在 TensorFlow Lite 中优化 MobileDet 目标检测模型

文 / Sayak Paul,Google Developer Expert
今年,来自威斯康星大学麦迪逊分校和 Google 的研究人员发表了他们在 MobileDet 上所做的研究工作。他们在 MobileDet 的研究中提出了一种架构理念,用于设计专门在 DSP、Edge TPU 等移动加速器上运行的目标检测器。在加速推理时间相同的情况下,MobileDet 在 COCO 目标检测任务中的表现,相比 MobileNetV2+SSDLite 和 MobileNetV3+SSDLite 架构得到了重大提升。长话短说,如果您打算在移动应用中使用目标检测模型,那么 MobileDets 将会是一个非常不错的选择。
MobileDet
https://arxiv.org/abs/2004.14525
-
针对移动 CPU 进行优化 -
针对 EdgeTPU 进行优化 针对 DSP 进行优化
其中每个变体都包含预训练检查点、与 TensorFlow Lite (TFLite) 兼容的模型计算图、TFLite 模型文件、配置文件以及计算图协议。这些模型已使用 COCO 数据集进行预训练。
在本文中,我将回顾使用预训练模型检查点进行的 TFLite 转换以及在此过程中出现的一些重要事项。这部分内容主要是对我和 Khanh LeViet 在这个 GitHub 话题中分享的研究结果的一些延伸。
GitHub 话题
https://github.com/ml-gde/e2e-tflite-tutorials/issues/21
这篇文章中涉及的代码将在此处以 Colab Notebook 的形式提供。
重要说明:如果您想使用自己的数据集训练 MobileDet 模型,则这些 Notebook 可能会对您有所帮助。您可以从中了解如何准备数据集、如何使用数据集微调 MobileDet 模型以及如何利用 TFLite 优化经过微调的模型。
Colab Notebook
https://colab.research.google.com/github/sayakpaul/Adventures-in-TensorFlow-Lite/blob/master/MobileDet_Conversion_TFLite.ipynbNotebook
https://github.com/sayakpaul/E2E-Object-Detection-in-TFLite/tree/master/colab_training
为什么又发布一篇关于模型转换的文章?
这是一个好问题。毕竟,现在已经有很多出色的示例和教程向大家介绍如何在 TFLite 中使用训练后量化 API 执行模型转换。我们使用 TensorFlow (TF) 1 来训练 TFOD API 代码库中的 MobileDet 模型。因此如果您想使用最新的 TFLite 转换器对其进行转换,您会发现无法直接实现该转换。
此外,对于 EdgeTPU 和 DSP 变体,也有一些要注意的地方。这些变体有两种精度格式:uint8 和 float32。精度为 uint8 的模型在训练时使用的是训练时量化 (QAT) 方法,而 float32 模型在训练时则未使用此方法。在 QAT 过程中,伪量化节点会插入到模型的计算图中。因此,正如我们马上将看到的那样,在 TFLite 转换过程中我们通常需要格外注意使用 QAT 训练的模型。
如果我们想将基于单步多框检测器 (SSD) 的模型转换成 TFLite,则必须首先生成一张与 TFLite 运算符集兼容的冻结图(依据以下指南:TF1 和 TF2)。TFOD API 团队提供了可用于此操作的常用脚本(TF1、TF2)。这两个脚本均向模型图添加了经过优化的后处理运算。现在,在 int8 精度中尚不支持这些运算。因此,如果您想使用全整数量化来转换这些预训练检查点,您觉得自己会采用什么方法?
