VALSE2017系列之三:人体姿态识别领域年度进展报告
本文经深度学习大讲堂授权转载。
编者按:基于RGB图像的人体姿态识别,在行为识别、人机交互、游戏、动画等领域有着很广阔的应用前景,是计算机视觉领域中一个既具有研究价值、同时又极具挑战性的热门课题。来自香港中文大学的欧阳万里教授将带着大家回顾过去一年中,人体姿态识别领域在学术界的研究进展。大讲堂特别在文末提供人体姿态识别领域最新文章的下载地址、以及欧阳教授组内工作的开源代码。

欧阳万里教授研究组的主页为:
http://www.ee.cuhk.edu.hk/~wlouyang/

什么是人体姿态识别?
给定一幅图像或一段视频,人体姿态识别就是去恢复其中人体关节点位置的过程。根据输入图像的类型,人体姿态识别算法可以分为两类:基于深度图的算法、以及直接基于RGB图像的算法。相较于深度图对图像采集设备要求过高而带来的应用易受限的问题,基于RGB图像的人体姿态估计算法具有更广的应用前景,并且在学术上也取得了很好的成果。目前,即便是针对比较复杂的场景下,基于RGB图像的人体姿态估计算法也能达到很好的识别效果。

人体姿态识别有很多应用:比如行为识别、人机交互、游戏、动画以及衣服的识别等等。
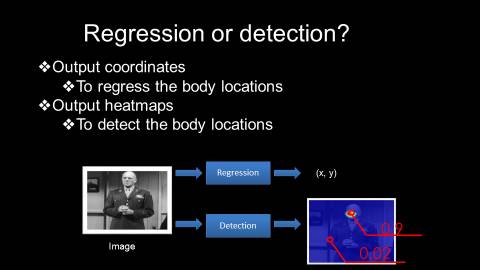
人体姿态识别回归or检测?
对于人体姿态识别问题,我们既可将其看作回归问题,亦可以将其看作检测问题。这两者的区别在于,对于前者而言,我们期望得到的是精确的坐标值(x, y);而对于后者而言,我们期望得到对应的热点图谱,用这个热点图谱的响应值来反映人体的不同部位,也就是说,不同部位获得的响应应该是不同的,对于感兴趣的区域(例如头部),需要返回一个较高的响应,而其它部位则响应相对较低。

采用回归的方式来解决人体姿态识别问题,效果并不理想。其主要原因有两方面:一方面是人体运动比较灵活,另一方面,回归模型的可扩展性较差,比较难于扩展到不定量的人体姿态识别问题中。因此,目前大家普遍使用的过渡处理方法是将其看作检测问题,从而获得一张热点图谱。

人体姿态识别挑战
在实际应用中,人体姿态识别也面临着几大问题,主要表现在三方面:1. 人体的肢体运动比较灵活 2. 视角的变化 3. 衣着的变化。这三方面导致人体各个部位的视觉信息变化较大,从而为人体姿态识别技术带来了极大的挑战。

人体姿态识别局部视觉信息
以上图标出的两个区域为例,如果不看全图的效果,仅根据局部的视觉信息,人眼是几乎无法识别出它们分别属于身体哪些部位的;而加上全图上下文信息之后,识别起来就容易得多。从这个例子我们可以看出,仅局部信息在人体姿态识别中是不够的,我们需要利用全局信息来为人体姿态识别提供辅助。

