三大顶会看动态图表示学习
作者 | 王春辰
学校 | 北京邮电大学
研究方向 | 图神经网络及其应用
鉴于网络挖掘在现实生活中的丰富应用,以及近些年网络表示学习的兴起,网络嵌入已经成为学术界和工业界日益关注的研究热点。
网络嵌入的目的是将节点嵌入到低维空间中,同时捕捉网络的结构和性质。虽然已经提出了很多很有前途的网络嵌入方法,但大多数都是针对静态网络的。
动态网络相比于静态网络来说,强调了网络中节点和边的出现顺序和时间。因为现实中,是通过节点和边的顺序添加而形成的,这确实应该被视为一个有节点与其邻居之间交互事件驱动的动态过程。因此节点的邻域并不是同时形成的,观察到的快照网络结构应该是一段时间内邻域的累积。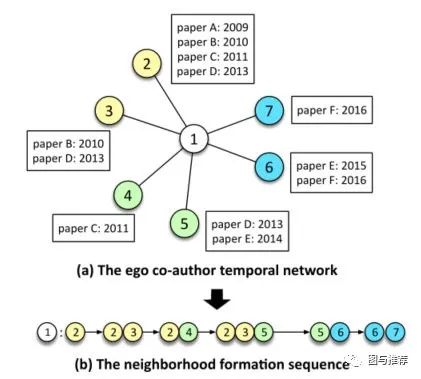
例如上图出示了一个作者的ego网络;节点1,以及其邻居,即节点2到6.从网络结构快照上来看只能看出网络最新的结构,而节点如何以及何时连接仍然是未知的事情。
本文主要介绍了以下几篇论文:
-
KDD2018 Embedding Temporal Network via Neighborhood Formation -
CIKM2019 Temporal Network Embedding with Micro- and Macro-dynamics -
ICLR2020 INDUCTIVE REPRESENTATION LEARNING ON TEMPORAL GRAPHS
KDD2018 Embedding Temporal Network via Neighborhood Formation
该文指出,在大多数实际网络中,节点之间的边通常是由顺序事件建立的,这些事件构成了所谓的时态网络。如Graph 1中合著者网络是由具有明确时间的合著论文驱动的。因此,本文将ego时间网络根据时间的定时展开成特定的邻居序列,如上图(b)所示。
本文中模型是基于多元Hawkes过程的邻域序列建模:
其中 表示x和y之间形成的边的事件的基本速率,而h是时间t之前的节点x的邻域形成序列中的历史目标节点。 表示历史邻域激发当前邻域y的程度,并且核函数 表示可以指数函数形式写入的时间衰减效应。
那么,在这里简单介绍一下Hawkes过程:
其中, 是特定事件的基本强度,显示在时间t的自发事件到达率; 是对过去历史对当前事件的时间衰减效应进行建模的核函数,其形式通常为指数函数。
霍克斯过程的条件强度函数表明,当前事件的发生不仅取决于上一个时间步长的事件,而且还受具有时间衰减效应的历史事件的影响。这种特性对于邻域形成序列的建模是期望的,因为当前的邻域形成可以受到较新事件的较高强度的影响,而在较长历史中发生的事件对目标邻域的当前出现的贡献较小。相关Hawkes process的文章清参见The Neural Hawkes Process: A Neurally Self-Modulating Multivariate Point Process https://arxiv.org/pdf/1612.09328v2.pdf
回到上述模型中来看, 表示历史邻域激发当前邻域y的程度。在这里文章中引入attention机制,文中使用Softmax定义源节点与其历史节点之间的权重,如下所示:
