模型加速 | 华为提出高效的模型加速框架(附源码)
计算机视觉研究院专栏
作者:Edison_G

2.背景
卷积神经网络在识别、检测和分割等大量计算机视觉任务中取得了很大的进展。Over-parameterized的深层神经网络可以产生令人印象深刻的性能,但同时也会消耗巨大的计算资源。有效的块设计、张量分解、剪枝、蒸馏和量化是使网络高效的常用技术。设计新的网络体系结构在很大程度上依赖于人类专家的知识和经验,并可能在取得有意义的结果之前进行许多试验。为了加速这一过程并使其自动化,提出了网络体系结构搜索(NAS),并且在各种任务中,所学习的体系结构已经超过了人类设计的体系结构。然而,这些搜索方法通常需要大量的计算资源来搜索性能可接受的体系结构。
虽然[Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for image classifier architecture search. AAAI, 2019]的一些实验表明,进化算法发现了比基于RL的方法更好的神经结构,但由于每个个体的评估过程,即进化算法中的神经网络被独立地评估,EA的搜索成本要昂贵得多。 此外,可能有一些架构在搜索空间中的性能非常差。 如果我们直接遵循ENAS提出的权重共享方法,超级网络必须被训练以补偿那些更糟糕的搜索空间。 有必要对现有的进化算法进行改革,以实现高效而准确的神经结构搜索。
3.相关工作
架构优化步骤包括基于RL、基于EA和基于梯度的方法。基于RL的方法使用递归网络作为网络体系结构控制器,并利用生成的体系结构的性能作为训练控制器的奖励。控制器在训练过程中收敛,最终输出性能优越的体系结构;基于EA的搜索架构方法借助进化算法,每个个体的验证精度被用作进化下一代的适应度;基于梯度的方法将网络体系结构视为一组可学习的参数,并通过标准的反向传播算法对参数进行优化。
