CNN网络介绍与实践-王者荣耀英雄图片识别
本文主要是对CS231n课程学习笔记的提炼,添加了一些Deep Learning Book和Tensorflow 实战,以及Caffe框架的知识。
一、卷积神经网络
1.1 卷积神经网络与常规神经网络
1.1.1 相同点
卷积网络是一种专门用来处理具有类似网格结构的数据的神经网络。它常规神经网络非常相似:它们都是由神经元组成,神经元中有具有学习能力的权重和偏差。每个神经元都得到一些输入数据,进行内积运算后再进行激活函数运算。整个网络依旧是一个可导的评分函数:该函数的输入是原始的图像像素,输出是不同类别的评分。在最后一层(往往是全连接层),网络依旧有一个损失函数(比如SVM或Softmax),并且在神经网络中我们实现的各种技巧和要点依旧适用于卷积神经网络。
1.1.2 不同点
卷积神经网络的结构基于一个假设,即输入数据是图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。常规神经网络的神经网络的输入是一个向量,然后在一系列的隐层中对它做变换。每个隐层都是由若干的神经元组成,每个神经元都与前一层中的所有神经元连接。但是在一个隐层中,神经元相互独立不进行任何连接。
常规神经网络对于大尺寸图像效果不尽人意。在CIFAR-10中,图像的尺寸是32x32x3(宽高均为32像素,3个颜色通道),因此,对应的的常规神经网络的第一个隐层中,每一个单独的全连接神经元就有32x32x3=3072个权重。这个数量看起来还可以接受,但是很显然这个全连接的结构不适用于更大尺寸的图像。举例说来,一个尺寸为200x200x3的图像,会让神经元包含200x200x3=120,000个权重值。而网络中肯定不止一个神经元,那么参数的量就会快速增加!显而易见,这种全连接方式效率低下,大量的参数也很快会导致网络过拟合。
卷积神经网络针对输入全部是图像的情况,将结构调整得更加合理,获得了不小的优势。与常规神经网络不同,卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度(这里的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数)。我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。如下图为常规神经网络和卷积神经网络示意图:
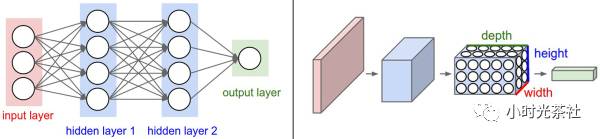
1.2 卷积神经网络结构
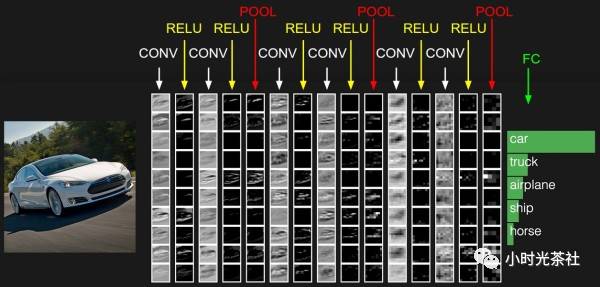
一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可以微分的函数将激活数据从一个层传递到另一个层。卷积神经网络主要由三种类型的层构成:卷积层,池化(Pooling)层和全连接层(全连接层和常规神经网络中的一样)。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络,结构如下图所示:
1.2.1 卷积层
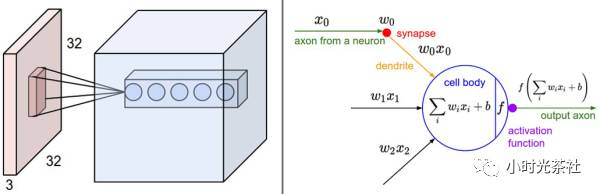
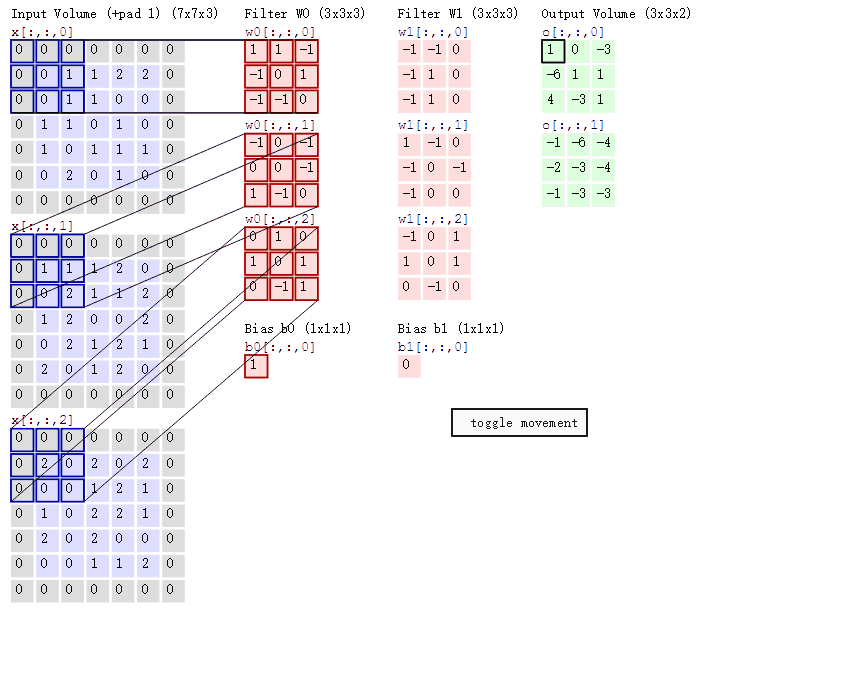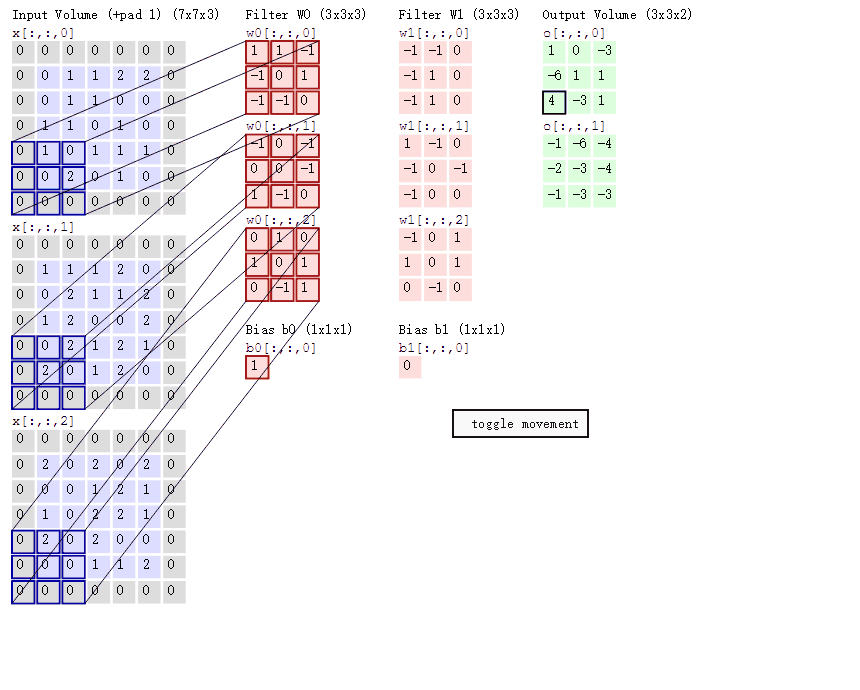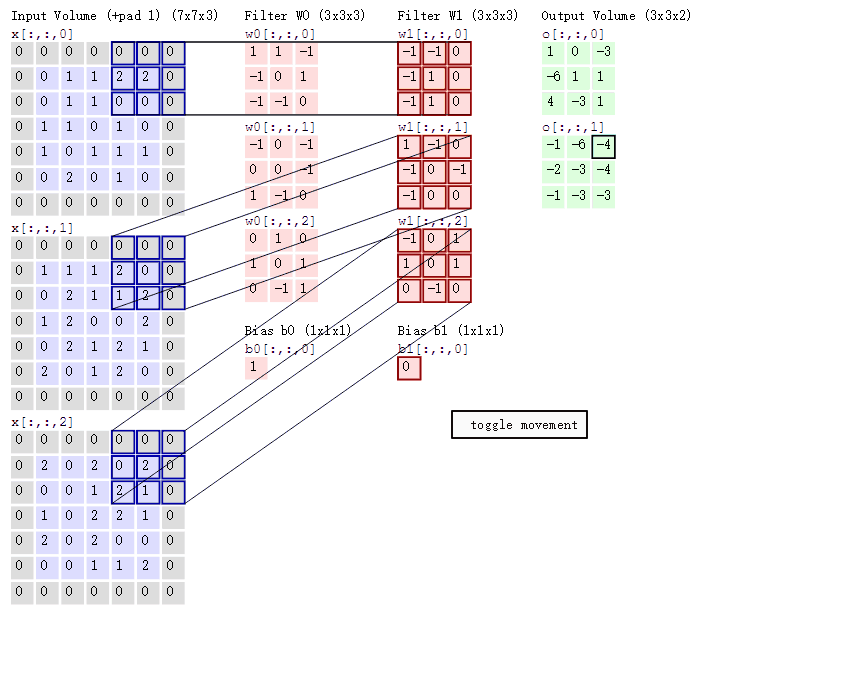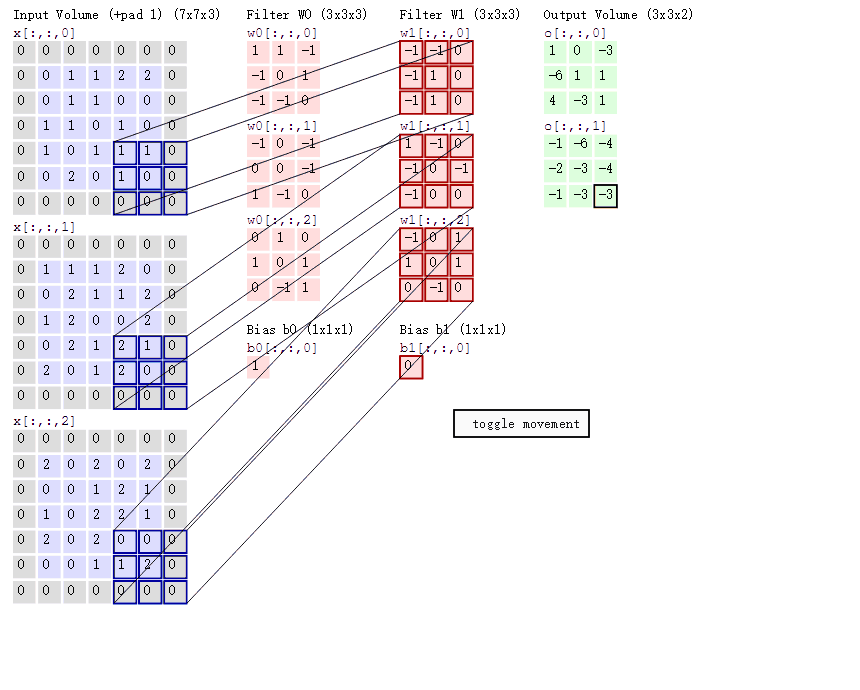
卷积层的参数是由一些可学习的滤波器集合构成的。每个滤波器在空间上(宽度和高度)都比较小,但是深度和输入数据一致。 在前向传播的时候,让每个滤波器都在输入数据的宽度和高度上滑动(更精确地说是卷积),然后计算整个滤波器和输入数据任一处的内积。当滤波器沿着输入数据的宽度和高度滑过后,会生成一个2维的激活图(activation map),激活图给出了在每个空间位置处滤波器的反应。直观地来说,网络会让滤波器学习到当它看到某些类型的视觉特征时就激活,具体的视觉特征可能是某些方位上的边界,或者在第一层上某些颜色的斑点,甚至可以是网络更高层上的蜂巢状或者车轮状图案。在每个卷积层上,我们会有一整个集合的滤波器(比如12个),每个都会生成一个不同的二维激活图。将这些激活映射在深度方向上层叠起来就生成了输出数据,如下图左所示,32*32的图像经过多个滤波器输出数据:
