人工智能的进步往往源自于新环境的开发,这些环境将现实世界中的情况抽象为便于研究的形式。本文基于初级微观经济学的启发,提供了这样一个新环境。智能体学会在一个复杂空间的世界中生产资源,相互交易,并消费他们喜欢的资源。我们发现出现的生产、消费和定价行为对环境条件改变的反应与微观经济学中的供给和需求转变所预测的方向一致。我们还证明了智能体商品的紧急价格随空间的变化能够反映当地商品的丰富程度。在价格差异出现后,一些智能体发现了在具有不同现行价格的地区之间运输货物的商机--这是一个有利可图的策略,因为他们可以在便宜的地方购买货物,在昂贵的地方出售货物。最后,在一系列的消融实验中,我们研究了如何在环境奖励、易货贸易行动、智能体结构和消费可交易商品的能力中进行选择,从而帮助或抑制这种经济行为的出现。这项工作是一项研究计划中环境开发分支的一部分,该计划旨在通过模拟社会中的多智能体互动来建立类似人类的人工通用智能。通过探索学习过程中自动出现的初级微观经济学基本现象所需的环境特征,我们得到了一个不同于先前多智能体强化学习在多个维度上进行研究的新环境。例如,该模型包含了各种各样的兴趣和能力,并且智能体之间的谈判是一种基础的通信形式。为了促进这方面的进一步工作,我们将发布环境的开源实现作为 Melting Pot 套件的一部分(Leibo 等人,2021 年)。

我们希望构造能够像人类一样进行创新的人工智能体。我们认为决策理论和强化学习(或 RL)等理论和算法框架与此目标相关。然而,我们还没有成功地建立这样的智能体,原因之一是这些理论擅长的东西(主要是加强薄弱和不可能的行为,使其变得更加普遍和完善)与我们实际希望它们做的事情之间的存在根本矛盾,我们希望它们能够发现真正新颖和创新的行为,然而这些行为在它们学习的开始阶段根本没有任何出现的频率。
任何曾经试图训练鸽子打保龄球的人都可以证明,如果你必须等到鸽子自发的出现期望的行为时才提供第一个奖励,那么你将不得不等待很长的时间(Peterson, 2004)。就贝叶斯决策理论而言,先验分布必须在其支持范围内包含新行为。 否则,任何证明其优越性的证据都不足以将其概率从零推低(Kalai 和 Lehrer,1993 年)。 L. J. Savage 用一对谚语说明了这个问题。 一个小世界是一个你总是可以“先看再跳”的世界。 一个广阔的世界是一个你有时必须“当你到达它时越过那座桥”的世界(Binmore,2007;Savage,1951)。 贝叶斯决策理论只在小世界中有效。 然而现实世界很大。
在大的世界里,RL变成了一个关于如何加强薄弱行为的理论,而不是一个关于如何产生全新行为的理论。这是因为,在第一次出现足够接近的创新行为之前,创新行为是无法被强化的。RL研究人员采用了各种方法来鼓励智能体不断产生新的行为。许多方法相当于在行动选择中注入随机性,如e-greedy和熵正则化玻尔兹曼探索(Sutton和Barto,2018)。Osband等人(2019)称这种方法为随机抖动。抖动为智能体提供了体验其从未尝试过的行为并获得的奖励的机会。然而,抖动是一种穿越大世界的低效方式。考虑一下:一个e-greedy的智能体以1的概率选择它目前认为是最好的行动,否则就从所有可用的行动中均匀地随机选择。它发出任何特定的新行为序列--即不包含最初认为有价值的行动的序列--的概率随着序列长度的增加而呈指数下降(Kakade,2003;Osband等人,2019)。乐观的初始化是另一种探索方法,它使智能体对每个状态和行动的初始奖励估计有积极的偏差(Sutton和Barto,2018)。然而,由于缺乏关于将”乐观“放在何处的先验知识,它会降低到的一般驱动力去探索所有状态和行动,在大世界中这是一项不可能的任务,也是一种低效和分散注意力的偏见。
在RL中还有许多其他更复杂的探索方法,但由于同样的原因,所有这些方法在大世界中都很困难:目标行为离当前最清楚的行为越远,智能体必须对它认为不具吸引力的行为做出更多地尝试,以便找到它。在大世界中,目标行为可能确实非常遥远。更复杂的探索方法寻求比随机抖动更明智地选择实验动作,但在不结合先验知识的情况下,这种方式可以获得多少效率是有限度的(Osband 等人,2019 年)。因此,当有益的行为(即行动序列)在学习之前从未偶然出现,而且随机智能体从未产生这些行为时,RL往往不善于发现这些行为。然而,这些正是我们最想发现的行为。我们知道人类可以创新:例子包括谱写贝多芬的第五交响曲,设计航天器将宇航员带到月球,以及设计农业技术为数十亿人提供食物。我们希望开发能够像人类一样创新的算法。