考虑到多个互补目标,即精度、参数数量、FLOPs、能量和延迟,没有一个体系结构在所有目标上超过所有其他体系结构。因此,Pareto前沿的体系结构是理想的。 提出了许多不同的工作来处理多目标网络体系结构搜索。 在速度和精度上,NEMO和MNAS网络目标。 DPPNet和LEMONADE考虑与设备相关和与设备无关的目标。 MONAS的目标是精确和能量。 NSGANet考虑FLOPs和准确性。
这些方法对于单独优化模型的效率较低。相反,我们的体系结构优化和参数优化步骤是交替进行的。此外,还共享了不同体系结构的参数,使搜索阶段更加高效。
论文使用基因算法(GA)来进行结构进化,GA能提供很大的搜索空间。在结构优化阶段,种群内的结构根据论文提出的pNSGA-III方法逐步更新。为了加速,使用一个超网用来为不同的结构共享权重,能够极大地降低个体训练的计算量。
Parameter Optimization
参数



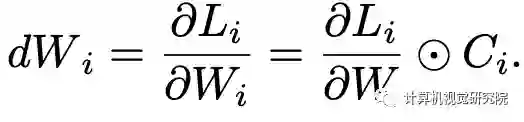
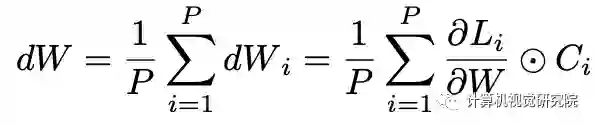
任何层都只能由在前向期间使用该层的网络进行优化。通过采集种群中个体的梯度,通过SGD算法更新参数W。由于在SuperNet中保持了一组具有共享权重的大型体系结构,借用了随机梯度下降的思想,并使用小批量体系结构来更新参数。累积所有网络的梯度将需要大量的时间进行一步梯度下降,因此我们使用小批处理架构来更新共享权重。
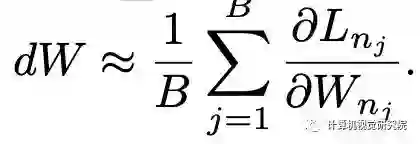
因此,将一小批体系结构上的梯度作为所有P个不同个体的平均梯度的无偏近似。每次更新的时间成本可以大大降低,适当的小批量大小可以在效率和准确性之间取得平衡。
Architecture Optimization

