深度学习面试100题(第51-55题)

点击蓝字关注我们,小七等你好久喽
解析:
方法:我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个神经网络中初始化权重值,看哪一个具有最好的训练性能。
假设:我们期望 Xavier 损失具有最好的性能(它是 tensorflow 中使用的默认值),而其他方法性能不佳(尤其是不断的初始化)。
运行实验所需的时间: 34.137 s
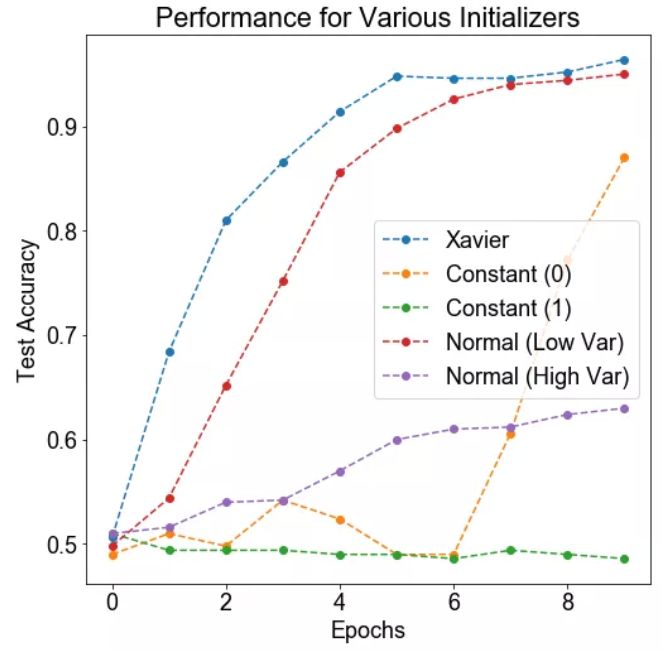
结论:Xavier 和高斯(具有较低的方差)初始化会得到很好的训练。有趣的是,常数 0 的初始化最终导致训练,而其他初始化并不会。
讨论:Xavire 初始化提供了最好的性能,这并不奇怪。标准偏差小的高斯也适用(但不像 Xavire 那样好)。如果方差变得太大,那么训练速度就会变得较慢,这可能是因为神经网络的大部分输出都发生了爆炸。
52、不同层的权重是否以不同的速度收敛?
解析:
我们的第一个问题是,不同层的权重是否以不同的速度收敛。
方法: 我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个数据集上训练一个带有 3 个隐藏层(将导致 4 层权重,包括从输入到)第一层的权重)的神经网络,我们在训练过程中绘制每层 50 个权重值。我们通过绘制两个轮数之间的权重的差分来衡量收敛性。
假设: 我们期望后一层的权重会更快地收敛,因为它们在整个网络中进行反向传播时,后期阶段的变化会被放大。
运行实验所需的时间: 3.924 s
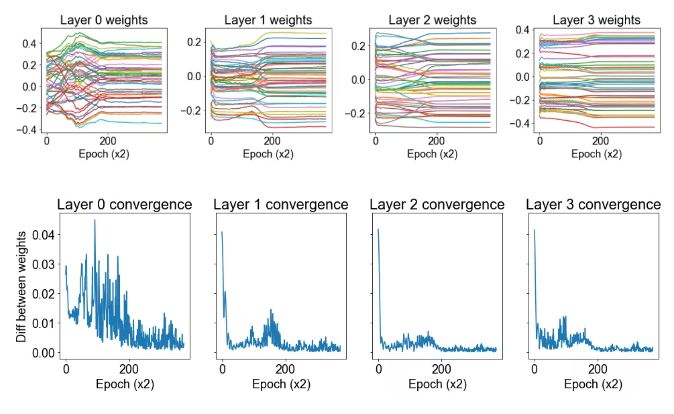
结论: 我们发现后一层的权重比前一层收敛得更快。
讨论: 看上去第三层的权重是几乎单调地收敛到它们的最终值,而且这一过程非常快。至于前几层权重的收敛模式,比较复杂,似乎需要更长的时间才能解决。
53、正则化如何影响权重?
解析:
方法:我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个数据集上训练一个具有 2 个隐藏层的神经网络,并在整个训练过程中绘制 50 个权重值。
然后我们在损失函数中包含 L1 或 L2 正则项之后重复这一过程。我们研究这样是否会影响权重的收敛。我们还绘制了正确率的图像,并确定它在正则化的情况下是否发生了显著的变化。
假设:我们预计在正则化的情况下,权重的大小会降低。在 L1 正则化的情况下,我们可能会得到稀疏的权重。如果正则化强度很高,我们就会预计正确率下降,但是正确率实际上可能会随轻度正则化而上升。
运行实验所需的时间: 17.761 s
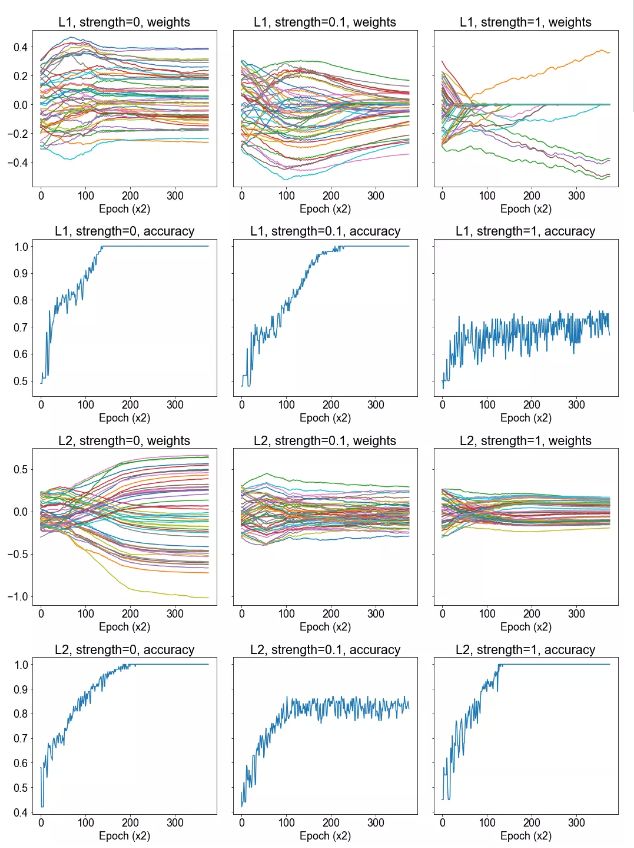
结论:我们注意到正则化确实降低了权重的大小,在强 L1 正则化的情况下导致了稀疏性。对正确率带来什么样的影响尚未清楚。
讨论:从我们所选的 50 个权重的样本可以清晰地看出,正则化对训练过程中习得的权重有着显著的影响。我们在 L1 正则化的情况下能够获得一定程度的稀疏性,虽然看起来有较大的正则化强度,这就导致正确率的折衷。而 L2 正则化不会导致稀疏性,它只有更小幅度的权重。同时,对正确率似乎没有什么有害的影响。
54、什么是fine-tuning?
解析:
在实践中,由于数据集不够大,很少有人从头开始训练网络。常见的做法是使用预训练的网络(例如在ImageNet上训练的分类1000类的网络)来重新fine-tuning(也叫微调),或者当做特征提取器。
