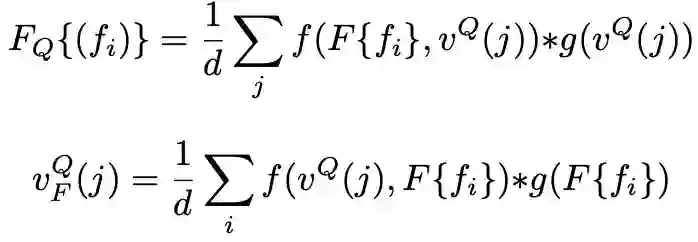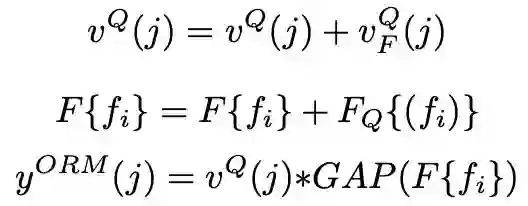本文是阿里巴巴达摩院视觉实验室潘攀博士团队在半监督视频目标分割领域的最新研究成果,已被 CVPR2021 接收。目前以 Space Time Memory Network(STM)为代表的 memory-based 算法在性能上有着巨大的优势,但仍然在部分场景中存在较大问题。本文分析了 memory-based 算法的局限性,提出建立位置和目标的一致性来作为改进方法,在 DAVIS、Youtube-VOS 等数据集上取得了 SOTA 结果。该成果同时获得了 DAVIS 2020 半监督视频目标分割比赛的冠军。
视频目标分割 (Video Object Segmentation,VOS) 是计算机视觉的基础任务,广泛应用于视频编辑、内容生产、自动驾驶等领域。其中,半监督视频目标分割,是指给定一段视频和第一帧的目标物体,在视频的所有剩余帧中分割出该物体。在一个视频序列中,目标物体往往会因为连续运动和视角变化发生很大的外观改变,包括形变和遮挡。同时视频中往往会有和目标相似的其他物体存在,使得分辨目标更加困难。因此,视频目标分割是一个比较有挑战性的问题,至今还没有很好的解决。
