AI界最危险武器 GPT-2 使用指南:从Finetune到部署
今早一起床就看到 François Chollet 大神(Keras 作者)发推,根据 GPT-2 中量模型的超长距离记忆想到了一种简单的不基于机器学习的文本生成方式,居然神奇地复现了 GPT-2 的结果,方法很简单(只用了20分钟写代码),每次用要基于文本中的关键词,还有句末几个词,在谷歌直接搜索,然后将获取检索片段基于最后几个词连接起来,只要这样不停做甚至能生成 GPT-2 论文中那个发现神奇独角兽的例子。
至于代码,François 很幽默地说:
“I will not be releasing the code, because you guys couldn't handle the power of a Python script cobbled together in 20 minutes with Requests, BeautifulSoup, and regular expressions. It would change algorithmic cyberwar forever.”
又是一个 “Too dangerous to release。” 不过更多调侃意义在里头,狠狠嘲讽了 OpenAI 一波。
趁此机会,也把自己慢慢码了几天的稿发出来。

如果说 BERT 模型还很巧妙地提出 Maske Language Model Loss 加上 Next Sentence Prediction Loss 来让预训练模型学到更全面信息,那 GPT 系列则就只是把貌似平淡无奇的 Transformer Decoder(单向解码)给加大再加大,当然好的数据也不可少,然后向大家展示大到一定程度后 (GPT-2) 非常厉害的,特别在语言生成上,刚好填补了 BERT 的缺陷。
GPT-2 现在如此有名估计也是吸取了前一次教训,直到 BERT 出现大部分人才知道有个 GPT,于是 GPT-1 完美的成了 BERT 的垫脚石。所以待 GPT-2 出场,虽然论文正文短短几页,却是出尽风头,不知其中 OpenAI 公关有出几分力,待人们问开不开源啊,答曰:”Too Dangerous to Release!(就是不给你们用!)“
此语一出,一下惊起一片反响,立刻出现了挺 OpenAI 派和反 OpenAI 派,双方论证十足,纷纷发文,光那几天我每天都起码得看上一篇关于 GPT-2 争论的博文。而 GPT-2 最小的 117MB (指参数量) 预训练模型,也在这吵吵闹闹中被悄悄放了出来。
之后,偶有在 Reddit 看到几篇基于 117M 模型 finetune 的帖,很有趣,一直想找时间也弄个玩玩,可惜太忙,前段时间专注 BERT 加上度假,也就搁下了。
因此,直到前几天,莫名发现关于 GPT-2 finetune 的帖突然又变多了,才发现 OpenAI 又放出了更大的模型,也就是这篇主要会用到的 345M 模型(如需用小模型,只需将文中 345M 改为 117M 即可)。除此二者,根据论文,应该还有两个更大模型,如果 OpenAI 准备放出的话,估计 GPT-2 这个概念能炒整个 2019 年。

趁着现在这波热潮,总算是把 GPT-2 使用相关的库都浏览了一遍,顺便自己也 finetune 了几个模型,发现效果还挺好的。此外发现网上也没太多关于 GPT-2 使用的中文资料,因此就分享一下自己经验。
本文结构如下,大家自取所需:
首先,我会告诉大家如何用更底层的 nshepperd 的
gpt-2库来 finetune 模型;之后,会介绍如何用更上层的 minimaxir 的
gpt-2-simple库来更简单地 finetune 模型,主要用 Colab 的 Notebook 来教大家免费蹭 GPU 来 finetune 模型;最后,我会介绍如何把训练好的模型用 t04glovern 的
gpt-2-flask-api模型部署到服务器上,通过浏览器访问,输入句子让模型续写。这里还会用到 Hugginface 的pytorch-pretrained-BERT来转换模型格式。
