文澜:超大规模多模态预训练模型!
导读
近年来,BERT等预训练语言模型在多类自然语言处理任务上取得了显著的性能提升,从而极大地改写了研究范式。随着OpenAI超大规模语言模型GPT-3的发布,预训练语言模型在自然语言理解能力上再次被推至新的高峰。
AI江湖里早已风起云涌,年初发布的CLIP和DALL·E模型,即多模态版本的GPT-3,更是展现出了惊人的语言理解和图像生成能力,刷爆了研究人员们的朋友圈。
处于AI浪潮中的你,一次次地见证着这些划时代的工作诞生。你是否期待着,当视觉和语言碰撞时,预训练模型还会为我们带来哪些新的惊喜?
赶快来围观这个最新发布的多模态预训练模型吧!
为了更进一步地推动相关领域的研究,北京智源人工智能研究院、中国人民大学和中科院计算所的研究团队在中国人民大学高瓴人工智能学院执行院长文继荣教授的带领下合作开展了大规模中文多模态预训练模型的研究,并发布了第一代悟道·文澜,旨在发掘预训练模型在中文通用多模态数据上的理解能力。
现阶段的“文澜”已初具规模,具备强大的视觉-语言检索能力和一定的常识理解能力。在“文澜”多模态模型的基础上,团队还开发了应用《AI心情电台》,可以为图像搭配符合意境的歌曲。

论文地址:
https://www.zhuanzhi.ai/paper/58ed10aeda3dacf6874d9d4dd3d3ce24
多模态首页:
https://model.baai.ac.cn/model/wl
模型特点及优势
多模态预训练模型通常可以归类为以下两种网络结构:如UNITER的单塔结构,和如CBT、VilBERT和ERNIE-VIL的双塔结构。
从2020年9月开始,通过一系列的实验和探索,文澜的研发团队独立提出了基于多模态对比学习的双塔结构,跟2021年1月发布的OpenAI CLIP在模型结构上不谋而合。
文澜团队推出的第一代图文互检模型在论文中叫做BriVL (Bridging Vision and Language),BriVL具有如下四个特点和优势。
1. 基于视觉-语言弱相关的假设
现有的大量多模态预训练模型,特别是单塔结构,往往会采用如下强假设:对于输入的数据,图像与文本之间存在较强的语义相关性。例如,对于下面这张蛋糕的图片,会假设在多模态数据集中对应“水果蛋糕上有一些蜡烛在燃烧”这样描述性的文本。

