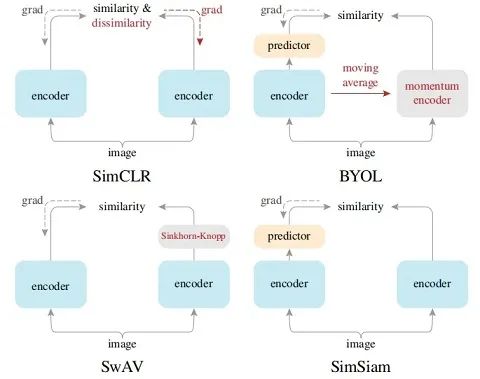
盘点近期大热对比学习模型:MoCo/SimCLR/BYOL/SimSiam



对比损失 Contrastive loss,简单的解释就是,利用对比正-负样本来学习表示。学习的目的为:

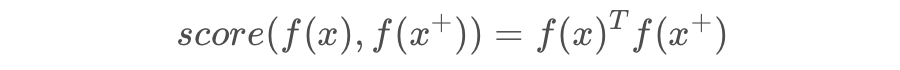
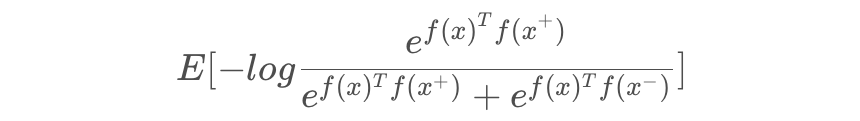
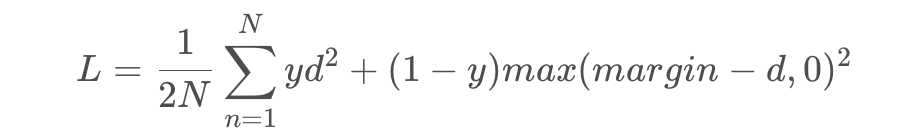
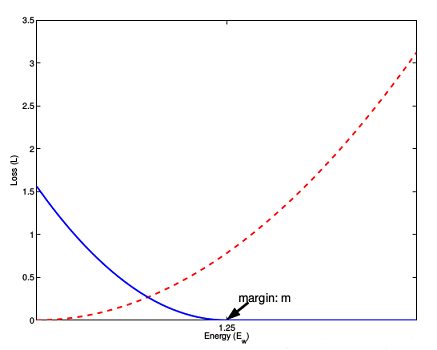
上图是 loss 与样本特征的欧式距离 d 之间的关系,其中红色虚线表示的是相似样本的损失值,蓝色实线表示的不相似样本的损失值。
def contrastive_loss(self, y,d,batch_size):
tmp= y *tf.square(d)
#tmp= tf.mul(y,tf.square(d))
tmp2 = (1-y) *tf.square(tf.maximum((1 - d),0))
return tf.reduce_sum(tmp +tmp2)/batch_size/2
Pairwise Ranking Loss
Triplet Ranking Loss
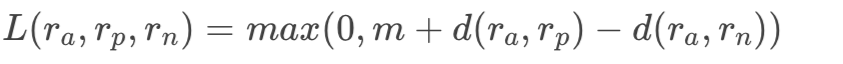
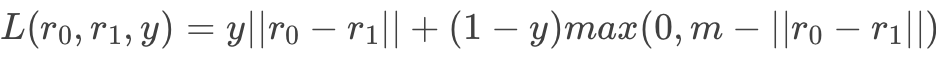
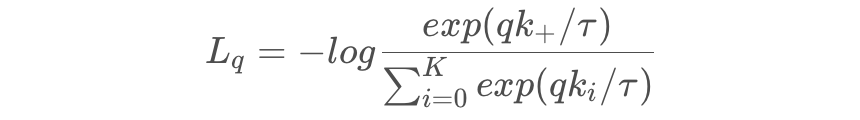

