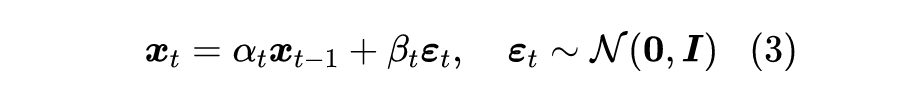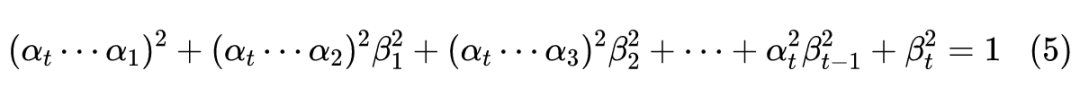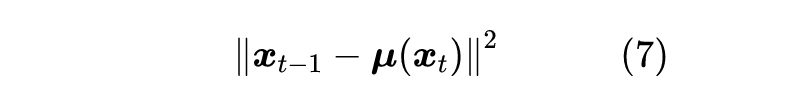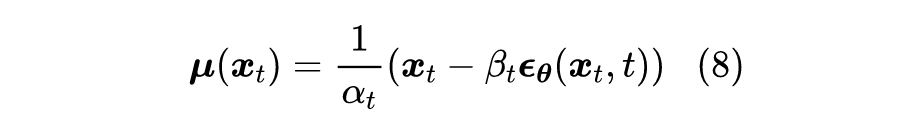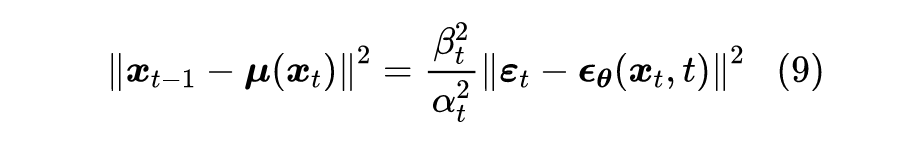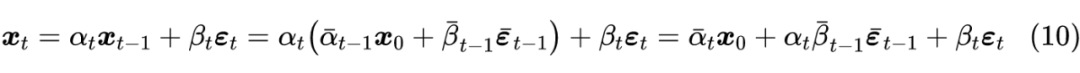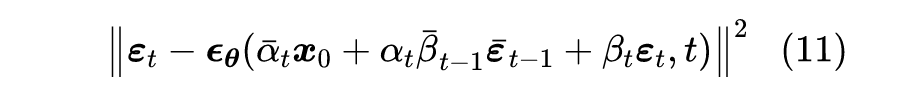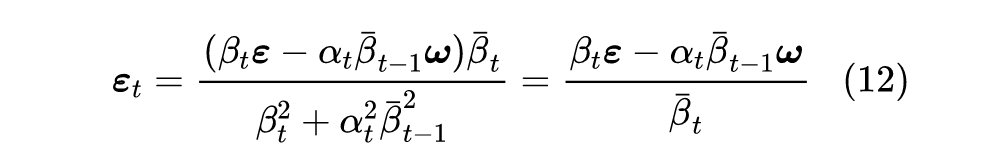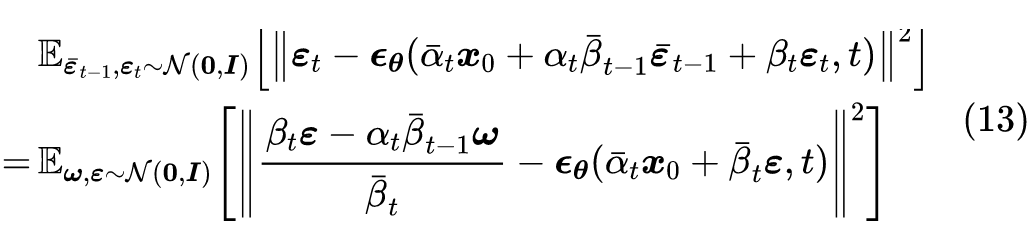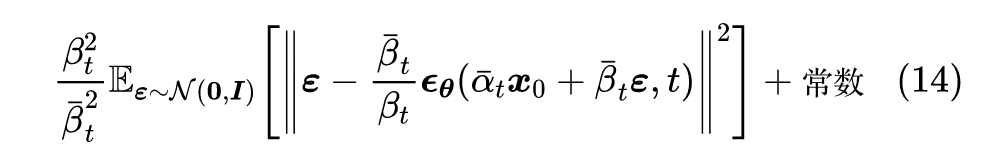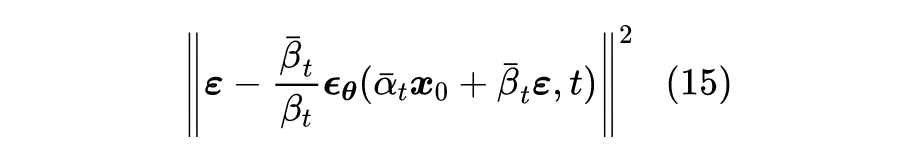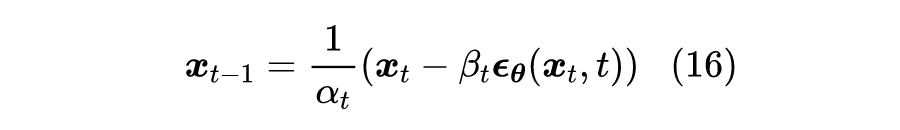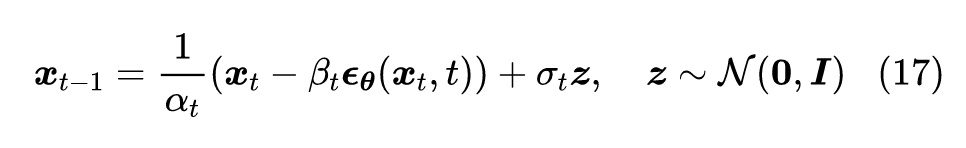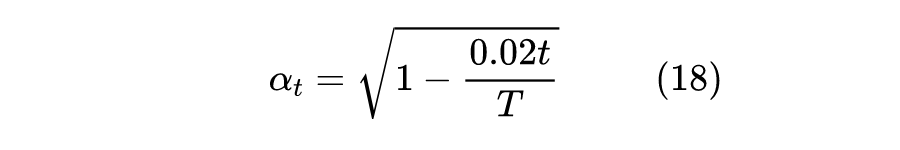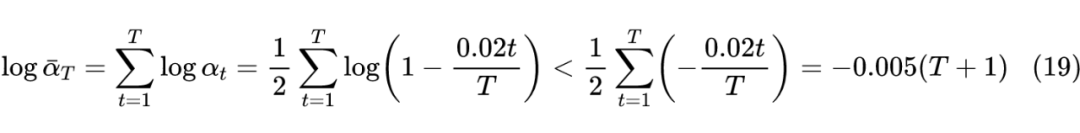![]()
©PaperWeekly 原创 · 作者 |
苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
说到生成模型,VAE、GAN 可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如 flow 模型
[1]
、VQ-VAE
[2]
等,也颇有人气,尤其是 VQ-VAE 及其变体 VQ-GAN
[3]
,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用 NLP 的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI 的 DALL·E 2
[4]
和 Google 的 Imagen
