如何构建线上线下一体化AI PaaS平台
11月30日至12月01日,UCloud受邀参加了由51CTO主办的“WOT2018 全球人工智能技术峰会”。作为推动人工智能务实创新的年度重要技术会议,UCloud与千余名参会者共聚一堂,不但探讨了如何让人工智能技术为行业赋能,还进行了题为《如何构建线上线下一体化AI PaaS平台》的主题分享。

下面是演讲内容的部分整理:
构建AI平台的技术挑战
在AI落地之前,大部分企业首先会面临的第一个挑战就是基础环境构建的复杂性:AI框架的多样选择,环境的诸多变量、硬件的诸多变量以及底层数据存储的诸多变量。以上这些交叉组合之后直接导致了一个情况:如果需要构建完整的一套软硬件组合的系统,而每一条业务线都有不同需求的时候,多环境维护就会变得异常痛苦。其次,需要在AI系统建设时考量算法的兼容性、平台的扩展性、弹性伸缩的能力、容灾能力等以应对平台的横向和纵向扩展。最后一点也是现在普遍出现的挑战,即公有云和私有云如何整合开发。
AI平台技术挑战的解决思路
针对以上三大技术挑战,主讲人UCloud AI平台技术专家宋翔博士向参会者提出了他的五大解决思路。
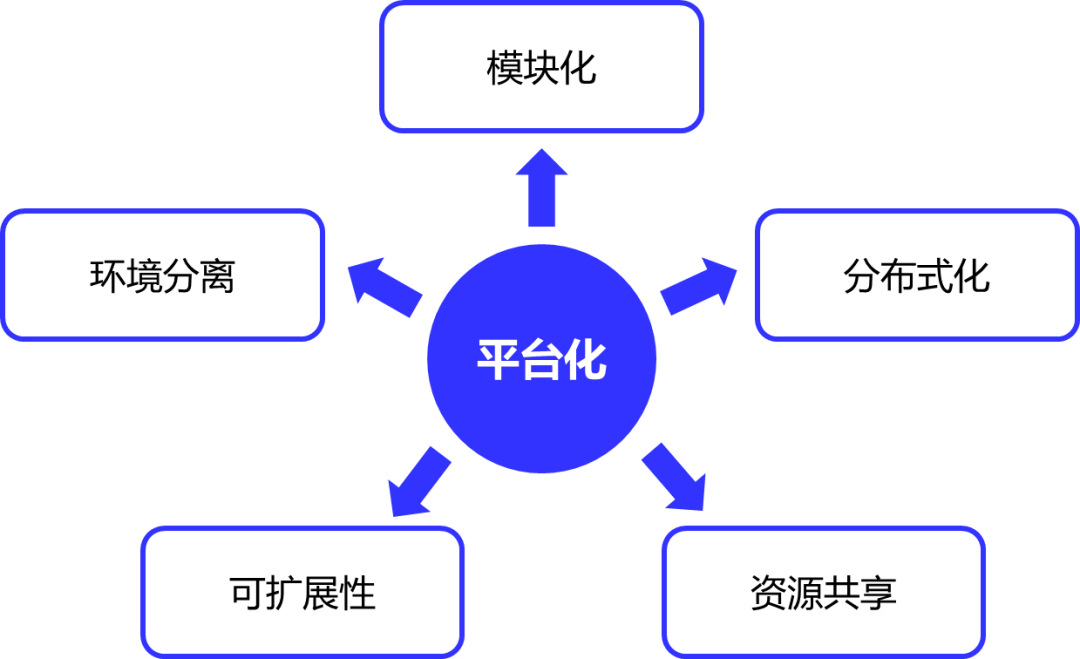
图1:AI平台技术挑战的解决思路
环境分离。首先是算力的分离,通过整个容器技术将CPU、GPU等环境给统一化,用户只需提供对应的容器。其次,针对GPU、CPU对应的不同硬件封装全部由系统去处理,这样的益处在于对于使用者而言他所需面对的只是一个容器。同时,UCloud在底层也专门做了一个数据接入层,这个接入层会把大量各式各样的数据统一成本地存储和NFS。这样处理之后,使用者可省去关注大量存储接口接入的工作,这也是整个环境分离的一个核心思路。容器分离的优势在于使用容器之后,每一个任务其实都是独立的运行环境,所以不同任务之间不会出现软件冲突。