分布式训练中数据并行远远不够,「模型并行+数据并行」才是王道
选自arXiv
数据并行(DP)是应用最广的并行策略,对在多个设备上部署深度学习模型非常有用。但该方法存在缺陷,如随着训练设备数量不断增加,通信开销不断增长,模型统计效率出现损失等。来自加州大学洛杉矶分校和英伟达的研究人员探索了混合并行化方法,即结合数据并行化和模型并行化,解决 DP 的缺陷,实现更好的加速。
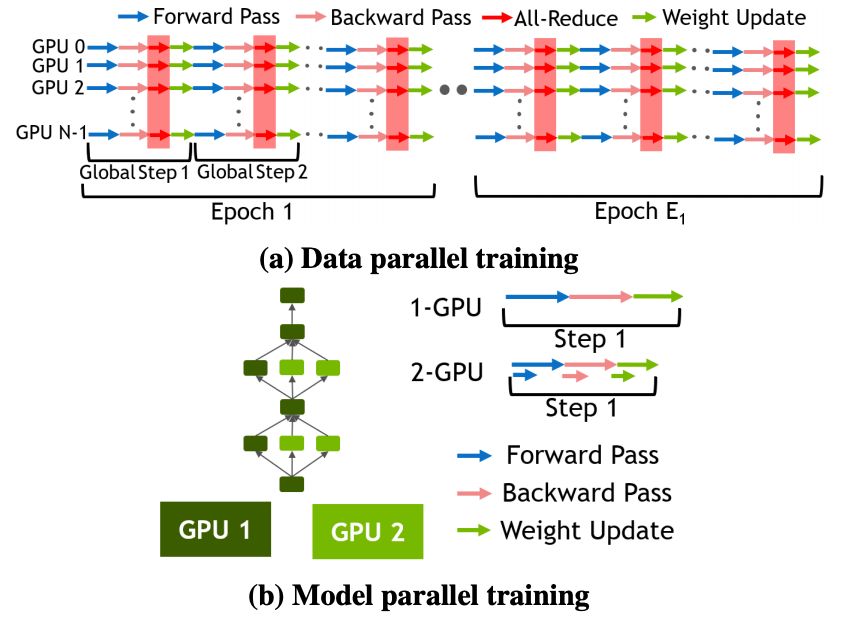
当 DP 愈加低效时,可以使用混合并行化策略(即每个数据并行化 worker 在多个设备上也是模型并行化的)进一步扩展多设备训练。
开发了一个分析框架,来系统性地找到设备数量(如用于训练模型的 GPU 和 TPU 数量)的交叉点,该交叉点表明在特定系统上优化模型训练时要使用的并行化策略。
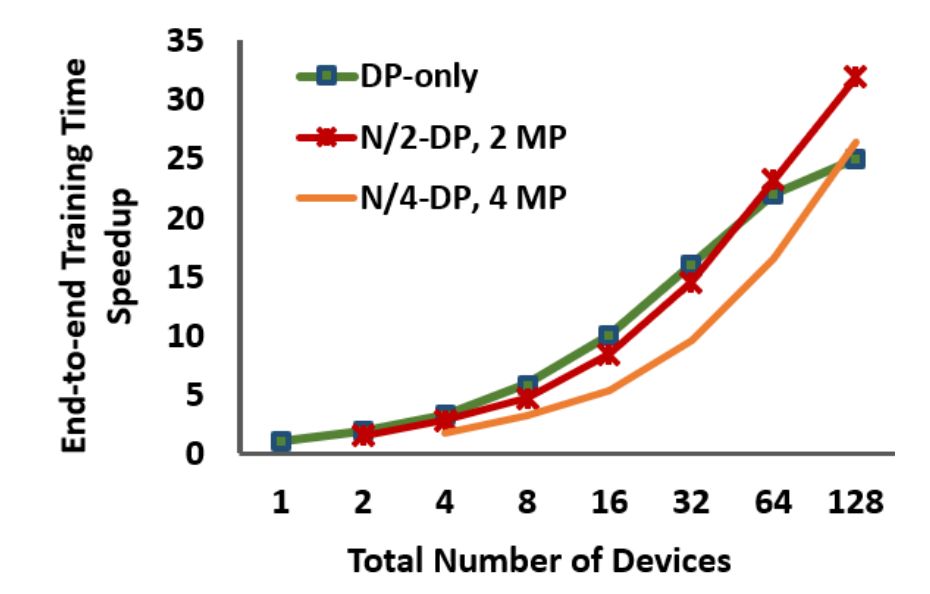
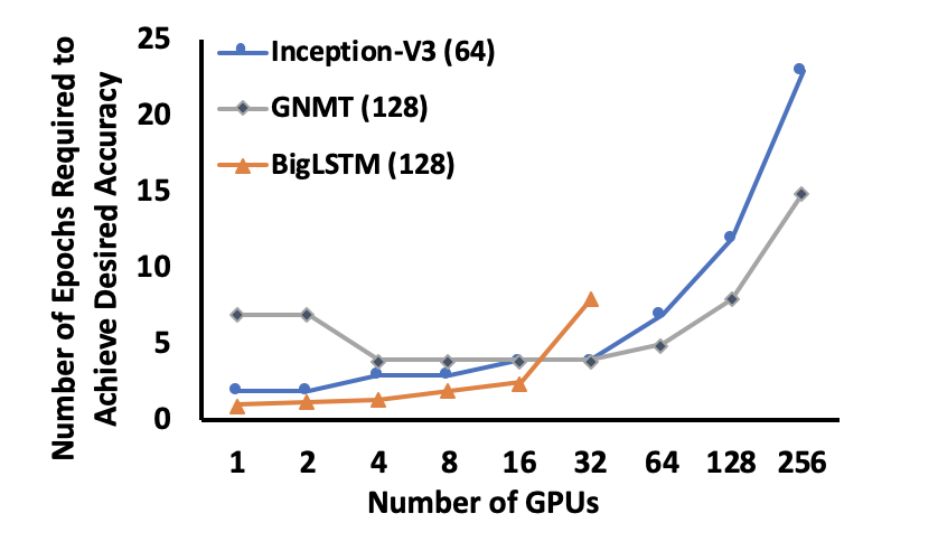
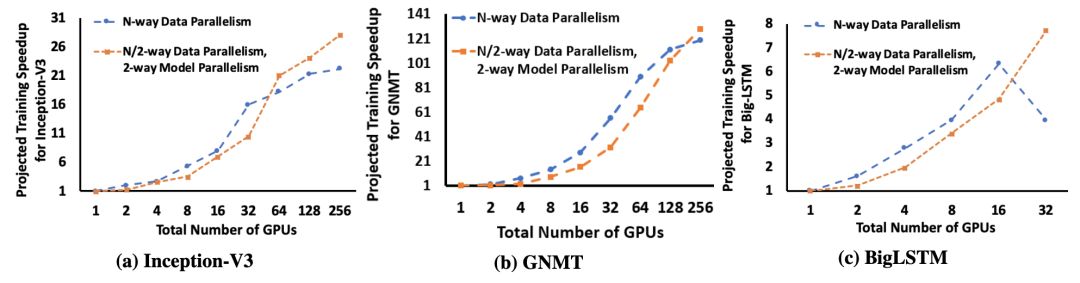