指南 [TF1]
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tensorflowlite.md指南 [TF2]
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tf2.md脚本 [TF1]
https://github.com/tensorflow/models/blob/master/research/object_detection/export_tflite_ssd_graph.py脚本 [TF2]
https://github.com/tensorflow/models/blob/master/research/object_detection/export_tflite_graph_tf2.py全整数量化
https://tensorflow.google.cn/lite/performance/post_training_quantization#full_integer_quantization
现在,希望我已经能够让您确信这篇文章要讨论的不仅仅只是与 TFLite 中常规模型转换有关的内容。我们将在后续章节中讨论的情况也可能有助于您创建 TFLite 生产模型。
简单的转换
在我们探索有趣内容之前,让我们先从无需通宵便可完成的转换开始。基于动态范围和 float16 量化的转换便属于这一类别。
动态范围
https://tensorflow.google.cn/lite/performance/post_training_quant
重要说明:MobileDet 的 EdgeTPU 和 DSP 变体需要在各自对应的硬件加速器上运行。这些加速器需要具有全整数精度的模型。因此,利用动态范围和 float16 量化转换 EdgeTPU 和 DSP 变体并没有任何实际用途。
据此,我们将仅使用 CPU 变体进行基于动态范围和 float16 量化的转换。该变体可在此处找到(名称为 ssd_mobiledet_cpu_coco)。在使用 untar 解压模型软件包后,我们将得到以下文件:
├── model.ckpt-400000.data-00000-of-00001
├── model.ckpt-400000.index
├── model.ckpt-400000.meta
├── model.tflite
├── pipeline.config
├── tflite_graph.pb
└── tflite_graph.pbtxt
此处
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md#mobile-models
model.ckpt 开头的文件是 COCO 数据集上的预训练检查点。如果您基于自己的数据集训练 MobileDet 目标检测模型,则此步骤得到的将是您自己的模型检查点文件。tflite_graph.pb 文件是与 TFLite 运算符集兼容的冻结推理图,导出自预训练模型检查点。model.tflite 文件是从 tflite_graph.pb 冻结图转换而来的 TFLite 模型。
如果您想使用自己的数据集训练 MobileDet 模型,则可以参考以下代码获取 TFLite 冻结图文件(基于上文中提到的这份指南):
$ PIPELINE_CONFIG="checkpoint_name/pipeline.config"
$ CKPT_PREFIX="checkpoint_name/model.ckpt-400000"
$ OUTPUT_DIR="tflite_graph"
$ python models/research/object_detection/export_tflite_ssd_graph.py \
--pipeline_config_path=$PIPELINE_CONFIG \
--trained_checkpoint_prefix=$CKPT_PREFIX \
--output_directory=$OUTPUT_DIR \
--add_postprocessing_op=true
您可以在上文中提到的 Colab Notebook 中看到完整示例。如果一切顺利,您应将冻结图文件导出到 OUTPUT_DIR 中。接下来,我们继续进行 TFLite 模型转换的部分。
Colab Notebook
https://colab.research.google.com/github/sayakpaul/Adventures-in-TensorFlow-Lite/blob/master/MobileDet_Conversion_TFLite.ipynb
在 TensorFlow 2 中,动态范围量化的代码如下所示:
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(
graph_def_file=model_to_be_quantized,
input_arrays=['normalized_input_image_tensor'],
output_arrays=['TFLite_Detection_PostProcess',
'TFLite_Detection_PostProcess:1',
'TFLite_Detection_PostProcess:2',
'TFLite_Detection_PostProcess:3'],
input_shapes={'normalized_input_image_tensor': [1, 320, 320, 3]}
