VALSE2017系列之二: 边缘检测领域年度进展报告
本文经深度学习大讲堂授权转载。
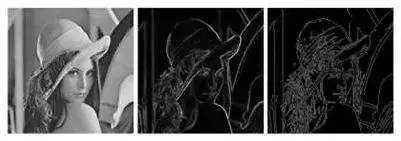
编者按:边缘检测是图像处理和计算机视觉中的基本问题,通过标识数字图像中亮度变化明显的点,来捕捉图像属性中的显著变化,包括深度上的不连续、表面方向的不连续、物质属性变化、和场景照明变化。南开大学的程明明副教授将带领大家回顾过去一年中,边缘检测领域在学术界的研究进展。文末提供报告中提到全部文章的下载地址以及程明明副教授组内工作的开源代码地址。

边缘检测在计算机视觉领域的很多应用中都有非常重要的作用。图像边缘检测能够大幅减少数据量,在保留重要的结构属性的同时,剔除弱相关信息。

在深度学习出现之前,传统的Sobel滤波器,Canny检测器具有广泛的应用,但是这些检测器只考虑到局部的急剧变化,特别是颜色、亮度等的急剧变化,通过这些特征来找边缘。

但这些特征很难模拟较为复杂的场景,如伯克利的分割数据集(Berkeley segmentation Dataset),仅通过亮度、颜色变化并不足以把边缘检测做好。2013年,开始有人使用数据驱动的方法来学习怎样联合颜色、亮度、梯度这些特征来做边缘检测。当然,还有些流行的方法,比如Pb, gPb,StrucutredEdge。为了更好地评测边缘检测算法,伯克利研究组建立了一个国际公认的评测集,叫做Berkeley Segmentation Benchmark。从图中的结果可以看出,即使可以学习颜色、亮度、梯度等low-level特征,但是在特殊场景下,仅凭这样的特征很难做到鲁棒的检测。比如上图的动物图像,我们需要用一些high-level 比如 object-level的信息才能够把中间的细节纹理去掉,使其更加符合人的认知过程(举个形象的例子,就好像画家在画这个物体的时候,更倾向于只画外面这些轮廓,而把里面的细节给忽略掉)。
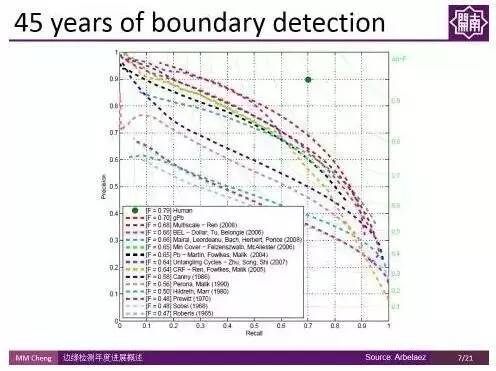
上图展示了过去45年间特别有代表性的工作在 Berkekey Segmentation Benchmark 上的PR(Precision-Recall)曲线。右上角绿色点是人类表现的均值,F-Measure值在0.8左右。

传统的基于特征的方法,最好的结果只有0.7,这很大程度上是因为传统的人工设计的特征并没有包含高层的物体级别信息,导致有很多的误检。因而研究者们尝试用卷积神经网络CNN,探索是否可以通过内嵌很多高层的、多尺度的信息来解决这一问题。