(1) 局部连接
局部连接会大大减少网络的参数。在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。相反,我们让每个神经元只与输入数据的一个局部区域连接。该连接的空间大小叫做神经元的感受野(receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。需要再次强调的是,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。
(2) 空间排列
上文讲解了卷积层中每个神经元与输入数据体之间的连接方式,但是尚未讨论输出数据体中神经元的数量,以及它们的排列方式。共有3个超参数控制着输出数据体的尺寸:深度(depth),步长(stride)和零填充(zero-padding)。下面是对它们的讨论:
1) 输出数据体深度
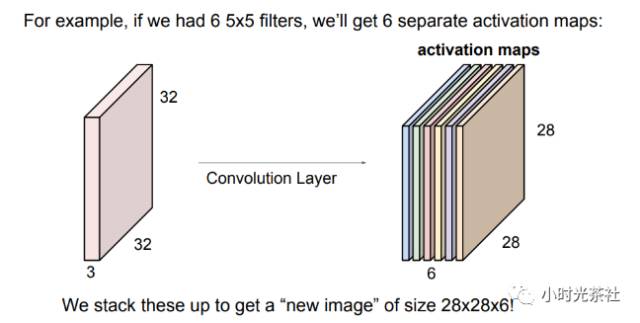
它和使用的滤波器的数量一致,每个滤波器会在输入数据中寻找一些不同的东西。举例来说,如果第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被不同方向的边界,或者是颜色斑点激活。我们将这些沿着深度方向排列、感受野相同的神经元集合称为深度列(depthcolumn)。如下图所示卷积层共有6个滤波器,输出的数据深度也为6。
2) 步长
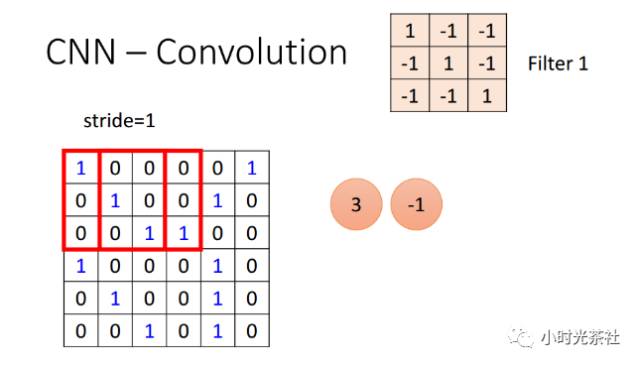
在滑动滤波器的时候,必须指定步长。当步长为1,滤波器每次移动1个像素。当步长为2(或者不常用的3,或者更多,这些在实际中很少使用),滤波器滑动时每次移动2个像素。这个操作会让输出数据体在空间上变小。如下图所示,移动的步长为1,输入的数据尺寸6 * 6,而输出的数据尺寸为4 * 4。
3) 填充
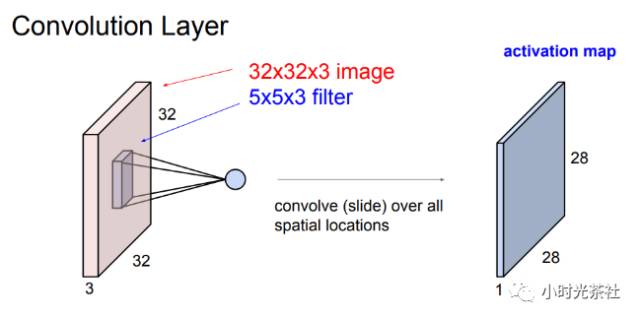
卷积层滤波器输出会减少数据的尺寸,如下图,32 * 32 * 3的输入经过一个5 * 5 * 3的滤波器时输出28 * 28 * 1尺寸的数据。
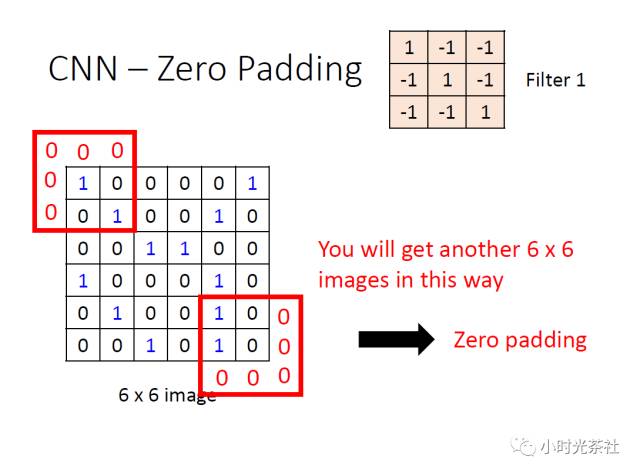
而零填充有一个良好性质,即可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。将输入数据体用0在边缘处进行填充是很方便的,这个零填充(zero-padding)的尺寸是一个超参数。如下图所示通过零填充保持了输入输出数据宽高的一致。
卷积层输出计算公式:
假设输入数据体的尺寸为:
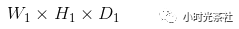
卷积层4个超参数为:

则输出数据体的尺寸为:
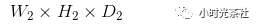
其中:
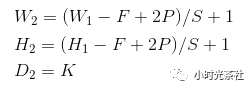
对这些超参数,常见的设置是F=3,S=1,P=1。比如输入是7x7,滤波器是3x3,步长为1,填充为0,那么就能得到一个5x5的输出。如果步长为2,输出就是3x3。
(3) 参数共享
在卷积层中使用参数共享是用来控制参数的数量。每个滤波器与上一层局部连接,同时每个滤波器的所有局部连接都使用同样的参数,此举会同样大大减少网络的参数。
这里作一个合理的假设:如果一个特征在计算某个空间位置(x,y)的时候有用,那么它在计算另一个不同位置(x2,y2)的时候也有用。基于这个假设,可以显著地减少参数数量。换言之,就是将深度维度上一个单独的2维切片看做深度切片(depth slice),比如一个数据体尺寸为[55x55x96]的就有96个深度切片,每个尺寸为[55x55]。在每个深度切片上的神经元都使用同样的权重和偏差。在反向传播的时候,都要计算每个神经元对它的权重的梯度,但是需要把同一个深度切片上的所有神经元对权重的梯度累加,这样就得到了对共享权重的梯度。这样,每个切片只更新一个权重集。
在一个深度切片中的所有权重都使用同一个权重向量,那么卷积层的前向传播在每个深度切片中可以看做是在计算神经元权重和输入数据体的卷积(这就是“卷积层”名字由来)。这也是为什么总是将这些权重集合称为滤波器(filter)(或卷积核(kernel)),因为它们和输入进行了卷积。下图动态的显示了卷积的过程:
1.2.2 池化层