所需库 Github 链接:
gpt-2:https://github.com/nshepperd/gpt-2gpt-2-simple:https://github.com/minimaxir/gpt-2-simplegpt-2-flask-api:https://github.com/t04glovern/gpt-2-flask-apipytorch-pretrained-BERT:https://github.com/huggingface/pytorch-pretrained-BERT
用到的训练数据是我从网上爬下来的老友记十季的剧本:
friends.txt: https://pan.baidu.com/s/1blbeVCro1nErh34KUGrPIA 提取码: 40bn
接下来就让我们开始吧,默认大家会用 Linux 系统来操作。
老板先来一盘 GPT-2
整个过程大体分四步,首先我们需要先 Clone 下来 nshepperd 的 gpt-2 库,之后准备数据与模型,然后再 finetune,最后用保存模型来生成样本。
git clone https://github.com/nshepperd/gpt-2
pip install -r requirements.txt #安装需要用到的包
进入文件夹,下载需要的预训练模型,这里用刚放出来的中型模型,机器不够可以用 117M 模型。
python download_model.py 345M
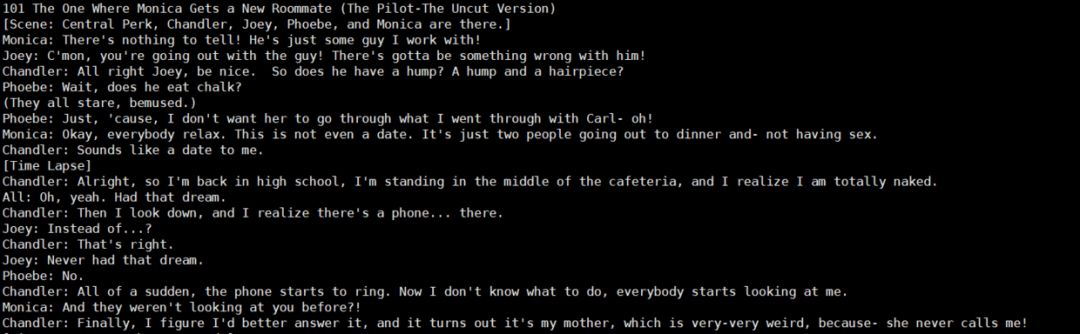
345M 模型比较大,大概 1.4 个G,所以下载同时可以来处理数据。如果用我提供的数据,那直接拷过去就好了,放在data/下。稍微看看数据的样子吧。
然后就可以开始 finetune 了。如想要 finetune 时更快些的话,可以预编码数据成训练格式。
PYTHONPATH=src ./encode.py data/friends.txt data/friends.txt.npz
开始 finetune 吧!
PYTHONPATH=src ./train.py --dataset data/friends.txt.npz --model_name 345M
其他值得关注参数:
learning_rate:学习率,默认2e-5,可根据数据集大小适当调整,数据集大的话可以调大些,小的话可以调小些。sample_every:每多少步生成一个样本看看效果,默认 100。run_name:当前训练命名,分别在samples和checkpoint文件夹下创建当前命名的子文件夹,之后生成的样本和保存的模型分别保存在这两个子文件夹。训练中断想继续训练就可以用同样的run_name,如想跑不同任务请指定不同run_name.
根据机器训练速度会不同,但基本上两三千步就能看到些还算不错的结果了。
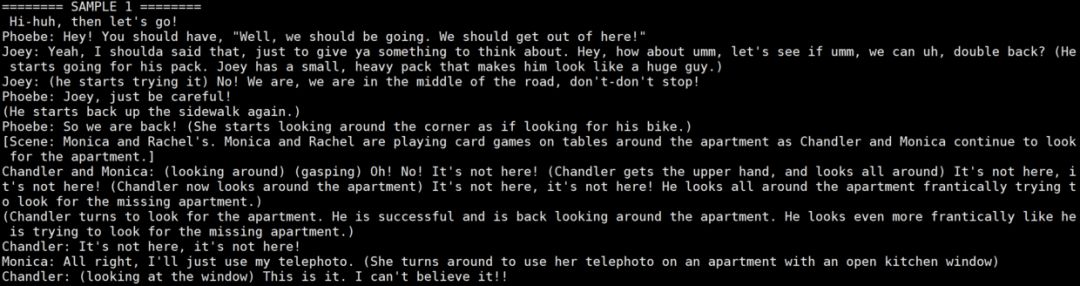
于是我们就拿到了 finetune 好的模型,接下来就来进行好玩的生成环节吧。第一步需要将生成的模型,更改名字,放入models文件夹里,替换掉原来的模型(一定要记得将之前的模型备份!)。
比如说将checkpoint/run1 里的model-4000模型名字都改成model.ckpt,然后移入models/345M里去。
OK了! 先是自由发挥环节,用generate_unconditional_samples.py 来无条件生成样本。
python src/generate_unconditional_samples.py --top_k 40 --temperature 0.9 --model_name 345M
然后是命题作文,有条件互动生成环节。
python src/interactive_conditional_samples.py --top_k 40 --temperature 0.9 --model_name 345M
运行后会出现一个互动框,输入你想让模型续写的话,让我想想...