第二,UCloud会提供很多预装的容器,所以企业/个人可以节省很多环境准备的开销支出。此外,对于容器来说,企业/个人可自由安装各类软件包,封装各类算法。容器同样也可重复使用,基于某一个容器去做自己的分支,打包不同的算法进去也未尝不可,可重用性很强。最后也是比较突出的一点是容器镜像可以在任意类型节点运行。GPU的容器可以在任意GPU的节点上去跑,CPU的容器也可以在任意的CPU节点上去跑。这使得每一个镜像均可以在不同的环境中运行,这样的兼容性和通用性在真正实际应用部署过程中优势突出。
环境分离的第二部分是数据接入。我们团队在整个平台设计过程中的理念就是让使用者专注于业务程序的编写,其它如接口转译、带宽控制、权限控制等交由一个软件接入层去管理。这样的好处第一,计算节点不需要支持各种存储接口,仅需要通过2-3种(例如本地存储、NFS)接口就可以对接各类存储类型。第二,通过扩展数据接入层可接入的存储类型,就可以扩展AI平台的数据接入类型。第三,数据接入层可以做数据流量控制,确保各个任务的SLA,同时对后端的数据存储系统进行带宽、流量保护。第四,整个接入层还以做一些权限控制,以便不同的人共享资源时确保数据安全性。
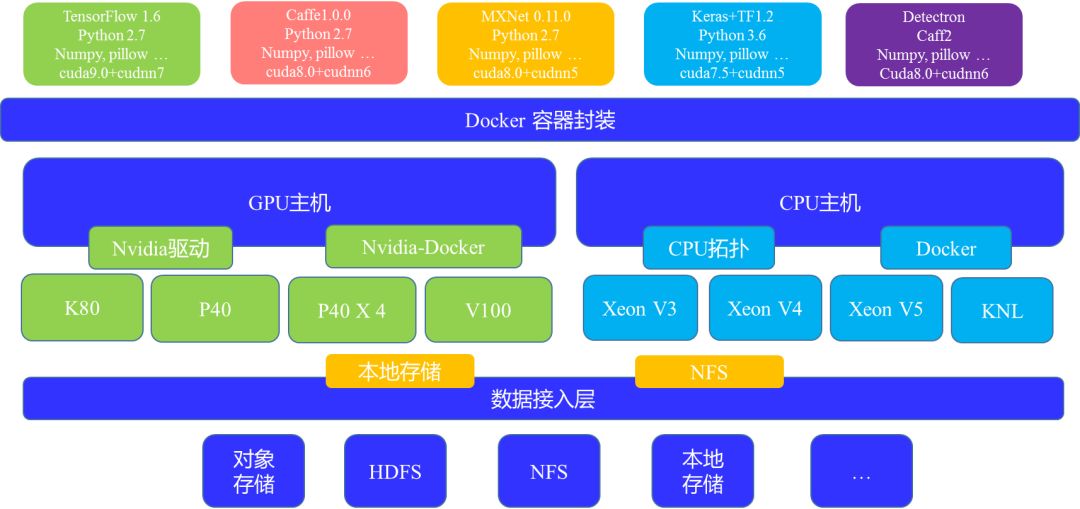
图2:UCloud整个底层环境分离的方案
分布式化。分布式化首先解决了节点宕机的问题,可做到容灾。其次可做到资源共享。以UCloud的AI训练服务平台和AI在线服务平台举例。训练平台的核心就是管理GPU资源,我们做一个桥梁把用户的算法和数据进行一个连通,这样一来,对于任何任务在任一GPU节点上去运行的时候,它都能访问自己的数据。企业/个人无需关心数据获取的来源、打通方式及维护GPU节点或集群,这些工作将全部交给平台管理。而在线推理平台,对于使用者而言,则只要关心业务的逻辑开发,开发一个单节点能用的AI服务即可。平台会负责做负载均衡、容灾、管理任务、弹性的扩(缩)容等工作。