通常,在连续的卷积层之间会周期性地插入一个池化层。它的作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。池化层使用Max操作,对输入数据体的每一个深度切片独立进行操作,改变它的空间尺寸。最常见的形式是池化层使用尺寸2x2的滤波器,以步长为2来对每个深度切片进行降采样,将其中75%的激活信息都丢掉。每个Max操作是从4个数字中取最大值(也就是在深度切片中某个2x2的区域)。深度保持不变。
池化层的计算公式:
输入数据体尺寸:
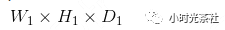
池化层有两个超参数:
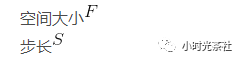
输出数据体尺寸:
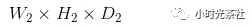
其中:
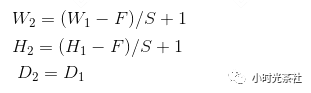
因为对输入进行的是固定函数计算,所以没有引入参数。在池化层中很少使用零填充。
在实践中,最大池化层通常只有两种形式:一种是F=3, S=2,另一个更常用的是F=2, S=2。对更大感受野进行池化需要的池化尺寸也更大,而且往往对网络有破坏性。
普通池化(General Pooling):除了最大池化,池化单元还可以使用其他的函数,比如平均池化(average pooling)或L-2范式池化(L2-norm pooling)。平均池化历史上比较常用,但是现在已经很少使用了。因为实践证明,最大池化的效果比平均池化要好。池化层的示意图如下图所示:
反向传播:回顾一下反向传播的内容,其中函数的反向传播可以简单理解为将梯度只沿最大的数回传。因此,在向前传播经过汇聚层的时候,通常会把池中最大元素的索引记录下来(有时这个也叫作道岔(switches)),这样在反向传播的时候梯度的路由就很高效。
1.2.3 归一化层
在卷积神经网络的结构中,提出了很多不同类型的归一化层,有时候是为了实现在生物大脑中观测到的抑制机制。但是这些层渐渐都不再流行,因为实践证明它们的效果即使存在,也是极其有限的。
1.2.4 全连接层
在全连接层中,神经元对于前一层中的所有激活数据是全部连接的,这个常规神经网络中一样。它们的激活可以先用矩阵乘法,再加上偏差。
1.3 常用CNN模型
1.3.1 LeNet
这是第一个成功的卷积神经网络应用,是Yann LeCun在上世纪90年代实现,被用于手写字体的识别,也是学习神经网络的“Hello World”。网络结构图如下图所示:
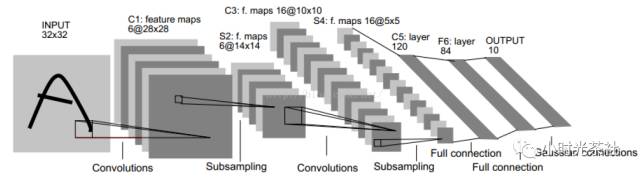
C1层:卷积层,这层包含6个特征卷积核,卷积核的大小为5 * 5,然后可以得到6个特征图,每个特征图的大小为32-5+1=28。
S2层:这是下采样层,使用最大池化进行下采样,池化的尺寸为2x2,因此我们可以得到6个14x14的特征图。
C3层:卷积层,这层包含16个特征卷积核,卷积核的大小依然为5x5,因此可以得到16个特征图,每个特征图大小为14-5+1=10。
S4层:下采样层,依然是2x2的最大池化下采样,结果得到16个5x5的特征图。
C5层:卷积层,这层使用120个5x5的卷积核,最后输出120个1x1的特征图。
之后就是全连接层,然后进行分类。
1.3.2 AlexNet
Alexnet的意义重大,他证明了CNN在复杂模型下的有效性,使得神经网络在计算机视觉领域大放异彩。 它由Alex Krizhevsky,Ilya Sutskever和Geoff Hinton实现。AlexNet在2012年的ImageNet ILSVRC 竞赛中夺冠,性能远远超出第二名(16%的top5错误率,第二名是26%的top5错误率)。这个网络的结构和LeNet非常类似,但是更深更大,并且使用了层叠的卷积层来获取特征(之前通常是只用一个卷积层并且在其后马上跟着一个汇聚层)。结构图如下图所示:
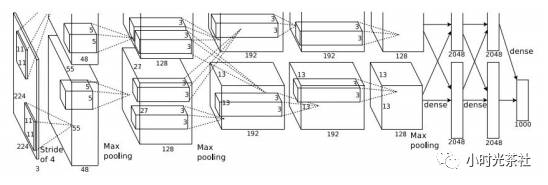
每层的详细信息如下图所示:
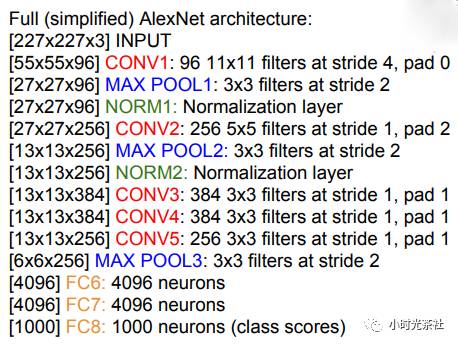

AlexNet输入尺寸为227x227x3。
第一个卷基层由96个大小为11x11的滤波器,步长为4。输出尺寸为(227 -11)/4 +1 = 55,深度为64。大概有11x11x3x643万5千个参数。
第二层池化的尺寸为3x3,步长为2,所以输出的尺寸为(55-3)/2+1=27。