)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
-
model_to_be_quantized对应着冻结图文件。 参考冻结图文件设置
input_arrays和input_shapes。正如我们在下图中所见,这些值已正确设置。
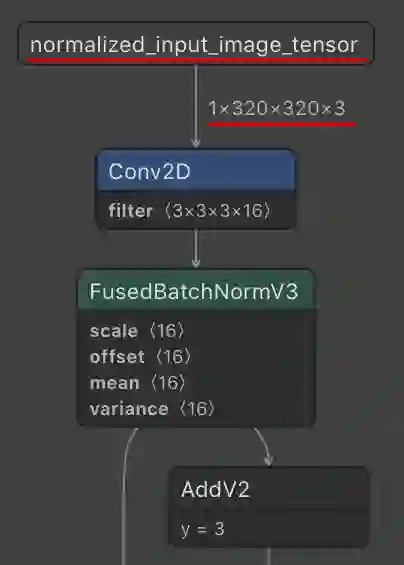
根据此指南中提供的说明设置
output_arrays。这些运算代表四个数组:detection_boxes、detection_classes、detection_scores和num_detections,对于任何常用的目标检测器来说,这些通常都是必需的数组。此指南
https://github.com/tensorflow/models/blob/master/research/object_detection/export_tflite_ssd_graph.py
如果您对 TFLite 中典型的训练后量化过程已经有所了解,则应该会对上述展示的代码中其余的部分感到熟悉。对于 float16 量化,所有代码都将保持不变;我们只需在调用 convert() 之前添加此代码行:converter.target_spec.supported_types = [tf.float16]。
动态范围量化模型的大小为 4.3 MB,而 float16 量化模型的大小为 8.2 MB。我们稍后将了解在使用和不使用不同加速器的情况下,此模型在实际的移动设备上的运行速度。
针对 MobileDet 的更复杂的 TFLite 转换
在本章节中,我们将针对 MobileDet 的三种不同变体处理全整数量化。与 TFLite 支持的其他量化格式相比,全整数量化通常更复杂。
代表性数据集
我们进行全整数量化的第一步是准备代表性数据集。我们需要对激活范围进行校准,以便量化模型能够尽可能地保持原始模型的性能。出于本文章的需要,我从 COCO 训练数据集(train2014 分块)中采样了 100 张图像。根据我的经验,包含 100 个样本的代表性数据集通常就足以够用。我将这些图像托管在了此处,以便于您在需要时使用。
COCO 训练数据集
https://cocodataset.org/#download此处
https://github.com/sayakpaul/Adventures-in-TensorFlow-Lite/releases/tag/v0.9.0
下方列出的代码表示一个生成器函数,可用于向 TFLite 转换器生成预处理图像:
rep_ds = tf.data.Dataset.list_files("train_samples/*.jpg")
HEIGHT, WIDTH = 320, 320
def representative_dataset_gen():
for image_path in rep_ds:
img = tf.io.read_file(image_path)
img = tf.io.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
resized_img = tf.image.resize(img, (HEIGHT, WIDTH))
resized_img = resized_img[tf.newaxis, :]
yield [resized_img]
请注意,这些预处理步骤应该与使用 TFLite 模型运行推理之前应用的实际预处理步骤同步。如果您有兴趣详细了解更为复杂的代表性数据集生成器,那么此 Notebook 对您而言将会很有帮助。
Notebook
https://github.com/sayakpaul/Adventures-in-TensorFlow-Lite/blob/master/Magenta_arbitrary_style_transfer_model_conversion.ipynb
另请注意,EdgeTPU 和 DSP 变体的动态范围及 float16 量化并没有多少实际用途。下一章节将仅介绍这些不同变体的全整数量化以及转换过程中要考虑的细枝末节。
在转换过程中处理伪量化节点
下图表示的是 uint8 EdgeTPU 模型计算图的一部分。以红色突出显示的节点是由 QAT 机制插入的。在 uint8 DSP 模型计算图中,您也会看到相同种类的节点。
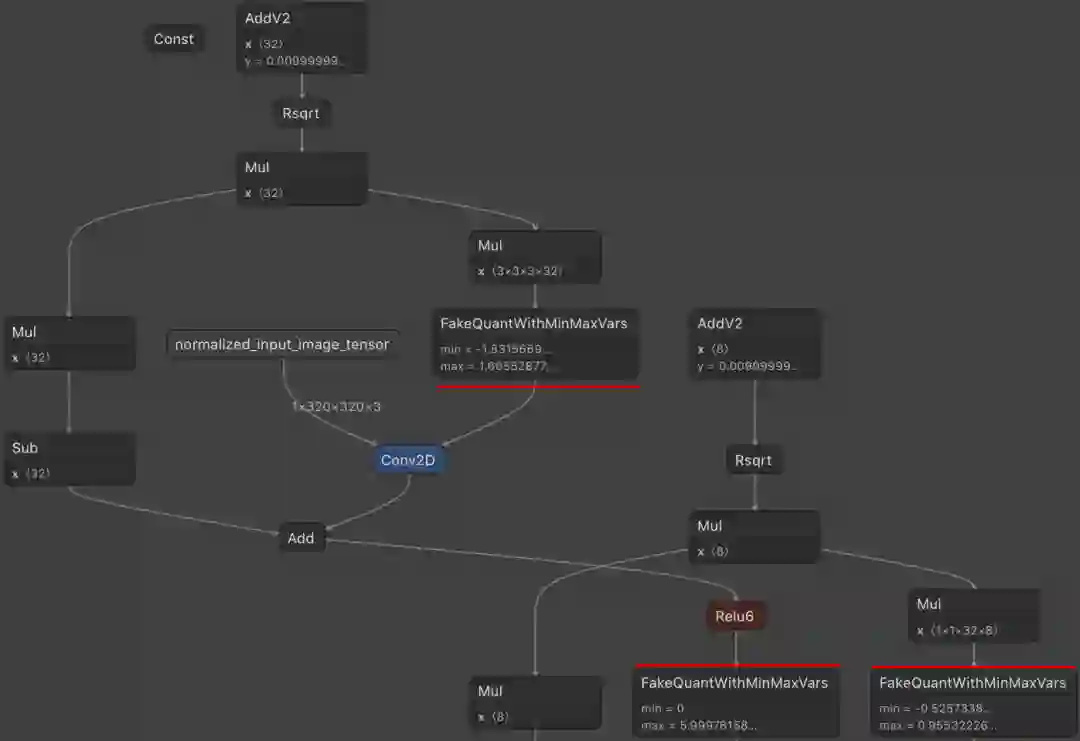
这些节点具有一些我们需要在转换过程中考虑的重要影响:
在 QAT 过程中,我们已对激活范围进行估算,即 QAT 与训练过程中的训练后量化类似,并且还会相应地调整激活范围。因此,我们不需要为基于全整数量化的转换提供代表性数据集。
这些伪节点通常都具有整数精度。因此,设置优化选项 (
converter.optimizations) 可能会导致出现不一致问题。如需使用全整数量化转换
uint8模型,我们需要将 TFLite 模型的输入和输出数据类型设置为整数精度(通常为uint8或int8)。根据此文档,我们还需要在转换过程中指定quantized_input_stats参数。要让已转换的 TFLite 模型将量化输入值映射到实际值,则需要执行此操作。如需了解更多详情,请点击此处。文档
https://tensorflow.google.cn/api_docs/python/tf/compat/v1/lite/TFLiteConverter#attributes此处
https://tensorflow.google.cn/lite/performance/quantization_spec
那么,我们如何用代码实现所有这些功能呢?
converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(
graph_def_file=model_to_be_quantized,
input_arrays=['normalized_input_image_tensor'],
output_arrays=['TFLite_Detection_PostProcess',
'TFLite_Detection_PostProcess:1',
'TFLite_Detection_PostProcess:2',
'TFLite_Detection_PostProcess:3'],
input_shapes={'normalized_input_image_tensor': [1, 320, 320, 3]}
)
converter.inference_input_type = tf.uint8
converter.quantized_input_stats = {"normalized_input_image_tensor": (128, 128)}
tflite_model = converter.convert()
如果您认为与上文展示的代码相比,这些代码看起来没有那么复杂,那么您的感觉是对的,它们不需要很复杂!该工具应该能够帮助您顺利完成这些操作。但是,要在您的项目开发过程中获取这些详细信息并不容易。请注意,我们未指定 converter.inference_output_type。稍等片刻,我们将很快讲到此内容。
在成功执行后,我们会得到两个全整数量化模型,其中 EdgeTPU 模型为 4.2 MB,而 DSP 模型为 7.0 MB。
CPU 变体和 float32 精度模型的整数量化
对于不包含伪量化节点(CPU 和所有具有 float32 精度的模型)的变体,转换过程会相对更简单一些。请记住,EdgeTPU 和 DSP 变体有两种不同精度:uint8 和 float32。例如,float32 精度模型的相关代码如下:
converter.representative_dataset = representative_dataset_gen
converter.inference_input_type = tf.uint8
converter.optimizations = [tf.lite.Optimize.DEFAULT]
请注意,我们在代码中指定了代表性数据集,是因为 float32 精度模型不是使用 QAT 训练的。对于 CPU 变体模型,这几行代码略有更改:
converter.inference_input_type = tf.uint8
converter.quantized_input_stats = {"normalized_input_image_tensor": (128, 128)}
converter.optimizations = [tf.lite.Optimize.DEFAULT]
坦率地讲,这一配置是我通过反复试验才发现的。我观察到,如果我指定代表性数据集,则它会对已转换模型的预测产生负面影响。另外,我还发现指定 converter.quantized_input_stats 可以帮助改进已转换模型的预测。
在此示例中,我们也未指定 converter.inference_output_type。我们现在开始指定吧。
在转换过程中处理非整数后处理算子
请记住,TFOD API 团队提供的冻结图导出器脚本会向计算图中添加经过优化的后处理运算。整数精度尚不支持这些运算。因此,即使您想将 converter.inference_output_type 指定为 tf.uint8,也很可能会遇到以下错误:
RuntimeError: Unsupported output type UINT8 for output tensor 'TFLite_Detection_PostProcess' of type FLOAT32.