展示了混合并行化对于不同规模的不同深度学习网络的性能优于仅使用 DP 的策略。
研究者实现了 InceptionV3、GNMT 和 BigLSTM 的双路模型并行化版本,发现相比仅使用 DP 策略,混合训练可提供至少 26.5%、8% 和 22% 的加速。
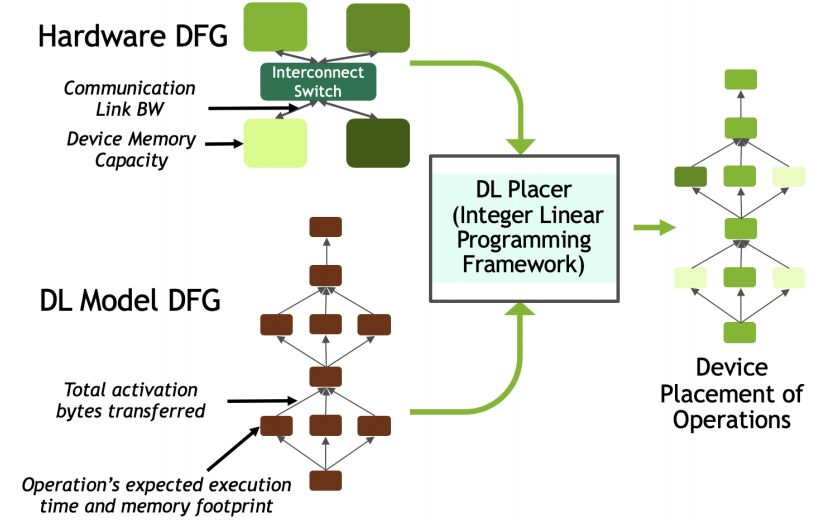
提出了基于整数线性规划的工具 DLPlacer,以发现最优的 operation-to-device 布局,从而最大化 MP 加速。
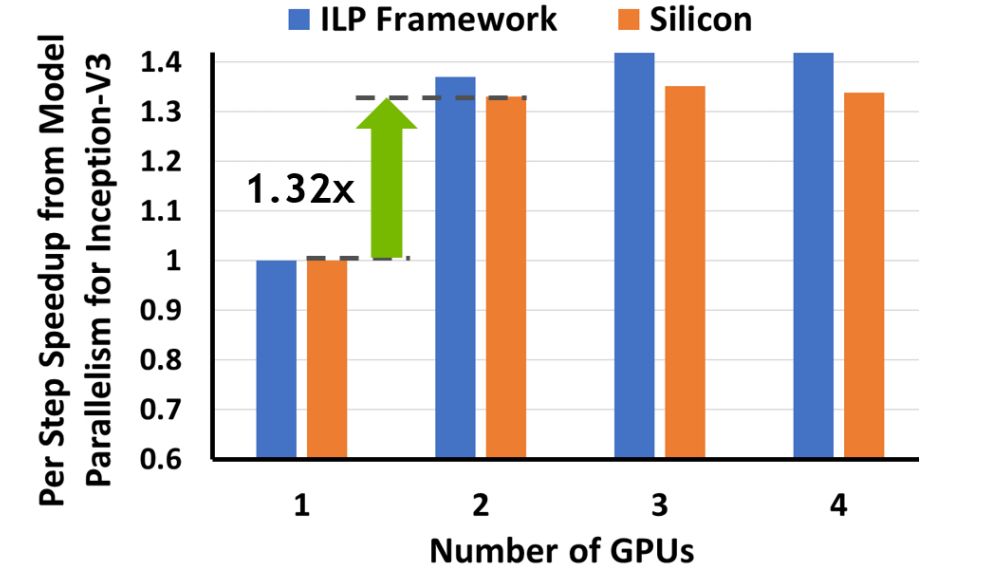
研究者使用 DLPlacer 为 Inception-V3 模型推导出最优的布局,从而展示了其有效性。
真实实验表明,在两个 GPU 的设置中获得的 1.32 倍模型并行加速在 DLPlacer 预测加速的上下 6% 的区间内。

其中 T 主要由计算效率决定,即给定相同的训练设置、算法和 mini-batch 大小,T 仅依赖于设备的计算能力,因此性能更好的硬件将提供更小的 T 值;