近几年,有很多基于CNN的方法的工作。这里从2014 ACCV N4_Fields开始说起。

N4-Fields:
如何从一张图片里面找边缘?我们会想到计算局部梯度的大小、纹理变化等这些直观的方法。其实N4-Fields这个方法也很直观,图像有很多的patch,用卷积神经网络(CNN)算出每个patch的特征,然后在字典里面进行检索,查找与其相似的边缘,把这些相似的边缘信息集成起来,就成了最终的结果,可以看到,由于特征更加强大了,结果有了较好的提升。
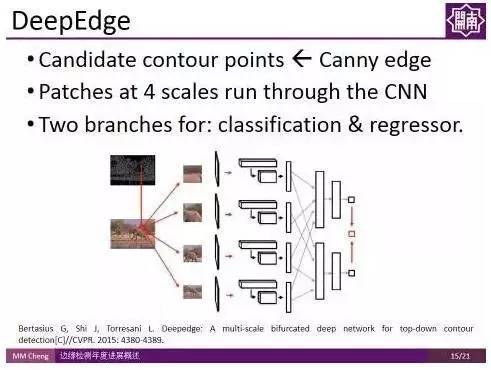
DeepEdge:
发表在CVPR 2015的DeepEdge对上述工作进行了扩展,首先使用Canny edge得到候选轮廓点,然后对这些点建立不同尺度的patch,将这些 patch 输入两路的CNN,一路用作分类,一路用作回归。最后得到每个候选轮廓点的概率。
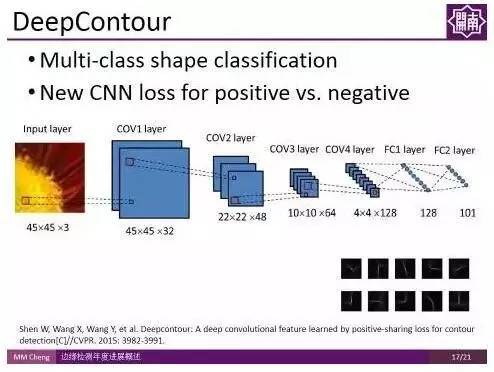
DeepContour:
这是CVPR2015中的另一个工作,该工作还是基于patch的。首先在图像中寻找patch,然后对patch 做多类形状分类,来判断这个边缘是属于哪一类的边缘,最后把不同类别的边缘融合起来得到最终的结果。
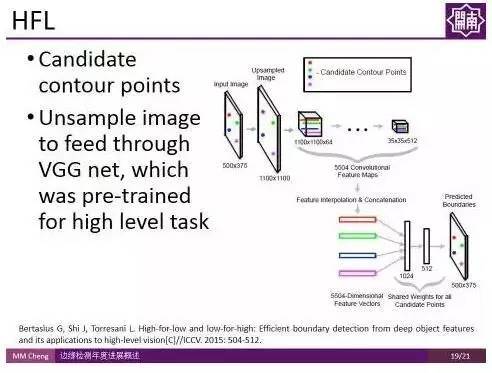
HFL:
ICCV 2015的工作High-for-Low (HFL)也用CNN对可能的候选轮廓点进行判断。由于使用了经过高层语义信息训练得到的VGG Net,在一定程度上用到了高层语义信息,因此取得了不错的结果。
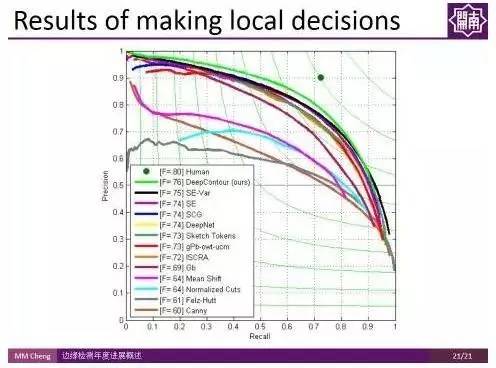
由上图结果可以看出,这些工作虽然取得了一些进展,但是离人类的表现还有很大的差距。 这些方法的缺点在于都是基于局部策略所做的结果,每次只看一个区域,即只针对一个patch,并没有很充分的利用高层级的信息。

Holistically-Nested Edge Detection:
Holistically-Nested Edge Detection 是屠卓文教授课题组在ICCV 2015 的工作。该工作最大的亮点在于,一改之前边缘检测方法基于局部策略的方式,而是采用全局的图像到图像的处理方式。即不再针对一个个patch进行操作,而是对整幅图像进行操作,为高层级信息的获取提供了便利。
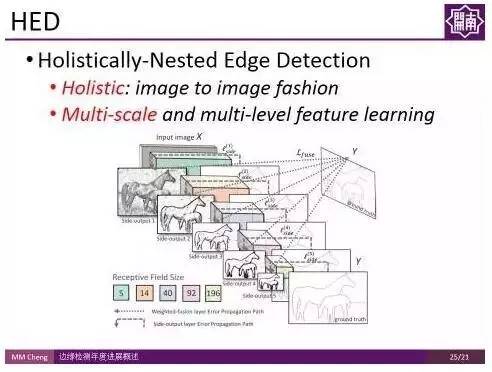
与此同时,该方法使用了multi-scale 和multi-level, 通过groundtruth的映射在卷积层侧边插入一个side output layer,在side output layer上进行deep supervision,将最终的结果和不同的层连接起来。

如图所示,加上deep supervision后,该方法可以在不同尺度得到对应抽象程度的边缘。
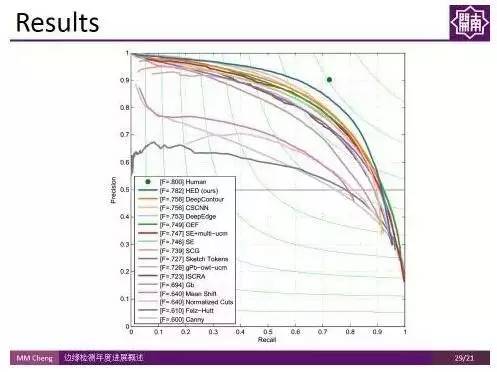
可以看到该方法在伯克利分割Benchmark上的结果较之前有了很大的提升。