正是有了语义相关性上的强假设,单塔结构才能在词汇与局部图像特征之间进行模态交互。但遗憾的是,在实际应用场景中,上述的强假设往往并不成立,比如视觉与语言之间通常只有较抽象的关联。例如,对于蛋糕的照片,配的文字可以是“生日快乐,许个愿吧”,也可以引申到“哎,我的减肥大计又泡汤了”。
文澜的研发者们进行了一系列的实验和探索,实验结果表明,在开放获取(例如互联网上的公开数据)的图文数据集上,简单的双塔结构要优于单塔结构。因此,BriVL采用了双塔结构作为多模态预训练模型的基本架构。
2. 将多模态与对比学习算法相结合
基于双塔结构的预训练模型网络结构比较简单,需要弥补神经网络在表达能力上的损失。近两年来,自监督学习有着飞速的进展,对比学习被发现可以用来提高神经网络的表达能力。
基于这一点,文澜的开发团队将对比学习引入到了BriVL的双塔结构中。不同于CLIP,对于给定的某一对图文数据,BriVL同时使用了视觉模态和语言模态去构建该图文数据的负样本,并且基于MoCo的思想扩大负样本数目,从而进一步提高神经网络的表达能力。
3. 网络结构灵活,方便实际部署
BriVL首先使用了独立的语言和视觉编码器提取语言和视觉信息的特征向量,然后将这些向量传入到对比学习模块中进行训练。采用这样的双塔结构,可以很方便地把编码器模块替换为最新的单模态预训练模型,从而可以持续地增强模型表达的能力。
在训练完毕后,BriVL可以对外提供获取图像和语言的向量特征的API,便于在下游任务中部署。特别地,与向量检索引擎的结合可以极大地提高图文检索效率。
此外,BriVL模型也可以再融入其他的预训练任务,例如图像caption任务等。
4. 目前最大的中文多模态通用预训练模型
文澜团队使用RUC-CAS-WenLan多源图文数据集对BriVL进行预训练。
RUC-CAS-WenLan是文澜团队构建的超大规模预训练数据集,该多源图文数据集来自网页用户产生的图文数据。文澜团队的数据组从互联网获取原始数据后,对数据进行了一系列的清洗工作,从而构建了包含5500万对图文数据的RUC-CAS-WenLan通用多模态数据集。RUC-CAS-WenLan的内容十分丰富,涵盖了新闻,体育,娱乐,文化,生活等多个主题。