这是第一次使用ReLU,至少第一次将ReLU发扬光大。
使用现在已经不怎么使用的数据规范化。
使用了很多数据增强。
1.3.3 ZFNet
Matthew Zeiler和Rob Fergus发明的网络在ILSVRC 2013比赛中夺冠,它被称为 ZFNet(Zeiler & Fergus Net的简称)。它通过修改结构中的超参数来实现对AlexNet的改良,具体说来就是增加了中间卷积层的尺寸,让第一层的步长和滤波器尺寸更小。他们基于试验做了一些参数的调整。结构图如下图所示:
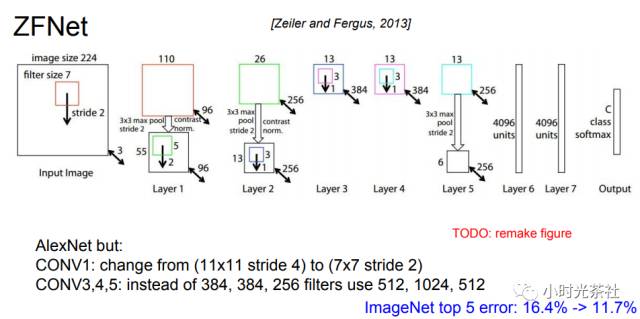
1.3.4 VGGNet
VGGNet并没有疯狂的架构选择,没有在如何设定滤波器的个数,尺寸大小上做非常多的工作。整个VGG网络只用3*3卷积核,滑动步长2和2*2池化窗口,滑动步长2。整个过程就维持了这样的参数设定。VGG的关键点在于这个操作你重复了多少层,最后同样的这组参数设定的网络结构重复了16层。选择这个层的原因可能是他们发现这样有最好的表现。对于每张图片需要200M内存,所有的参数加起来,最终总的参数量会达到1.4亿。
为什么使用3*3滤波器?3*3是最小的能够捕获上下左右和中心的感受野,多个3*3的卷积层比一个更大尺寸滤波器卷积层有更多的非线性。在步长为1的情况下, 两个3*3的滤波器的最大感受野区域是5*5, 三个3*3的滤波器的最大感受野区域是7*7, 可以替代更大的滤波器尺寸多个3*3的卷积层比一个大尺寸的filter有更少的参数,假设卷积层的输入和输出的特征图大小相同为10,那么含有3个3*3的滤波器的卷积层参数个数3*(3*3*10*10)=2700, 因为三个3*3的filter可以看成是一个7*7的filter分解而来的(中间层有非线性的分解), 但是1个7*7的卷积层参数为7*7*10*10=4900 1*1滤波器作 用是在不影响输入输出维数的情况下,对输入线进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
VGGNet不好的一点是它耗费更多计算资源,并且使用了更多的参数,结构图如下所示:

1.3.5 GoogLeNet
VGGNet性能不错,但是有大量的参数。一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合也会大大增加计算量。
一般文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。“稀疏连接结构”的理解是这样的,用尽可能的“小”、“分散”的可堆叠的网络结构,去学习复杂的分类任务,Inception之所以能提高网络精度,可能就是归功于它拥有多个不同尺度的kernels,每一个尺度的kernel会学习不同的特征,把这些不同kernels学习到的特征汇聚给下一层,能够更好的实现全方位的深度学习。
普通的Inception结构如下图所示:
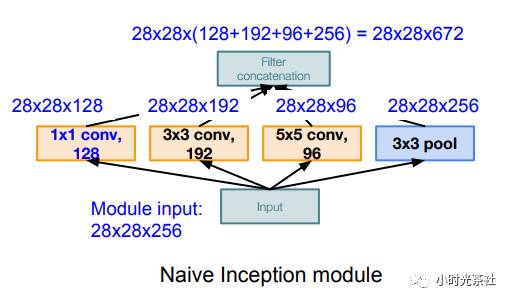
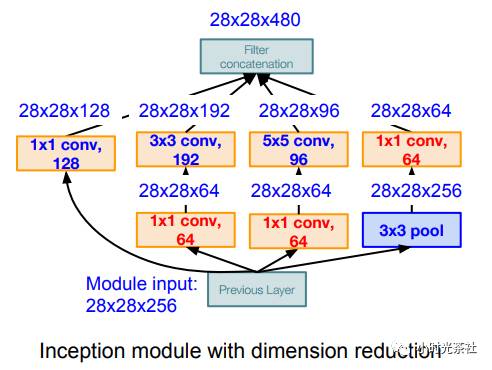
降维实现的Inception如下图所示,将256维降到64维,减少了参数量:
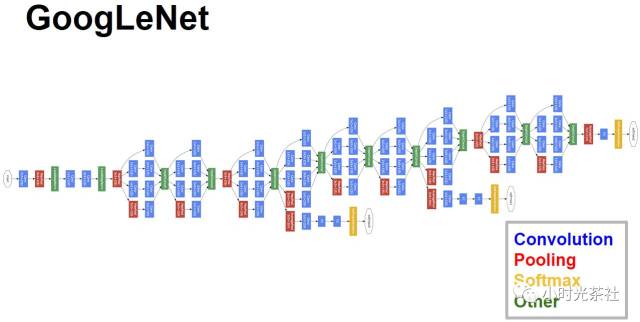
为什么VGG网络的参数那么多?就是因为它在最后有两个4096的全连层。Szegedy吸取了教训,为了压缩GoogLeNet的网络参数,他把全连层取消了。GoogLeNet完整结构如下图所示:
1.3.6 ResNet
由何恺明和同事完成的残差网络,他们不仅仅在2015年的ImageNet上获胜,同时还赢得了相当多的比赛,几乎所有重要比赛的第一名。在深度网络优化中存在一个著名的障碍是:梯度消失和梯度爆炸。这个障碍可以通过合理的初始化和一些其他技术来解决,但是随着网络的深度增加,准确度饱和并迅速减少,这一现象称为degradation,并且广泛的存在于深层网络中,说明不是所有的系统都很容易被优化。
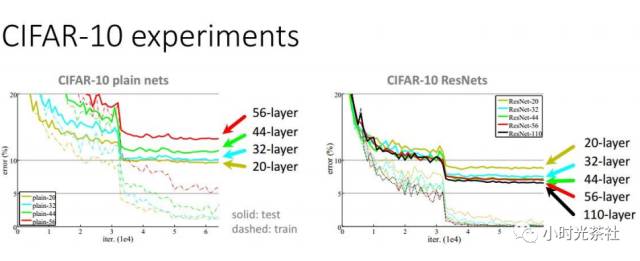
对于plainnet 如果你单纯的提高网络层数,将没有什么用处。如上图,在cifar-10上,实线是测试集上的错误率,虚线是训练集上的错误率。我们看到层数更深的网络错误率反而更高,这不科学,按道理来说,层数更深的网络容量更大,那是因为我们在优化参数上做的不够好,没法选择更优的参数。而残差网络模型的训练错误率和测试错误率都随着网络深度的增加在持续的改进。训练ResNet需要2-3周8个GPU训练。