[5]
,都是基于扩散模型来完成的。
▲ Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比 VAE、GAN 要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
其实我们在之前的文章《能量视角下的 GAN 模型(三):生成模型=能量模型》[6]、《从去噪自编码器到生成模型》也简单介绍过扩散模型。说到扩散模型,一般的文章都会提到能量模型(Energy-based Models)、得分匹配(Score Matching)、朗之万方程(Langevin Equation)等等,简单来说,是通过得分匹配等技术来训练能量模型,然后通过郎之万方程来执行从能量模型的采样。
从理论上来讲,这是一套很成熟的方案,原则上可以实现任何连续型对象(语音、图像等)的生成和采样。但从实践角度来看,能量函数的训练是一件很艰难的事情,尤其是数据维度比较大(比如高分辨率图像)时,很难训练出完备能量函数来;另一方面,通过朗之万方程从能量模型的采样也有很大的不确定性,得到的往往是带有噪声的采样结果。所以很长时间以来,这种传统路径的扩散模型只是在比较低分辨率的图像上做实验。
如今生成扩散模型的大火,则是始于 2020 年所提出的 DDPM [7](Denoising Diffusion Probabilistic Model),虽然也用了“扩散模型”这个名字,但事实上除了采样过程的形式有一定的相似之外,DDPM 与传统基于朗之万方程采样的扩散模型可以说完全不一样,这完全是一个新的起点、新的篇章。
准确来说,DDPM 叫“渐变模型”更为准确一些,扩散模型这一名字反而容易造成理解上的误解,传统扩散模型的能量模型、得分匹配、朗之万方程等概念,其实跟 DDPM 及其后续变体都没什么关系。有意思的是,DDPM 的数学框架其实在 ICML 2015的论文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》
[8]
就已经完成了,但 DDPM 是首次将它在高分辨率图像生成上调试出来了,从而引导出了后面的火热。由此可见,一个模型的诞生和流行,往往还需要时间和机遇.
