【泡泡图灵智库】DynaSLAM:动态场景中的追踪、建图和修复(arXiv)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
作者:Berta Bescos, Jose M. Facil, Javier Civera and Jose Neira
来源:arXiv:1806.05620v2 [cs.CV],现已被IEEE Robotics and Automation Letters接收
编译:李雨昊
审核:万应才
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes ,该文章发表于arXiv:1806.05620v2 [cs.CV],现已被IEEE Robotics and Automation Letters接收。
在SLAM算法中的一个典型假设是场景固定。这样的一个强假设限制了大多数视觉SLAM系统在有人居住下真实环境中的使用,而这正是一些诸如服务机器人、自动驾驶车辆等相关应用的目标场景。本文中,作者提出DynaSLAM系统,这是一种建立在ORB-SLAM2上的视觉SLAM系统,同时增加了动态物体检测和背景修复功能。DynaSLAM在单目、立体、RGB-D传感器下的动态场景中均有鲁棒性。作者通过使用多视几何、深度学习或者两者兼有的方法实现移动物体的检测。并且通过对动态物体遮挡的背景帧进行修复,生成静态场景地图。作者在单目、立体、RGB-D公开数据集上进行了评估。通过研究几项影响精度和速度之间权衡的因素评估了本文提出方法的极限。DynaSLAM在动态场景中的精度优于标准视觉SLAM系统架构,并且可以生成静态的场景地图,而这一点是SLAM在真实环境中长期应用所必需的。
主要贡献
1、提出了基于ORB-SLAM2的视觉SLAM系统,通过增加运动分割方法使得其在单目、立体、RGB-D相机的动态环境中均具有稳健性。
2、通过对因动态物体遮挡而缺失的部分背景进行修复,生成一个静态场景地图。
算法流程

图1 RGB-D例子下DynaSLAM的结果

图2 本文方法的完整流程图
对于RGB-D相机而言,将RGB-D数据传入到CNN网络中对有先验动态性质的物体如行人和车辆进行逐像素的分割。作者使用多视几何在两方面提升动态内容的分割效果。首先作者对CNN输出的动态物体的分割结果进行修缮;其次,将在大多数时间中保持静止的、新出现的动态对象进行标注。对于单目和双目相机,则直接将图像传入CNN中进行分割,将具有先验动态信息的物体分割出去,仅使用剩下的图像进行跟踪和建图处理。
A、使用卷积神经网络对潜在的动态物体进行分割
作者使用Mask RCNN进行实例分割,他们认为在大多数环境中的潜在动态或可移动物体有:人、自行车、汽车、猫、摩托车、飞机、人,自行车,汽车,摩托车,飞机,巴士,火车,卡车,船,鸟,猫,狗,马,羊,牛,大象,熊,斑马和长颈鹿。如果需要增加其他类别,可以在MS COCO数据集上进行微调得到相应的权重模型。在实例分割部分,输入数据为m*n*3的RGB图像,输出为m*n*L的矩阵,再将L层分类图像合并成一幅图像。
B、基于Mask RCNN和多视几何的动态物体分割
主要是针对性地处理在Mask RCNN中没有先验动态标记而具有移动性的物体的分割,例如行人手中的书等。
对于每一个输入影像帧,作者选择一些与其重叠度最大的旧影像帧(文中作者选择数量为5),将这些旧影像帧上的关键点x投影到当前帧上得到特征点x',以及其投影深度zproj,同时生成对应的三维点X。计算关键点x,x'与三维点X形成的夹角xXx', 记为Alpha,若Alpha大于30度则认为该点可能被挡住了,即不对其做处理。作者观察到在TUM数据集中,夹角Alpha大于30°时的静态物体即被认为是动态的。单目、双目情况下,作者使用深度测量计得到x'对应的深度值z',在误差允许的范围内,将其与zproj进行比较,超过一定阈值则认为该点x'对应于一个动态的物体。判断过程如图3所示。作者经过在TUM数据集上进行的测试发现深度值差阈值为0.4m时,表达式0.7*Precision +0.3* Recall达到最大。
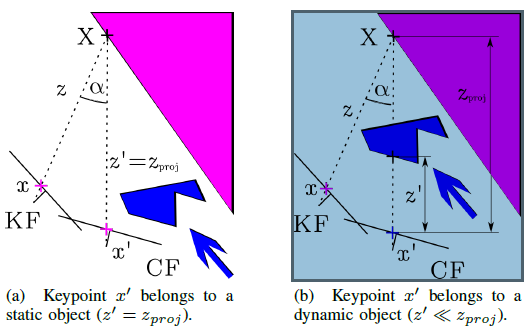
图3 采用多视几何判断动态物体示意图
作者对处于运动物体边缘的被标记为动态物体的关键点进行了额外处理,通过其邻域范围内的像素进行判断,对其标记状态进行修改。对图像中像素的分类标记使用区域生长算法得到了运动物体的掩膜。图4显示了基于多视几何、深度学习和两者结合的方式进行动态物体分割的结果对比