从最近的研究成果来看,Memory-based 的方法是目前 VOS 领域性能表现最佳的一类方法,其代表作是 STM。STM 提出利用过往所有历史帧的信息,对于当前待分割的帧,STM 会将其与所有历史帧在时空域上做一个匹配学习,从而将当前帧的特征和历史帧的特征关联起来,得到了远超之前方法的效果。然而 STM 的分割结果中仍然有很多不足。如下图所示,可以观察到有两个典型的错误现象:
![]()
左边一列图中,STM 会倾向于把和目标物体同类别的其他物体也分割出来。右边一列图中,STM 的分割结果中会出现一些错误的碎块。这些错误样本都有一个共同特点,就是其局部像素块的外观特征和待分割目标局部区域的外观特征极为相似。这些 badcase 的现象和 STM 本身的原理是有关联的,因为类似 STM 的 Memory-based 方法,在帧间关系建模上,是均等地在时间和空间域上做了一个特征像素级别的匹配,倾向于找出当前帧和所有历史帧标记 mask 区域的特征相似区域,因此会产生上述 badcase。
为了进一步提升 Memory-based 的 VOS 方法,该研究提出从两个方面去改进:
一、位置一致性。目标物体在视频帧间的运动是遵循一定轨迹的,如果在某一帧的一些位置出现和目标物体相似的同类物体,如果其位置不合理,那么该物体是目标物体的可能性就会降低,不应该被分割。
二、目标一致性。视频目标分割本质上也可以理解为是一个像素级别的物体跟踪。虽然分割是像素级的任务,但 VOS 的处理对象是物体(object),需要有一个类似图像实例分割中对于物体级别的约束。显然那些错误的碎块分割结果是不满足一个目标物体整体的概念的。