对于结构的优化过程,使用NSGA-III算法的non-dominated排序策略进行。标记



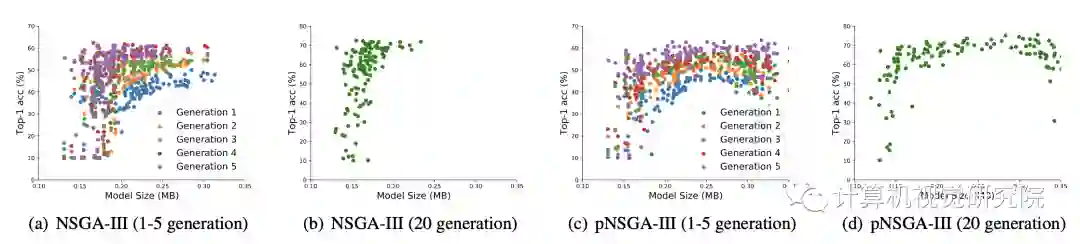
上图,使用NSGA-III和pNSGA-III的种群被可视化。如果我们使用NSGA-III来更新体系结构,就会遇到小模型陷阱问题。很明显,pNSGA-III可以在进化过程中保护大型模型,并提供广泛的模型。下一节介绍了更详细的讨论。
Continuous Evolution for CARS
总之,利用所提出的CARS pipeline搜索最优体系结构有两个步骤:1)网络结构优化,2)参数优化。此外,还引入了参数warm-up来更新参数。
Parameter Warmup,由于超网的共享权重是随机初始化的,如果结构集合也是随机初始化,那么出现最多的block的训练次数会多于其它block。因此,使用均分抽样策略来初始化超网的参数,公平地覆盖所有可能的网络,每条路径都有平等地出现概率,每种层操作也是平等概率,在最初几轮使用这种策略来初始化超网的权重。
Architecture Optimization,在完成超网初始化后,随机采样
个不同的结构作为父代,
为超参数,后面pNSGA-III的筛选也使用。在进化过程中生成
个子代,
是用于控制子代数的超参,最后使用pNSGA-III从
中选取
个网络用于参数更新。
Parameter Optimization,给予网络结构合集,使用公式3进行小批量梯度更新。




Search Time Analysis
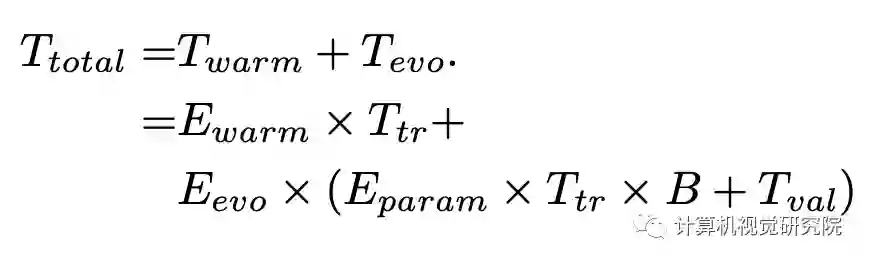
 ,验证耗时
,验证耗时
 ,warmup共
,warmup共
 周期,共需要
周期,共需要
 时间来初始化超网
时间来初始化超网
 的参数。假设进化共
的参数。假设进化共
 轮,每轮参数优化阶段对超网训练
