知识库问答中的关系识别研究回顾

知识库是用于知识管理的特殊数据库,通常由大量三元组构成,三元组形如(奥巴马,出生于,火奴鲁鲁),三者分别是三元组的 subject、predicate 和 object(主语、谓词和宾语),其中谓词也可被称作关系。
知识库问答尝试构建利用知识库信息的问答系统,关系识别是知识库问答中的重要环节,即识别出自然语言问题中所提及的知识库谓词(关系),将自然语言描述与知识库中的谓词联系起来。本文盘点近年来部分关于知识库问答关系识别的研究。
表述形式多样:例如“be famous for”和“known for”两个短语,虽然在字面上的相似度很低,但实际上在语义上相近。关系的描述不同于实体,可能不局限于短语的形式,还可能是由包含连词、介词等的搭配描述。
隐式关系可能需要推断,例如“Which Americans have been on the moon?” 其中 Americans 表示一个针对“出生”的额外的约束,但句中没有“is born”这类显式的约束。
含义与上下文相关:同一谓词在不同的语境中可能表示不同的含义,需要我们在识别关系时利用整个句子的上下文信息。
测试集中的未知关系:在训练模型时,训练集中包含的关系数量总是有限的,测试集中可能包含大量模型没有学习过的关系。
-
正负样本的生成:对于一个句子,正确的关系链接结果可能只有数个,而关系链接工具却可能产生远超过这个数量的错误的关系链接候选作为负样本。对于一个分类模型,如何平衡正负样本的数量,如何提升负样本的质量,值得讨论。
而当前关系识别的基本思路,大体上至少包括:
-
谓词词典:词典即通过算法生成或人工编写的数据,可直接为关系识别的算法所用。在 NLP 研究中,有单词到单词的词典,短语到短语的词典,但此处特指的是谓词到短语的词典。 神经网络方法:相比词典而言,神经网络方法具有更好的模糊匹配和应对未知输入的能力。
需要注意的是,无论是谓词词典还是神经网络方法,它们的构建都是基于有限的谓词信息,对于没有见过或者没有学习过的关系,识别的性能可能会相对下降,且不同的方法所适用的知识库也可能是不同的。而对于神经网络方法来说,经过预训练的词嵌入模型能够提供一定的超越训练数据的泛化能力。
简单问答系统中的关系识别模型
词嵌入方法在关系识别中的应用
谓词词典在关系识别中的应用
未知关系的识别

-
实体链接:通过字符级 CNN 将事实候选中的主语实体与问题中的实体描述进行匹配。 谓词链接:通过单词级 CNN 将该事实中的谓语与问题进行匹配。
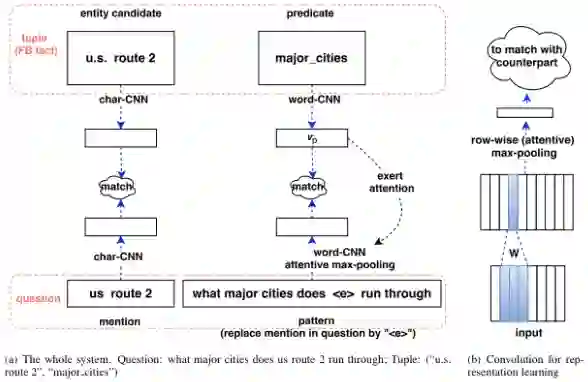
使用 CNN 处理文本,尤其应对形态多变的关系描述,存在着固有的缺陷:关系的描述可能并不局限在一个文本的局部,长距离依赖是可能存在的,且长度不便预估。
不过,个人认为即使作者通过消融实验说明利用残差学习的双层 Bi-LSTM 能够取得更好的效果,却很难从除参数规模以外的方面解释双层网络在问题理解上的优势。
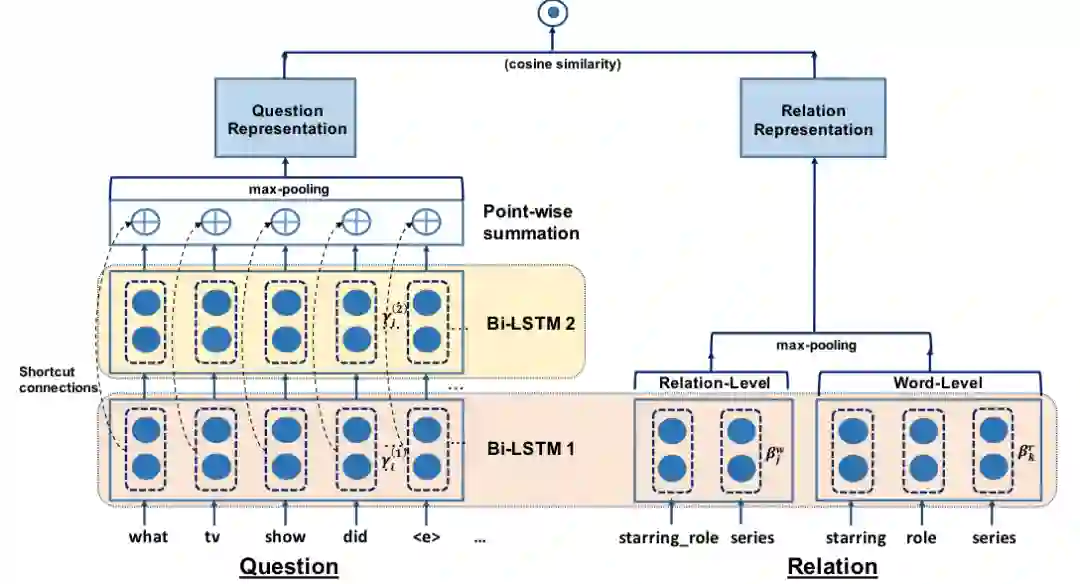