下面就是见证奇迹的时刻了... ... ... 好一会儿后,当当
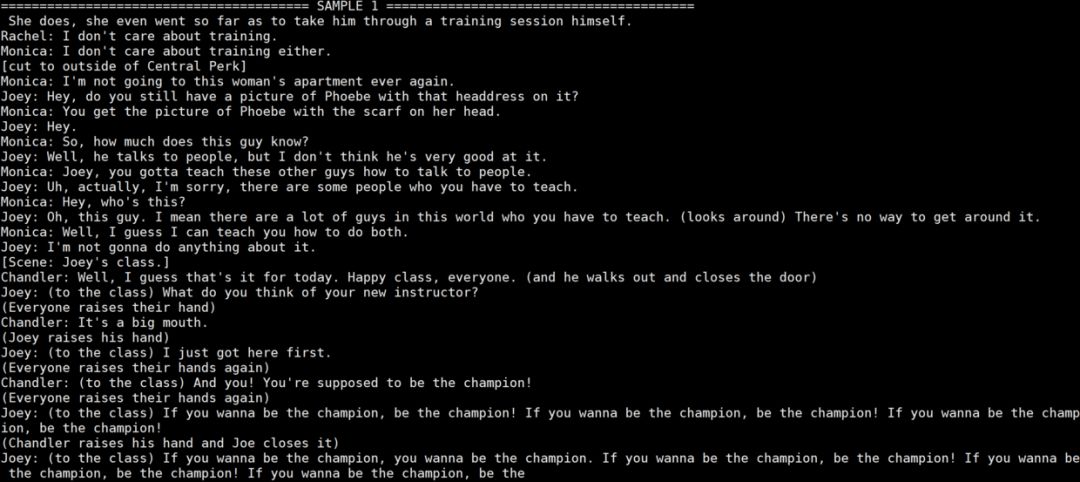
在 Rachel loves Andy 两秒后,完美跑题,伤心,不过感觉后半段还是很有意思。
关于参数 --topk 还有 --temperature,会影响生成的效果,可自己尝试调节一下,上面例子使用的是两个推荐设定。
到此 finetune 一个基本 GPT-2 的过程就完了,是不是比想象中要简单很多。
不过下面还有更简单的方法。
简之又简:gpt-2-simple
如其名,gpt-2-simple 库就是可以让你更简单 finetune 和生成,主要基于上面的gpt-2写的。
关键使用教程,我直接将 Colab Notebbok 部分内容放在这,更详细查看 Notebook。推荐使用 Notebook 查看教程,有免费 GPU 可以薅。
Notebook 链接:https://colab.research.google.com/drive/1_kQQ8WCjus9mz0Cf1onVeE1pUG-ulTqA
整个过程大体和上面一样,不过命令更加简单了。同样先是下载模型。
import gpt_2_simple as gpt2
gpt2.download_gpt2(model_name="345M")
然后放上训练数据,就可以开始训练了。
sess = gpt2.start_tf_sess()
gpt2.finetune(sess,
dataset="friends.txt",
model_name='345M',
steps=1000,
restore_from='fresh',
print_every=10,
sample_every=200,
save_every=500
)
很直观,直接调用 gpt2.finetune 就可以了。
gpt2.finetune 训练参数介绍:
restore_from:
fresh是指从 GPT2 原模型开始, 而latest是从之前 finetune 保存的模型继续训练sample_every: 每多少步输出样本,看看训练效果
print_every: 每多少步打印训练的一些参数,从左到右,步数、时间,loss,平均loss
learning_rate: 学习率 (默认
1e-4, 如果数据小于1MB的话可以调低到1e-5)run_name: 运行的时候,保存模型到
checkpoint下子文件夹,默认run1
你会发现和上一节很多内容都类似。
训练获得保存模型后,又到了生成环节,先把模型 load 进来。
sess = gpt2.start_tf_sess()
gpt2.load_gpt2(sess)
然后生成文本。
gpt2.generate(sess)
gpt2.generate 里面也有很多参数可以设置:
length: 生成文本长度 (默认 1023, 也是可设最大长度)
temperature: temperature 越高,生成越随意。(默认 0.7,推荐 0.7 到 1.0之间)
top_k: 将输出限定在 top k 里面 (默认0,也就是不使用。推荐在生成效果差的时候使用,可以设top_k=40)
truncate: 从指定符号阶段生成文本 (比如设
truncate='<|endoftext|>', 那么就会取第一个'<|endoftext|>'前的文本作为输出). 可以和一个比较小的length值搭配使用.include_prefix: 如果用了
truncate和include_prefix=False, 那么在返回文本中就不会包含prefix里的文本。
要大量生成文本的话可以用 gpt2.generate_to_file.
部署到服务器上
既然弄好了模型,那么当然就是要开始炫耀啦,部署到服务器上,让小伙伴们从浏览器也能直接互动生成文本。
主要用到 Github 上的 gpt-2-flask-api 库,只需要提供它一个预训练或者 finetune 好的 GPT2 模型(Huggingface 的 pytorch 格式)。
将模型文件放在 models/ 下,命名为gpt2-pytorch_model.bin
也可以先用它提供的实例模型来做个实验:
mkdir models
curl --output models/gpt2-pytorch_model.bin https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin
之后运行python deployment/run_server.py.
