何恺明团队最新力作SimSiam:消除表征学习「崩溃解」,探寻对比表达学习成功之根源
机器之心转载
本文是FAIR的陈鑫磊&何恺明大神在无监督学习领域又一力作,提出了一种非常简单的表达学习机制用于避免表达学习中的「崩溃」问题,从理论与实验角度证实了所提方法的有效性;与此同时,还侧面证实了对比学习方法成功的关键性因素:孪生网络。

论文地址:https://arxiv.org/abs/2011.10566
方法
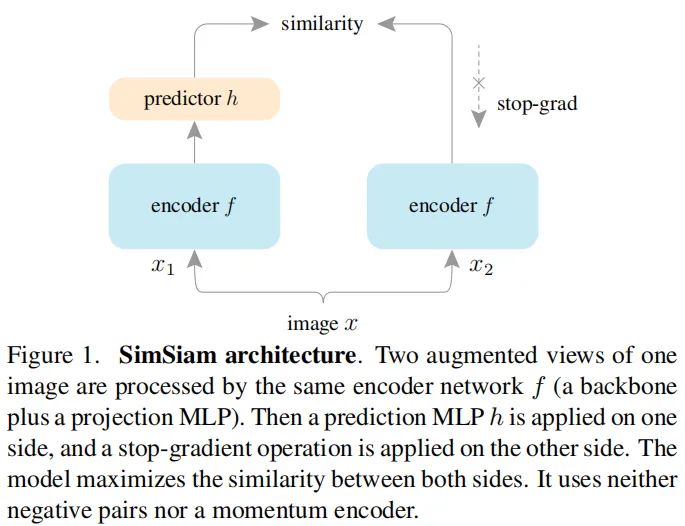
Stop-gradient操作(即上图的右分支部分)。可以通过对上述公式进行简单的修改得到本文的损失函数:
# Algorithm1 SimSiam Pseudocode, Pytorch-like
# f: backbone + projection mlp
# h: prediction mlp
for x in loader: # load a minibatch x with n samples
x1, x2 = aug(x), aug(x) # random augmentation
z1, z2 = f(x1), f(x2) # projections, n-by-d
p1, p2 = h(z1), h(z2) # predictions, n-by-d
L = D(p1, z2)/2 + D(p2, z1)/2 # loss
L.backward() # back-propagate
update(f, h) # SGD update
def D(p, z): # negative cosine similarity
z = z.detach() # stop gradient
p = normalize(p, dim=1) # l2-normalize
z = normalize(z, dim=1) # l2-normalize
return -(p*z).sum(dim=1).mean()
-
Optimizer: SGD用于预训练,学习率为 , 基础学习率为 ,学习率采用consine衰减机制,weight decay=0.0001,momentum=0.9。BatchSize默认512,采用了SynBatchNorm。 -
Projection MLP:编码网络中投影MLP部分的每个全连接层后接BN层,其输出层 后无ReLU,隐含层的 的维度为2048,MLP包含三个全连接层。 -
Prediction MLP:预测MLP中同样适用了BN层,但其输出层 后无BN与ReLU。MLP有2个全连接层,第一个全连接层的输入与输出维度为2048,第二个的输出维度为512. -
Backbone:作者选用了ResNet50作为骨干网络。
Stop-gradient
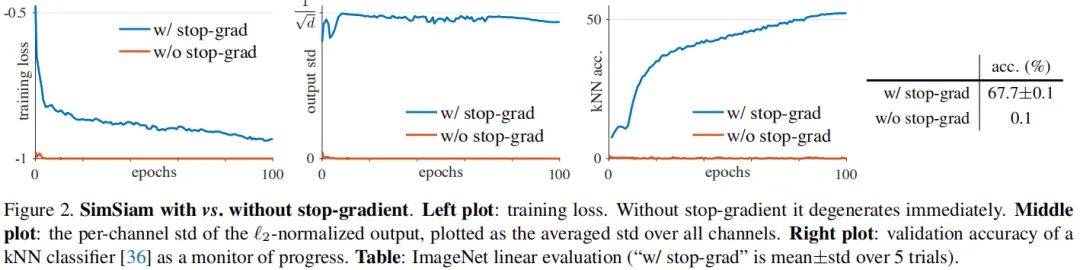
Stop-gradient添加与否的性能对比,注网络架构与超参保持不变,区别仅在于是否添加
Stop-gradient。
Stop-gradient
时,优化器迅速找了了一个退化解并达到了最小可能损失-1。为证实上述退化解是「崩溃」导致的,作者研究了输出的
规范化结果的标准差。如果输出「崩溃」到了常数向量,那么其每个通道的标准差应当是0,见上图middle。
Stop-gradient)接近
,这也就意味着输出并没有「崩溃」。
Stop-gradient时,其分类精度仅有0.1%,而添加
Stop-gradient后最终分类精度可达67.7%。
Predictor

