目标检测之殇—小目标检测

极市导读
目标检测作为一项发展了20年的技术,技术层面已经非常成熟,涌现了一大批可以在工业界实用的目标检测方法,但小目标检测性能差的问题至今也没有被完全解决。本文详细分析了小目标检测的难点以及梳理了小目标检测近年来的发展现状。>>加入极市CV技术交流群,走在计算机视觉的最前沿
目标检测作为一项发展了20年的技术,技术层面已经非常成熟,涌现了一大批如Faster R-CNN、RetinaNet、YOLO等可以在工业界实用的目标检测方法,但小目标检测性能差的问题至今也没有被完全解决。因为Swin Transformer的提出,COCO test-dev(https://competitions.codalab.org/competitions/20794#results)上的 已经刷到61 ,但小目标检测性能(即 )和大目标检测性能(即 )仍然差距悬殊, 是 的1.7倍(74 AP vs 44 AP)。从某方面讲,现在COCO刷不上去的一个主要原因就是小目标检测的性能太差。
小目标检测难点
本文所指的小目标是指COCO中定义的像素面积小于32*32 pixels的物体。小目标检测的核心难点有三个:
-
由本身定义导致的rgb信息过少,因而包含的判别性特征特征过少。 -
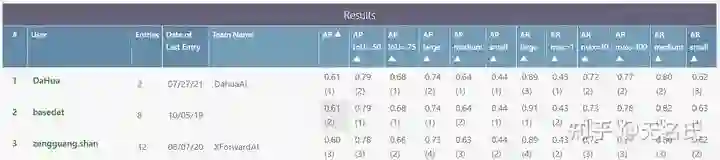
数据集方面的不平衡。这主要针对COCO而言,COCO中只有51.82%的图片包含小物体,存在严重的图像级不平衡。具体的统计结果见下图。
-
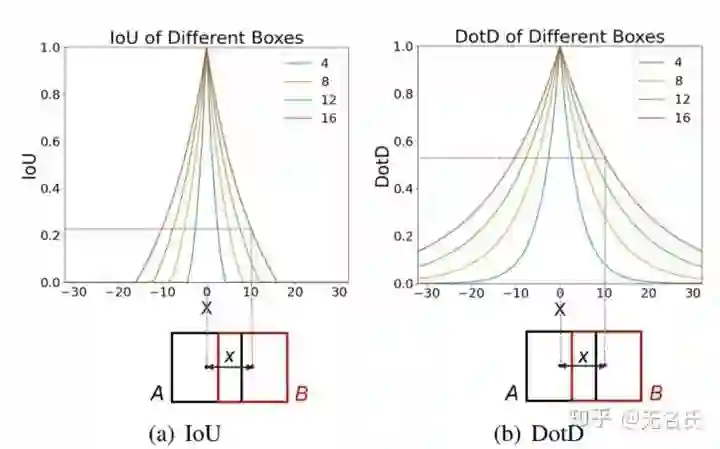
anchor难匹配问题。这主要针对anchor-based方法,由于小目标的gt box和anchor都很小,anchor和gt box稍微产生偏移,IoU就变得很低,导致很容易被网络判断为negative sample。如下图,不同颜色代表不同size的gt box,对于小目标,IoU对偏移量x极为敏感。
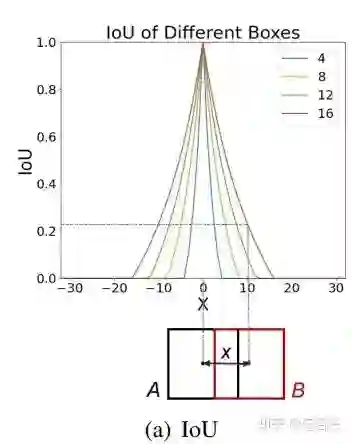
除了以上三点,最近个人发现了另一个难点:COCO中很大一部分小目标标注都是hard case annotation。它们不仅仅是小,而且是难,存在不同程度的遮挡、模糊、不完整现象(见下图),这也就解释了为什么在41%的标注都是小目标的情况下,小目标的检测性能还是如此差,因为它们中很大一部分标注都是难以被有效利用的。



小目标检测研究现状
小目标检测一直都是计算机视觉领域的研究热点,近年来各式各样的方法被提出来解决小目标检测问题,主要可分为以下几种。
Multi-scale feature learning
这一类方法大致思想都是将不同scale物体分开学习,主要解决的是小目标本身判别性特征少的问题,它们可细分为两类,分别是feature pyramid based和receptive filed based。
feature pyramid based方法以FPN为代表,主要思想是融合low-level的空间信息和high-level的语义信息来加强目标特征,其它方法大都是FPN的“魔改",具体如下:
-
Path aggregation network for instance segmentation, CVPR 2018 -
Augfpn: Improving multi-scale feature learning for object detection, CVPR 2020 -
Effective fusion factor in fpn for tiny object detection, WACV 2021