很多文章在介绍 DDPM 时,上来就引入转移分布,接着就是变分推断,一堆数学记号下来,先吓跑了一群人(当然,从这种介绍我们可以再次看出,DDPM 实际上是 VAE 而不是扩散模型),再加之人们对传统扩散模型的固有印象,所以就形成了“需要很高深的数学知识”的错觉。事实上,DDPM 也可以有一种很“大白话”的理解,它并不比有着“造假-鉴别”通俗类比的 GAN 更难。
首先,我们想要做一个像 GAN 那样的生成模型,它实际上是将一个随机噪声
变换成一个数据样本
的过程:
![]()
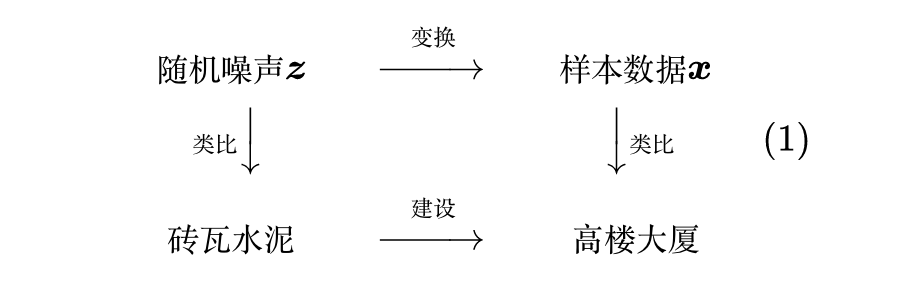
我们可以将这个过程想象为“建设”,其中随机噪声
是砖瓦水泥等原材料,样本数据
是高楼大厦,所以生成模型就是一支用原材料建设高楼大厦的施工队。
![]()
这个过程肯定很难的,所以才有了那么多关于生成模型的研究。但俗话说“破坏容易建设难”,建楼你不会,拆楼你总会了吧?我们考虑将高楼大厦一步步地拆为砖瓦水泥的过程:设
为建好的高楼大厦(数据样本),
为拆好的砖瓦水泥(随机噪声),假设“拆楼”需要
步,整个过程可以表示为
![]()
建高楼大厦的难度在于,从原材料
到最终高楼大厦
的跨度过大,普通人很难理解
是怎么一下子变成
中的。但是,当我们有了“拆楼”的中间过程
后,我们知道
代表着拆楼的一步,那么反过来
不就是建楼的一步?如果我们能学会两者之间的变换关系
,那么从
出发,反复地执行
、
、...,最终不就能造出高楼大厦
出来?
