TensorFlow 首个优化工具来了:模型压缩4倍,速度提升3倍!
来源:medium,新智元

今天,TensorFlow发布了一个新的优化工具包:一套可以让开发者,无论是新手还是高级开发人员,都可以使用来优化机器学习模型以进行部署和执行的技术。
这些技术对于优化任何用于部署的TensorFlow模型都非常有用。特别是对于在内存紧张、功耗限制和存储有限的设备上提供模型的TensorFlow Lite开发人员来说,这些技术尤其重要。
关于TensorFlow Lite,这里有更多教程:https://www.tensorflow.org/mobile/tflite/

优化模型以减小尺寸,降低延迟和功耗,同时使精度损失可以忽略不计
这次添加支持的第一个技术是向TensorFlow Lite转换工具添加post-training模型量化(post-training quantization)。对于相关的机器学习模型,这可以实现最多4倍的压缩和3倍的执行速度提升。
通过量化模型,开发人员还将获得降低功耗的额外好处。这对于将模型部署到手机之外的终端设备是非常有用的。
post-training quantization技术已集成到TensorFlow Lite转换工具中。入门很简单:在构建了自己的TensorFlow模型之后,开发人员可以简单地在TensorFlow Lite转换工具中启用“post_training_quantize”标记。假设保存的模型存储在saved_model_dir中,可以生成量化的tflite flatbuffer:
1converter=tf.contrib.lite.TocoConverter.from_saved_model(saved_model_dir)
2converter.post_training_quantize=True
3tflite_quantized_model=converter.convert()
4open(“quantized_model.tflite”, “wb”).write(tflite_quantized_model)
我们提供了教程详细介绍如何执行此操作。将来,我们的目标是将这项技术整合到通用的TensorFlow工具中,以便可以在TensorFlow Lite当前不支持的平台上进行部署。
教程:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/tutorials/post_training_quant.ipynb
post-training 量化的好处
模型大小缩小4倍
模型主要由卷积层组成,执行速度提高10-50%
基于RNN的模型可以提高3倍的速度
由于减少了内存和计算需求,预计大多数模型的功耗也会降低