这类方法在FPN之后就再没有突破性的工作,大部分是水文,花式融合特征。
receptive filed based方法以Trident Network[3]为代表,核心思想是小目标需要较小的感受野,大目标需要较大的感受野,利用不同dilation rate的dilated covolution,构成具有不同感受野的、负责检测不同scale物体的三个branch。
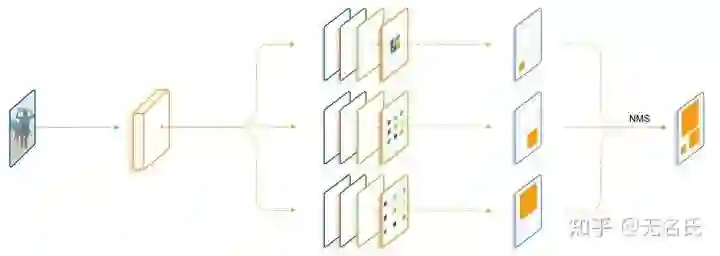
GAN-based
基于GAN的方法解决的也是小目标本身判别性特征少的问题,其想法非常简单但有效:利用GAN生成高分辨率图片或者高分辨率特征。
生成高分辨率图片的方法有SOD-MTGAN[4],大致思路是利用训练好的detector如Faster R-CNN获取包含object的子图,然后利用generator生成对应的高清图像,discriminator则负责判断生成的图像是real还是fake,同时充当detector的作用,预测object的类别和位置。

生成高分辨率特征的方法有Perceptual GAN[5]和BFFBB GAN[6],以BFFBB GAN为例,其思想是将输入图像缩小2倍然后经过特征提取得到的特征作为low resolution feature,原图像经过特征提取得到的特征作为对应的 "real" high resolution feature,generator根据low resolution feature生成 "fake" high resolution feature,discriminator负责区分"fake" high resolution feature和“real" high resolution feature。
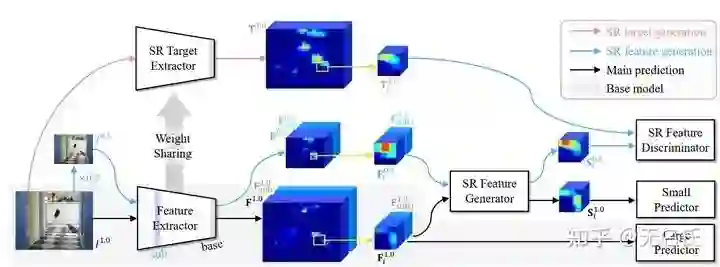
Context-based
Context-based方法的核心思想是利用小物体所处的环境信息或者和其它容易检测的物体之间的relationship来辅助小物体的检测,本质上解决的也是小目标本身判别性特征少的问题。这类方法最有名的有以下三个:
Inside-Outside Net[7]通过上下左右四个方向的RNN提取每个物体的全局context信息。
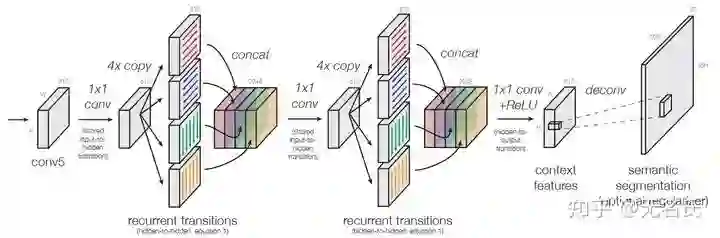
Pyramidbox[8]针对的是小人脸检测问题,其利用头与身体总是和人脸一起出现的先验信息,并且前两者总是更好检测,具体做法是通过检测头和身体来确定人脸的位置,再做进一步检测。