正所谓“饭要一口一口地吃”,楼也要一步一步地建,DDPM 做生成模型的过程,其实跟上述“拆楼-建楼”的类比是完全一致的,它也是先反过来构建一个从数据样本渐变到随机噪声的过程,然后再考虑其逆变换,通过反复执行逆变换来完成数据样本的生成,所以本文前面才说 DDPM 这种做法其实应该更准确地称为“渐变模型”而不是“扩散模型”。
![]()
其中有
且
,
通常很接近于 0,代表着单步“拆楼”中对原来楼体的破坏程度,噪声
的引入代表着对原始信号的一种破坏,我们也可以将它理解为“原材料”,即每一步“拆楼”中我们都将
拆解为“
的楼体 +
的原料”。(提示:本文
的定义跟原论文不一样。)
![]()
可能刚才读者就想问为什么叠加的系数要满足
了,现在我们就可以回答这个问题。首先,式中花括号所指出的部分,正好是多个独立的正态噪声之和,其均值为 0,方差则分别为
、
、...、
、
;
然后,我们利用一个概率论的知识——正态分布的叠加性,即上述多个独立的正态噪声之和的分布,实际上是均值为 0、方差为
的正态分布;最后,
在
恒成立之下,我们可以得到式(4)的各项系数平方和依旧为 1,即:
![]()
![]()
这就为计算
提供了极大的便利。另一方面,DDPM 会选择适当的
形式,使得有
,这意味着经过
步的拆楼后,所剩的楼体几乎可以忽略了,已经全部转化为原材料
。(提示:本文
的定义跟原论文不一样。)
“拆楼”是
的过程,这个过程我们得到很多的数据对
,那么“建楼”自然就是从这些数据对中学习一个
的模型。设该模型为
,那么容易想到学习方案就是最小化两者的欧氏距离:
![]()
其实这已经非常接近最终的 DDPM 模型了,接下来让我们将这个过程做得更精细一些。首先“拆楼”的式(3)可以改写为
,这启发我们或许可以将“建楼”模型
设计成:
![]()
的形式,其中
是训练参数,将其代入到损失函数,得到:
![]()
前面的因子
代表 loss 的权重,这个我们可以暂时忽略,最后代入结合式(6)和(3)所给出
的表达式:
![]()
![]()
可能读者想问为什么要回退一步来给出
,直接根据式(6)来给出
可以吗?答案是不行,因为我们已经事先采样了
,而
跟
不是相互独立的,所以给定
的情况下,我们不能完全独立地采样
。
原则上来说,损失函数(11)就可以完成 DDPM 的训练,但它在实践中可能有方差过大的风险,从而导致收敛过慢等问题。要理解这一点并不困难,只需要观察到式(11)实际上包含了 4 个需要采样的随机变量:
2. 从正态分布
,
中采样
,
(两个不同的采样结果);
要采样的随机变量越多,就越难对损失函数做准确的估计,反过来说就是每次对损失函数进行估计的波动(方差)过大了。很幸运的是,我们可以通过一个积分技巧来将
合并成单个正态随机变量,从而缓解一下方差大的问题。
这个积分确实有点技巧性,但也不算复杂。由于正态分布的叠加性,我们知道
实际上相当于单个随机变量
,同理
实际上相当于单个随机变量
,并且可以验证
,所以这是两个相互独立的正态随机变量。
![]()
![]()
注意到,现在损失函数关于
只是二次的,所以我们可以展开然后将它的期望直接算出来,结果是:
![]()
再次省掉常数和损失函数的权重,我们得到 DDPM 最终所用的损失函数:
![]()
(提示:原论文中的
实际上就是本文的
,所以大家的结果是完全一样的。)
至此,我们算是把 DDPM 的整个训练流程捋清楚了。内容写了不少,你要说它很容易,那肯定说不上,但真要说非常困难的地方也几乎没有——没有用到传统的能量函数、得分匹配等工具,甚至连变分推断的知识都没有用到,只是借助“拆楼-建楼”的类比和一些基本的概率论知识,就能得到完全一样的结果。所以说,以 DDPM 为代表的新兴起的生成扩散模型,实际上没有很多读者想象的复杂,它可以说是我们从“拆解-重组”的过程中学习新知识的形象建模。
训练完之后,我们就可以从一个随机噪声
出发执行
步式(8)来进行生成:
![]()
这对应于自回归解码中的 Greedy Search。如果要进行 Random Sample,那么需要补上噪声项:
![]()
一般来说,我们可以让
,即正向和反向的方差保持同步。这个采样过程跟传统扩散模型的朗之万采样不一样的地方在于:DDPM 的采样每次都从一个随机噪声出发,需要重复迭代
步来得到一个样本输出;朗之万采样则是从任意一个点出发,反复迭代无限步,理论上这个迭代无限步的过程中,就把所有数据样本都被生成过了。所以两者除了形式相似外,实质上是两个截然不同的模型。
从这个生成过程中,我们也可以感觉到它其实跟 Seq2Seq 的解码过程是一样的,都是串联式的自回归生成,所以生成速度是一个瓶颈,DDPM 设了
,意味着每生成一个图片,需要将
反复执行 1000 次,因此 DDPM 的一大缺点就是采样速度慢,后面有很多工作都致力于提升 DDPM 的采样速度。
而说到“图片生成+自回归模型+很慢”,有些读者可能会联想到早期的 PixelRNN
[9]
、PixelCNN
[10]
等模型,它们将图片生成转换成语言模型任务,所以同样也是递归地进行采样生成以及同样地慢。那么DDPM的这种自回归生成,跟 PixelRNN/PixelCNN 的自回归生成,又有什么实质区别呢?为什么 PixelRNN/PixelCNN 没大火起来,反而轮到了 DDPM?