轮,每轮参数优化阶段对超网训练
 周期,所以每轮进化的参数优化耗时
周期,所以每轮进化的参数优化耗时
 ,
,
 为mini-batch大小。结构优化阶段,所有个体是并行的,所以搜索耗时为
为mini-batch大小。结构优化阶段,所有个体是并行的,所以搜索耗时为
 。CARS的总耗时如上公式。
。CARS的总耗时如上公式。
5.实验
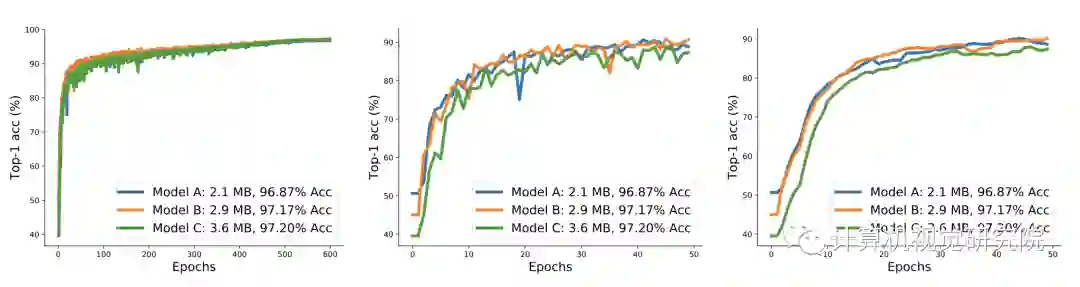
训练了3个不同大小的模型,在训练600轮后,模型的准确率与其大小相关,从前50轮的曲线可以看出小模型陷阱的原因:
小模型准确率上升速度较快;
小模型准确率的波动较大。
在前50轮模型C一直处于下风,若使用NSGA算法,模型C会直接去掉了,这是需要使用pNSGA-III的第一个原因。对于模型B和C,准确率增长类似,但由于训练导致准确率波动,一旦模型A的准确率高于B,B就会被去掉,这是需要使用pNSGA-III的第二个原因。
在完成CARS算法搜索后,保留128个不同的网络,进行更长时间的训练,然后测试准确率。
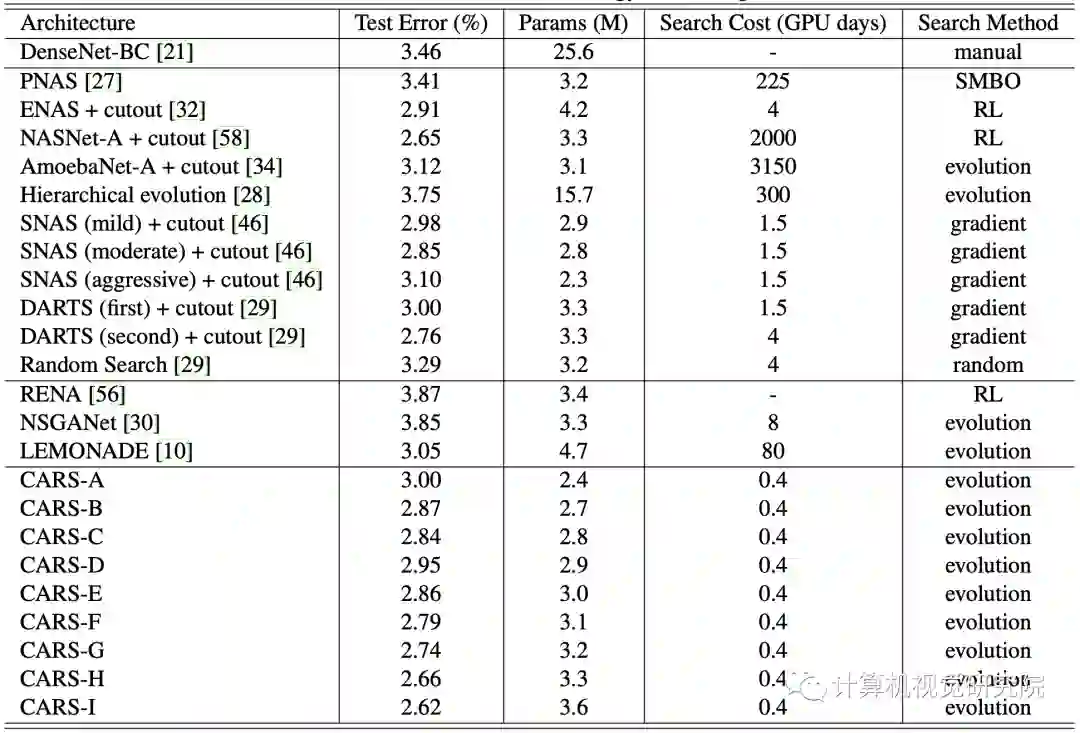
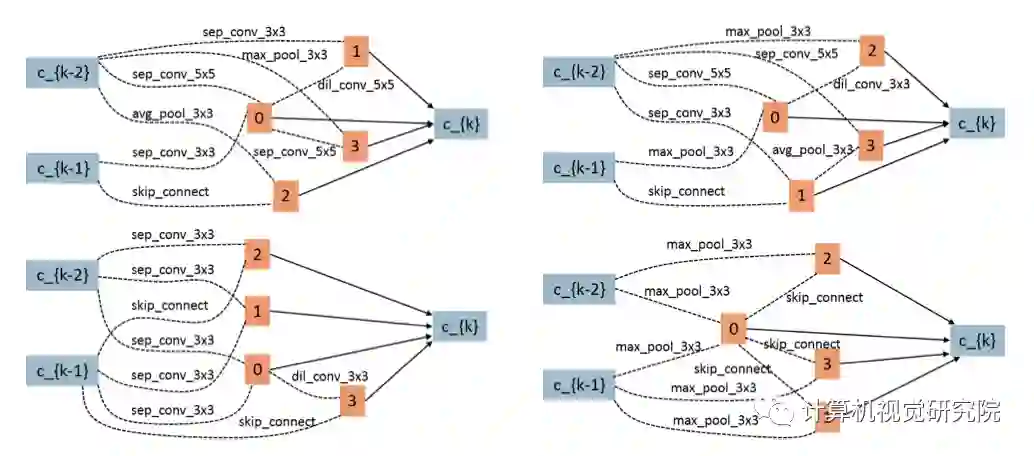
CARS-H与DARTS参数相似,但准确率更高,CARS-H的reduction block包含更多的参数,而normal block包含更少的参数,大概由于EA有更大的搜索空间,而基因操作能更有效地跳出局部最优解,这是EA的优势。
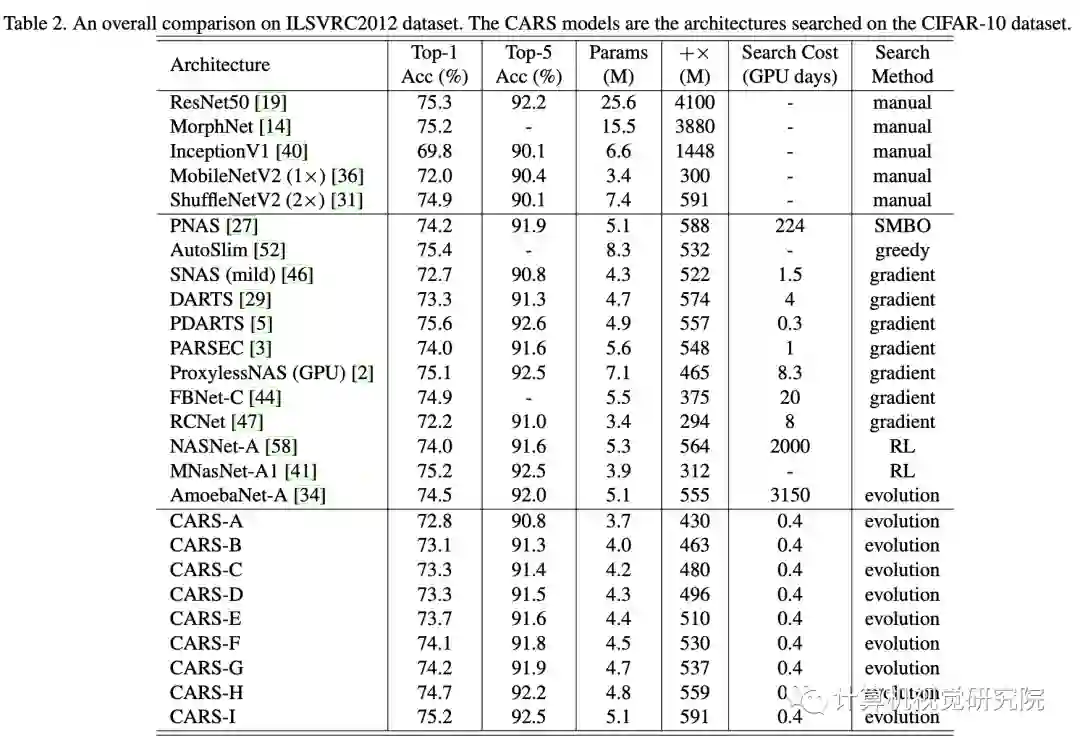
将在CIFAR-10上搜索到网络迁移到ILSVRC22012数据集,结果表明搜索到的结构具备迁移能力。

扫码关注我们
公众号 : 计算机视觉战队
关注回复:华为加速,获取源码