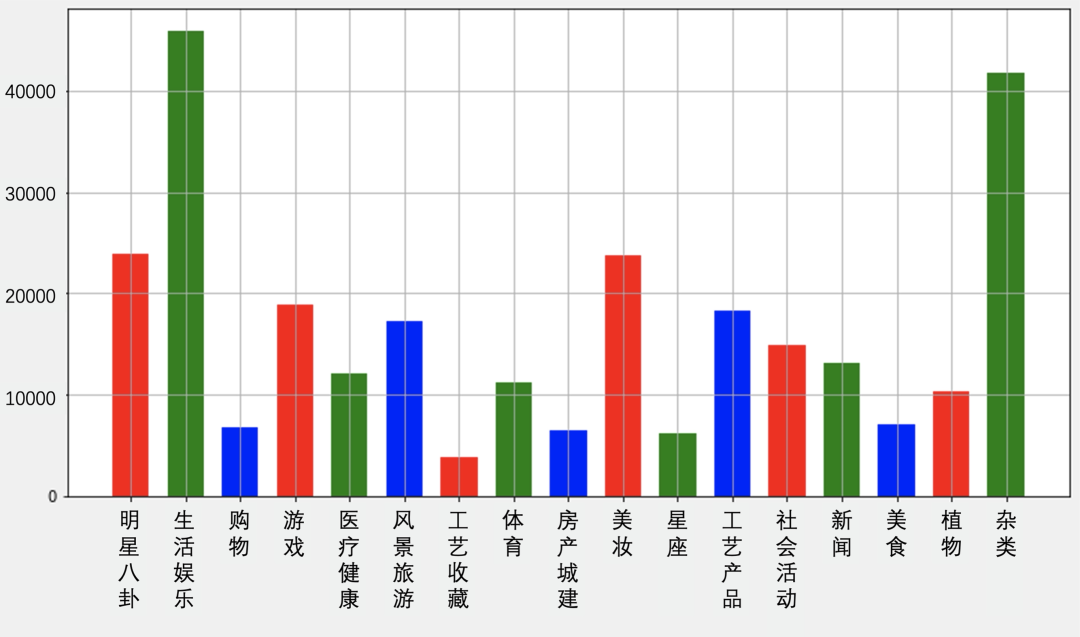
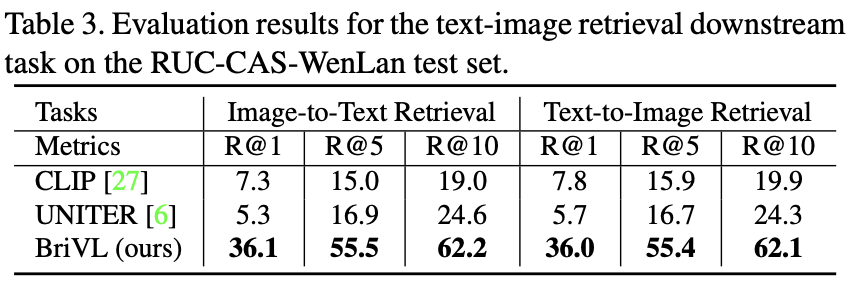
第一代文澜使用了3000万对图文数据,训练得到的BriVL模型的初始版本有10亿参数量,此阶段的BriVL模型在RUC-CAS-WenLan测试集和AIC-ICC测试集上的性能均超过了UNITER和CLIP。
在未来,文澜团队将使用5亿级别的图文数据作为预训练数据集,BriVL的参数量将达到百亿级别。
模型基本架构
BriVL模型是基于图文互检预训练任务设计的,采用了如下图所示的基础架构。
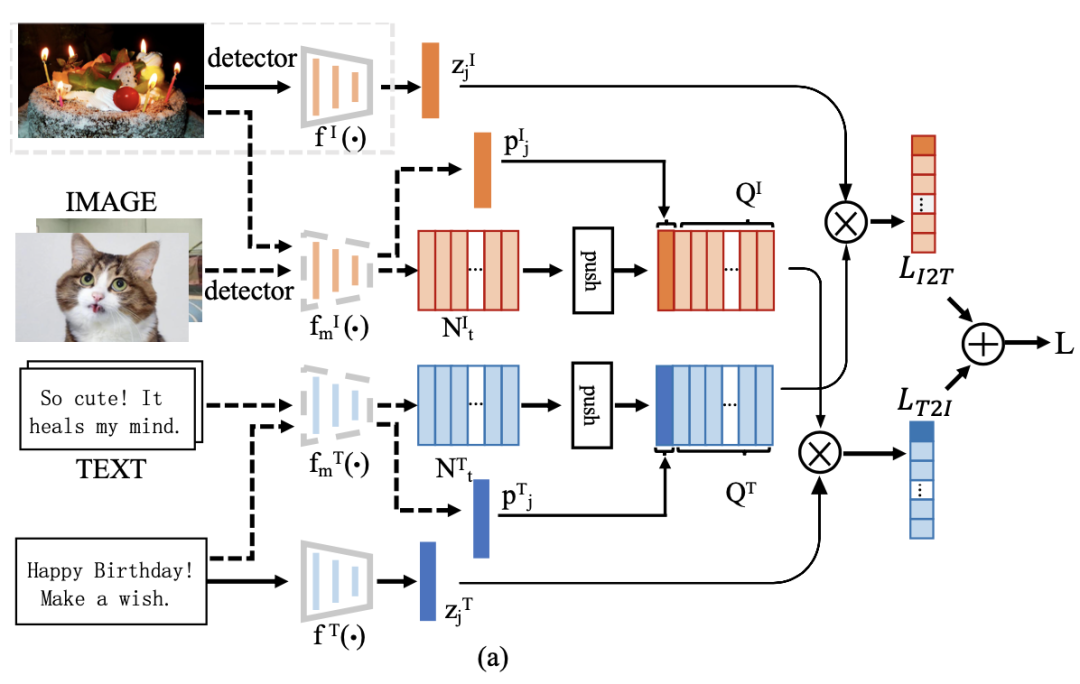
图文互检模型BriVL结构示意图
针对图文互检预训练任务,BriVL模型采用了双塔结构。具体地,先使用图像目标检测器去提取图像数据的Bounding Box,再使用这些Bounding Box对经过图像编码器的特征图进行空间上的池化,得到图像特征序列。文本数据也会经过文本编码器进行特征提取。
在提取特征后,两个模态的序列特征被分别映射到了不同的语义空间,然后对这两个序列分别进行序列池化和多层感知机映射,从而得到它们在同一空间下的特征表示。
图文互检预训练任务使用了基于MoCo的多模态对比学习方法,优化处于同一特征空间下的双模态特征,使得对应的图文对在该特征空间下有一致的语义表示。在图像编码器部分,BriVL使用了EfficientNet-B7-NS模型和多层单模态的Transformer模型;在文本编码器部分,BriVL使用了RoBERTa-Large和多层单模态的Transformer模型。
基于上述图文编码器,文澜开发团队使用16台8卡*A100的GPU集群进行了7天的预训练,得到了最终的BriVL模型。在下一轮迭代中,文澜开发团队还会探索如何构建性能更强的文本编码器,以进一步提高其表达能力。
实验分析
1. AIC-ICC的评测结果
AIC-ICC是2017年由创新工场、搜狗、今日头条联合主办的首届AI Challenger全球AI挑战赛中发布的中文图像描述数据集。文澜团队以AIC-ICC公开数据集为基础,进行了一系列的消融和对比实验,并取得两项突破性的结果:
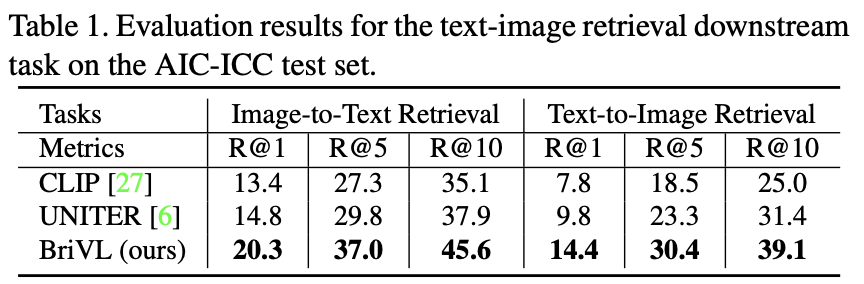
(1)在图文互检的任务上,BriVL的性能优于UNITER和CLIP:图检索文与文检索图的结果均明显超过UNITER和CLIP,且检索速度是UNITER的20倍,与CLIP速度相当。在与OPENAI-CLIP的比较过程中,由于CLIP未放出预训练数据,只给了测试模型与接口,文澜研发团队便采取将测试集用主流翻译软件翻译成英文再调用其接口得到特征向量的做法,以最大程度公平比较。
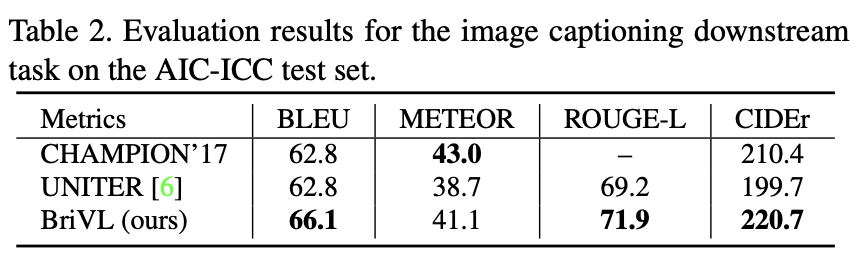
(2)在图生成文任务上,以四个指标的综合评价,文澜BriVL在公开评测集AIC-ICC上超过了现有最高结果AI Challenger全球AI挑战赛的冠军,同时也超过了UNITER。
2. RUC-CAS-WenLan的评测结果
文澜团队最初就从RUC-CAS-WenLan中分离出了1.1万个图文对作为测试集,其余的用作训练。在测试集的图文互检任务上,文澜BriVL的性能均超过了UNITER和CLIP。
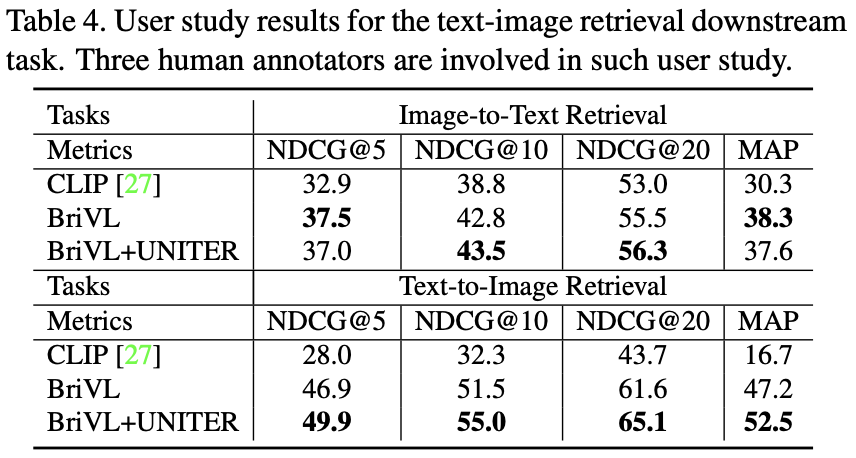
3. 非公开评测结果
针对图文互检任务,文澜团队还进行了非公开评测。给定一组文本和图像查询样例,为每个查询样例从候选集中挑选最好的30个结果,然后进行人工评分。选用三个人工进行标注,从而得到三组结果,每个查询样例有7个级别的打分,每组有30个打分。
通过计算NDCG和MAP,可以对该查询样例的30个打分进行评测,最终得到所有查询样例的平均结果。通过表4可以看出,文澜BriVL要优于CLIP。此外,若使用BriVL为UNITER选择候选集,UNITER能够在BriVL的基础上继续提高性能。
结果展示
1. 文本检索图像
用“航拍南京玄武湖秋色美若画卷”进行检索,返回结果如下:

query: 航拍南京玄武湖秋色美若画卷
2. 图像检索文本

用上面这张图片做query,返回的结果如下:
梨花开年复年,相思别处生又生;今日有酒今宵醉,何至年头憎恨春