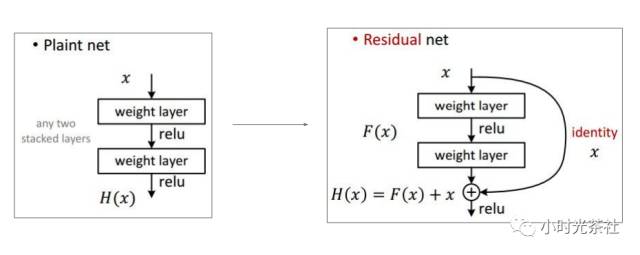
何恺明提出了深度残差学习的概念来解决这一问题。首先我们假设我们要求的映射是H(x),通过上面的观察我们意识到直接求得H(x)并不那么容易,所以我们转而去求H(x)的残差形式F(x)=H(x)-x,假设求F(x)的过程比H(x)要简单,这样,通过F(x)+x我们就可以达到我们的目标,简单来说就是上面这幅图,我们将这个结构称之为一个residual block。 相信很多人都会对第二个假设有疑惑,也就是为什么F(x)比H(x)更容易求得,关于这一点,论文中也没有明确解释。但是根据后的实验结果确实可以得到这一个结论。
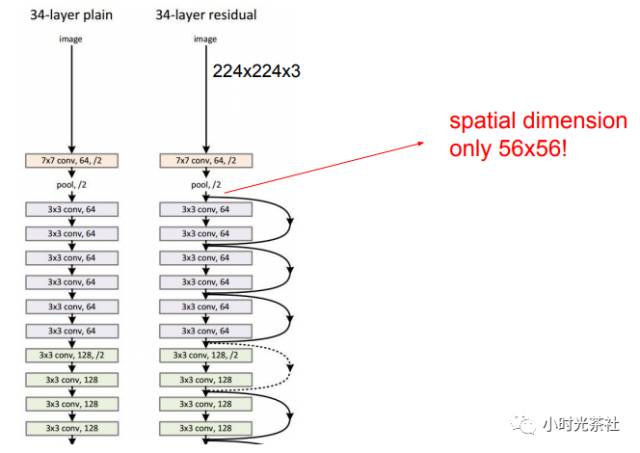
在ResNet中有这些有趣的跳跃连接,如上图所示。在残差网络的反向传播中,梯度除了流经这些权值向后传播,还有这些跳跃连接,这些跳跃连接是加法处理,可以分散梯度,让梯度流向之前的一部分,因此你可以训练出离图像很近的一些特征。
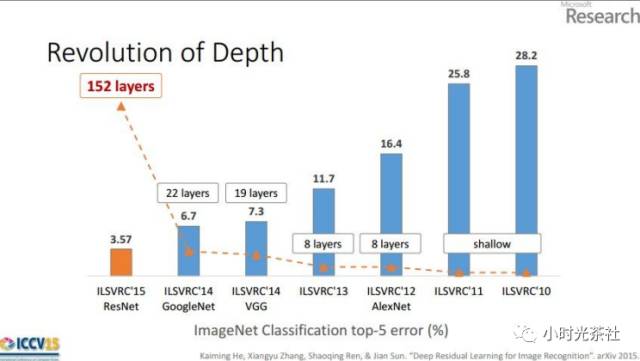
通过下图ImageNet上神经网络算法的深度和错误率统计,我们可以看到,神经网路层数越来约深,同时错误率也越来越低。
二、Tensorflow实战
2.1 深度学习开源框架对比
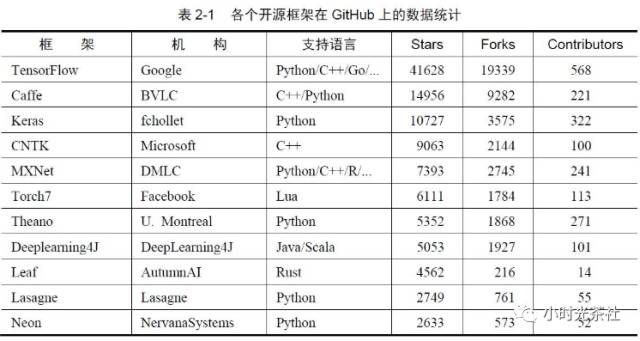
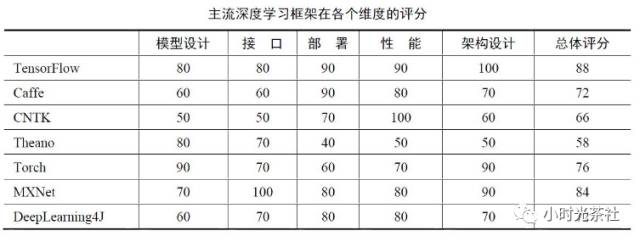
深度学习框架很多,我们这里只介绍两个用的比较多的框架:
Tensorflow:TensorFlow 是一个使用数据流图(data flow graphs)进行数值计算的开源软件库, 一个用于机器智能的开源软件库。TensorFlow拥有产品级的高质量代码,有Google强大的开发、维护能力的加持,整体架构设计也非常优秀。 Google作为巨头公司有比高校或者个人开发者多得多的资源投入到TensorFlow的研发,可以预见,TensorFlow未来的发展将会是飞速的,可能会把大学或者个人维护的深度学习框架远远甩在身后。TensorFlow是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写C++或CUDA代码。
TensorFlow也有内置的TF.Learn和TF.Slim等上层组件可以帮助快速地设计新网络 TensorFlow的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量CPU或GPU的PC、服务器或者移动设备上。 除了支持常见的网络结构[卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurent Neural Network,RNN)]外,TensorFlow还支持深度强化学习乃至其他计算密集的科学计算(如偏微分方程求解等)。
Caffe: Caffe是一个被广泛使用的开源深度学习框架,在Tensorflow出现之前一直是深度学习领域Github star最多的项目。Caffe的主要优势为:1.容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络。训练速度快,组件模块化,可以方便的拓展到新的模型和学习任务上。但是Caffe最开始设计时的目标只针对于图像,没有考虑文本、语音或者时间序列的数据,因此Caffe对卷积神经网络的支持非常好,但是对于时间序列RNN,LSTM等支持的不是特别充分。
2.2 Tensorflow环境搭建
2.2.1 操作系统
Tensorflow支持在window、linux、mac上面运行,我搭建的环境使用的是Ubuntu16.04 64位。Tensorflow需要依赖python环境,这里默认使用python3.5作为python的基础版本。推荐使用Anaconda作为Python环境,因为可以避免大量的兼容性问题。
2.2.1 安装Anaconda
Anaconda是Python的一个科学计算发行版,内置了数百个Python经常使用会使用的库,其中可能有一些还是Tensorflow的依赖库。Anaconda的Python版本要和Tensorflow版本一致,不然会存在问题。我这里下载的是Anaconda3-4.2.0-Linux-x86_64.sh。执行:
bash Anaconda3-4.2.0-Linux-x86_64.sh安装Anconda,安装完成后,程序会提示我们是否把Anaconda3的binary路径加入到.bashrc,这里建议添加,这样以后python命令就会自动使用Anaconda Python3.5的环境了。
2.2.2 Tensorflow安装
Tensowflow分为cpu版本和gpu版本,如果你的电脑上有NVIDIA显卡的话,建议装GPU版本,他会加快你训练的速度。cpu版本安装比较简单,这里就不在赘述,主要讲下gpu版本的安装。首先使用:
lspci | grep -i nvidia查看nvidia显卡的型号,然后去https://developer.nvidia.com/cuda-gpus查看你的显卡是否支持cuda,只有支持cuda的gpu才能安装tensorflow的gpu版本。我的电脑是GeForce 940M 支持cuda。
(1) 安装CUDA和cuDNN
首先在nvidia官网上下载对应的cuda版本。这边下载是cuda_8.0.61_375.26_linux.run。这里下载会比较慢,建议使用迅雷下载。在安装前需要暂停NVIDIA的驱动X server,首先使用ctrl+alt+f2接入ubuntu的命令界面,如果进不去,有些电脑需要使用fn+ctrl+alt+f2然后执行
sudo /etc/init.d/lightdm stop暂停X Server。然后执行如下命令安装:
chmod u+x cuda_8.0.61_375.26_linux.runsudo ./cuda_8.0.61_375.26_linux.run先按q跳过开头的license,接着输入accept接受协议,然后按y键选择安装驱动程序,在之后的选择中,我们选择不安装OpenGL,否则可能出现在登录界面循环登录的问题。然后按n键选择不安装samples。
接下来安装cuDNN,cuDNN是NVIDIA推出的深度学习中的CNN和RNN的高度优化的实现,底层使用了很多先进的技术和接口,因此比其他GPU上的神经网络库性能高不少。首先从官网上下载cuDNN,这一步需要先注册NVIDIA的帐号,并等待审核。执行
cd /usr/local sudo tar -xzvf ~/Downloads/cudnn-8.0-linux-x64-v6.0.tgz就完可以成了cuDNN的安装。
(2) 安装Tensorflow
在github上下载对应的版本,这里下载的是tensorflow_gpu-1.2.1-cp35-cp35m-
linux_x86_64.whl。然后执行如下命令即可完成安装。
pip install tensorflow_gpu-1.2.1-cp35-cp35m-linux_x86_64.whl2.2 Hello World-MINST手写数字识别
2.2.1 使用线性模型 并使用softmax分类器
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)print(mnist.train.images.shape, mnist.train.labels.shape)print(mnist.test.images.shape, mnist.test.labels.shape)print(mnist.validation.images.shape, mnist.validation.labels.shape) sess = tf.InteractiveSession() x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x, W) + b) y_ = tf.placeholder(tf.float32, [None, 10]) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) tf.global_variables_initializer().run() for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(1000) train_step.run({x: batch_xs, y_: batch_ys}) correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))print(accuracy.eval({x: mnist.test.images, y_: mnist.test.labels}))2.2.2 使用CNN模型
