谷歌经典的语义分割框架系列1——DeepLab v1
临近中国的春节,Google 团队也从不休假,趁着中国人每年一度大迁徙,他们在 arXiv 放出了 DeepLabv3+,虽然这个技术已经出现很久,但是其在语义分割领域取得新的 state-of-the-art 水平,以及典型的改进型让大家都能够熟知。那今天计算机视觉战队开始好好说说这一系列的操作,有兴趣的同学,我们一起去进行深入学习讨论!
今天先讲讲DeepLab v1的那些知识。
原文地址:Semantic image segmentation with deep convolutional nets and fully connected CRFs
收录:ICLR 2015 (International Conference on Learning Representations)
DeepLab是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。在实验中发现DCNNs做语义分割时精度不够的问题,根本原因是DCNNs的高级特征的平移不变性(即高层次特征映射)。DeepLab解决这一问题的方法是通过将DCNNs层的响应和全连接的条件随机场(CRF)结合。同时模型创新性的将Hole(即空洞卷积)算法应用到DCNNs模型上,在现代GPU上运行速度达到了8FPS。
相比于传统的视觉算法(SIFT或HOG),DCNN以其end-to-end(端到端)方式获得了很好的效果。这样的成功部分可以归功于DCNN对图像转换的平移不变性,这根本是源于重复的池化和下采样组合层。平移不变性增强了对数据分层抽象的能力,但同时可能会阻碍部分视觉任务,例如姿态估计、语义分割等,在这些任务中我们倾向于精确的定位而不是抽象的空间关系。
DCNN在图像标记任务中存在两个技术障碍:
信号下采样;
空间不敏感。
第一个问题涉及到:在DCNN中重复最大池化和下采样带来的分辨率下降问题,分辨率的下降会丢失细节。DeepLab是采用的atrous(带孔)算法扩展感受野,获取更多的上下文信息。
第二个问题涉及到:分类器获取以对象中心的决策是需要空间变换的不变性,这天然的限制了DCNN的定位精度,DeepLab采用全连接的条件随机场(DenseCRF)提高模型捕获细节的能力。
主要贡献:
速度:带atrous算法的DCNN可以保持8FPS的速度,全连接CRF平均推断只需要0.5s;
准确:在当年PASCAL语义分割挑战中获得了第二的成绩;
简单:DeepLab是由两个非常成熟的模块(DCNN和CRFs)级联而成。
相关工作:
DeepLab系统应用在语义分割任务上,目的是做逐像素分类的,这与使用two-stages的DCNN方法形成鲜明对比(指R-CNN等系列的目标检测工作),R-CNN系列的做法是原先图片上获取候选区域,再送到DCNN中获取结果。虽然这种方法明确地尝试处理前段分割算法的本质,但在仍没有明确的利用DCNN的预测图。