因此,历史邻居对当前目标的影响可以重新表述为:
CIKM2019 Temporal Network Embedding with Micro- and Macro-dynamics
Temporal Network Embedding with Micro- and Macro-dynamics CIKM2019 可以看做是在上述模型之上的扩展出的模型. 本文提出时间网络是无处不在的,它通常在微观和宏观动力学方面随着时间的推移而演变。微观动力学详细描述了网络结构的形成过程,而宏观动力学则是指网络规模的演化模式。本文提出了一种新的微观和宏观相结合的时态网络嵌入方法MMDNE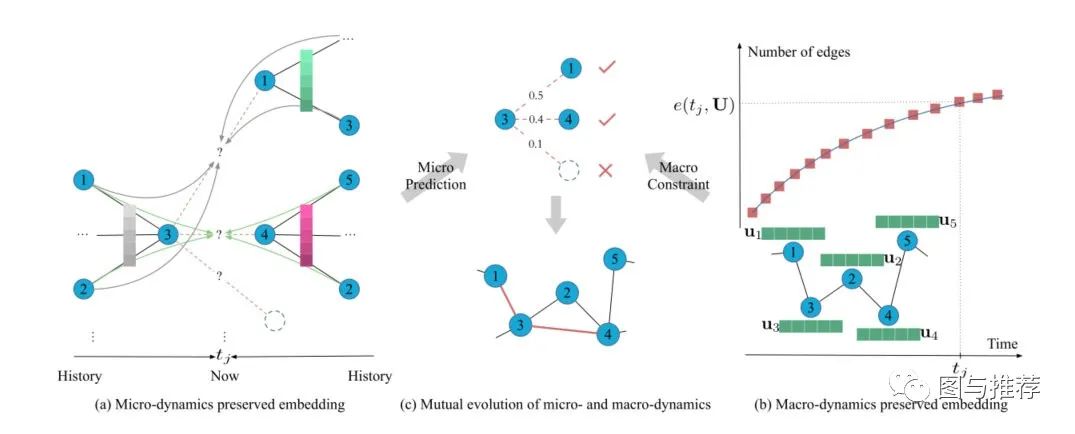
(a)微观动力学保存嵌入时序attention点过程。虚线表示要建立的边,不同颜色的实心箭头表示邻居对不同边的影响。垂直彩色矩形块代表attention机制,颜色越深,邻居的影响越大。(B)宏观动力学保留嵌入动力学方程,该方程用网络嵌入 (即绿色矩形块)和时间 参数化。在时间 ,MMDNE 宏观约束边数为 。(C)微观和宏观动力学以相互的方式演化和派生节点嵌入。在当前时间 ,通过从历史邻居(即 和 )微观预测, 链接节点 , 和 的概率分别为0.5、0.4和0.1;而宏观动力学根据网络规模的演化模式将新边的数量限制在只有2条。因此,MMDNE捕获了更精确的结构和时间属性。
本文中微观动力学模型由节点自身基本强度和来自双向历史邻居的历史影响组成,如下所示:
其中 是度量两个节点相似度的模型,这里定义为 。 和 分别是 和 在 之前的历史邻居。是具有依赖于节点且可学习的衰减率 的时间衰减函数。这里 和 是分层的attention。
如前所述,过去的事件对当前事件有所影响,这种影响可能与过去的事件有所不同。因为邻居的影响也是动态的,所以文中提出一种时态分层的attention来捕捉历史结构的非均匀和动态的影响。attention系数定义如下:
其中 是级联运算, 作为attention向量, 表示局部权重矩阵。
文中考虑到对于整个邻居的全局影响,这里是一个全局attention,文中用每个邻居的聚合来表示历史邻居来作为一个整体。考虑到全局衰减,文中对过去时间衰减进行平均。所以有如下定义:
其中, 是单层神经网络,他以邻居聚合嵌入和过去时间的平均时间衰减作为输入。
本文中宏观动力学描述的是网络规模的演化模式,通常服从明显的分布,即网络规模可以用一定的动力学方程来描述。此外,宏观动力学在更高的层次上约束了网络内部结构的形成,即它决定了到目前为止总共应该生成多少条边。给定一个时间网络 ,我们有时间t的累计节点数 ,对于每个节点 ,它在时间 以一个链接率 链接其他节点(例如,节点 )。根据网络演化的增密幂律,我们有平均可达邻居 ,其线性稀疏系数 和幂律稀疏指数 。因此,我们将涉及时间t处的新边的数量的宏观动力学定义如下:
其中 可以随着网络随时间 的演化而获得, 和 可通过模型优化来学习。
上面是通过Network Embedding的方法来进行时序网络建模。那么在图神经网络上是否也可以进行时序网络建模呢?