Easy negative example 比较容易识别,所以相对来说找一些较难的 pair 是有利于训练的。一般可分为:
Offline mining:计算所有的数据的 embedding,然后计算所以 pair 之间的距离判断其难易程度,主要选择 hard 或者 semi-hard 的数据。
Online mining:为每一 batch 动态挖掘有用的数据,将一个 batch 输入到神经网络中,得到这个 batch 数据的 embedding,Batch all 的方式还是会计算所有的合理的,Batch hard 偏向于选择距离最大的正样本和距离最小的负样本。
一般来说,对比方法在有更多的负样本的情况下效果更好,因为假定更多的负样本可以更有效地覆盖底层分布,从而给出更好的训练信号。
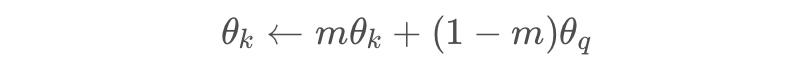
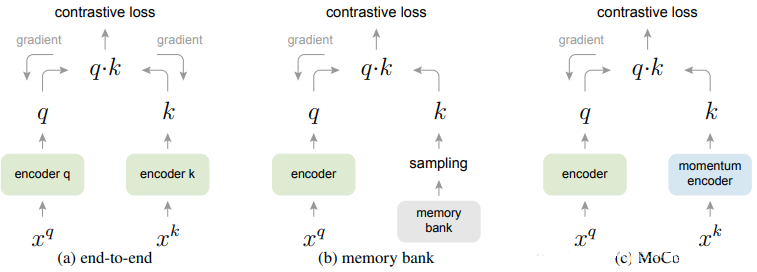
end-to-end:先编码 encoder(可同可不同),然后内积算 loss 再梯度。但是这种方法由于 dictionary size 和 mini-batch 的强耦合性(负例样本对也会为 loss 产生贡献,也会回传梯度),在 batch 大的时候优化难,而在 batch 小的时候,batch 之间的参数会不一样,也就是 GPU 大小限制了模型的性能。
memory bank:把 dictionary size 从 mini-batch 中解耦出来,即先把所有样本的特征保存下来 bank,然后每次随机采样,再梯度 query 的 encoder 的参数。但是这样只有当所有 key 被 sample 完以后才会更新 memory bank,不同的 key 在和 query 是不一致的和滞后的,因为每一次 sample encoder 都会更新虽有 memory bank 后面也加入了 momentum,但是是针对 sample 来的,在更新 memory bank 时会保留一部分上一轮的特征值。
MoCo:是以上两者的融合版本,将 dictionary 作为一个 queue 进行维护当前的negative candidates pool,且它是改成了 queue 的动态更新机制,每 sample 一个 batch key(所以一个 trick 就是会使用 Shuffling BN,打乱再 BN),进队后相对于一些最早进入队列的 mini-batch 对应的 key 进行出队操作,这样保证一些过时的、一致性较弱的 key 可以被清除掉。这样就同样是解耦,K 是队列长度,K 可以设置很大,同时更新也不会有问题。

@torch.no_grad()
def _momentum_update_key_encoder(self):
"""
key encoder的Momentum update
"""
for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
@torch.no_grad()
def _dequeue_and_enqueue(self, keys):
"""
完成对队列的出队和入队更新
"""
# 在更新队列前得到keys
keys = concat_all_gather(keys)#合并所有keys
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0 # for simplicity
# 出队入队完成队列的更新
self.queue[:, ptr:ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K # 用来移动的指针
self.queue_ptr[0] = ptr
def forward(self, im_q, im_k):
# 计算query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# 计算key features
with torch.no_grad(): # 对于keys是没有梯度的反向的
self._momentum_update_key_encoder() # 用自己的来更新key encoder
# 执行shuffle BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# 还原shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# 计算概率
# positive logits: Nx1
l_pos = torch.einsum('nc,nc->n', [q, k]).unsqueeze(-1) #用爱因斯坦求和来算sum
# negative logits: NxK
l_neg = torch.einsum('nc,ck->nk', [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# 平滑softmax的分布,T越大越平
logits /= self.T
# labels是正例index
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# 出队入队更新
self._dequeue_and_enqueue(k)
return logits, labels论文链接:
https://arxiv.org/abs/1911.05722
代码链接:

MoCo 强调 pair 对的样本数量对对比学习很重要,SimCLR 认为构建负例的方式也很重要。先说结论:
多个数据增强方法组合对于对比预测任务产生有效表示非常重要。此外,与有监督学习相比,数据增强对于无监督学习更加有用;
在表示和对比损失之间引入一个可学习的非线性变换可以大幅提高模型学到的表示的质量;
与监督学习相比,对比学习得益于更大的批量和更多的训练步骤。
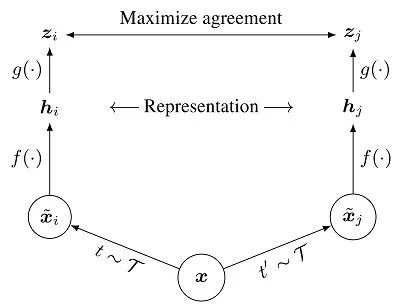
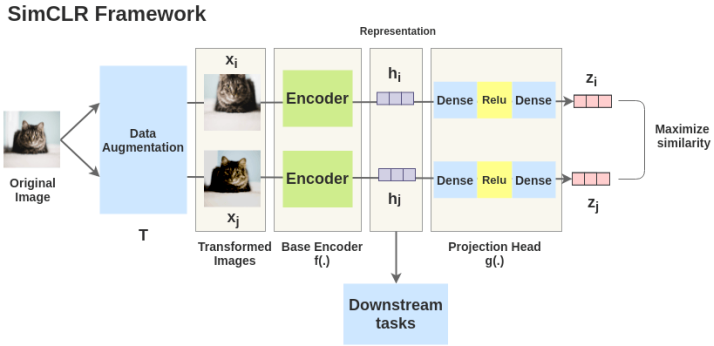
先 sample 一些图片(batch)
对 batch 里的 image 做不同的 data augmentation,如图上的 和 ,将其视为正对;
一个基本的神经网络编码器 f(·),从增强数据中提取表示向量, 作者使用 ResNet-50;
一个小的神经网络投射头(projection head)g(·),将表示映射到对比损失的空间;
目标是希望同一张图片、不同 augmentation 的结果相近,并互斥其他结果。

推荐有一个 github 用于数据增强很好用,pip install imgaug:

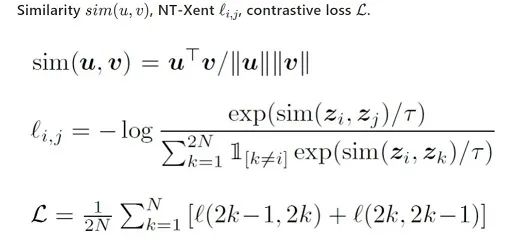
论文链接:
https://arxiv.org/abs/2002.05709
代码链接:


-
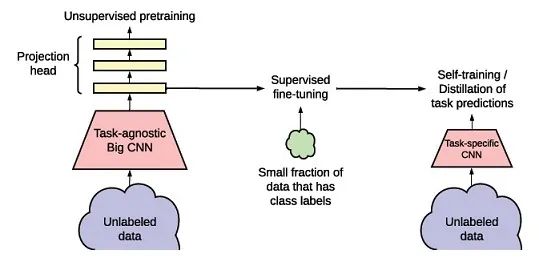
左边,非监督的方法学习一个任务无关的通用的表征,这里直接用 SimCLR,不同点在于网络变大和也借用了 MoCo 部分架构。
-
中间,用监督的方法进行 fine-turning
-
右边,在 unlabeled 大数据集上进行蒸馏