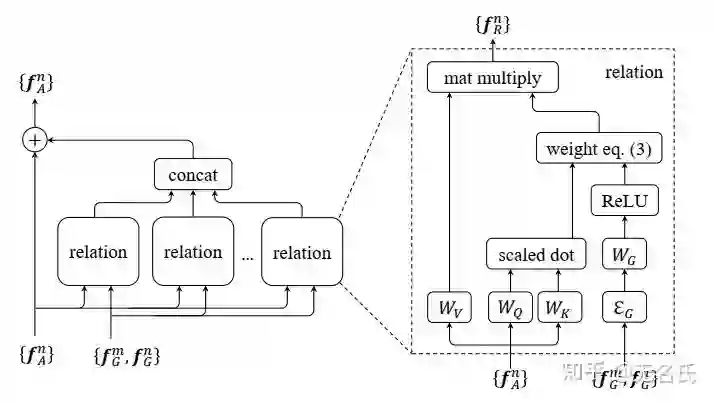
RelationNetwork[9]利用物体之间的relationship来辅助小物体的检测,核心想法是通过Transformer隐式建模两两物体间的relationship,并利用这种relationship加强每个object的特征。
Data-based
Data-based方法从数据集本身解决问题,该类方法往往只对特定数据集有效,如COCO。COCO数据集存在两种不平衡问题:image-level 和 instance-level imbalance。
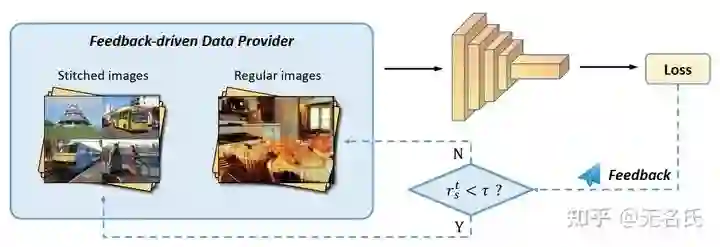
image-level imbalance指COCO中只有51.8%图片含有小物体。解决该问题的代表性方法是Stitcher,Stitcher[10]以小物体的loss在总loss中的占比为反馈信号,当占比小于某阈值时,将四张图片拼成一张图片作为下次iter的输入,相当于增加了小物体的数量。
instance-level imbalance指COCO中小物体像素面积只占1%。Augmentation[11]通过简单的复制粘贴小物体来解决该问题。

Special design for small object
此类方法指对现有目标检测方法做改进,对小物体做“特殊照顾”。
FaceBoxes[12]定义了一种描述anchor在原图上分布的密集程度的指标:
代表anchor的尺度(如256*256就是256), 指anchor中心点之间的距离, 越大代表anchor在原图越密集。作者计算了不同大小物体的density,发现小物体的anchor分布太稀疏,所以“朴素”地增加了小物体anchor的数量。
S3FD[13]做法更“朴素”,降低小物体positive sample的IoU阈值(大于某IoU即为pos),如果经历这一步有些小物体匹配的anchor还是太少,就在和该物体IoU大于0.1的所有anchor中选择top N个anchor作为匹配的anchor。
Dot Distance[14]设计新的指标DotD代替IoU来做pos和neg assignment,简单来说就是两个bbox中心点的距离的函数:
该指标对bbox偏移不敏感,少量的偏移不会导致该指标的剧烈下降。
Special training strategy
此类方法主要通过设计特殊的训练策略来提升小物体检测性能,代表方法有以下两个:
SNIP[15]是针对image pyramid训练方法的改进,其通过在小尺度的图像上检测大物体、大尺度的图像上检测小物体,来保证输入分类器的物体大小接近 ,即和在ImageNet上预训练的尺度一致,进而提升小物体检测性能。
SNIPPER[16]是SNIP的加强版,其根据图像内容自适应得在image pyramid截取一系列子图(chips),这样小物体就被放大了,同时计算量也变小了。

Loss reweight
该类方法通过提升小物体loss中的权重来让网络更关注小物体的训练。代表方法有Feedback-driven loss[17],其利用和Stitcher[10]一样的反馈机制,即当小物体loss占比较低时,提升小物体loss的权重,从而让网络更平等地对待不同尺度的物体。
个人对小目标检测的理解
我现在的研究方向就是小目标检测,且做的是通用小目标检测(COCO),在我看来,小目标检测的难点远不止一个“小”字,它还可能是被严重遮挡的大物体的局部,亦可能伴随着模糊、黑暗,它是目标检测领域最难啃的骨头。可能也正因为它难,近年来小目标检测相关的顶会几乎没有了,大家都在那些容易做但是意义不大的地方疯狂水文章,某种程度上也可以说2D目标检测已经到达了瓶颈阶段,而小目标检测是突破这个瓶颈的关键一环。
纵观我上面列举的那些方法,只有FPN和GAN在本质上解决了问题,其它方法大都是意义不大的改进,特别是data-based方法,换个数据集可能就完全不起作用。也有可能是深度学习方法本身达到了某种瓶颈,它就是无法解决这种hard case问题。不知道未来会不会出现一种新颖的解法,让我们拭目以待吧!
为了促进小目标检测领域的进一步发展,我建了一个小目标检测论文库
https://github.com/Icecream-blue-sky/Past-and-present-small-object-detection
实时收录最新的并且是个人阅读过的小目标检测论文,欢迎大家Star和提issue!
参考:
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