在GC-LSTM: Graph Convolution Embedded LSTM for Dynamic Link Prediction https://arxiv.org/abs/1812.04206 中提出采用GCN-LSTM的结构来将结构信息与时间信息相结合。同期还有采用GCN-GRU等架构。
ICLR2020 INDUCTIVE REPRESENTATION LEARNING ON TEMPORAL GRAPHS
论文链接: https://arxiv.org/abs/2002.07962
文中提到,时序图的演化特性要求处理新节点以及捕获时态模式。节点嵌入现在是时间的函数,它既要代表节点的静态特征,又要代表不断演变的拓扑结构。此外,节点和拓扑特征也可以是时态的,节点嵌入也应该捕获其模式。
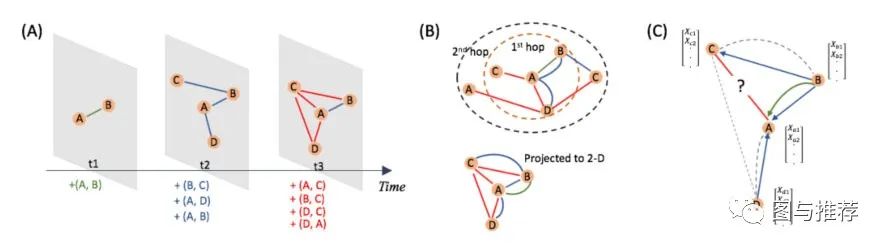
时间图中几个复杂情况的直观说明。(A)。时态图及其快照的生成过程。显然,快照中的静态图形只反映了部分时间信息。(B)。将时间图形投影到与时间无关的2-D平面时的最终状态。除了丢失时间信息外,还会出现多边缘情况。(C)。当在时间t3预测节点A和C之间的链路时,消息传递路径应该受到时间约束。实线给出了适当的方向,而虚线违反了时间约束。
下面我们来看本文的模型,文中提到一种特殊的时间函数编码。本文中的函数时间编码启发于self-attention机制。将self-attention中代表位置的vector用本文提到的时间函数编码替代,从而使整体带有时间属性。
下面来看本文中提到的时序图注意层: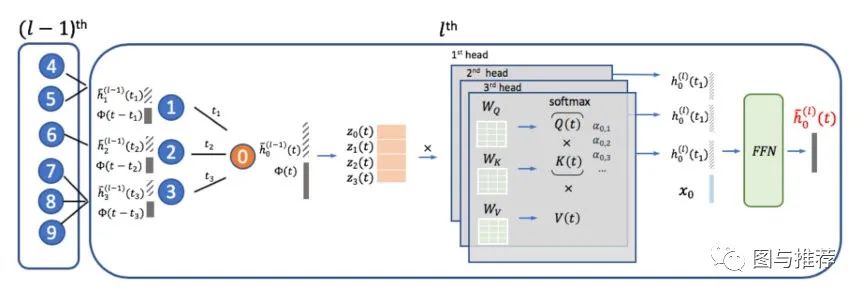
文中所设计的TGAT体系结构完全依赖于TGAT层。类似于GraphSage和GAT,TGAT层可以看成是一个局部聚集算子。
根据原有的自我注意机制,首先得到实体-时间矩阵,即输入
然后将其转发到三个不同的线性投影,用来获得‘query’,‘key’, ‘value’:
其中,适用于捕获事件编码和特征之间的交互的权重矩阵。
类比于self-attention,同理得到。
为了将邻域表示与目标节点特征相结合,文中采用了与GraphSAGE相同的做法,将邻域表示与目标节点特征向量连接。然后将其传给前馈网络:
其中, 是目标节点在时间 处的最终表示输出。
当然,为了推广的目的,文中还证明了TGAT层是可以很容易的拓展到多头设置。考虑来自多哥头的自我注意输出向量。我们将他们表示成一个组合向量,然后执行相同过程:
就像GraphSAGE一样,单个TGAT层聚合本地化的一跳邻域,通过堆叠 层TGAT,聚合扩展到 跳。
这里还有一篇相类似的文章推荐给大家DYNAMIC GRAPH REPRESENTATION LEARNING VIA SELF-ATTENTION NETWORKS ICLR2019 https://arxiv.org/abs/1812.09430
总结
近些年已经陆陆续续有很多关于动态网络建模或者动态链接预测的文章发表出来。无论是Network Embedding的方法,或是GCN+LSTM,亦或是将时序信息嵌入到GNN当中去,都是为了更好的捕捉时间信息对网络烟花的影响。我们希望不断探索,通过某种算法以更逼真的方式来模拟时序网络的演化过程,从而更能服务于我们的实际问题。
上述文章中如果有某些地方引用不准确我说明不准确的地方望大家包涵 ———— Thank you for reading