图4 使用不同分割方法检测和分割动态物体的对比结果
同时需要注意的是,在追踪和建图的过程中需要对由于掩膜出现,在边缘处检测出的异常ORB特征点进行去除。
C、背景修复
作者将之前20关键帧的RGB以及深度图投影到当前帧上完成无动态物体的背景修复。值得注意的是,由于在其他帧中再也没有出现过当前帧中的场景或者深度信息无效造成投影失败,会导致结果中不可修复裂痕的出现。一旦出现这种情况则还需要另寻他法。图5显示了从不同TUM基准序列中得到人工合成影像。利用这些经过修复的影像可以得到满足静态场景假设的SLAM效果。

图5 不同TUM序列中人工合成的影像图
主要结果
将本文提出的系统和原始ORB-SLAM2进行比较,来验证本文方法在动态场景中的提升。作者在相应的序列数据上进行了10次测试,以避免不确定性效应。
A、TUM数据集
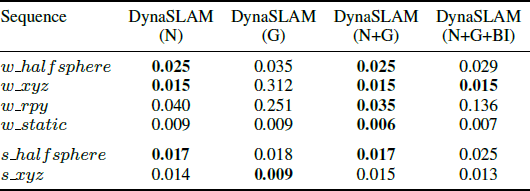
表1 不同DynaSLAM变体的测试结果
DynaSLAM (N)代表仅使用Mask RCNN进行动态物体分割; DynaS LAM (G)代表仅使用基于深度变化的多视几何进行动态检测和分割;DynaSLAM (N+G)代表同时利用多视几何和深度学习的方法进行检测;DynaSLAM (N+G+BI)代表在背景修复之后进行跟踪和建图的操作(这时是基于真实影像和重建影像完成ORB特征提取)。从表中可以发现使用DynaSLAM(N+G)的精度是最高的,DynaSLAM (G) 由于在经过一定的延迟之后运动估计和实例分割才会准确这一方法特性,使得最后的精度较差。DynaSLAM (N+G+BI)由于使用了重建之后的影像进行跟踪,而相机姿态会对重建影像有较大影响,因此这样的效果比较差。
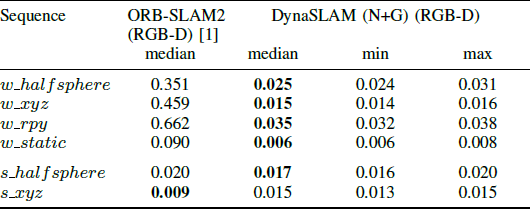
表2 DynaSLAM与 RGB-D ORB-SLAM2的比较
作者还将DynaSLAM(N+G)中RGB-D分支与RGB-D ORB-SLAM2进行了对比。可以发现在高动态场景walking中,本文的方法优于ORB-SLAM2,并且误差与RGB-D ORB-SLAM2在静态场景中的误差相近。而在低动态场景setting中,要稍微差一些。
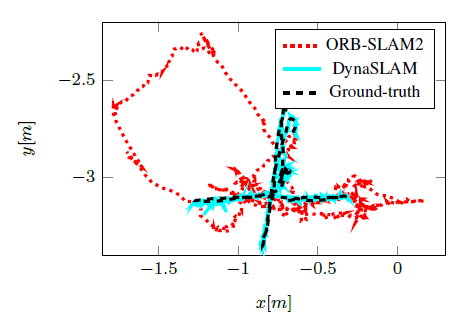
图6 DynaSLAM与ORB-SLAM2估计得到的轨迹
与地面真值之间的比较
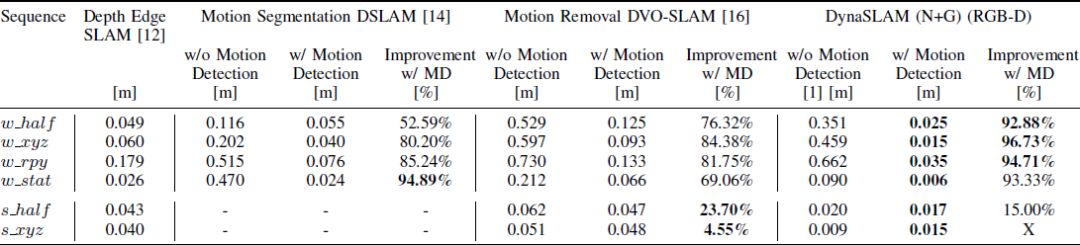
表3 当前主流RGB-D SLAM系统与DynaSLAM系统之间的比较
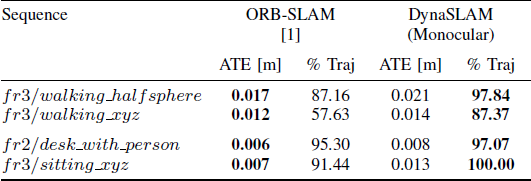
表4 ORB-SLAM和单目DynaSLAM在TUM数据集上
的跟踪结果以及跟踪轨迹的百分比
B、KITTI数据集
在KITTI数据集上中进行测试发现,DynaSLAM以及ORB-SLAM在有些场景下的结果是相近的。当不在具有先验动态信息的物体上提取特征时,跟踪精度会比较高,诸如汽车,自行车等(KITTI01\KITTI04);当在大多数车辆都是停止状态时,DynaSLAM的误差会大一些,因为将这些物体对象去掉之后检测到的特征点会处于较远或纹理较弱的区域,从而导致跟踪精度下降(KITTI00\KITTI02\KITTI06)。但是在回环检测和重定位处理中结果较为稳健,因为构建的地图中仅仅包含结构性物体对象,没有动态物体。而如何设计更好的特征区分标准,使得具有移动性的物体在未移动时,其对应的关键点可以被用于跟踪却不会在最终的结果地图中出现这一问题需要进行更加深入的研究。