出于这种考虑,同时在深度学习与大数据引爆学术界的大背景下,如何针对人体姿态估计问题设计出专用网络结构成为了一个新兴研究方向。例如,来自密歇根大学的研究团队设计的Stacked hourglass network就是一种专门用于人体识别问题的网络结构。如图所示,这是一种沙漏型的网络结构,首先进行卷积处理,并进行下采样操作,获得一些分辨率较低的特征,从而使计算复杂度降低。为了使图像特征的分辨率上升,紧接着进行上采样。上采样操作使得图像的分辨率增高,同时更有能力预测物体的准确位置。通过这样一种处理,相较于其他网络,该网络结构能够使同一个神经元感知更多的上下文信息。
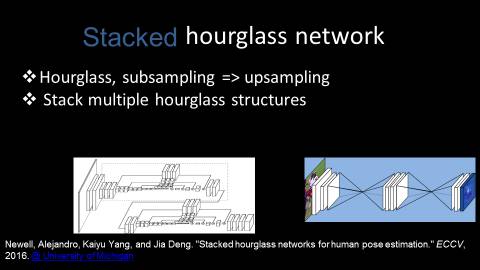
这种沙漏结构还具备可堆叠性,通过多个沙漏结构的堆叠,来组成新的更具表示能力的沙漏型结构。
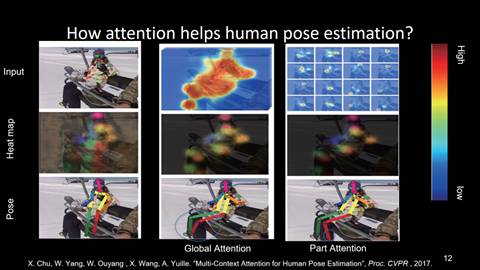
注意力机制
基于已有的网络结构,输入一张图片,获得一张热点图谱。通过热点图谱,我们得到一个预测结果。但是,在这个预测结果中,相对于这张图片,对人体膝盖或者脚踝的预测是错误的。这个时候我们可以引入注意力机制--注意力机制,是通过网络隐式学到的模型,会把我们的注意力集中在人体相关的红色区域。通过对这些相关区域进行人体姿态运动的预测识别,可以获得膝盖、腿和脚踝部位相对更准确的预测结果。同时,注意力机制不仅可以应用于整张图像或整个人体,也可以应用到人体的各个部位。通过对人体的各个部位设计不同的注意力机制特性,来得到更好的人体姿态预测结果。比如示例中,通过引入部位注意力机制,我们得到了更准确的人体脚踝位置的预测结果。
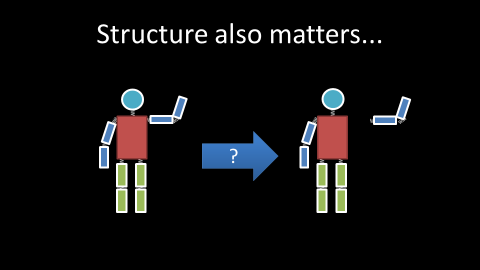
人体结构化信息
同时在人体姿态估计过程中,还可以结合人体的结构化信息,这些结构化信息来自于我们的骨骼。比如人的头、手不能离身体太远,不然的话,真不知道会发生什么样的事情。