模块化。调用资源时我们团队做了一个适配,即企业/个人既可以使用UCloud自己的资源管理平台也可以用K8s或是OpenShift。此时你会发现整个平台可以对接不同的资源管理系统。我们使用资源管理系统的目的是让它能管理资源,给到使用者资源状态的反馈。同时实际任务的调度和下发都由核心平台去做。这样,整个平台系统就变成了三层结构,最上层就变成了一个灵活层,实现快速对接各种各样的不同软件环境。这即是前后分离。
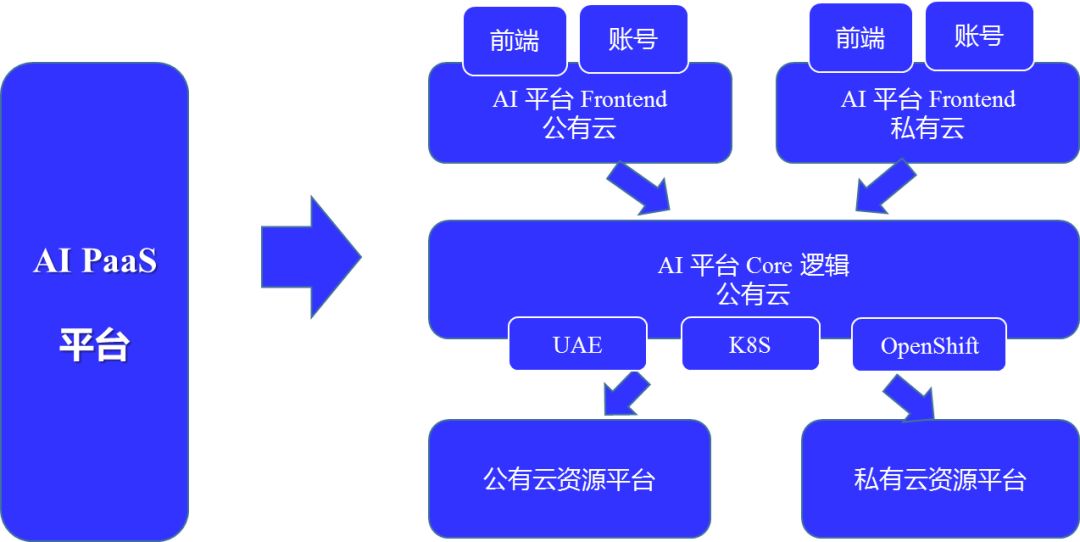
图3:UCloud AI PaaS平台的模块化
可扩展性。在完成上述操作后,整个系统的扩展性会非常强。如果有增加新的存储模式或者扩容存储的话,企业/个人的开发只是在数据封装层,无需开发到应用里去。对于整个集群而言,因为所有任务已经全部分布式化了,所以可以快速地部署第二个第三个集群,平台甚至支持对一个集群进行快速扩充。
资源共享。通过之前的原理介绍,想必大家不难发现我们UCloud开发的这两个平台其实就是一个平台。CPU集群、GPU集群、存储集群均是可以共享的。这两个互通平台甚至可交付给几百几千人共享资源,资源的使用率就这样被大幅提升。
原理介绍之后必然是实践,UCloud AI实验室在过去的两年分别构建了公有云AI平台和私有云AI平台。下面是这两个平台的构建方法简述。
如何构建公有云AI平台
公有云的AI平台是基于UCloud自己的公有云产品线上构建的,完全是在UCloud的云主机或者物理云主机上搭建环境,用的容器及负载均衡也都是UCloud本身提供的服务。整个系统的架构如下图示:
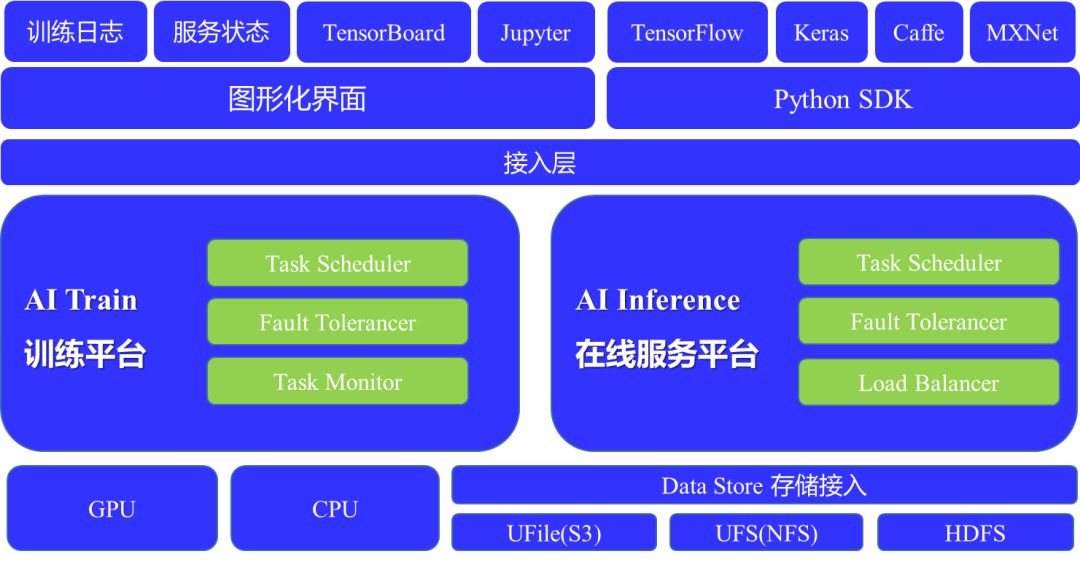
图4:UAI 公有云PaaS平台
