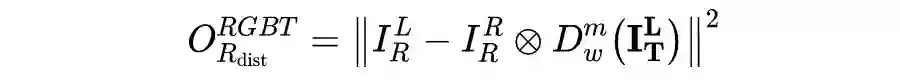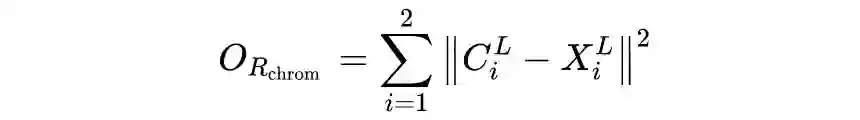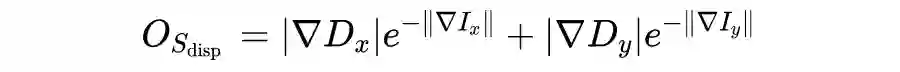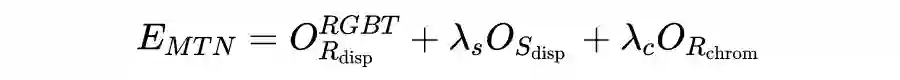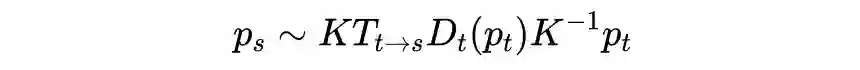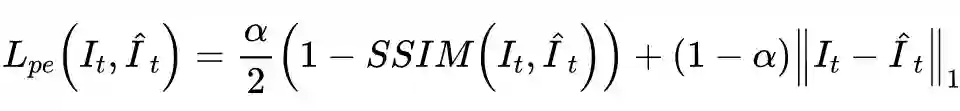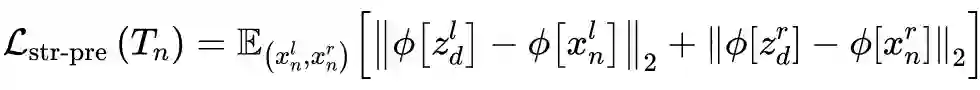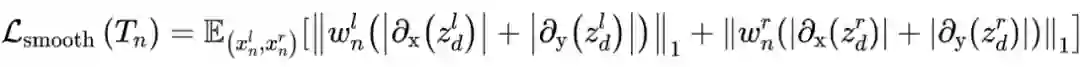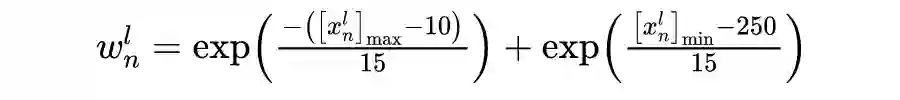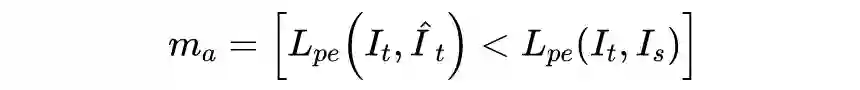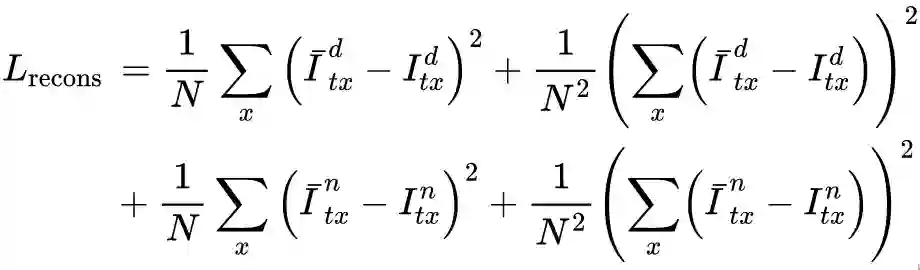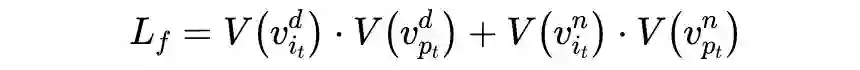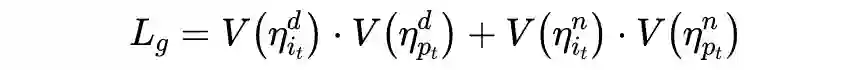单目深度估计虽然在数学和几何上是一个不适定问题(ill-posed),但是随着卷积神经网络的发展,依靠数据驱动的单目深度估计获得了蓬勃的发展。根据场景的不同可以分为室内场景深度估计(如 NYUv2 数据集)和室外场景深度估计(如 KITTI 数据集)。另一方面,根据数据是否具有深度标签又可以分为有监督学习和自监督学习两种范式。
对于室外场景,深度估计主要应用于自动驾驶领域,经典的评估数据集包括 KITTI 和 CityScapes 数据集。由于室外场景中深度范围的跨度较大,现有的 3D 激光扫描仪难以覆盖较大的深度值,即使采用激光雷达等设备也只能得到稀疏的深度标签,难以作为深度模型训练的标签。因此,自监督单目深度估计已经成为室外场景深度估计的主流。
以往的研究更多关注在网络结构的设计、如何添加语义信息,或者设计更好的损失函数和辅助监督等,但是它们都采用白天图像作为训练和评测对象。鲜有研究关注夜间场景下的自监督单目深度估计,因为夜间场景存在更大的挑战,例如低对比度、变化的光照条件、噪声以及时常出现的耀斑和眩光。
本文主要梳理了夜间场景下自监督深度估计方法的发展历程,以及在 ICCV 2021 上的最新进展。
在已有工作中,最先关注夜间场景下深度估计的下面这篇 AAAI 2018 的方法 MTN。
论文标题:
Multispectral Transfer Network Unsupervised Depth Estimation for All-Day Vision
论文地址:
https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewFile/16771/16286
论文来源:
AAAI 2018
项目地址:
http://multispectral.kaist.ac.kr/
作者认为要想理解真实世界,应当让模型能够在全天的条件下进行深度感知。现有机制采用 RGB 传感器采集图像,这会导致白天和夜间的图像差异很大,因此夜间场景具有很大的挑战性。作者从源头出发,认为实现全天深度感知的解决方法是采用热传感器取代 RGB 传感器来搜集高光谱图像,高光谱图像的一大优势是不受强光和黑暗环境下灯光变化的影响。为此,作者首先采集了一个高光谱双目数据集。
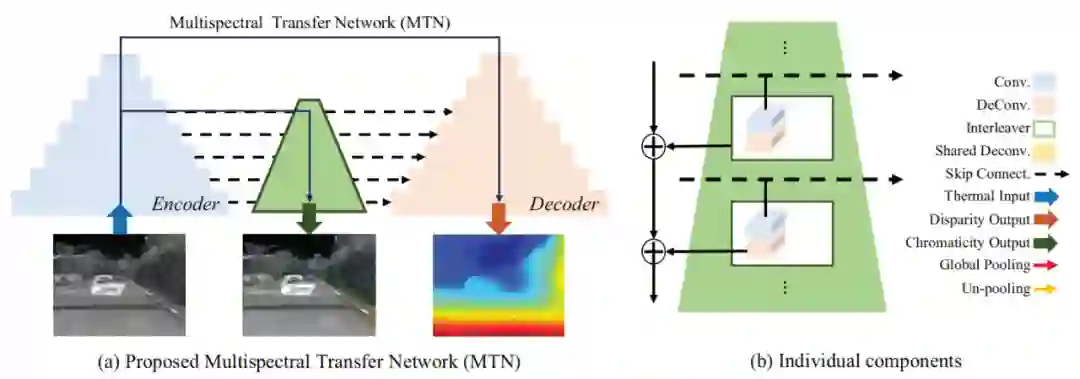
上图展示了作者采集的高光谱双目数据集,一组数据样本包括一对经过校正的 RGB 双目图像,一张根据 RGB 左图对齐的高光谱图像,以及 3D 标注信息。为了确保数据集具有多样性,作者采集了 4 种驾驶场景的数据,分别是第 1 行的校园(campus),第 2 行的住宅区(residential),第 3 行的城市(urban)和第 4 行的郊区(suburbs)。时间横跨白天(7am~2pm)和夜间(10pm~2am)。
为了从单张高光谱图像中估计出深度图,作者设计了基于编解码网络的多光谱迁移网络 MTN。假设一对 RGB 双目图像为
,对应的高光谱图像为
,那么对于估计的视差
,可以采用基于光度重构的损失来进行自监督的学习,即:
本文的另一大创新点是引入多任务学习机制,即从 Encoder 的浅层特征中来重建原始 RGB 图像的色度信息。为此,作者在 Encoder 和 Decoder 之间设计了一个 Interleaver,通过将浅层的特征经过池化和门控机制,与高层特征进行融合来提取色度特征,之后与原始 RGB 图像在 YCbCr 空间计算损失,即:
其中
和
分别是 CbCr 通道的真值和预测值。对于得到的深度图还可以采用深度平滑损失进行平滑性约束:
![]()
这篇工作虽然首次提出了夜间条件下的自监督深度估计问题,但是它是建立在高光谱图像上的,这种热传感器的普及度要远低于 RGB 传感器。后续研究工作更多围绕 RGB 图像来开展,因此这篇工作的后续的影响力有限,但仍是探索夜间场景深度估计的一次尝试。
真正开启夜间环境下,基于 RGB 图像的自监督单目深度估计的工作是下面这篇 ECCV 2020 的工作。
论文标题:
Unsupervised Monocular Depth Estimation for Night-time Images using Adversarial Domain Feature Adaptation