这正是我们没有设置 converter.inference_output_type 参数的原因。
如果您想要转换 TFOD API 团队提供的 MobileDet 模型,这应该可以解决您可能遇到的所有问题。在最后两个章节中,我们将看到这些转换后的模型的运行情况,以及它们在各自对应的硬件加速器上的执行速度。
结果展示
对于 CPU 变体模型,其 float16 量化后的 TFLite 模型提供了相当不错的结果:

在 Colab 上,此特定模型的推理时间约为 92.36 毫秒。我尝试了不同的阈值来滤除弱预测,在阈值为 0.3 时得到了最佳结果。在我们讨论的几个不同模型中,这些结果具有非常高的一致性。
对于 EdgeTPU 和 DSP 变体,这里有一点需要特别注意,由于它们专门针对不同的硬件加速器优化,因此在 Colab 上它们转换后的对应模型会慢得多。
建议您通过上文中提到的 Colab Notebook 来亲自试用不同的转换后模型并查看这些结果。
模型基准测试
在本章节中,我们将解决以下问题:“我该如何在这么多的模型中选择?”您可以手动试用所有模型,看看哪个模型在您选择的运行环境中表现最佳。但是,更实用的方法是先在一组设备上使用 TFLite 基准测试工具对这些模型进行基准测试,然后再做出相应决定。
下表全面总结了有关不同 TFLite MobileDet 模型的运行环境的重要统计数据。这些结果是使用上文中提到的 TFLite 基准测试工具生成的。
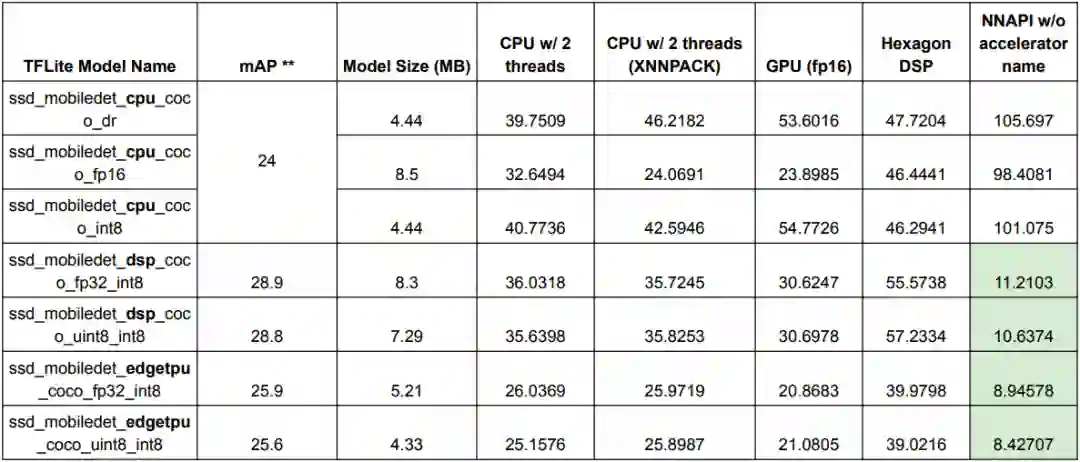
* 使用的设备:Pixel 4(推理计时以毫秒为单位)
** 相关报告请参阅此处
TFLite 基准测试工具生成
https://tensorflow.google.cn/lite/performance/measurement此处
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md
我们可以看到,在使用合适的硬件加速器的情况下,DSP EdgeTPU 变体的表现非常突出。对于 CPU 变体,如果是 GPU 加速的运行环境,则 float16 量化后的 TFLite 模型可以带来额外的速度提升。
这里有一个小问题,那就是 Pixel 设备不允许第三方应用使用 Hexagon DSP,因此即便我们指示基准测试工具使用该 DSP,模型也会回退到 CPU 进行执行。因此要获得 DSP 变体的真实基准测试结果,我们应该考虑在提供 Hexagon DSP 并允许第三方应用使用的设备(例如,Samsung Galaxy S9+)上运行基准测试工具。
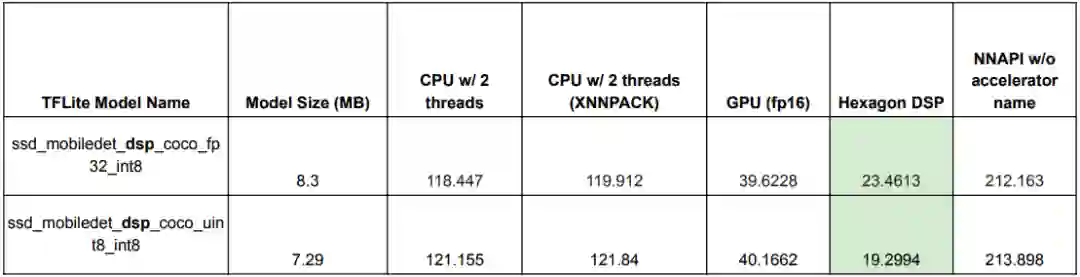
* 使用的设备:Samsung Galaxy S9+(推理计时以毫秒为单位)
结论
在本文中,我们讨论了在 TFLite 中转换 MobileDet 模型的不同变体时可能会遇到的一些复杂问题。我非常喜欢 TFLite 的一点在于它提供了解决此类实际问题的所需工具。
感谢 Khanh 在我撰写本文时给予了全面的指导。感谢 Martin Andrews 提出的文字编辑建议。
— 推荐阅读 —

了解更多请点击 “阅读原文” 访问官网。
分享 💬 点赞 👍 在看 ❤️
以“三连”行动支持优质内容!