![]()
论文地址:https://arxiv.org/pdf/2104.04329.pdf
来自阿里巴巴达摩院视觉实验室潘攀博士团队提出了一个新的
视频目标分割方法 LCM
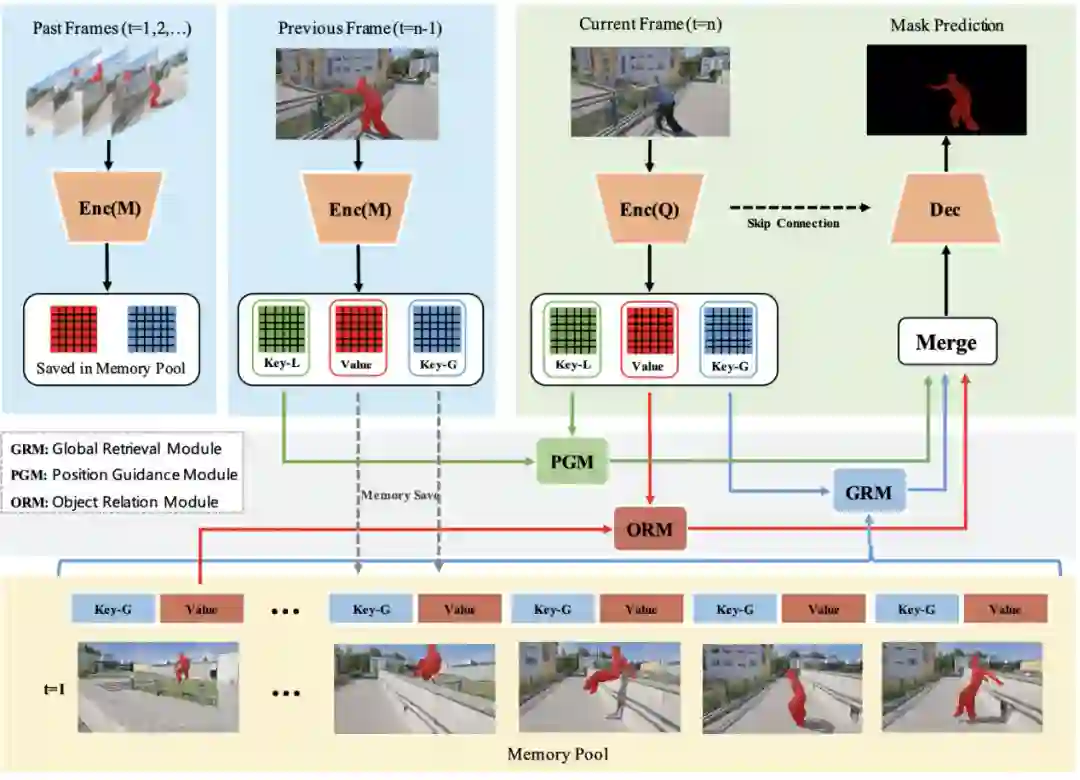
,主要包含三个模块 Global Retrieval Module(GRM)、Position Guidance Module(PGM)和 Object Relation Module(ORM)。其中 GRM 结构借鉴了 STM 的整体建模框架,该研究认为 GRM 本质上起到了召回当前帧所有与历史帧语义相似的区域像素的作用。但只有 GRM 是不够的,该研究的重点改进是提出后两个模块 PGM 和 ORM,分别对应之前所述的两个要点。
![]()
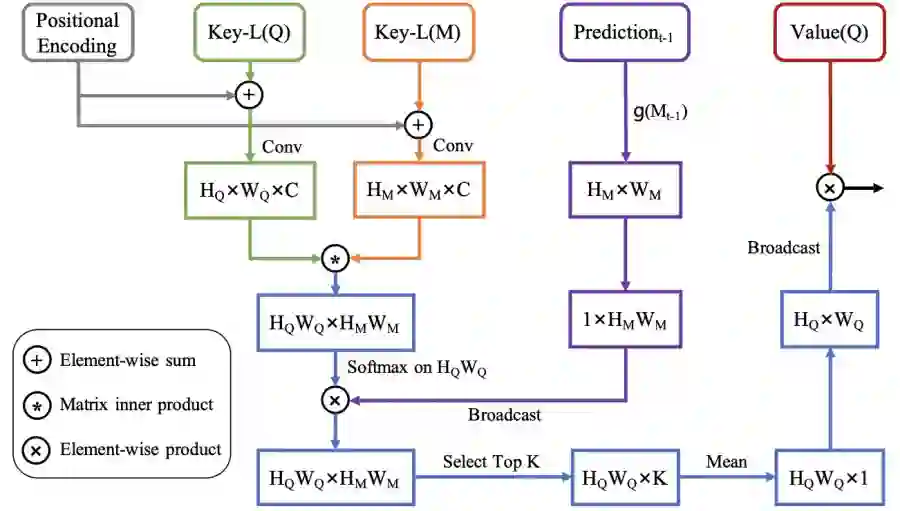
除了在全局时空域匹配所需要的 Key-G 外,该研究还额外计算了一个局部匹配所需要的 Key-L。考虑到物体的位置信息和相邻帧的位置有很强的相关性,该研究会在当前帧和上一帧的特征图中计算 Key-L。PGM 的计算框架如下图所示,其与 GRM 的匹配方式很类似,但有几个区别:
一、该研究不仅希望特征图的匹配和语义信息相关,而且希望能同时考虑位置信息,因此加入了 Transformer 中常用的位置编码作为位置信息的补充;
