ICML 最佳论文提名论文:理解词嵌入类比行为新方式
选自arxiv
作者:Carl Allen、Timothy Hospedales
机器之心编译
参与:王子嘉、张倩
前不久,ICML大会在美国举办。大会放出了最佳论文等奖项,还有7篇最佳论文荣誉提名论文,本文便是其中的一篇。在这篇论文中,来自爱丁堡大学的研究者提出了一种解释词嵌入类比(如「女人之于王后就像男人之于国王」)的新方式,推导出了一种意译 (paraphrasing) 的概率定义,即「w_x之于w_y」的数学描述。他们通过这些概念证明了W2V型嵌入之间存在线性关系。
word2vec(W2V)这类神经网络生成的词嵌入以其近似线性的特性而闻名,比如「女人之于王后就像男人之于国王」这种类比嵌入,描述了一种近似平行四边形的结构。
有趣的是,这个特性并不是从训练中得来的。对此现象也有几种解释,但每一种解释都引入了不太合理的假设。
研究者推导出一种意译(paraphrasing)的概率定义,即「w_x 之于 w_y」的数学描述,并将其称为单词转换(word transformation)。他们通过这些概念证明了 W2V 型嵌入之间存在线性关系,这些关系是类比的基础,并确定了显式误差项。
研究者首先展示了嵌入在因子分解点互信息(PMI)的情况下,它的意译决定了嵌入的线性组合何时等于另一个单词的线性组合。例如,如果 king 和 {man, royal} 是语义等价的,就说 king 可以意译为 man 和 royal。
我们可以用邻近单词的概率分布来衡量这种等价性,这印证了一句弗斯的一句格言——「你应该通过语境来理解一个单词」。然后,研究者提出意译可以看作是基于加减法的单词转换(例如 man 加 royal 变成 king)。
最后,研究者通过将类比「w_a 之于 w_a ^∗就像 w_b 之于 w_b ^∗」解释为「w_a 之于 w_a ^∗和 w_b 之于 w_b ^∗」共享参数的单词转换,证明了本文中的观点。图 4 展示了类比中词嵌入的线性关系。
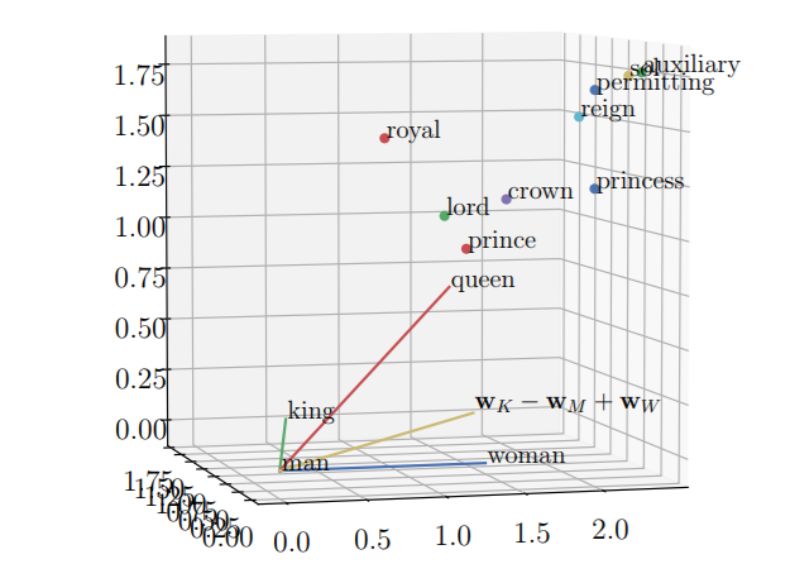
图 1:类比「man is to king as woman is to ..?」的词嵌入的相对位置。其中最接近 w_K - w_M + w_W 线性组合的词嵌入是 queen。研究者解释了发生这种情况的原因及它们之间的区别。
本文的主要贡献是:
得出意译的概率定义,并证明意译控制一个单词嵌入(PMIderived)与任意单词之和的关系;
说明如何泛化意译,并利用「w_x 之于 w_x^∗」的数学表达式将其解释为从一个单词到另一个单词的转换,;
首次严谨地证明了类比词嵌入之间的线性关系,包括显式的、可解释的误差项;
展示了这些关系如何在 PMI 向量之间实现,这些关系在因式分解了 PMI 矩阵的词嵌入以及类似的分解(如 W2V 和 Glove 等)中也都适用。
背景知识
Levy & Goldberg(2014b)发现,如果满足以下条件,则 W2V 的目标函数是最优的:
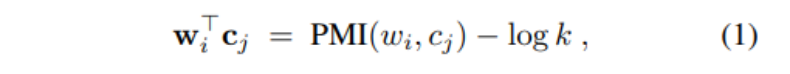
其中,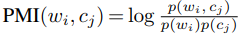
其中,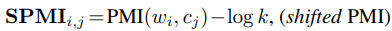
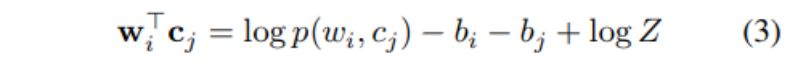