论文地址:
https://arxiv.org/abs/2010.01402
论文来源:
ECCV 2020
项目地址:
https://github.com/madhubabuv/NightDepthADFA
这篇论文的思想简洁明了,即将白天和夜间图像看成两个数据域,通过采用 Patch-GAN 等生成对抗模型来判别白天和夜间图像,从而转换成一个对抗式的域特征自适应(ADFA)问题。在介绍 ADFA 方法前,先介绍自监督单目深度估计的学习范式,这种统一的学习框架适用于后续工作。
自监督单目深度估计可看做是一个视角合成问题。对于每一张参考图像
,我们可以通过深度图
和相对相机位姿
来重构目标图像
。在训练过程中,模型分为深度估计网络
和位姿估计网络
,
利用目标图像来估计深度图
,而
利用参考图和目标图来估计相机位姿
。
在已知相机内参
的情况下,我们得到目标图
中的像素点
和参考图
中的像素点
的逐像素对应关系,即:
之后
可通过可导的双线性差值操作
从
中重构得到,也即
。
在自监督训练阶段,主要采用基于重构的损失和之前介绍的深度平滑损失。重构损失采用
和 SSIM 来计算
和
之间的光度误差,其中
取 0.85:
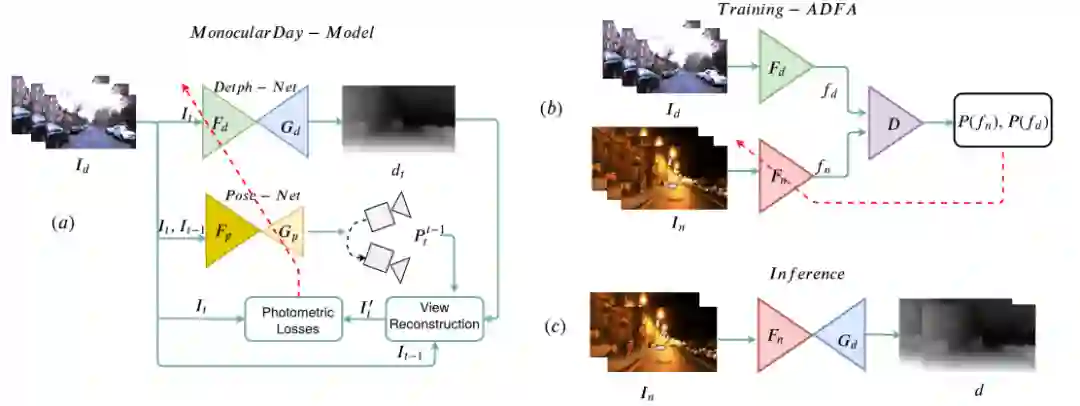
上图展示了 ADFA 的整体框架图,整个流程分为三步:第一步是采用已有的单目深度估计模型(例如 MonoDepthv2)在白天图像上进行自监督训练;第二步是引入基于 Patch-GAN 的判别器训练用于夜间图像特征提取的 Encoder(
);第三步是将夜间图像特征编码器
和白天图像深度解码器
组合起来用于夜间图像的深度估计。下面具体介绍前两步。
-
白天模型:如上图(a),用于白天图像训练的模型包括深度估计编解码器
和相机位姿估计编解码器
,采用自监督学习的范式进行训练,梯度回传路径如红线所示。
-
ADFA 训练:如上图(b),由于白天和夜间图像不是成对的(unpaired),即不是同时或同地拍摄的,因此作者考虑采用对抗学习的方式。引入用于夜间图像特征提取的编码器
,它可看做是生成器,目的是使得夜间图像特征与白天图像特征相似;而判别器
的目的是来鉴别特征来源于白天还是夜间图像。这里作者对每个特征层都采用了一个判别器,实验表明这种多阶段判别器的方式对域自适应的性能提升很有效。
2.3 实验结果
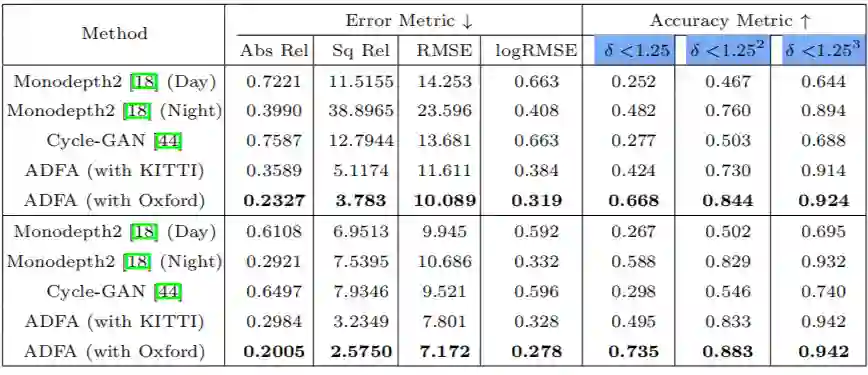
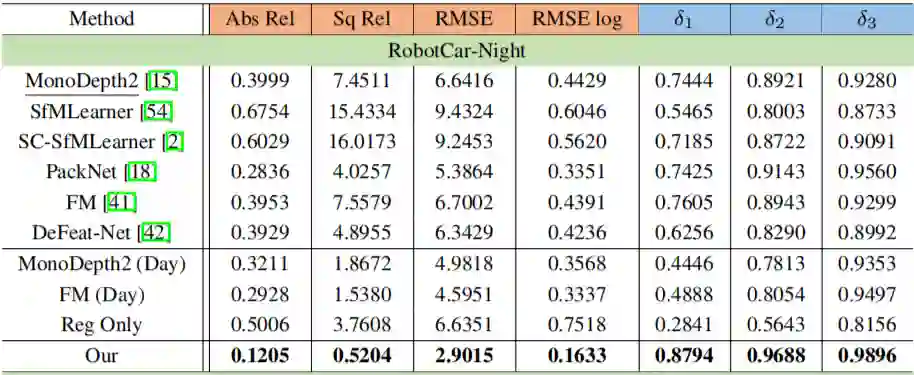
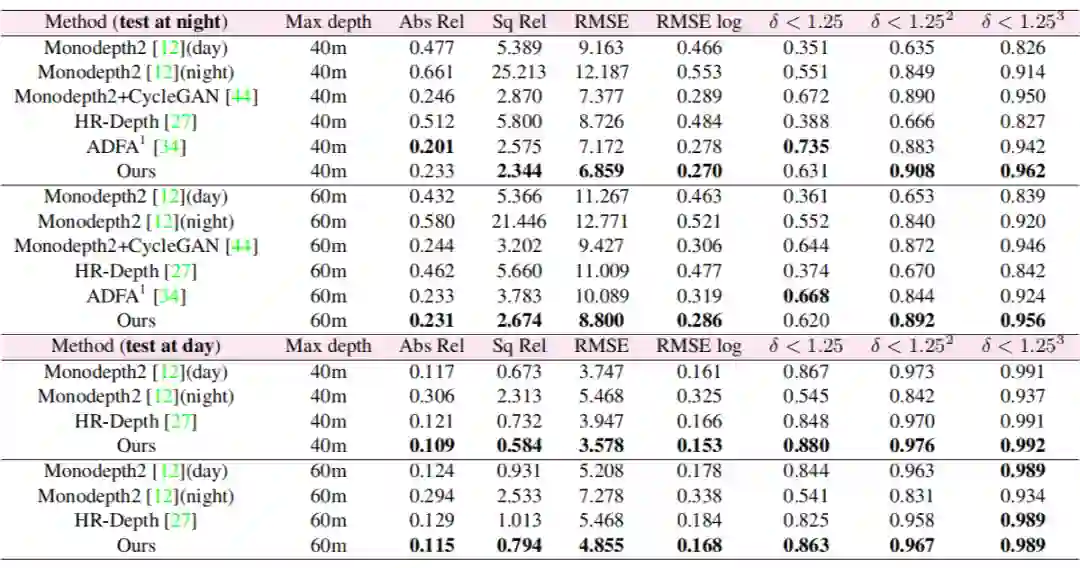