UAI-Train的底层对接所有存储,GPU资源像一个池子一样被管理起来。平台同时支持分布式训练、单接点的训练以及交互式的训练。所有的训练对于用户来说,可能只是一个任务,但平台会根据不同的训练需求及所需的资源需求去适配不同的硬件设备,去协助完成这一任务。而UAI-Inference展现给用户的则是一个图形界面,包括服务的请求数量、客户到底调用了哪些应用、计费信息等。但底层的如APP使用了多少节点、是否需要做扩(缩)容等都是平台自行处理。整套系统全部是容器化的,可以做很多封装。并且我们也提供很多开源系统的镜像包括开源算法的在线服务镜像等,这些镜像就像是案例,如果企业/个人需要快速去验证部分应用的话可直接拿去使用试验。
UAI 公有云PaaS平台也具备了很多功能:
1、自动调度。平台会依托整个UCloud的GPU资源池,提供足量的GPU去跑任务,由系统自动选取空闲的节点。如此一来,当没有任务提交的时候也不会有任何的成本开销。
2、强扩展性。当后台运营期间发现整个GPU的需求量上升的时,UCloud GPU资源池里的资源可扩展到平台里去,同时平台也可对接UCloud自身的海量存储资源。以确保训练任务的正常执行。
3、负载均衡。在UAI-Inference里,用户部署的APP或者其它应用,系统是会自动协助做负载均衡。第一层从交换机开始做,中间有我们UCloud的负载均衡器(LVS、ULB),再下一层是调度算法,协同将所有任务打散至各个计算节点上去。如遇节点挂掉,系统将第一时间帮助用户去补足量的节点。
4、高可用的容灾能力。整个系统会部署在多个Set里面,如果业务量和节点数较多时,会被打散在UCloud不同的可用区里面,哪怕某一个机房出现断电或者拥堵的情况,另外一个机房的节点还能够提供部分的有损服务。
5、基于秒级/分钟级的计费规则,按需收费。我们团队将计费从传统的按年按月按小时的计费方式直接缩成了按分钟或者按秒的计费方式。对于用户而言,无论是使用UAI-Train还是UAI-Inference,,每一分钱都是用在刀刃上的,无需担心大量前置资源的浪费。任务一旦结束,计费也就停止了。
