资源 | 谷歌开源AdaNet:基于TensorFlow的AutoML框架
由极市、机器之心和中科创达联合举办的“2018计算机视觉最具潜力开发者榜单”评选活动,现已接受报名,杨强教授、俞扬教授等大牛嘉宾亲自评审,高通、中科创达、微众银行等大力支持,丰厚奖励,丰富资源,千万渠道,助力您的计算机视觉工程化能力认证,提升个人价值及算法变现。极市与您一起定义自己,发现未来~点击阅读原文即可报名~
谷歌开源了基于 TensorFlow 的轻量级框架 AdaNet,该框架可以使用少量专家干预来自动学习高质量模型。据介绍,AdaNet 在谷歌近期的强化学习和基于进化的 AutoML 的基础上构建,快速灵活同时能够提供学习保证(learning guarantee)。重要的是,AdaNet 提供通用框架,不仅能用于学习神经网络架构,还能学习集成架构以获取更好的模型。
相关论文:
AdaNet: Adaptive Structural Learning of Artificial Neural Networks
论文地址:
http://proceedings.mlr.press/v70/cortes17a/cortes17a.pdf
Github 项目地址:
https://github.com/tensorflow/adanet
教程 notebook:
https://github.com/tensorflow/adanet/tree/v0.1.0/adanet/examples/tutorials
结合不同机器学习模型预测的集成学习在神经网络中得到广泛使用以获得最优性能,它从其悠久历史和理论保证中受益良多,从而在 Netflix Prize 和多项 Kaggle 竞赛等挑战赛中取得胜利。但是,因其训练时间长、机器学习模型的选择要求领域专业知识,它们在实践中并不那么常用。而随着算力、深度学习专用硬件(如 TPU)的发展,机器学习模型将越来越大,集成技术也将越发重要。现在,想象一个工具,它能够自动搜索神经架构,学习将最好的神经架构集成起来构建高质量模型。
刚刚,谷歌发布博客,开源了基于 TensorFlow 的轻量级框架 AdaNet,该框架可以使用少量专家干预来自动学习高质量模型。AdaNet 在谷歌近期的强化学习和基于进化的 AutoML 的基础上构建,快速灵活同时能够提供学习保证(learning guarantee)。重要的是,AdaNet 提供通用框架,不仅能用于学习神经网络架构,还能学习集成架构以获取更好的模型。
AdaNet 易于使用,能够创建高质量模型,节省 ML 从业者在选择最优神经网络架构上所花费的时间,实现学习神经架构作为集成子网络的自适应算法。AdaNet 能够添加不同深度、宽度的子网络,从而创建不同的集成,并在性能改进和参数数量之间进行权衡。
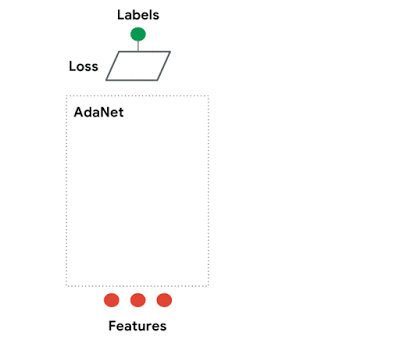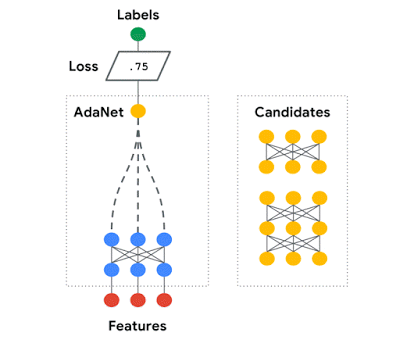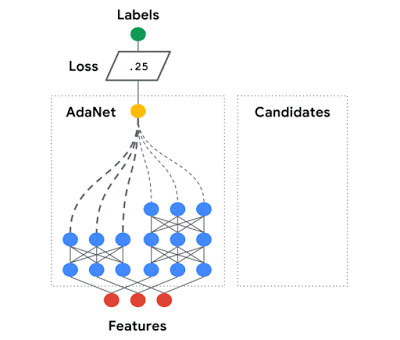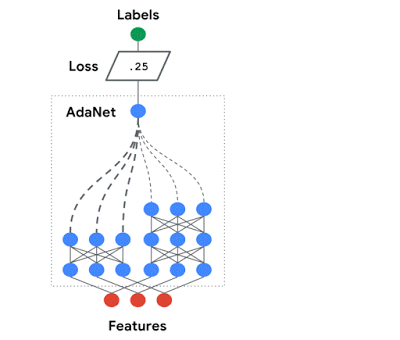
AdaNet 适应性地增长集成中神经网络的数量。在每次迭代中,AdaNet 衡量每个候选神经网络的集成损失,然后选择最好的神经架构进入下一次迭代。
快速易用
AdaNet 实现了 TensorFlow Estimator 接口,通过压缩训练、评估、预测和导出极大地简化了机器学习编程。它整合如 TensorFlow Hub modules、TensorFlow Model Analysis、Google Cloud』s Hyperparameter Tuner 这样的开源工具。它支持分布式训练,极大减少了训练时间,使用可用 CPU 和加速器(例如 GPU)实现线性扩展。
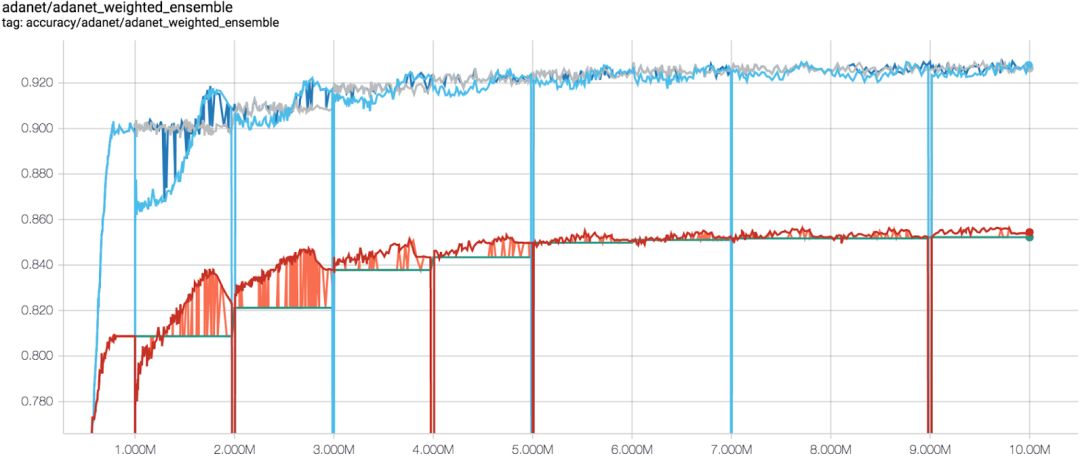