实验采用的数据集是 Oxford RobotCar,这是一个常用的室外驾驶场景数据集,涵盖不同季节、天气、白天和夜间的图像,很适合进行夜间场景深度估计性能的评测。几种模型在该数据集上的定性结果如下表,其中上面一层是以 60 米作为最大深度值,而下面一层是以 40 米作为最大深度值。
第 1 行:采用 Monodepthv2 在白天图像上训练,之后再在夜间图像上测试,性能较差,这表明在白天图像上训练的模型在夜间场景泛化性较差。
第 2 行:采用 Monodepthv2在白天图像上训练后,用部分夜间图像进行自监督微调,虽然性能有显著提升,但是仅靠重构损失在夜间图像上仍然无法取得较好的效果。
第 3 行:采用 Cycle-GAN 将夜间图像迁移成白天图像,再利用白天图像训练的模型进行深度估计,但是这种方法的效果较差,因为 GAN 的风格迁移不足以弥补白天和夜间图像的差异,同时采用 GAN 训练也耗时耗力。
第 4 行:先在 KITTI 的白天图像上预训练,再在 Oxford 的夜间图像上采用 ADFA 训练,性能有显著提升,这验证了所提出的 ADFA 方法的优势。
第 5 行:均在 Oxford 数据集的白天图像上预训练和夜间图像上采用 ADFA,在 Oxford 测试集上取得了最佳的性能。通过第 4 和第 5 行也表明了不仅白天和夜间图像上存在偏差,相同场景的不同数据集下也存在偏差。
如上图,作者还进行了一些可视化定性比较,可见基于重构损失的夜间场景深度估计几乎失败了,而采用 GAN 将夜间图像迁移成白天图像也会造成很多失真的现象,不利于后续的深度估计。本文所提的 ADFA 方法能够较好的估计出夜间图像的深度图。
ADFA 作为夜间场景自监督单目深度估计的开创工作,主要为后续研究工作提供了几点贡献:
提出了基于 RGB 图像的夜间场景自监督单目深度估计的任务,这不同于以往采用高光谱图像的 MTN 方法,成为后续工作的起点;
定义了夜间场景深度估计是采用不成对的白天和夜间图像,这种不成对的问题也成为后续工作的出发点;
将夜间场景深度估计任务转换成域自适应问题,并提出了一种行之有效的方法 ADFA,成为后续工作的 baseline 方法。
在 ADFA 同一时期,还有在双目领域的探索工作,下面简单介绍一下。
Nighttime Stereo Depth Estimation using Joint Translation-Stereo Learning: Light Effects and Uninformative Regions
https://arxiv.org/abs/1909.13701