如何构建私有云AI平台
其实,私有云的AI平台构建部分与公有云很相似,从下图中我们不难看出核心层几乎是一致的。底层依赖的资源也依旧是CPU与GPU。
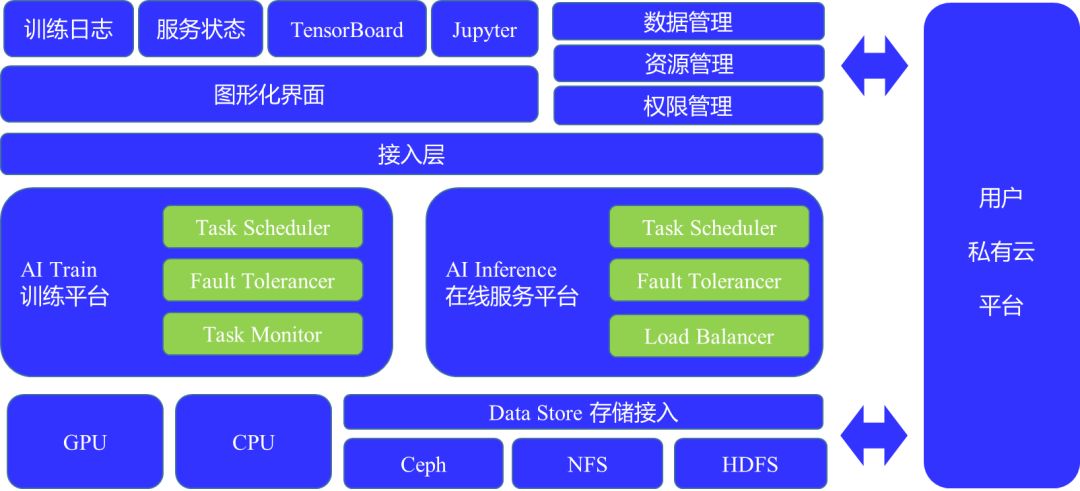
图4:UAI 私有云PaaS平台
发生变化的是接入层及上层界面。最重要的变化是权限管理、资源管理和数据管理这一块即与用户的私有云做整合,按照UCloud的API去开发,使用户整合出一套自有的权限管理或者账号管理体系,包括存储体系也是这样去操作。另外,现阶段开发的私有云平台版本是基于超融合技术。如此一来,在私有云上去部署算法和应用就变得非常容易,用户只需要把算法推到算法库,然后算法库可以利用AI平台把算法部署到AI平台上去。同时这个超融合平台还自带容器平台,容器平台可以部署一些接入的容器,即业务容器。使得业务容器和算法容器通过内网的连接打通,变成一个服务。
私有云AI平台与公有云平台一样具备很多优势:
1、提供预置AI基础环境。包括NV GPU驱动、Cuda、TensorFlow/MXNet等框架。用户无须进行复杂的环境安装、配置工作。
2、提供一站式AI服务。包括AI训练平台和AI在线服务平台,用户无须自行搭建复杂的AI平台。
3、系统可自由横向扩展。可以根据需求规模自行定义。
4、纵向扩展力强。用户可自由对多种计算、存储、网络资源类型进行选择合适组合。
5、可快速定制用户账号权限、资源管理等功能。
12月21日UCloud用户大会暨 Think in Cloud 2018上海站将于上海宝华万豪酒店开幕。届时,UCloud 副总裁杨镭将带来有关极简产品的设计理念、下一代网络、下一代计算以及全球基础设施建设等前沿技术话题的深度剖析。除此之外,还会分享UCloud新一代后台系统以及Service Mesh网络灰度等内容,欢迎扫码报名参加。

▼点击【阅读原文】也可以报名