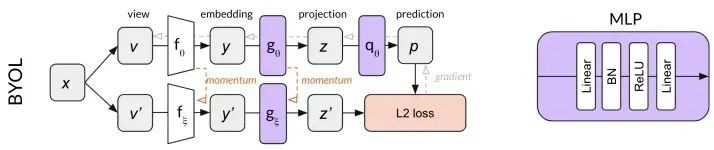
上面的分支是 online network,包括了 embedding,projection 以及 prediction,其中嵌入的使我们最要想要的模块。
下面的分支是 target network,包括 embedding 和 projection 。
online 网络参数使用 L2 的梯度进行更新,而 target 网络直接通过 online 的 momentum 得到,这里 target 的就充当了之前负样本的功能。

为什么BYOL有效?

BYOL和MoCo、SimCLR的区别
-
MoCo、SimCLR 更偏向于问这两张图片之间有何差异?
-
BYOL 可能是在问这张图片与这些图片的平均有什么差异?
论文链接:
https://arxiv.org/abs/2006.07733

SimSiam
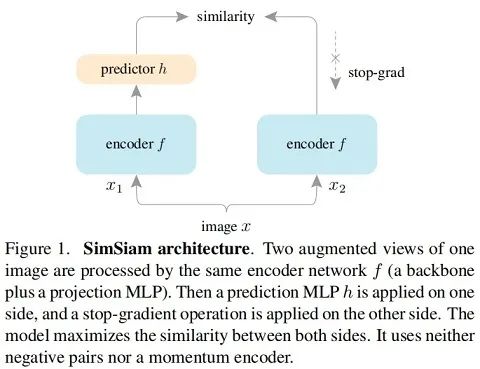
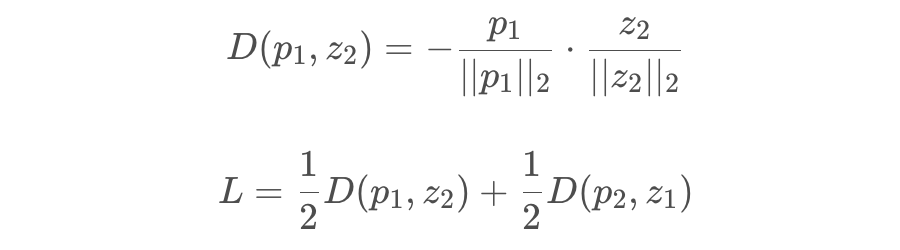
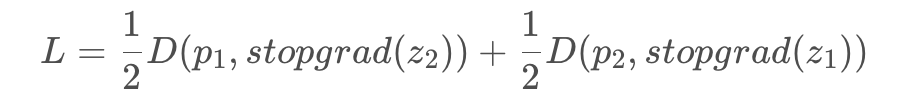
# Algorithm1 SimSiam Pseudocode, Pytorch-like
# f: backbone + projection mlp。f是backbone+projection head部分组成
# h: prediction mlp
for x in loader: # load a minibatch x with n samples
x1, x2 = aug(x), aug(x) # random augmentation,随机增强后的x1和x2
#分别做两次投影操作
z1, z2 = f(x1), f(x2) # projections, n-by-d
p1, p2 = h(z1), h(z2) # predictions, n-by-d
#计算不对称的两个D得到loss L
L = D(p1, z2)/2 + D(p2, z1)/2 # loss
L.backward() # back-propagate,反向传播
update(f, h) # SGD update,梯度更新
def D(p, z): # negative cosine similarity
z = z.detach() # stop gradient,在这里使用detach做stopgrad的操作
p = normalize(p, dim=1) # l2-normalize
z = normalize(z, dim=1) # l2-normalize
return -(p*z).sum(dim=1).mean()
论文链接:
https://arxiv.org/abs/2011.10566
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