RCF:
接下来,介绍的是程明明副教授课题组CVPR2017的工作。其实想法很简单,一句话就能概括,由于不同卷积层之间的信息是可以互补的,传统方法的问题在于信息利用不充分,相当于只使用了Pooling前最后一个卷积层的信息,如果我们使用所有卷积层的信息是不是能够更好的利用卷积特征,进而得到更好的结果?
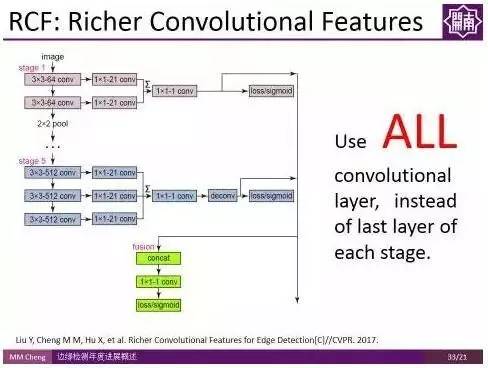
使用所有卷积层的信息,而不是池化之前的最后一层,这样一个非常简单的改变,使得检测结果有了很大的改善。这种方法也有望迁移到其他领域。
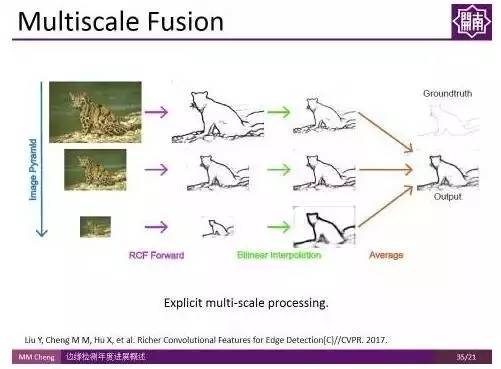
实验结果表明,虽然卷积神经网络自带多尺度特征,但显式地使用多尺度融合对边缘检测结果的提升依然有效。

这是部分示例结果。
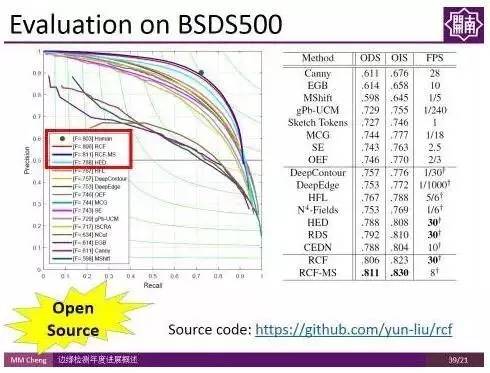
该方法操作简单,且不明显增加计算时间,虽然代码量少,但在BSDS500数据集上的结果甚至超过人类标注者的平均表现水平,而且在Titan X上能够达到实时检测速度(30fps)。且,这部分代码是开源的,可通过访问如下网址获得: https://github.com/yun-liu/rcf。

最后,大讲堂喜大普奔地告知各位小伙伴:程明明副教授组内几乎所有工作均开源,可通过扫描上图二维码来获得。
文中提到所有文章的下载链接为:
http://pan.baidu.com/s/1jHLdyIU
致谢:
本文主编袁基睿,诚挚感谢志愿者范琦、贺娇瑜、李珊如对本文进行了细致的整理工作。
作者简介:


程明明,南开大学副教授,博导,中科协青年人才托举工程、天津市青年千人、南开大学百名青年学科带头人计划入选者。2012年博士毕业于清华大学,之后在英国牛津从事计算机视觉研究,并于2014年加入南开大学。其主要研究方向包括:计算机图形学、计算机视觉、图像处理等。已在IEEE PAMI等CCF-A类国际会议及期刊发表论文20余篇。相关研究成果受到国内外同行的广泛认可,论文他引5000余次,最高单篇他引1700余次。其研究工作曾被英国《BBC》,《每日电讯报》,德国《明镜周刊》,美国《赫芬顿邮报》等权威国际媒体撰文报道。


欢迎大家关注我们!
VALSE(Vision and Learning Seminar) 年度研讨会的主要目的是为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。

VALSE

点击阅读原文查阅VALSE主页



