆解到五环中的某些环上,然后从那些环的研究成果中汲取解决问题的灵感,而不是胡子眉毛一把抓,急病乱投医。而最近我也在反思。随着我对推荐算法的理解进一步加深,之前在文章中的一些观点,也值得再思考、再商榷:
-
在《再评Airbnb的经典Embedding论文》一文中,我认为在利用side information解决item2vec冷启缺陷的问题上,Airbnb根据side information人工将user/item分群的方式,不如阿里在EGES算法中将side information embedding与id embedding先pooling再一起喂入word2vec算法的自动化方式。 现在回过头来看,当时的我对算法的拟合能力太乐观了。而随着自己踩过的坑越来越多,很多理论上很完美的方法,模型未必训练得好。所以,既然机器没有想像中智能, 那么像Airbnb那样用更多人工的先验知识指导模型,未必不是解决之道。 -
在《用TensorFlow实现支持多值、稀疏、共享权重的DeepFM》一文中,我觉得我的实现一大亮点就是能够实现权重的共享。比如,app的安装、启动、卸载三个field,底层共享一套app embedding。但是据我观察,最近的趋势是, 参数共享、结构共享在推荐算法中,越来越不受待见。按当下流行的作法,app的"装启卸"每个field应该有自己独立的一套app embedding,三个field各用各的,互不干扰;再比如,阿里的Co-Action Net通篇都在讲参数独立性,同一个特征与不同特征交叉时,也要使用不同的embedding。如此看来,我对参数共享、结构共享的态度也在慢慢修正。
敢于怀疑
看论文,没必要被作者的名号,或者大厂的招牌,震住,觉得自己只有顶礼膜拜的份,丝毫不敢怀疑文章中的观点。敢于怀疑“权威”,敢于提出自己的观点,才能够提升自己。我最受读者欢迎的一篇文章《负样本为王:评Facebook的向量化召回算法》(https://zhuanlan.zhihu.com/p/165064102)就是“怀疑精神”的产物。
我读Youtube论文的时候,就特别不理解为什么Youtube不用“曝光未点击”做负样本,而是拿抽样结果做负样本。而且这样做的还不仅仅Youtube一家,Microsoft的DSSM中的负样本也是随机抽取来的 。但是两篇文章都没说明这样选择负样本的原因。当时的我只有排序方面的经验,觉得拿“曝光未点击”做负样本,体现用户的真实反馈,简直是天经地义。何况用“曝光未点击”数据,还能够复用排序的data pipeline。
所以,敢于怀疑的我在第一次实践Youtube算法时,直接拿“曝光未点击”样本做负样本,结果踩了坑。但是“塞翁失马,焉知非福”,踩坑的教训反而促使我进一步的思考,终于领悟到召回与排序相比,速度要求上的不同只是一方面,另一方面重大不同就是二者面临的候选集差异巨大:排序是优中选优,召回则是鱼龙混杂、良莠不齐。所以,只有随机负采样,才能让模型达到"开眼界、见世面"的目的,从而在“大是大非”上不犯错误。