from tensorflow.examples.tutorials.mnist import input_dataimport tensorflow as tf mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) sess = tf.InteractiveSession()def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial)def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial)def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') x = tf.placeholder(tf.float32, [None, 784]) y_ = tf.placeholder(tf.float32, [None, 10]) x_image = tf.reshape(x, [-1, 28, 28, 1]) W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1) W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2) W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1])) train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.global_variables_initializer().run()for i in range(10000): batch = mnist.train.next_batch(50) if i % 100 == 0: train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0}) print("step %d, training accuracy %g" % (i, train_accuracy)) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) print("test accuracy %g" % accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
三、王者荣耀英雄识别
在企鹅电竞的业务场景中,需要识别主播当前在王者荣耀中使用的英雄。这里初次尝试使用深度学习的方法来分类,使用的框架是Caffe。
3.1 设计特征
首先是准备训练数据,我们需要根据业务场景设计需要分类的特征。我们可以选择整张游戏画面、游戏中英雄画面或者技能键作为分类特征,如下图所示。使用整张游戏画面时,图片包含较多无关元素,能够标识英雄的特征区域较小。使用英雄截图可以作为明显特征,但是由于每个英雄存在多套皮肤,准备数据比较困难,以及会对识别准确率有影响。所以使用技能键区域作为分类特征是较好的选择。

在设计分类特征是需要特征尽可能清晰,并且不同种类之间的特征差别大。
3.2 收集数据
收集数据并标注是繁琐但是很重要的任务,同一个模型在不同的数据训练下可能效果会差别很大。这里是在Youtube针对不同的英雄分别下载一段15分钟左右的视频,然后使用如下ffmpeg命令截取技能键区域的图片并将其尺寸压缩。
ffmpeg -i videos/1/test.mp4 -r 1 -vf "crop=380:340:885:352,scale=224:224" images/1/test_%4d.png数据集图片文件夹如下图所示。需要人肉筛选其中不包含技能键的噪声图片,并将其放入0文件夹中。0文件夹作为背景分类,对应于无法识别英雄的分类。

这里每个分类大概包含1000-2000张图片。数据集当然越大越好,并且覆盖尽可能多的场景,增加模型的泛化能力。
3.3 处理数据
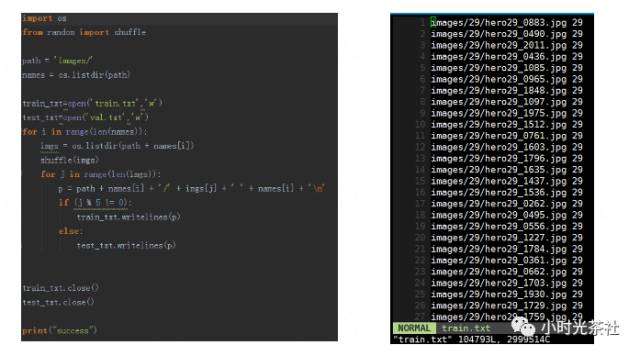
数据集生成好了之后,需要将其转换为Caffe能够识别的格式。首先使用下图左侧的python代码生成训练集和测试集所包含的图片,生成文件如下图右侧所示,包含图片路径和分类。其中测试集为所有图片的五分之一。