今天提出的算法框架与其他先进模型的主要区别在于DenseCRFs和DCNN的结合。是将每个像素视为CRF节点,利用远程依赖关系,并使用CRF推理直接优化DCNN的损失函数。Koltun(2011)的工作表明全连接的CRF在语义分割下非常有效。
也有其他研究者采取非常相似的方向,将DCNN和密集的CRF结合起来,作者团队已经更新提出了DeepLab新框架(此处具体指的是DeepLabV2)。
密集分类下的卷积神经网络
这里先描述一下DCNN如何设计,调整VGG16模型,转为一个可以有效提取特征的语义分割框架。具体来说,先将VGG16的FC层转为卷积层,模型变为全卷积的方式,在图像的原始分辨率上产生非常稀疏的计算检测分数(步幅32,步幅=输入尺寸/输出特征尺寸),为了以更密集(步幅8)的计算得分,我们在最后的两个最大池化层不下采样(padding到原大小),再通过2或4的采样率的空洞卷积对特征图做采样扩大感受野,缩小步幅。
空洞卷积的使用
简单介绍下空洞卷积在卷积神经网络的使用(在后期分享的DeepLabv3中有更详细的讨论)。在1-D的情况下,我们扩大输入核元素之间的步长,如下图Input stride:
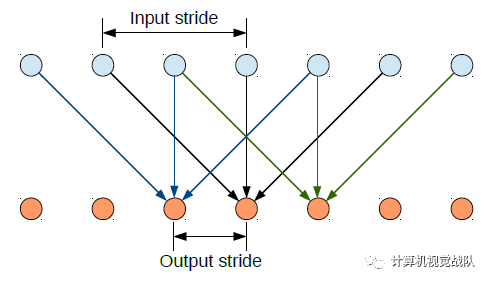
如果不是很直观,看下面的在二维图像上应用空洞卷积:

蓝色部分是输入:7×7的图像;
青色部分是输出:3×3的图像;
空洞卷积核:3×3,采样率(扩展率)为2,无padding。
这种带孔的采样又称atrous算法,可以稀疏的采样底层特征映射,该方法具有通常性,并且可以使用任何采样率计算密集的特征映射。在VGG16中使用不同采样率的空洞卷积,可以让模型在密集的计算时,明确控制网络的感受野。保证DCNN的预测图可靠的预测图像中物体的位置。
训练时将预训练的VGG16的权重做fine-tune,损失函数是输出的特征图与ground truth下采样8倍做交叉熵和;测试时取输出图双线性上采样8倍得到结果。但DCNN的预测物体的位置是粗略的,没有确切的轮廓。在卷积网络中,因为有多个池化层和下采样的重复组合层使得模型具有平移不变性,我们在其输出的high-level的基础上做定位是比较难的。这需要做分类精度和定位精度之间是有一个自然的折中。
解决这个问题的工作,主要分为两个方向:
第一种是利用卷积网络中多个层次的信息;
第二种是采样超像素表示,实质上是将定位任务交给底级的分割方法。
DeepLab是结合了DCNNs的识别能力和全连接的CRF的细粒度定位精度,寻求一个结合的方法,结果证明能够产生准确的语义分割结果。
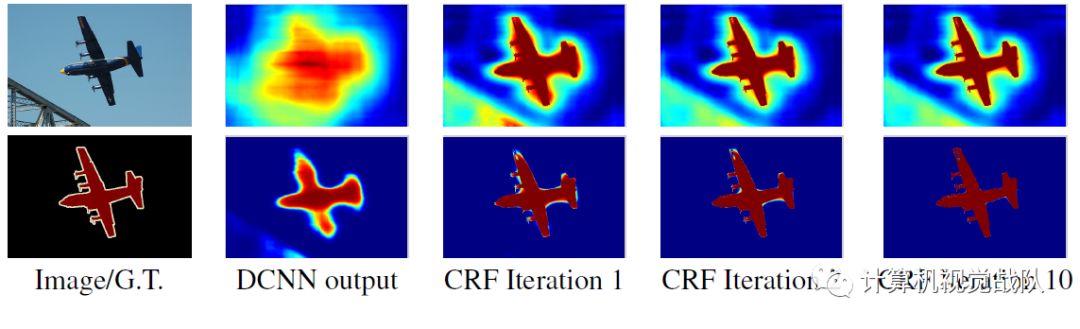
CRF在语义分割上的应用
传统上,CRF已被用于平滑噪声分割图。通常,这些模型包含耦合相邻节点的能量项,有利于相同标签分配空间近端像素。定性的说,这些短程的CRF主要功能是清除在手工特征基础上建立的弱分类器的虚假预测。
与这些弱分类器相比,现代的DCNN体系产生质量不同的预测图,通常是比较平滑且均匀的分类结果(即以前是弱分类器预测的结果,不是很靠谱,现在DCNN的预测结果靠谱多了)。在这种情况下,使用短程的CRF可能是不利的,因为我们的目标是恢复详细的局部结构,而不是进一步平滑。而有工作证明可用全连接的CRF来提升分割精度。