你看,如果没有当初的怀疑,只知道照搬论文中的作法,可能在当时会少踩一次坑,但是也失去了一次提升自己的机会。而如果不提升自己的认知水平,“知其然,而不知其所以然”,未来的坑也是避不开的。
同样的例子还有我对Deep Interest Evolution Network的质疑(《也评Deep Interest Evolution Network》)。尽管引发了一定的争议(当时有的公众号在转载我的文章时,起的标题是《看神仙打架》),但直到今天,我也坚持认为我的怀疑是有意义的。后来阿里推出《Deep Session Interest Network for Click-Through Rate Prediction》,也印证了我“用户时序要区分session内与session外”这一观点的合理性。
最近一次质疑是,我在《初来乍到:帮助新用户冷启的算法技巧》(https://zhuanlan.zhihu.com/p/458843906)中狠狠吐槽了一把MeLU,认为它这种“每个用户拥有一套参数”的作法完全脱离了推荐系统的实际,毫无实战价值,不知道怎么就被KDD录用了?后来有小伙伴评论说,让MeLU只学习每个用户的user id embedding就好,但是一来,新用户的user id embedding是在meta-learning阶段从未出现过的,meta-learning根本帮不上忙;二来,原文的文字根本没有让meta-learning只学user id embedding的意思。所以我才说这篇文章是误人子弟。熟悉我的文章的同学可能会发现,与很多解读论文的文章不同,
我的解读文章中从来不贴论文中的实验结果。这同样也是从“敢于怀疑”的角度出发。毕竟我们不是在打kaggle比赛,即使指标没有水分,因为大家的数据环境、技术治理水平都不同,“橘生淮南则为橘,生于淮北则为枳”,论文中那么显著的效果未必能够在你的环境中复现。但是,论文中的实验设计是有借鉴意义的,一定要看。
最后我也要指出,我强烈同意推荐算法还是一门强实践的学问,我见过太多理论完美的算法,现实中不work,而一些理论上有瑕疵的算法,却确确实实带来了收益。毕竟,“AB平台是(老板)检验算法的唯一标准” :-( 。结合上边的“勤于总结与反思”一条,过段时间发现自己当初怀疑错了,大方承认就好了,也不丢人,反而是自己的水平获得了提高。
关注代码实现细节
虽然我们常常戏称自己是“调包师”、“调参侠”,但是有追求的同学(比如正在读我文章的你)是绝不满足让自己的技术只停留在调包和调参的水平上。而摆脱这两个身份最好的办法,就是阅读+学习经典算法的实现源码,等自己功力修炼到一定程度,自己(从头)实现一遍,再长一层功力。