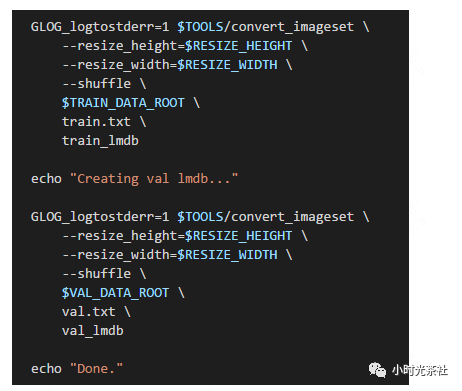
然后将图片转换为LMDB格式的数据,Caffe提供了工具帮助我们转换。处理脚本如下图所示。
3.4 选择模型
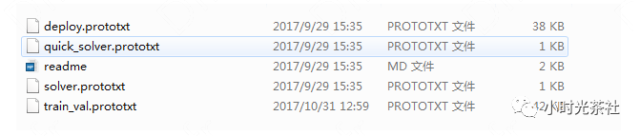
上文介绍的六种模型为常用的图片分类模型,这里我们选择GoogLeNet作为模型网络。在Caffe工程的models文件夹中有这些网络模型,查看caffe/models/bvlc_googlenet文件夹,其中文件如下图:
3.4.1 solver.prototxt
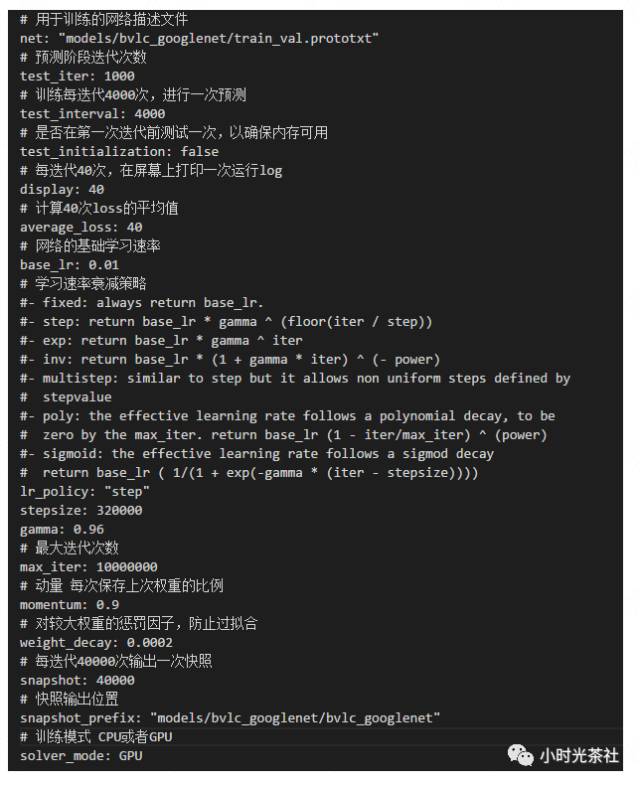
solver.prototxt文件夹中定义了训练模型所用到的参数,其中参数的具体含义如下图所示:
3.4.2 train_val.prototxt
train_val.prototxt为GoogLeNet网络的结构的具体定义,网络文件很多,这里介绍下独立的网络层结构。首先是数据层,其参数如下图所示:
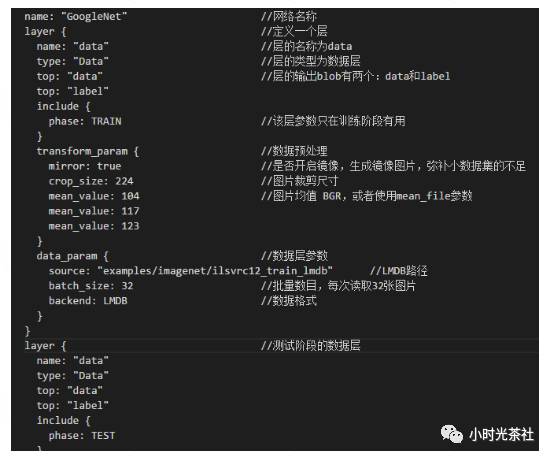
卷积层、ReLU层和池化层结构如下图所示:

LRN层的结构如下图所示:

Dropout层和全连接层如下图所示:

3.4.3 deploy.prototxt
deploy文件为部署时使用的网络结构,其大部分内容与train_val.prototxt文件相似,去掉了一些测试层的内容。
3.5 训练模型
将数据和模型准备好了之后,就可以进行模型的训练了。这里调用如下代码开始训练:
caffe train -solver solver.prototxt可以添加-snapshot 参数可以接着上次训练的模型训练,训练日志如下图所示:
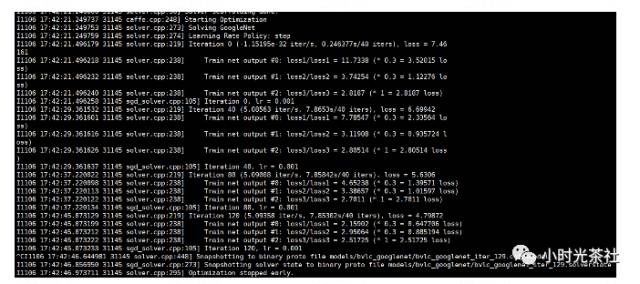
当模型收敛,或者准确率达到我们要求之后,可以停止训练。
3.6 裁剪模型
GoogLeNet本身是比较大的网络,我们可以根据自己的需求裁剪网络。
GoogLeNet中的LRN层影响不大可以去掉,或者删除一些卷积层,降低网络的层数。
3.7 finetuning
当我们的数据量比较小的时候,训练完整的网络参数比较容易过拟合。这时我们可以通过只训练网络的某几层来解决这个问题。
首先修改train_val.prototxt中的全连接层的名称,即loss1/classifier,loss2/classifier,loss3/classifier这三层的名称,以及他们的输出分类个数,默认是1000,需要改成我们自己的种类总数。这样我们再加载训练好的model时,这三层的参数才会重新初始化。然后将所有其他层的lr_mult该为0,这样其他层的参数不会改变,使用预先训练好的参数。
下载bvlc_googlenet.caffemodel,这是谷歌在ImageNet上训练出来的参数。然后调用caffe train -solver solver.prototxt -weights bvlc_googlenet.caffemodel即可训练。
Tips
局部极小值问题:可行的trick是开始阶段batchsize调小。
Loss爆炸:学习率调小。
Loss始终不收敛:要怀疑数据集或label是否有问题。
过拟合:数据增强,正则化、Dropout、BatchNormalization以及early stopping等策略。
权值初始化:一般xavier或gaussian。
Finetune: 使用GoogLeNet或VGG,可以finetune已有模型。
参考文档:
1、本文主要整理自CS231n课程笔记,中文翻译链接https://zhuanlan.zhihu.com/p/21930884。中文公开课链接http://study.163.com/course/introduction/1003223001.htm。强烈建议大家看看。
2、Yoshua Bengio 《Deep Learning Book》 炸裂推荐,非常值得一看。
3、周志华《机器学习》 适合机器学习入门。
4、《Tensorflow 实战》Tensorflow实践不错。
5、斯坦福大学深度学习教程 http://ufldl.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B。
作者:高成才,腾讯Android开发工程师,主要负责企鹅电竞推流SDK、企鹅电竞APP的功能开发和技术优化工作。
文章来源:小时光茶社