了解 PixelRNN/PixelCNN 的读者都知道,这类生成模型是逐个像素逐个像素地生成图片的,而自回归生成是有序的,这就意味着我们要提前给图片的每个像素排好顺序,最终的生成效果跟这个顺序紧密相关。然而,目前这个顺序只能是人为地凭着经验来设计(这类经验的设计都统称为“Inductive Bias”),暂时找不到理论最优解。
换句话说,PixelRNN/PixelCNN 的生成效果很受 Inductive Bias 的影响。但 DDPM 不一样,它通过“拆楼”的方式重新定义了一个自回归方向,而对于所有的像素来说则都是平权的、无偏的,所以减少了 Inductive Bias 的影响,从而提升了效果。此外,DDPM 生成的迭代步数是固定的
,而 PixelRNN/PixelCNN 则是等于图像分辨率(
),所以 DDPM 生成高分辨率图像的速度要比 PixelRNN/PixelCNN 快得多。
这一节我们讨论一下超参的设置问题。
在 DDPM 中,
,可能比很多读者的想象数值要大,那为什么要设置这么大的
呢?另一边,对于
的选择,将原论文的设置翻译到本博客的记号上,大致上是:
![]()
这是一个单调递减的函数,那为什么要选择单调递减的
呢?
其实这两个问题有着相近的答案,跟具体的数据背景有关。简单起见,在重构的时候我们用了欧氏距离(7)作为损失函数,而一般我们用 DDPM 做图片生成,以往做过图片生成的读者都知道,欧氏距离并不是图片真实程度的一个好的度量,VAE 用欧氏距离来重构时,往往会得到模糊的结果,除非是输入输出的两张图片非常接近,用欧氏距离才能得到比较清晰的结果,所以选择尽可能大的
,正是为了使得输入输出尽可能相近,减少欧氏距离带来的模糊问题。
选择单调递减的
也有类似考虑。当
比较小时,
还比较接近真实图片,所以我们要缩小
的差距,以便更适用欧氏距离 (7),因此要用较大的
;当
比较大时,
已经比较接近纯噪声了,噪声用欧式距离无妨,所以可以稍微增大
的差距,即可以用较小的
。那么可不可以一直用较大的
呢?可以是可以,但是要增大
。注意在推导(6)时,我们说过应该有
,而我们可以直接估算:
![]()
代入
大致是
,这个其实就刚好达到
的标准。所以如果从头到尾都用较大的
,那么必然要更大的
才能使得
了。
最后我们留意到,“建楼”模型中的
中,我们在输入中显式地写出了
,这是因为原则上不同的
处理的是不同层次的对象,所以应该用不同的重构模型,即应该有
个不同的重构模型才对,于是我们共享了所有重构模型的参数,将
作为条件传入。按照论文附录的说法,
是转换成《Transformer升级之路:Sinusoidal位置编码追根溯源》介绍的位置编码后,直接加到残差模块上去的。
本文从“拆楼-建楼”的通俗类比中介绍了最新的生成扩散模型 DDPM,在这个视角中,我们可以通过较为“大白话”的描述以及比较少的数学推导,来得到跟原始论文一模一样的结果。总的来说,本文说明了 DDPM 也可以像 GAN 一样找到一个形象类比,它既可以不用到 VAE 中的“变分”,也可以不用到 GAN 中的“概率散度”、“最优传输”,从这个意义上来看,DDPM 甚至算得上比 VAE、GAN 还要简单。
[1] https://kexue.fm/tag/flow/
[2] https://kexue.fm/archives/6760
[3] https://arxiv.org/abs/2012.09841
[4] https://arxiv.org/abs/2204.06125
[5] https://arxiv.org/abs/2205.11487
[6] https://kexue.fm/archives/6612
[7] https://arxiv.org/abs/2006.11239
[8] https://arxiv.org/abs/1503.03585
[9] https://arxiv.org/abs/1601.06759
[10] https://arxiv.org/abs/1606.05328
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()