以下是常见的两类迁移学习场景:
1 卷积网络当做特征提取器。使用在ImageNet上预训练的网络,去掉最后的全连接层,剩余部分当做特征提取器(例如AlexNet在最后分类器前,是4096维的特征向量)。这样提取的特征叫做CNN codes。得到这样的特征后,可以使用线性分类器(Liner SVM、Softmax等)来分类图像。
2 Fine-tuning卷积网络。替换掉网络的输入层(数据),使用新的数据继续训练。Fine-tune时可以选择fine-tune全部层或部分层。通常,前面的层提取的是图像的通用特征(generic features)(例如边缘检测,色彩检测),这些特征对许多任务都有用。后面的层提取的是与特定类别有关的特征,因此fine-tune时常常只需要Fine-tuning后面的层。
预训练模型
在ImageNet上训练一个网络,即使使用多GPU也要花费很长时间。因此人们通常共享他们预训练好的网络,这样有利于其他人再去使用。例如,Caffe有预训练好的网络地址Model Zoo。
何时以及如何Fine-tune
决定如何使用迁移学习的因素有很多,这是最重要的只有两个:新数据集的大小、以及新数据和原数据集的相似程度。有一点一定记住:网络前几层学到的是通用特征,后面几层学到的是与类别相关的特征。这里有使用的四个场景:
1、新数据集比较小且和原数据集相似。因为新数据集比较小,如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
2、新数据集大且和原数据集相似。因为新数据集足够大,可以fine-tune整个网络。
3、新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
4、新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
实践建议
预训练模型的限制。使用预训练模型,受限于其网络架构。例如,你不能随意从预训练模型取出卷积层。但是因为参数共享,可以输入任意大小图像;卷积层和池化层对输入数据大小没有要求(只要步长stride fit),其输出大小和属于大小相关;全连接层对输入大小没有要求,输出大小固定。
学习率。与重新训练相比,fine-tune要使用更小的学习率。因为训练好的网络模型权重已经平滑,我们不希望太快扭曲(distort)它们(尤其是当随机初始化线性分类器来分类预训练模型提取的特征时)。
55、请简单解释下目标检测中的这个IOU评价函数(intersection-over-union)
解析:
在目标检测的评价体系中,有一个参数叫做 IoU ,简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率。
具体我们可以简单的理解为:即检测结果DetectionResult与真实值Ground Truth的交集比上它们的并集,即为检测的准确率 IoU :
举个例子,下面是一张原图

然后我们对其做下目标检测,其DR = DetectionResult,GT = GroundTruth。

黄色边框框起来的是:
DR⋂GT
绿色框框起来的是:
DR⋃GT
不难看出,最理想的情况就是DR与GT完全重合,即IoU = 1。
题目来源:
七月在线官网(https://www.julyedu.com/)——面试题库——面试大题——深度学习 第51-55题。
福利时刻:为了帮助大家系统地学习机器学习课程的相关知识,我们特意推出了深度学习系列课程。

更多资讯
请戳一戳