比如,对于《如何理解TensorFlow中的IndexedSlices类》这个问题,如果你不借助TensorFlow/PyTorch等高级框架,亲自实现过一遍某个含有“稀疏ID特征embedding”的算法,这个问题的答案是相当直觉的。简单来说,尽管embedding过程在数学上等价于“稠密embedding矩阵”与“one-hot/multi-hot向量”相乘,但是在实现的时候,是万万不能用矩阵乘法的方式实现的,因为把稀疏ID特征展开成one-hot/multi-hot向量,在推荐系统这样一个“高维稀疏ID特征”主导的场景下,计算代价是无法接受的。所以,我们必须实现稀疏的前代和回代,回代时不用更新整个embedding矩阵,而只更新batch中出现的有限几个feature id对应的那几行,而IndexedSlices就是用来记录那些要更新的位置。具体详情见《用NumPy手工打造 Wide & Deep》一文。
另外,我还非常推崇FM算法,称赞它为一把小巧灵活、但功能强大、还适用于召回+粗排+粗排等多场景的瑞士军刀,而且FM很多思想是与DNN是相通的。而如果想彻底吃透FM算法,最有效的方法就是阅读一遍alphaFM的源码。该项目只不过是作者八小时之外的课外作品,却被很多公司拿来投入线上实际生产环境,足见该项目性能之优异和作者功力之深厚,通读一遍下来,一定收获满满。
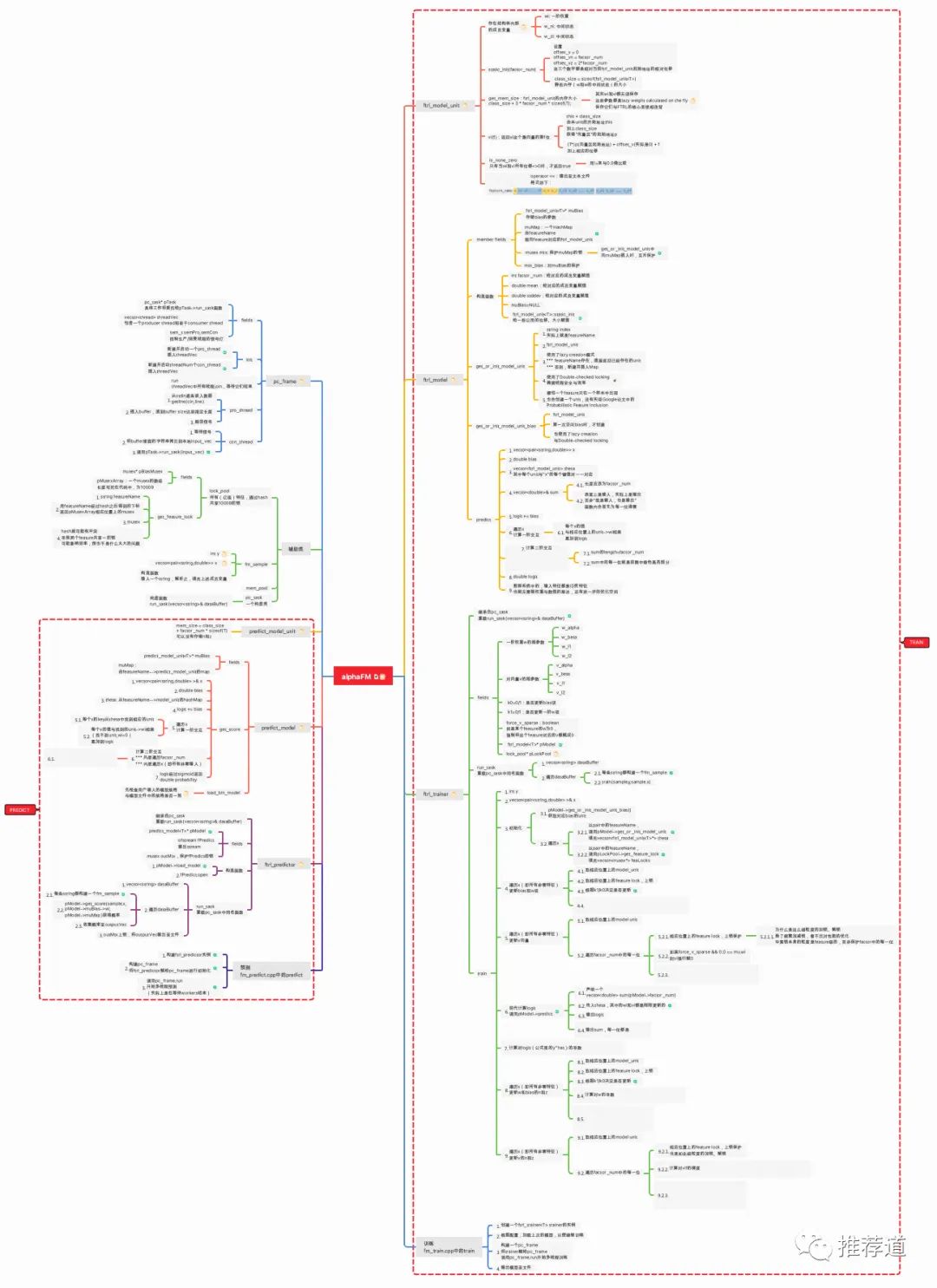
后记
总结了一下我的算法学习经验,分享给大家:
-
工欲善其事 ,必先利其器。读书笔记的重要性,是无论怎么强调也不过分的,它相当于我们的“第二大脑”、“知识库”。而一个合适的笔记工具是这个“知识库”正常运转的物理基础。文章中我介绍一下我正在使用的两款知识库工具。
-
接下来,我从以下5个方面阐述了我的算法学习方法论:
-
坚持问题导向:读论文,不要迷失在炫技般复杂的算法中,有时候作者提出的问题比他提出的解决方法更重要。检查作者提出的问题,是否也存在于我们自己的推荐系统中?意识到问题的存在,就成功解决了一半,没准你能提出比作者更优秀、更切合自身实际的解决方案。 -
举一反三:切忌不要孤立地读论文,正确的姿势是,将这篇论文的知识点与之前的知识点串联起来,读得论文多了,孤立的知识点串联成脉络,才将真正将别人的文章变成了你自己的知识,而不是“读君一篇论文,如读一篇论文”。 -
勤于总结与反思:周期性地总结回顾一下之前学习到的知识。希望你能够发现,随着自己功能的提高,对知识的理解也提高了一个层次。 -
敢于怀疑:看论文,没必要被作者的名号,或者大厂的招牌,震住,敢于怀疑“权威”,敢于提出自己的观点,才能够提升自己。 -
关注代码实现细节:不满足只做“调包师”和“调参侠”,最好的办法,就是学习经典算法的实现源码,等自己功力修炼到一定程度,自己(从头)实现一遍,再长一层功力。
希望我的这篇经验总结能够为“准备转行算法”和“已经奋斗在算法行业”的同学们提供帮助。
公众号后台回复“ECCV2022”获取论文资源分类汇总下载~

“
点击阅读原文进入CV社区
收获更多技术干货