利用这种结构化信息,我们可以在深度学习的学习过程中,既学习特征,也学习结构化信息。
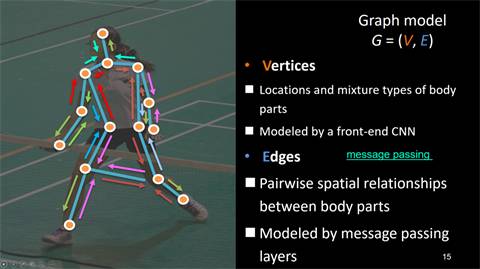
在结构信息学习中,人体各个关节部位可看作节点,并基于人体各部位的空间关系建立边,并在这些边中进行信息传递。
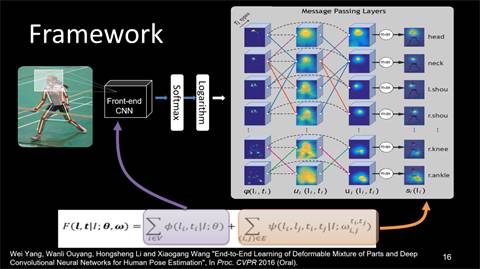
在具体实践中,将一张图片输入到一个已存在的卷积网络中得到特征,进而获得人体各个部位的局部热点图谱,然后,在热点图谱中使用自己设计的多个信息传递层,使得信息在各信息层之间传递,在各个不同的身体部位之间传递,从而得到更好的预测结果。
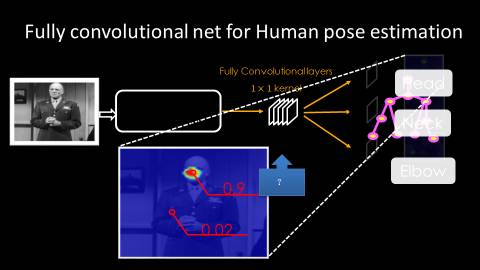
前文所述的信息传递是指,在结果输出的热点图谱之间进行信息传递。那么,是否可以在特征层级进行信息传递呢?答案是肯定的。至于为什么要在特征层级进行信息传递呢?原因是特征层级提供了一些输出结果所没有提供的更丰富的视觉信息。
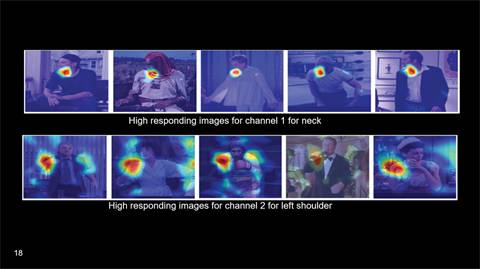
比如,我们在实验中发现,有一个神经元会对头偏向左侧这一特征有一个高的响应。而另外一个神经元可能会对于手遮住肩膀这样一个视觉信息有一个高的响应。虽然标签或者输出中并没有提供这些视觉信息,然而通过算法学习得到的特征却可以提供这些信息。
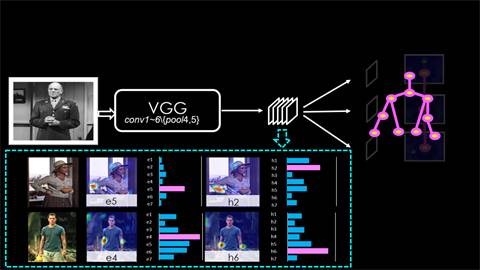
正是因为特征层级拥有更丰富的视觉信息,而现有实验结果表明这些视觉信息其实也是具备相关性的。比如:人的手肘和手臂会有一些相容或互斥的关系。所以,当它们本身存在这种内在的关系时,我们就可以考虑根据这种内在关系,在它们之间进行建模。
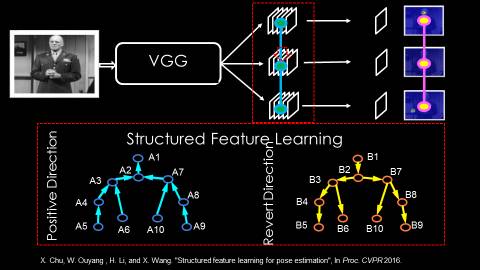
因此,我们可以为身体的各个部位定义它自己所特有的特征。有了各部位特有的特征以后,信息就可以在这些特有的特征之间进行信息传递。我们可以把手的特征传递到头部,也可以把头部的特征传递到手臂,从而实现一个结构化的信息传递。而这种特征层级之间的信息传递,使得特征得到更好的预测,进而更好地预测最终结果。
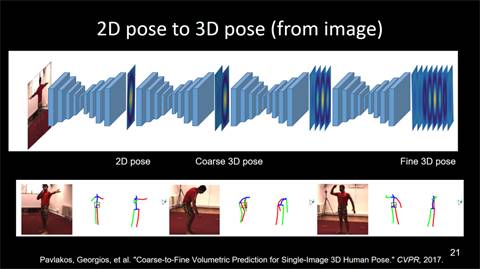
图像获取2D/3D信息
前文所讲,都是基于2D图片获得姿态预测结果,即我们得到的只是在图片中人体的2D位置的坐标(x,y)。然而,人是在3D世界中的真实存在,我们其实还可以获取另外一个维度的信息,即深度信息。现有研究结果表明,只从一个简单的RGB图像是可以获得图像的3D信息的。其方法如下:首先获得2D位置预测,通过堆叠沙漏型的网络结构,得到一个3D位置的初步、粗略的预测信息,再进一步堆叠网络结构进行精细化的处理,最终会得到一个非常精细的3D信息预测结果。
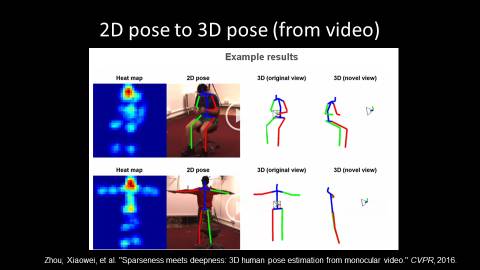
视频中获取2D/3D信息
前文所讲的都是对于图片的,其实这种工作也可以扩展到视频中。

从视频来做三维姿态估计,应用到的很重要的点是,相邻帧之间的视觉信息应该是连续的,因而人的姿态在相邻帧之间的变化也会是连续的,因而可以利用这些信息的连贯性,来改进人体在3D或者2D中姿态识别的预测结果。

最后,大讲堂喜大普奔地告知各位小伙伴:欧阳万里教授组内关于人体姿态识别的代码开源,下载地址为:
http://www.ee.cuhk.edu.hk/~xgwang/projectpage_structured_feature_pose.html
文中提到所有文章的下载链接为:
http://pan.baidu.com/s/1qYweZPM

致谢:
本文主编袁基睿,诚挚感谢志愿者高春乐 、朱婷 、李珊如对本文进行了细致的整理工作。
作者简介:


欧阳万里,香港中文大学研究助理教授,毕业于香港中文大学,研究领域涉及深度学习以及其在计算机视觉、模式识别、视频图像处理中的应用。在CVPR、TPAMI等顶级会议及期刊上发表高水平论文数十篇。

欢迎大家关注我们!
VALSE(Vision and Learning Seminar) 年度研讨会的主要目的是为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。

VALSE

点击阅读原文查阅VALSE主页