二、研究人员在匹配计算时,采取在 Query 图上做 Softmax,并希望用上一帧的信息学习当前帧的特征响应,这一点和 ECCV20 的 KMN 的做法有些类似,但目的不同;
三、该研究会利用上一帧的 mask 结果对特征匹配结果做约束,并取 TopK 的结果做计算,以消除背景区域的匹配影响。
![]()
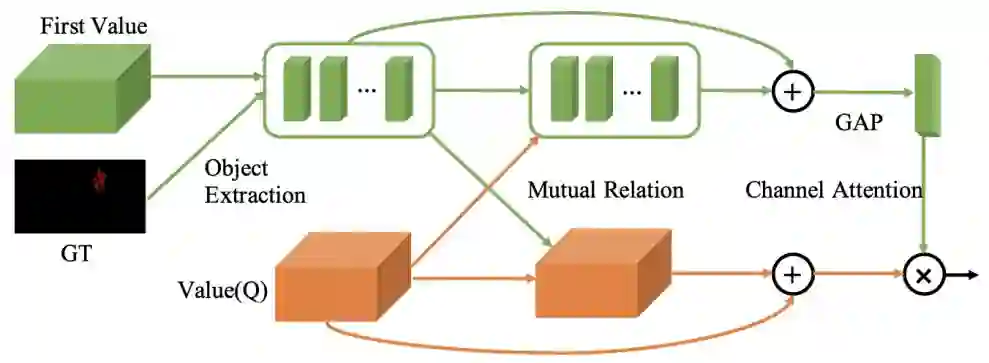
ORM 的目的在于将整个视频序列中保持所要跟踪物体的整体特征信息。在计算历史帧的特征时,该研究会把图像和其 mask 结果拼接在一起作为输入,因此所提取的深度特征会受到其对应 mask 的指导。而在提取当前帧的特征时,只有图像输入,其特征缺少针对性。在半监督视频目标监督中,第一帧的 Groundtruth 是给出的,可以利用它来作为物体级别信息的参照。这一点很像单目标跟踪中利用第一帧的物体来做相关匹配。ORM 的计算框架如下图所示,利用首帧的 GT 得到目标物体的特征区域,记作 F{fi},Query 图的特征记为 vQ(j),然后对这两个特征互相做一个 non-local 计算,并和之前的特征融合增强。首帧的特征还会通过类似 SENet 的通道注意力机制和当前帧的特征融合。
![]()
![]()
![]()
第一阶段,静态图预训练。这和 STM 中的预训练一致,即利用图像分割数据集做数据增强的方式构造出训练样本。