这篇论文考虑的是夜间场景下的自监督双目深度估计,总体思想和 ADFA 类似,也是通过引入 GAN 来对白天和夜间图像进行转换,并通过两种场景下的一致性约束进行训练。本文拿到了 3DV 的 Oral,其亮点在于还处理了夜间图像中的两个细节性的挑战,一是夜间图像的眩光部分(Light Effects)转换成白天图像时会丢失结构信息;二是在低光照等无信息区域(Uninformative Regions)会产生错误的结构信息。
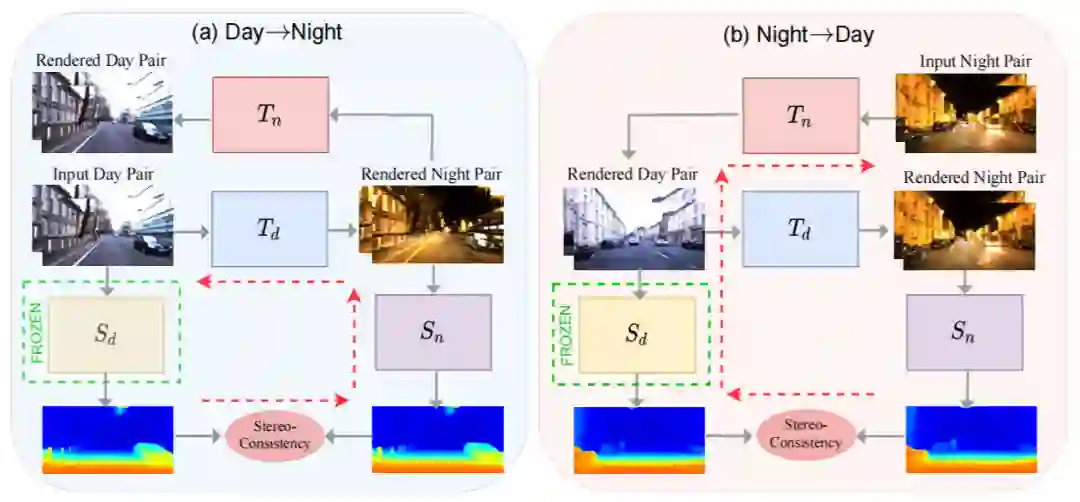
上图展示了本文的整体框架图,分为两个并行的循环结构:
-
白天到夜间:输入白天图像,通过迁移网络
转换成夜间图像,再通过迁移网络
转回白天图像。分别利用白天图像深度估计网络
和夜间图像深度估计网络
得到一对图像在两个场景的视差图。这两个视差图应当具有一致性。
-
夜间到白天:输入夜间图像,先通过迁移网络
转成白天图像,再通过迁移网络
转回夜间图像。其他保持一致。
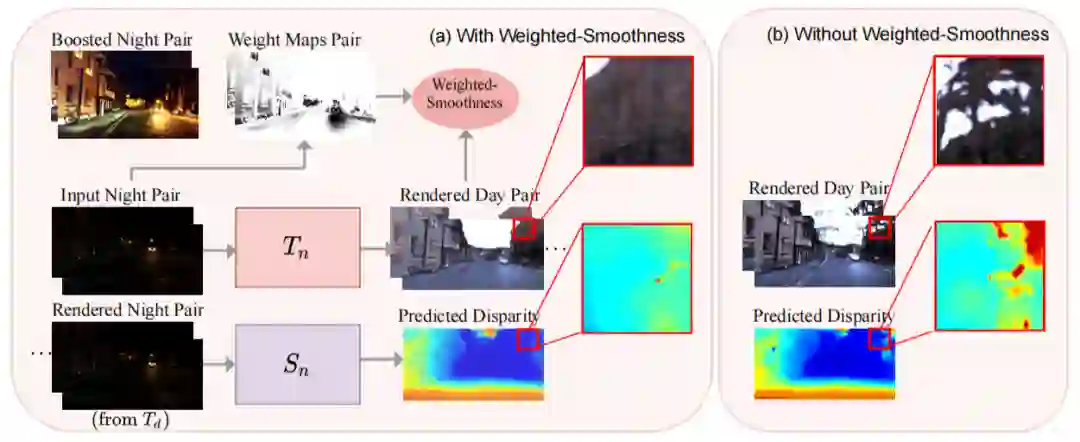
上图仅仅展示了整体框架和双目一致性约束,因此判别器和其他损失函数并没有展示,例如判别损失,基于 Cycle-GAN 的循环一致性损失。尽管上述框架已经能够实现在夜间场景下的深度估计,但是在将夜间图像转换成白天图像时,仍然会存在生成错误区域的现象。本文专门针对两种问题提出了解决方案。
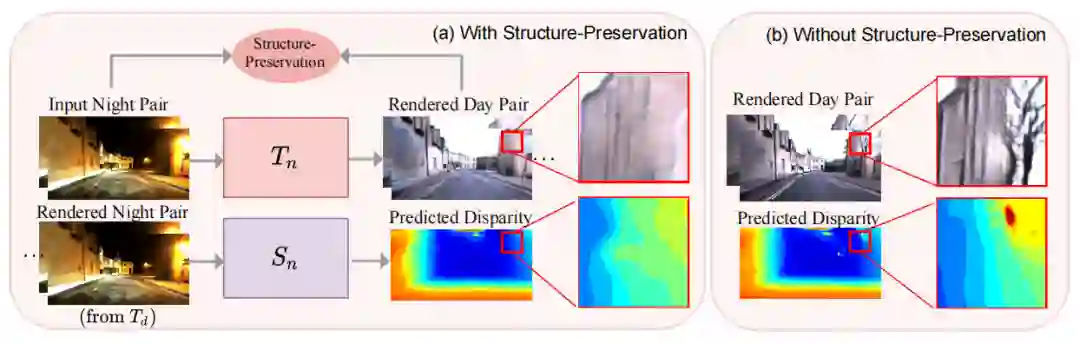
如上图,第一种是针对夜间图像中的眩光,在转换成白天图像时会丢失原有的结构,如图(b)中出现未知的树结构导致深度估计出错。为此,作者提出在训练阶段加入结构保留的约束。具体地,采用在 ImageNet 上预训练的 VGG-16 模型在夜间图像数据集 ExDark 上 finetune,从而使得微调后的 VGG-16 模型保持更好的结构性特征。
对于一对夜间图像
,及其生成的对应白天图像
,对于从夜间到白天图像转换的循环有结构保留损失如下:
其中
选自 finetune 后的 VGG-16 模型的“Conv4_2”层。
如上图,第二种是针对夜间图像中的低光照等无信息区域,这些区域在转换成白天图像时容易出错,生成一些不相符的结构,从而导致深度估计出错。为此,作者提出仅在测试阶段施加加权平滑性约束。同样以一对夜间图像
及其生成的对应白天图像
为例,加权平滑性约束如下:
其中
和
分别计算的是水平和竖直方向的梯度,
是输入图像
的权重图,其计算方式为
![]()
通过这种方式,这些无信息区域在测试阶段可以得到更平滑的深度图。值得注意的是,本文提出的两种技巧对于单目深度估计同样可以适用。
ICCV 2021 的论文近日陆续开放在 Arxiv 上,这里介绍两篇最新的工作。
论文标题:
Regularizing Nighttime Weirdness: Efficient Self-supervised Monocular Depth Estimation in the Dark
论文地址:
https://arxiv.org/abs/2108.03830
论文来源:
ICCV 2021
项目地址:
https://github.com/w2kun/RNW
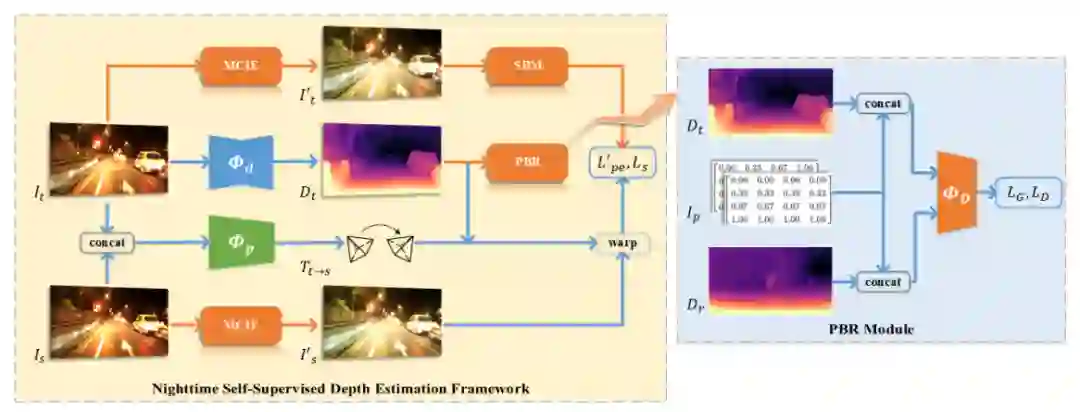
上面这篇论文可以看做是 ADFA 方法的加强版,整体上仍然延续 ADFA 以自监督单目深度估计+对抗学习的框架。作者认为夜间图像的挑战性在于低可见度和变化的光照条件,从而导致弱纹理区域和光照的不一致性。为此提出了三点增强措施,一是基于先验的正则化,用来学习白天和夜间图像的深度分布先验信息;二是映射一致性的图像增强模块来增强夜间图像的可见度和对比度;三是基于数据的掩码策略,用来动态调整无纹理区域的消除像素点个数。
上图展示了论文的整体框架图,其中的三个改进点分别:
-
Priors-Based Regularization(PBR):在对抗学习中加入深度值对应的坐标信息;
-
Mapping-Consistent Image Enhancement(MCIE):在计算光度一致性损失时增强夜间图像的质量;
-
Statistics-Based Mask(SBM):常用的 Auto-Mask(AM)方法的改进版;
PBR 的作用是利用对抗学习和参考深度图
来约束邻域范围内的夜间图像的预测深度图
。深度估计网络
可以看做是生成器,而基于 Patch-GAN 的判别器
用来判别白天图像的深度参考图
和夜间图像的深度图
。
作者观察发现在驾驶场景中,像素点的深度与它的位置具有紧密的联系,因此提出将像素点的位置坐标融合进对抗学习中。具体地,可以对 x 和 y 两个方向的坐标归一化到
,从而得到一张位置图像
。对于深度图
和
也进行归一化,即
,其中
是在空间上计算平均值。最后将
与归一化后的
和
分别 concat,再作为判别器
的输入。对抗损失与 ADFA 中的类似。
MICE 来自 Contrast Limited Histogram Equalization(CLHE),作用是增强夜间图像的可见度和细节纹理,以满足光度一致性。其核心是一个亮度映射函数
,分别对参考图像和目标图像进行亮度变换,以映射到同一个特定的输出。
上图展示了 MCIE 的计算过程,曲线分布是不同亮度层级
频率分布
。MCIE 的计算过程分为三步:
-
裁剪掉频率在给定参数
以上的部分,以限制增强同时避免放大噪声;
将裁剪掉的频率均匀地填充在每一个亮度层级;
-