像冬季清晨里的一抹阳光像夏季傍晚的凉风,像秋季午后凉爽的汽水,像春季凌晨犹如浩瀚宇宙一般的天空,你是我的心小鹿乱撞的原因。
嘿嘿!小编的品味还不错吧。接下来是真人女头像。小仙女们请拿去食用!
殿下一族吧是由小吧主天魔舞梦创建的。主要由天魔舞梦、赤黑烁、幻冥黑白、赤黑之友发言。
《石楠小札》,收录于古风歌手 CcccEs 个人原创音乐专辑《不贰》,由小鱼萝莉填词,TetraCalyx 编曲,CcccEs 演唱。其发行时间为 2014 年 08 月 21 日。
3. 下游任务:基于图像的文本生成
BriVL在AIC-ICC+MSCoCo+Flickr30数据集上,以图片生成标题为任务,进行微调。生成的结果如下:

生成文本:一个穿着戏服的男人和一个穿着戏服的女孩在一起

生成文本:一条城市街道,有一个红绿灯,上面有一个标志
4. 下游任务:为图像打标签
用BriVL模型在动漫数据集danboru上进行微调,为动漫图像自动打标签,得到的结果如下所示:

灰色围巾,屋顶,双手插在口袋里,多云的天空,大衣
鸟,围巾,云,天空,长袖,微笑,长发

木栅栏,城镇,街道,房屋,道路,日落,建筑
风景,窗口,云,天空
下游应用
基于BriVL模型,可以开发多款跨模态应用。在BriVL的基础上,文澜团队开发了H5小应用《AI心情电台》。
布灵——为图片赋予音乐的灵魂
用户随便上传一张图片后,便会有一个可爱的小精灵——布灵,为用户配上一首符合意境的歌。《AI心情电台》是使用BriVL提取图像和文本特征,接着进行图文检索,将图片和歌词特征进行匹配,并将歌词准确定位到最符合图片特征的歌词位置。
《AI心情电台》期待做用户的灵魂DJ。
你是否怀疑过自己越想越不太可能
现在开始你会相信带着梦去旅行
让我看看你的瞳孔正在排练的电影
我听见你的心房跳动越靠近越大声
《you make me free》——张惠妹

整理旧照片泛黄的笑脸
记忆不断涌现湿热我的脸
铺木的街道无忧的年少
《小木马》——张信哲
随着动听的旋律,感受灵魂的对白,用图与音乐,交织梦与理想的绘卷。

据悉,布灵是诞生于中国人民大学高瓴人工智能学院的第一个AI,擅长视觉理解,是个在努力弄懂生活和内涵的AI小精灵。赶快来让小布灵为你选首歌曲吧!