由于偏差的存在,(3) 泛化 (1),使得 Glove 拥有比 W2V 更大的灵活性以及可能更加广泛的解。然而,本文将要展示的是,是 PMI 指标的因式分解导致了嵌入中的线性类比结构,正如 W2V (1) 中实现的那样。研究者推测,支持 Glove 嵌入类比结构的理论基础也是相同的,但可能由于其增加的灵活性而更加薄弱。
初步研究
研究者考虑了与词嵌入和共现统计量之间关系相关的方面 (1,2),这与类比嵌入之间的线性结构相关:
偏移的影响
作为一个超参数,它不反映任何词属性,对 (1) 中出现的 k 的嵌入的影响也是随机的。将 k 的典型值与常见的 PMI 值进行比较(图 2)后可以发现,偏移(shift)(- log k)可能也很重要。
此外,可以观察到,为了避免偏移的直接影响而对 W2V 算法的调整提高了嵌入的性能 (Le, 2017)。因此,这种偏移显然是 W2V 算法的有害产物,除非另有说明,否则尽量还是使用对未平移 PMI 矩阵进行分解的嵌入:
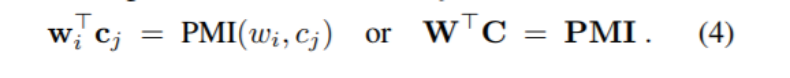
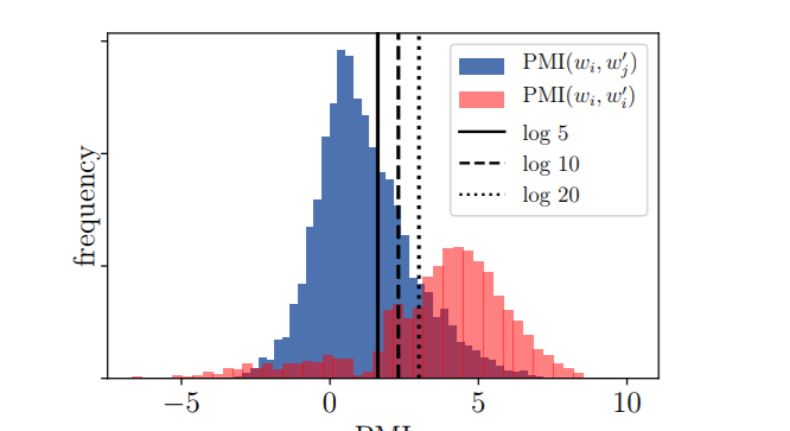
图 2: 从文本中随机抽取的单词对的 PMI 直方图(w_i, c_j,蓝色)与相同单词重叠(红色,缩放)的 PMI 直方图 (w_i, c_i)。偏移使用 k 的典型值。
重构误差
在实践中,(2) 和 (4) 仅近似成立,因为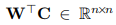

零同现数(Zero Co-occurrence Counts)
罕见词汇的同时出现往往会被忽视,因此它们的经验概率估计值为零,PMI 估计值也未被定义。然而,对于一个固定的字典 E,随着语料库或语境窗口的增大,这样的零计数会减少(如果较远的单词向下加权,语境窗口大小可以任意变大,如 Pennington et al. (2014))。
这里,我们只考虑小词集 W,并假设语料库和语境窗口足够大,概率真实值为非零,且其 PMI 值定义良好,即:
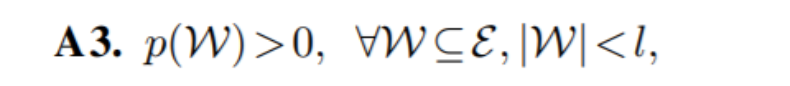
其中「|W| < l」表示 |W| 充分小于 l。
W 与 C 之间的关系
一些工作(如 Hashimoto et al. (2016),Arora et al .(2016))假设嵌入矩阵 W 和 C 相等,即 w_i = c_i ∀_i。这种假设使得参数减半,且简化了方程,不再需要过多考虑 w_i 和 c_i。
然而,这意味着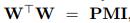
结论
本文中,研究者通过参考单词对其周围的单词所引起的分布,在单词和单词集之间产生等价,推导出意译的概率定义。
他们证明,在统计依赖关系下,是意译关系导致了分解 PMI 的词嵌入(包括 PMI 矩阵的列)与近似分解 PMI 的词嵌入(如 W2V 和 Glove)之间的线性关系。
意译可以解释为单词转换,因此我们可以用数学方法定义类比,从而将语义属性转换为词嵌入的属性。这首次精确地证明了类比词嵌入之间的线性关系的存在。
在未来的工作中,研究者的目标是将他们对词嵌入之间关系的理解扩展到其他依赖于底层矩阵分解的离散对象表示应用中,例如图嵌入和推荐系统。
此外,众所周知,词嵌入可以捕捉语料库中存在的偏见(Bolukbasi et al. (2016)),未来的工作可能会着眼于发展对嵌入组合的理解,以提出纠正或消除带有偏见的嵌入的方法。

论文链接:https://arxiv.org/abs/1901.09813v2
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