MCIE 仅在计算光度重构损失时才使用,对于输入网络的图像仍然是原始的 RGB 夜间图像。
动态掩码(AM)技术是自监督单目深度估计中常用的技巧,用来剔除估计不准确的野点和外点,可通过计算重构图像的光度误差与参考图和目标图的光度误差的大小来得到掩码,即:
AM 并不能调整被剔除的像素点个数,SBM 在此基础上更进一步,希望动态地调整剔除像素点的个数。具体地,在训练阶段计算目标帧和每张参考帧的光度差异
,之后利用指数加权移动平均来更新当前帧的误差,即:
其中 i 是当前时间点,
是动量参数(设为 0.98)。之后引入参数
用来表示剔除的百分比,这样可以得到新的掩码
,即
。最终的掩码由
和
采用逐点相乘得到,也即
。
上图表明采用 SBM 能够去除黑色像素点在最终损失中的计算。
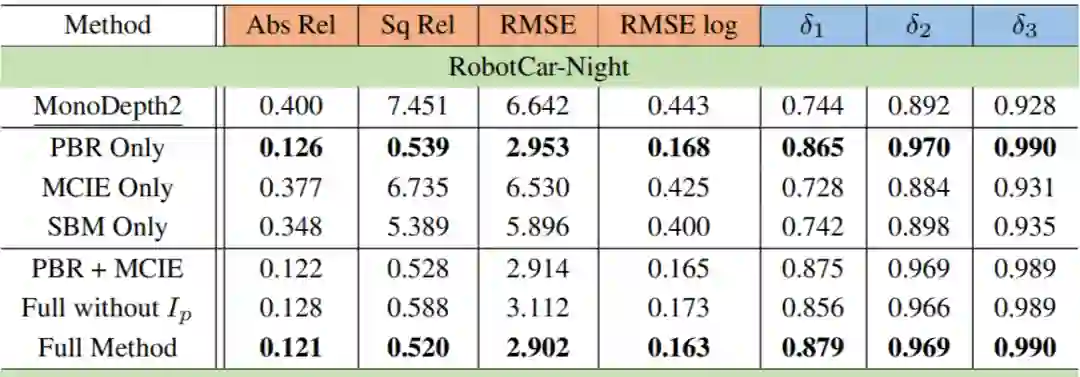
作者也在 Oxford 数据集上进行了实验,相比于现有的 SOTA 方法,所提出的方法在夜间图像上具有更好的性能。相应的消融实验也表明了所提出的模块的有效性。
上表说明所提方法超越了自监督单目深度估计在白天图像上的 SOTA 方法,例如 SfMLearner,PackNet,FM 等。
上表的消融实验说明所提出的 PBR,MCIE 和 SBM 对于性能提升都是有帮助的,其中 PBR 其实是整个算法的核心增长点,MCIE 和 SBM 是锦上添花的改进。
作者也和 ADFA 进行了可视化比较,可见所提出的方法在饱和和模糊区域具有更好的效果,这可能更多得益于 PBR 的提升。
以上方法侧重于单独解决夜间图像的深度估计,但是夜间图像的模型仍然无法较好的估计白天图像。自 AAAI 18 的论文后,今年 ICCV 2021 的工作又重新关注通过一个模型同时估计白天和夜间图像的深度信息。
论文标题:
Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation
论文地址:
https://arxiv.org/abs/2108.07628
论文来源:
ICCV 2021
项目地址:
https://github.com/LINA-lln/ADDS-DepthNet
这篇论文的动机也较为直观,和 ADFA 类似,白天和夜间图像可以看做是两个域,这两个域在光照等扰动条件下具有很大的差异,但是在纹理等共享属性上具有不变性。因此,作者提出将两个域的学习分为私有域(private)和不变域( invariant)。私有域用于专门学习白天和夜间图像的特征,而不变域用于学习白天和夜间图像中共享的特征。
上图展示了本文的整体框架图。输入是夜间图像序列和通过 GAN 生成的对应的白天图像序列。整个框架分为三个模块:
-
白天私有域特征提取模块(黄色):包括白天图像特征提取器