-
当移除预测MLP头模块h(即h为恒等映射)后,该模型不再有效(work); -
如果预测MLP头模块h固定为随机初始化,该模型同样不再有效; -
当预测MLP头模块采用常数学习率时,该模型甚至可以取得比基准更好的结果(多个实验中均有类似发现).
Batch Size
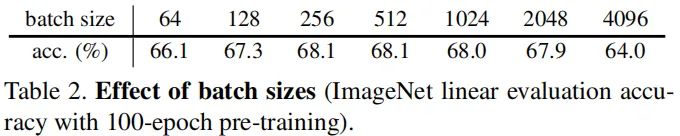
Batch Normalization

-
移除所有BN层后,尽管精度只有34.6%,但不会造成「崩溃」;这种低精度更像是优化难问题,对隐含层添加BN后精度则提升到了67.4%; -
在投影MLP的输出后添加BN,精度可以进一步提升到68.1%; -
在预测MLP的输出添加BN后反而导致训练变的不稳定。
Similarity Function
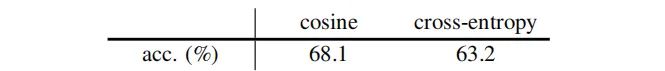
Symmetrization

stop-gradient
操作。
Hypothesis
Formulation
stop-gradient操作是引入额外变换的结果。我们考虑如下形式的损失:
stop-gradient是一个很自然的结果,因为梯度先不要反向传播到
,在该子问题中,它是一个常数;对于
的七届,上述问题将转换为:
Proof of concept

对比
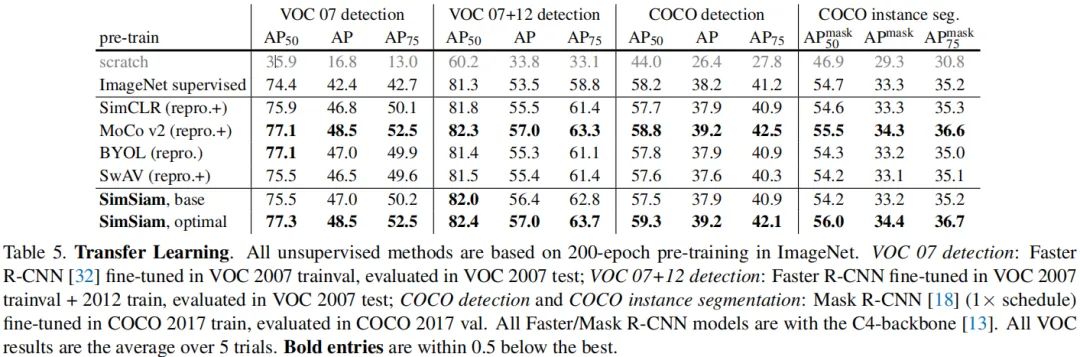
前述内容已经说明了所提方法的有效性,接下来将从ImageNet以及迁移学习的角度对比一下所提方法与其他SOTA方法。

-
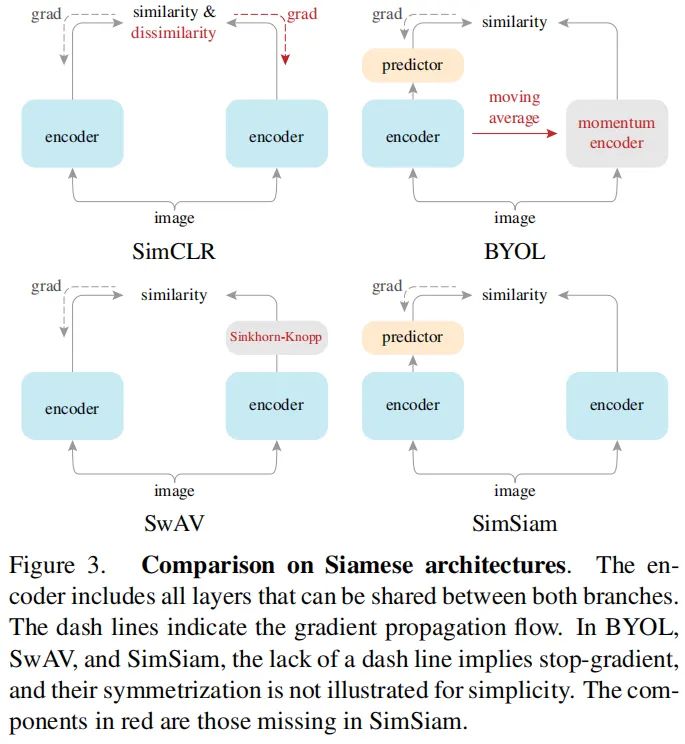
Relation to SimCLR:SimCLR依赖于负采样以避免「崩溃」,SimSiam可以是作为「SimCLR without negative」。 -
Relation to SwAV:SimSiam可以视作「SwAV without online clustering」. -
Relation to BYOL: SimSiam可以视作「BYOL without the momentum encoder」
相关文章:

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容


相关VIP内容
相关资讯