第二阶段,视频分割数据训练,不约束时序。在视频序列中采帧,打乱顺序作为训练样本。研究人员利用这一步骤来增强模型对各种相似区域特征的召回能力。
第三阶段,按时序顺序模拟训练。因为最终的模型推断是按时序逐帧计算的,这样的方法能减少训练和测试之间的差异。同时在这一阶段的样本构造会更加符合 PGM 对于位置信息的学习。
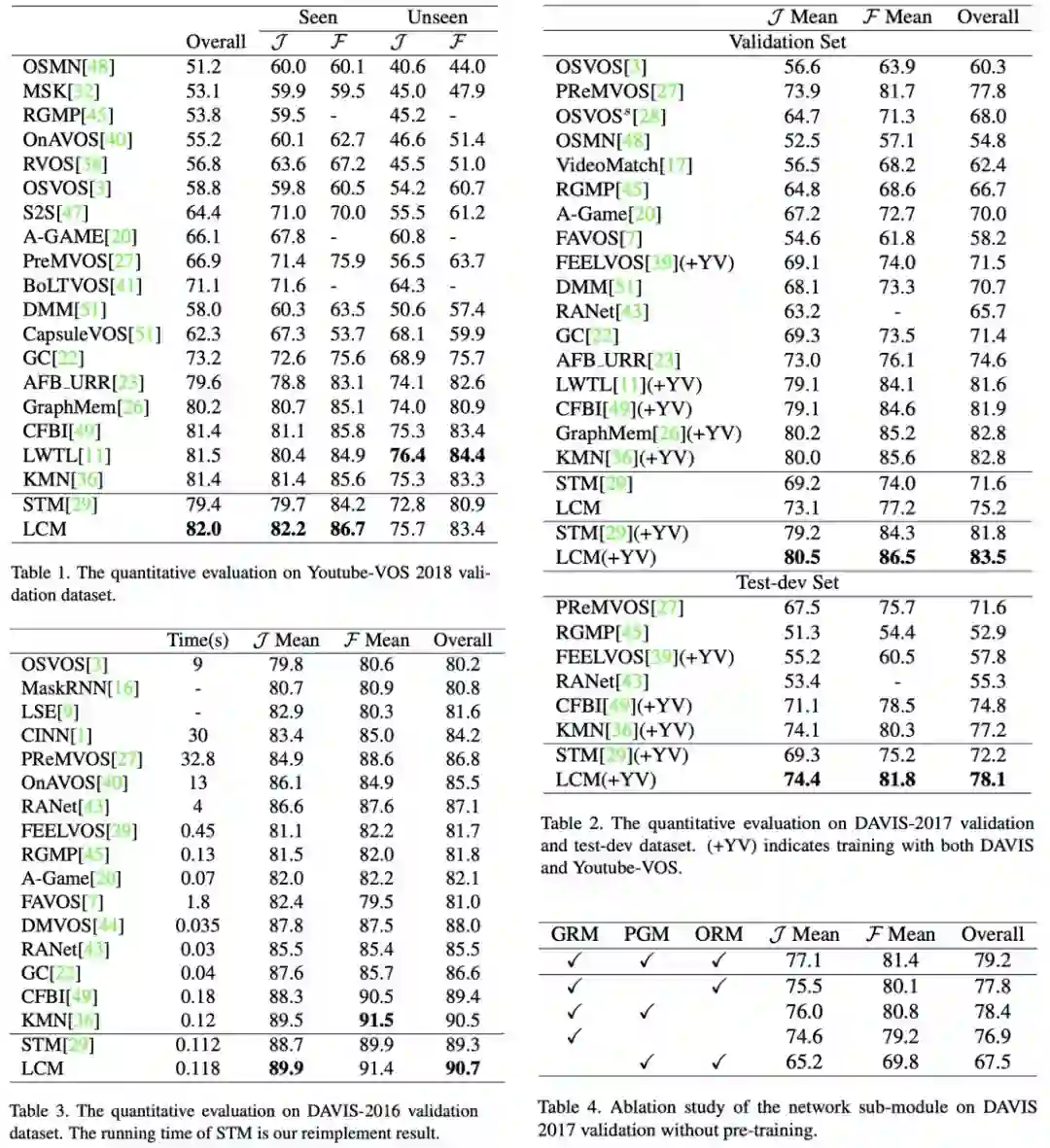
该研究在 YouTube-VOS 18、DAVIS 2017、DAVIS 2016 上都取得了 SOTA 的结果。消融实验也证明了所提出模块的作用。
![]()
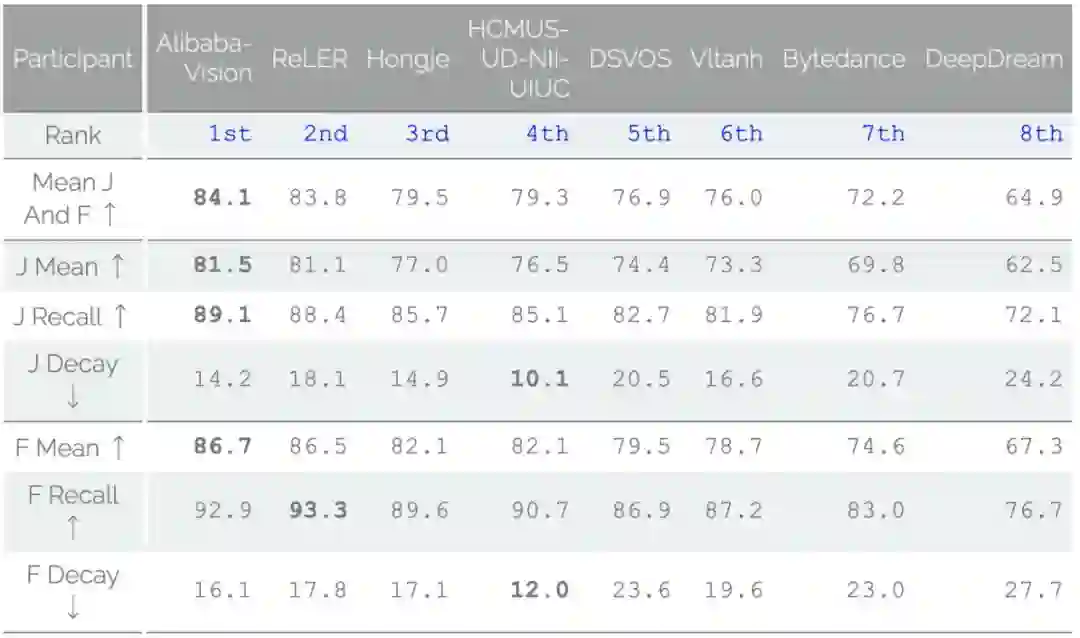
同时该研究在 DAVIS2020 竞赛的半监督视频目标分割中取得了第一名。
![]()
可视化的结果表明在一些复杂场景中 (尤其是存在相似物体) 有更好的效果。
![]()
AI青年说第二期:如何摘取 AI 皇冠上的 NLP 明珠
4月26日19:30-21:00,自然语言处理领域的两位专家——清华大学计算机系长聘副教授、博士生导师黄民烈和西湖大学终身副教授张岳,将分别带来《下一代对话系统》和《关于开放域对话挑战的思索》的主题分享,并且还会以「关于让机器说人话这件事」 展开圆桌讨论。
识别海报二维码或点击阅读原文,直达直播间。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com