S 依赖于全局批大小和训练数据集中的样本数。
每个 epoch 需要一次性处理数据集中的所有样本,因此每个 epoch 的时间步数 (S) 等于数据集中样本数除以全局批大小。
收敛所需 epoch 数量 (E) 取决于全局批大小和其他训练超参数。
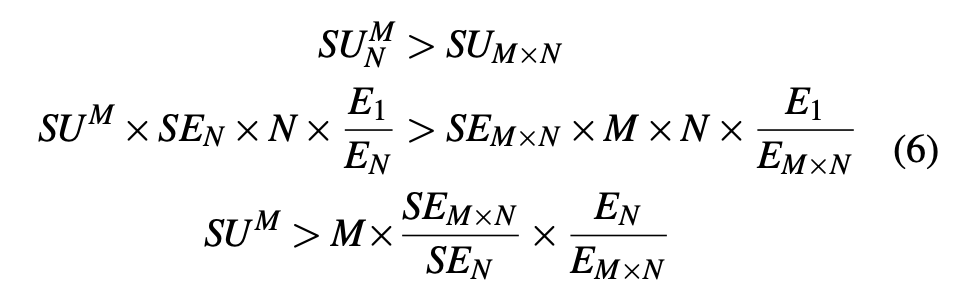

登录查看更多
相关内容

专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
36+阅读 · 2020年4月14日
Arxiv
7+阅读 · 2020年3月12日
Arxiv
8+阅读 · 2019年5月20日
Arxiv
4+阅读 · 2018年1月11日

相关VIP内容
专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
36+阅读 · 2020年4月14日
相关资讯
相关论文
Arxiv
7+阅读 · 2020年3月12日
Arxiv
8+阅读 · 2019年5月20日
Arxiv
4+阅读 · 2018年1月11日