然后,会获得一个访问端口:

之后直接用浏览器访问就行了,如果是远程访问把 0.0.0.0 改成服务器IP就好了。
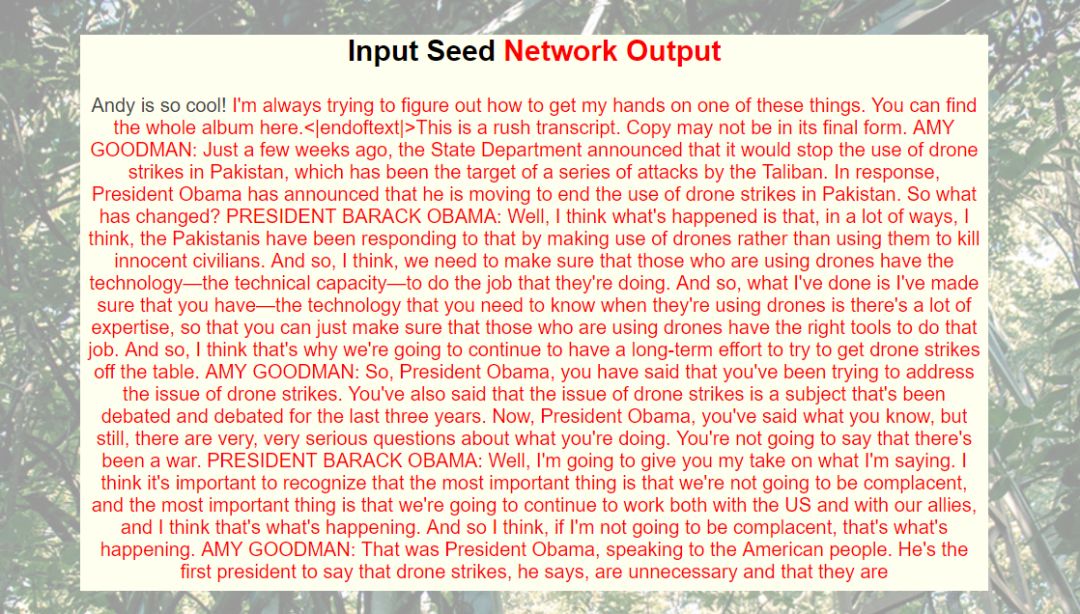
现在往里面键入想要它续写的话就行,等一会儿,结果就出来了。黑色的是用户输入,红色的是模型生成。
最后的问题:如何部署自己的模型
因为 finetune 保存的 tensorflow 的模型文件格式,但这个包只支持 Pytorch 的保存模型。因此我们要先将 tensorflow 的模型转换成 Pytorch 的模型。
这里可以用 Huggingface 的pytorch-pretrained-BERT 库里面的转换脚本,先根据指示安装库,之后运行以下脚本。
export GPT2_DIR=模型所在文件夹
pytorch_pretrained_bert convert_gpt2_checkpoint $GPT2_DIR/model_name output_dir/ path_to_config/config.json
上面命令 convert_gpt2_checkpoint 后三个参数分别是,输入的 tensorflow 模型路径,转换输出的 pytorch 模型路径,模型的配置参数文件。
需要注意的是,因为这几个库之间的不统一,所以下载下来 345M 模型的设置文件在转换时会出错,需要添加一些参数。前面有下载 345M 模型的话,会发现模型文件夹下有一个设置文件 hparams.json。
cp hparams.json hparams_convert.json #复制一份来修改
之后在 hparams_convert.json里添加几个参数,改成下面这样:
{
"n_vocab": 50257,
"n_ctx": 1024,
"n_embd": 1024,
"n_head": 16,
"n_layer": 24,
"vocab_size":50257,
"n_positions":1024,
"layer_norm_epsilon":1e-5,
"initializer_range": 0.02
}将这个设置文件指定到转换命令convert_gpt2_checkpoint后面相应参数去。
获得转换模型后,把它放入models/ 中去,并且重命名,之后把 deployment/GPT2/config.py 里面的参数设定改成 345M 大模型的参数就好了。
class GPT2Config(object):
def __init__(
self,
vocab_size_or_config_json_file=50257,
n_positions=1024,
n_ctx=1024,
n_embd=1024,
n_layer=24,
n_head=16,
layer_norm_epsilon=1e-5,
initializer_range=0.02,
):
最后运行 run_server.py,成功载入模型,部署完成!之后测试一下,发现确实是已经 finetune 好的老友记模型。

本文转载自公众号:安迪的写作间,作者:Andy
推荐阅读
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
Transformer (变形金刚,大雾) 三部曲:RNN 的继承者
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。