AdaNet 在 CIFAR-100 上每个训练步(x 轴)对应的准确率(y 轴)。蓝线是训练集上的准确率,红线是测试集上的性能。每一百万个训练步开始一个新的子网络,最终提高整个集成网络的性能。灰色和绿色线是添加新的子网络之前的集成准确率。
TensorBoard 是 TensorFlow 最好的功能之一,能够可视化训练过程中的模型指标。AdaNet 将 TensorBoard 无缝集成,以监控子网络的训练、集成组合和性能。AdaNet 完成训练后将导出一个 SavedModel,可使用 TensorFlow Serving 进行部署。
学习保证
构建神经网络集成存在多个挑战:最佳子网络架构是什么?重复使用同样的架构好还是鼓励差异化好?虽然具备更多参数的复杂子网络在训练集上表现更好,但也因其极大的复杂性它们难以泛化到未见过的数据上。这些挑战源自对模型性能的评估。我们可以在训练集分留出的数据集上评估模型表现,但是这么做会降低训练神经网络的样本数量。
不同的是,AdaNet 的方法是优化一个目标函数,在神经网络集成在训练集上的表现与泛化能力之间进行权衡。直观上,即仅在候选子网络改进网络集成训练损失的程度超过其对泛化能力的影响时,选择该候选子网络。这保证了:
集成网络的泛化误差受训练误差和复杂度的约束。
通过优化这一目标函数,能够直接最小化这一约束。
优化这一目标函数的实际收益是它能减少选择哪个候选子网络加入集成时对留出数据集的需求。另一个益处是允许使用更多训练数据来训练子网络。
AdaNet 目标函数教程:
https://github.com/tensorflow/adanet/blob/v0.1.0/adanet/examples/tutorials/adanet_objective.ipynb
可扩展
谷歌认为,创建有用的 AutoML 框架的关键是:研究和产品使用方面不仅能够提供合理的默认设置,还要让用户尝试自己的子网络/模型定义。这样,机器学习研究者、从业者、喜爱者都能够使用 tf.layers 这样的 API 定义自己的 AdaNet adanet.subnetwork.Builder。
已在自己系统中融合 TensorFlow 模型的用户可以轻松将 TensorFlow 代码转换到 AdaNet 子网络中,并使用 adanet.Estimator 来提升模型表现同时获取学习保证。AdaNet 将探索他们定义的候选子网络搜索空间,并学习集成这些子网络。例如,采用 NASNet-A CIFAR 架构的开源实现,把它迁移到一个子网络,经过 8 次 AdaNet 迭代后提高其在 CIFAR-10 上的当前最优结果。此外,获得的模型在更少参数的情况下获得了以下结果:

在 CIFAR-10 数据集上,NASNet-A 模型的表现 vs 结合多个小型 NASNet-A 子网络的 AdaNet 的表现。
通过固定或自定义 tf.contrib.estimator.Heads,用户可以使用自己定义的损失函数作为 AdaNet 目标函数的一部分来训练回归、分类和多任务学习问题。
用户也可以通过拓展 adanet.subnetwork.Generator 类别,完全定义要探索的候选子网络搜索空间。这使得用户能够基于硬件扩大或缩小搜索空间范围。子网络的搜索空间可以简单到复制具备不同随机种子的同一子网络配置,从而训练数十种具备不同超参数组合的子网络,并让 AdaNet 选择其中一个进入最终的集成模型。
来源:机器之心
原文地址:
https://ai.googleblog.com/2018/10/introducing-adanet-fast-and-flexible.html
*推荐阅读*
微软开源的深度学习模型转换工具MMdnn
资源 | 一个基于PyTorch的目标检测工具箱,商汤联合港中文开源mmdetection
DeepMind开源图深度学习(GraphDL)工具包,基于Tensorflow和Sonnet
杨强教授、俞扬教授等大牛嘉宾评审团,万元大奖,丰富资源,助力您的计算机视觉工程化能力认证,点击阅读原文即可报名“2018计算机视觉最具潜力开发者榜单”~