词嵌入方法在关系识别中的应用
BiLSTM-Softmax:标准的 BiLSTM softmax 分类器预测问题属性,输出范围覆盖训练过程中见过的所有属性
BiLSTM-KB:预测与预训练 KB 嵌入中最接近的谓词表示匹配的谓词低维表示
BiLSTM-Binary:二元决策,判断一对(主体,谓词)是否匹配给定问题
-
FastText-Softmax:使用 FastText 作为分类器预测属性
简单的结论是,作者认为 FastText 提供了更好的效果。FastText 是一个使用神经网络的词嵌入方法,表现出相对 BiLSTM 的各类方法的优越性。
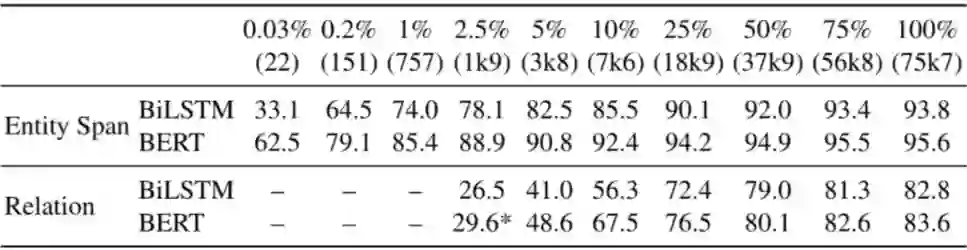
可见,关系识别相比于实体的识别,对于数据量的要求更加严苛,而在相同数据量的情况下使用 BERT 的表现总是好于 BiLSTM。词嵌入与预训练模型的一个优势在于能引入外部的语言知识,来弥补有限的训练数据。

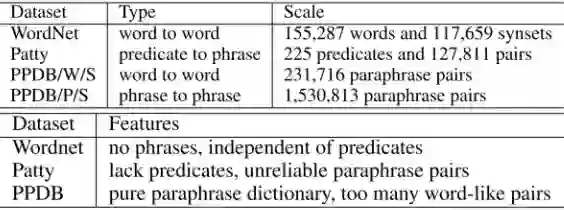
个人认为,即使通过大量运算和人工构建词典,并不断优化内容,一个好的词典对关系识别任务的影响也停留在量上的进步,对于一个有一定关系识别能力的问答系统,引入词典或许仅仅是一种辅助手段。词典存在容量限制,若要维护其与时俱进更是需要成本。
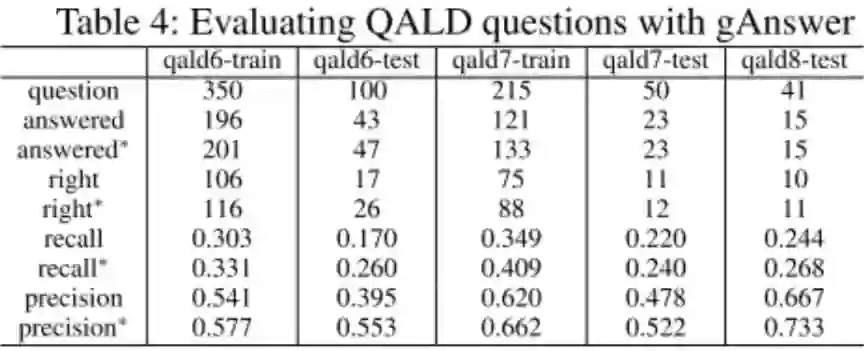

未知关系的识别
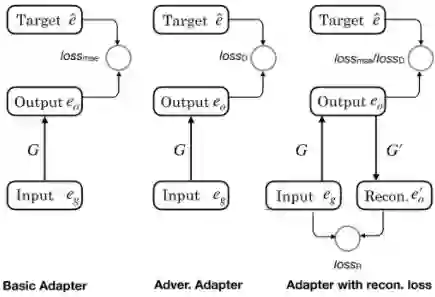
在设计完适配器后,其关系识别模型的整体架构类似于前文所述的分层 RNN 模型。
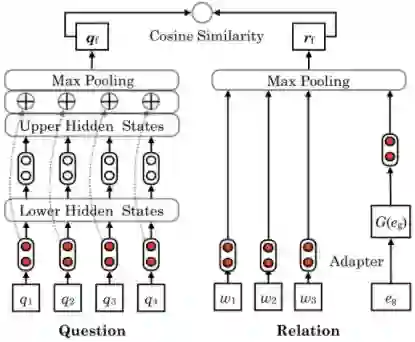

小结
另外,现有的部分方法中,对自然语言问题的表示和对关系的表示是分离的,将这二者分别学习出表示再进行匹配与评分,不妨考虑如何通过注意力等模型找出问题中的关键信息,再与关系进行匹配。
联系我
很期待能与各位对知识图谱或问答系统有兴趣的同学交流学习(别忘了备注呀,谢谢)。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