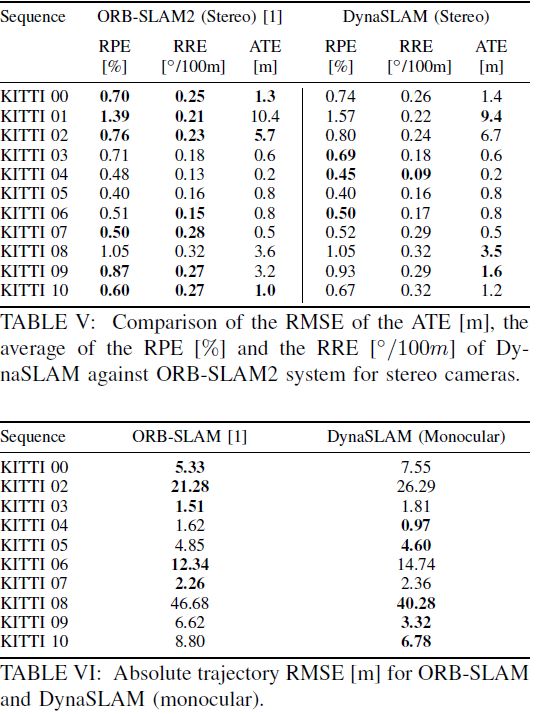
表5、6 双目条件下DynaSLAM和ORB-SLAM之间的比较以及单目下DynaSLAM和ORB-SLAM之间的比较结果
C、时间分析
作者还提到所做的实验中并没有对算法进行工程优化,因此时间上的开销会比较大,具体时间开销详见下表7。

表7 DynaSLAM中各部分的时间开销

Abstrac
The assumption of scene rigidity is typical in SLAM algorithms. Such a strong assumption limits the use of most visual SLAM systems in populated real-world environments, which are the target of several relevant applications like service robotics or autonomous vehicles.
In this paper we present DynaSLAM, a visual SLAM system that, building on ORB-SLAM2, adds the capabilities of dynamic object detection and background inpainting. DynaSLAM is robust in dynamic scenarios for monocular, stereo and RGB-D configurations. We are capable of detecting the moving objects either by multi-view geometry, deep learning or both. Having a static map of the scene allows inpainting the frame background that has been occluded by such dynamic objects.
We evaluate our system in public monocular, stereo and RGB-D datasets. We study the impact of several accuracy/speed trade-offs to assess the limits of the proposed methodology. DynaSLAM outperforms the accuracy of standard visual SLAM baselines in highly dynamic scenarios. And it also estimates a map of the static parts of the scene, which is a must for long-term applications in real-world environments.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