和用于白天图像重构的解码器
。这个设计和 AAAI 18 的 MTN 中的 Interleaver 有点类似,都是在特征提取后增加了光度重构。
-
夜间私有域特征提取模块(绿色):包括夜间图像特征提取器
和用于夜间图像重构的解码器
。
-
共享深度估计模块(橙色):包括权重共享的不变域特征提取模块
和深度估计解码器
。
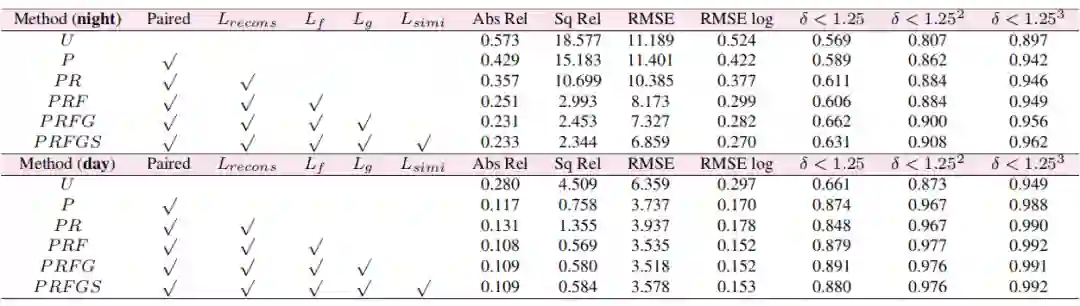
论文的另一大核心内容是驱动整个框架训练的损失函数的设计,包括以下 4 种损失函数:
重构损失(Reconstruction Loss)
重构损失是白天和夜间图像经过
和
重构的 RGB 图像与原始图像的光度误差,也即:
由于输入的白天图像是夜间图像通过 GAN 生成的,因此二者是成对的。那么在经过深度估计网络后得到的深度图也应当具有一致性约束,由此得到相似性损失如下:
对于白天和夜间图像,二者既有对应的私有特征提取器来提取各自域的私有特征
,又有共享的不变特征提取器来提取共享特征
,因此私有特征和共享特征应当是完全不同的。为此,作者设计了两种正交损失来保证两种特征的不同。
一种是直接特征正交损失:对于私有特征
和不变特征
,分别通过
卷积降维再平铺成 1 维向量,采用向量内积的方式(操作
)来做损失,记为
如下:
均表示
卷积操作。另一种是 Gram 矩阵正交损失:Gram 矩阵在风格迁移中广泛用于表征特征的不同风格,为此,作者先对两种特征计算 Gram 矩阵,再平铺成 1 维向量来计算向量内积,记为
如下:
光度损失是自监督单目深度估计学习范式中的光度一致性损失,这里不再赘述。
作者同样在 Oxford 数据集上进行了评估,分别和 SOTA 方法进行了定性和定量比较,同时进行了消融实验表明了几种损失函数的有效性。
上表展示了在白天和夜间两种场景下的深度估计性能,可见所提方法在两种场景, 40m/60m 两种评估标准下都要超越现有的方法,特别是和 ADFA 比较也有更进一步的提升,但是本文的另一个优势还能同时估计白天图像的深度。
上图展示了和现有方法在夜间图像的深度图可视化结果,重点关注与 ADFA 的比较,可见 ADFA 对目标边界的建模效果较差,而本文的方法能够取得更好的效果。
最后在消融实验上验证了重构损失,两种正交损失和相似度损失的有效性。
从上述几篇工作来看,夜间场景下的自监督深度估计离不开基于 GAN 的对抗学习,研究重心在于设计更有效的网络训练框架,设计新颖的损失函数,以及解决夜间图像转换到白天图像后的细节性挑战,这三个方面可能也是后续工作的跟进点和改进点。另一方面,未来工作能否打破基于 GAN 的学习模式,或者引入外部辅助信息等也是值得探索的领域。
![]()