文澜API文档
文澜团队对外开放了获取图像/文本embedding的API接口,供开发者调用。可以在以下地址获取API的调用文档:
https://model.baai.ac.cn/api
文澜研发团队介绍
文澜的研究团队由中国人民大学高瓴人工智能学院院长文继荣教授带领,主要人员包括:
指导教师:
文继荣 中国人民大学高瓴人工智能学院执行院长
卢志武 中国人民大学高瓴人工智能学院教授,博士生导师
宋睿华 中国人民大学高瓴人工智能学院长聘副教授
窦志成 中国人民大学高瓴人工智能学院副院长,北京智源人工智能研究院“智能信息检索与挖掘”方向项目经理
金 琴 中国人民大学信息学院教授,博士生导师
兰艳艳 现清华大学智能产业研究院研究员,曾中国科学院计算技术研究所研究员,博士生导师,北京智源人工智能研究院青年科学家
赵 鑫 中国人民大学高瓴人工智能学院长聘副教授,博士生导师,北京智源人工智能研究院青年科学家
参与学生:
数据组:刘沛羽、郑伟昊、侯丹阳、李英彦、杨越千、隰宗正、龚政、李军毅、赵一达、张良、金楚浩、高一钊、杨国兴
模型组:霍宇琦、胡安文、洪鑫、张曼黎、卢浩宇、高一钊、杨国兴、温静远、崔莞清、赵金明、张良、李瑞晨、赵一达、张恒、许宝贵
评测组:孙宇冲、宋宇晴、崔莞清、霍宇琦
应用组:刘光镇、郑伟昊、隰宗正、金楚浩
部分参考文献
[1] Wu, Z., Xiong, Y., Yu, S., & Lin, D. (2018). Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3733–3742).
[2] He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9729–9738).
[3] Chen, X., Fan, H., Girshick, R., & He, K. (2020). Improved baselines with momentum contrastive learningarXiv preprint arXiv:2003.04297.
[4] Morgado, P., Vasconcelos, N., & Misra, I. (2020). Audio-visual instance discrimination with cross-modal agreementarXiv preprint arXiv:2004.12943.
[5] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., & others (2020). Language models are few-shot learnersarXiv preprint arXiv:2005.14165.
[6] Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning (pp. 10709–10719).
[7] Chen, Y.C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., Cheng, Y., & Liu, J. (2020). Uniter: Universal image-text representation learning. In European Conference on Computer Vision (pp. 104–120).
[8] Li, X., Yin, X., Li, C., Zhang, P., Hu, X., Zhang, L., Wang, L., Hu, H., Dong, L., Wei, F., & others (2020). Oscar: Object-semantics aligned pre-training for vision-language tasks. In European Conference on Computer Vision (pp. 121–137).
[9] Alayrac, J.B., Recasens, A., Schneider, R., Arandjelovi\'c, R., Ramapuram, J., De Fauw, J., Smaira, L., Dieleman, S., & Zisserman, A. (2020). Self-supervised multimodal versatile networks. In Advances in Neural Information Processing Systems.
[10] Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., & others. Learning Transferable Visual Models From Natural Language SupervisionImage, 2, T2.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“WENLAN” 就可以获取《文澜:超大规模多模态预训练模型!》专知下载链接