有关模型尺寸缩小和执行时间加速,请参见下图(使用单核心在Android Pixel 2手机上进行测量)。
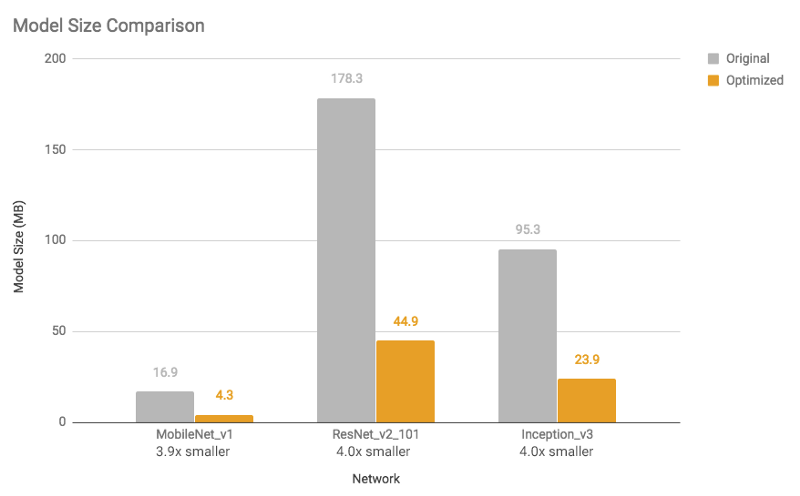
图1:模型大小比较:优化的模型比原来缩小了4倍
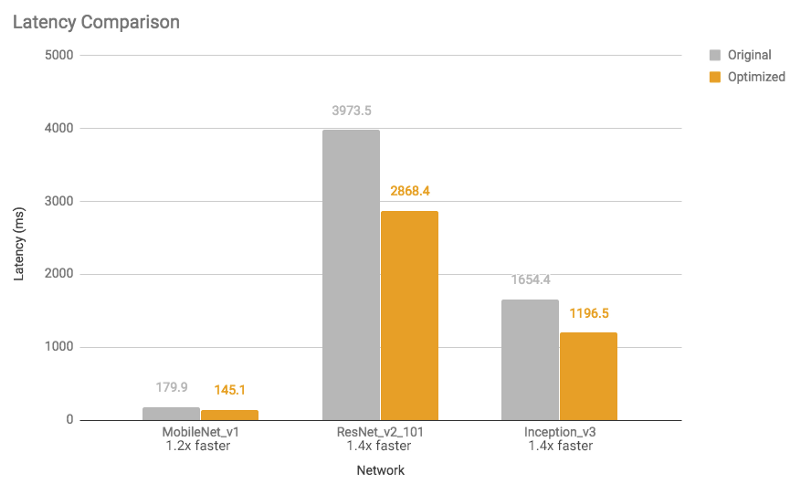
图2:延迟比较:优化后的模型速度提高了1.2到1.4倍
这些加速和模型尺寸的减小对精度影响很小。一般来说,对于手头的任务来说已经很小的模型(例如,用于图像分类的mobilenet v1)可能会发生更多的精度损失。对于这些模型,我们提供预训练的完全量化模型(fully-quantized models)。
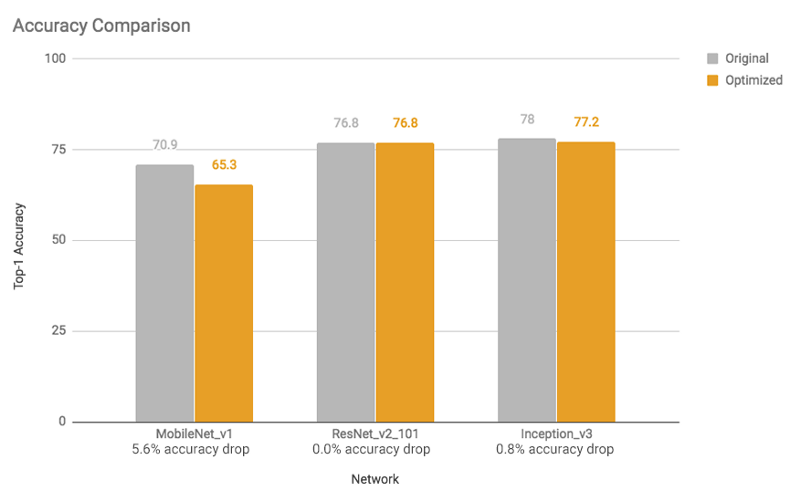
图3:精度比较:除 mobilenets外,优化后的模型的精度下降几乎可以忽略不计
我们希望在未来继续改进我们的结果,请参阅模型优化指南以获得最新的测量结果。
模型优化指南:
https://www.tensorflow.org/performance/model_optimization
在底层,我们通过将参数(即神经网络权重)的精度从训练时的32位浮点表示降低到更小、更高效的8位整数表示来运行优化(也称为量化)。 有关详细信息,请参阅post-training量化指南。
post-training量化指南:
https://www.tensorflow.org/performance/post_training_quantization
这些优化将确保将最终模型中精度降低的操作定义与使用fixed-point和floating-point数学混合的内核实现配对。这将以较低的精度快速执行最繁重的计算,但是以较高的精度执行最敏感的计算,因此通常会导致任务的最终精度损失很小,甚至没有损失,但相比纯浮点执行而言速度明显提高。
对于没有匹配的“混合”内核的操作,或者工具包认为必要的操作,它会将参数重新转换为更高的浮点精度以便执行。有关支持的混合操作的列表,请参阅post-training quantizaton页面。
我们将继续改进post-training量化技术以及其他技术,以便更容易地优化模型。这些将集成到相关的TensorFlow工作流中,使它们易于使用。
post-training量化技术是我们正在开发的优化工具包的第一个产品。我们期待得到开发者的反馈。
原文链接:
https://medium.com/tensorflow/introducing-the-model-optimization-toolkit-for-tensorflow-254aca1ba0a3?linkId=57036398
点击“ 阅读原文 ”进入AI学院学习