CRF在语义分割上的应用:
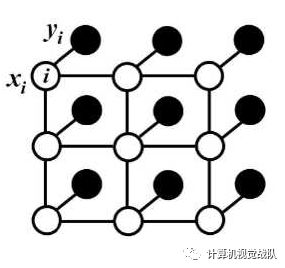
对于每个像素位置i具有隐变量xi(这里隐变量就是像素的真实类别标签,如果预测结果有21类,则(i∈1,2,..,21),还有对应的观测值yi(即像素点对应的颜色值)。以像素为节点,像素与像素间的关系作为边,构成了一个条件随机场(CRF)。通过观测变量yi来推测像素位置i对应的类别标签xi。条件随机场示意图如下:
多尺度预测
论文还探讨了使用多尺度预测提高边界定位效果。具体的,在输入图像和前四个最大池化层的输出上附加了两层的MLP(第一层是128个3×3卷积,第二层是128个1×1卷积),最终输出的特征映射送到模型的最后一层辅助预测,合起来模型最后的softmax层输入特征多了5×128=640个通道,实验表示多尺度有助于提升预测结果,但是效果不如CRF明显。
Experiment
测试细节:
项目 |
设置 |
数据集 |
PASCAL VOC 2012 segmentation benchmark |
DCNN模型 |
权重采用预训练的VGG16 |
DCNN损失函数 |
交叉熵 |
训练器 |
SGD,batch=20 |
学习率 |
初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1 |
权重 |
0.9的动量, 0.0005的衰减 |
DeepLab由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。在对DCNN做了fine-tune后,对CRF做交叉验证。具体参数请参考论文。
CRF和多尺度的表现
在验证集上的表现:
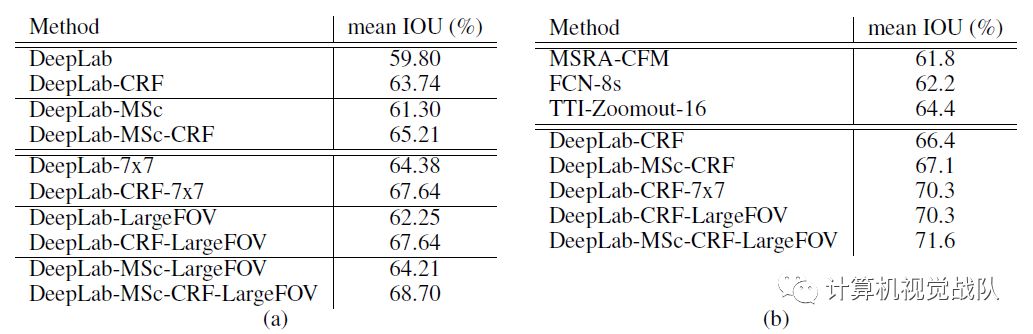
可以看到带CRF和多尺度的(MSc)的DeepLab模型效果明显上升了。
多尺度的视觉表现:

第一行是普通输出,第二行是带多尺度的输出,可以看出多尺度输出细节部分要好点。
空洞卷积的表现
在使用空洞卷积的过程中,可控制空洞卷积的采样率来扩展特征感受野的范围,不同配置的参数如下:

同样的实验结果:
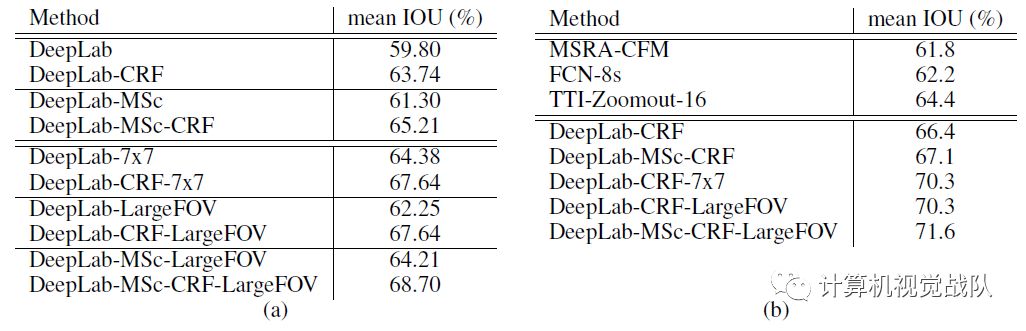
带FOV的即不同空洞卷积的配置,可以看到大的空洞卷积效果会好一点。
与其他模型相比

与其他先进模型相比,DeepLab捕获到了更细节的边界。
DeepLab创造性的结合了DCNN和CRF产生一种新的语义分割模型,模型有准确的预测结果同时计算效率高。在PASCAL VOC 2012上展现了先进的水平。DeepLab是卷积神经网络和概率图模型的交集,后续可考虑将CNN和CRF结合到一起做end-to-end训练。
后续我们将进一步讨论DeepLabv2~3,他们都是DeepLabv1的升级版,并进一步讨论空洞卷积和CRF的使用。