到目前为止,我们已经假设我们不能依赖智能体的学习环境具有任何特定的结构。这个假设背后的逻辑很清楚:既然我们希望我们的RL智能体在任何环境中都能成功,那么我们就必须倾向于最终在所有环境中都收敛的探索技术,如e-greedy,特别是那些没有先验知识可以利用的环境。这个出发点使我们对RL解释创新的能力得出了一个悲观的结论。另一方面,允许有先验知识将完全改变情况。有许多RL算法在获得某种形式的正确先验知识时,即使在大世界中也能有效地探索(例如Gupta等人(2018))。也许通过将我们的注意力限制在像人类进化的自然环境中,我们可以发现创新的根本要素。毕竟,自然环境只覆盖了所有可能环境空间的一小部分,而它们可能具有促进其中的智能体进行探索的有用特性。此外,我们通常用于研究的 RL 环境从未打算作为有助于自然智能进化或发展的情境模型。他们可能无法系统地捕捉自然环境的重要特性。
事实上,两条独立的生物学证据和推理表明,我们大多数的RL环境错过了自然环境中存在的一些重要东西。在实验室的动物中,对饲养环境的操作而产生的变化对动物大脑结构和行为都产生了深刻的影响。例如,实验室啮齿动物的环境可以通过使用更大的笼子来丰富,笼子里有更多的其他个体--创造更多的社会互动机会,可变的玩具和喂食地点,以及一个允许自己转动的轮子。在这种丰富的环境中饲养动物可以提高它们的学习和记忆力,增加突触分支,并增加大脑的总重量(Van Praag等人,2000)。生物学推理的第二个分支是关于灵长类动物进化中出现智力的 "社会脑假说"(Dunbar, 1998)。它是基于这样的观察:一个物种的大脑大小与其典型的社会群体大小(根据整体身体大小调整)有很好的相关性。这种相关性在整个灵长类动物中保持不变,它们的大脑大小跨越了三个数量级(Dunbar和Shultz,2017)。一般来说,生活在较大群体中的灵长类动物具有较大的大脑。社会大脑假说表明,由于诸如减轻捕食风险等原因而需要更大的社会群体,从而引发了无数新的社会起源问题。解决这些问题的需要推动了灵长目动物越来越高的智能进化。在RL术语中,该假设是“更聪明”物种的社会丰富环境包含正确的问题组合,以鼓励智能体寻找智能解决方案。
此外,许多关键创新涉及不止一个智能体的协作行为。RL领域解决探索问题的标准方法--内在动机(例如Pathak等人(2017)),特别不适合发现涉及智能体之间广泛协作的平衡,因为根据定义,内在动机是内在的 - 仅依赖于 自我产生的信号,这些信号不容易与其他人的信号相关联。
幸运的是,RL 有一个考虑社会丰富环境的子领域:多智能体强化学习 (MARL)。多智能体环境本质上是非稳定的,因为每个智能体的经验流和最佳行为随着其他智能体的学习和行为的改变而改变。随着种群的学习,可能会产生新的智能体可以填补的新利基市场,或者其他智能体可能会开始竞争智能体当前的利基市场。这为智能体提供了外在动机,以随着人口的适应不断探索新的行为(Baker 等人,2019;Balduzzi 等人,2019;Leibo 等人,2019a;Wang 等人,2019b)。在理论上,这样的多智能体系统可以永远继续探索。在实践中,他们经常达到一个平衡点并停止探索。为理解这些系统如何工作所做的工作与人工智能和认知科学的主流 "单智能体范式 "产生了矛盾。简而言之,所有重要的表示不再位于智能体的“头脑”内部,而是以某种方式分布在智能体、种群、环境和训练协议本身之间。
多智能体环境的特点是提供探索的外在动力:因果力量。例如:考虑微观经济学中的供应和需求要素。它们是由单个智能体的多个行为聚合而创造的。它们构成了对的智能体的真正激励力量,这些智能体在经济理论中充斥着供给和需求的变化将会导致智能体在特定方向上产生改变其行为的系统激励。例如,我出售一个小部件的价格的增加,激励我生产更多的小部件。同样,相互竞争购买我的小部件的智能体商数量减少会激励我降低出售它们的价格或减少产量。这些因素有时也能激励创新。如果对我的工厂生产的小商品的需求有足够大的增长,而且我不能简单地提高价格,那么我就会被激励去寻找方法来生产更多的小商品,或者更有效地生产小商品,也许是通过改进制造工艺。这个例子说明,不一定存在探索与开发的权衡。事实上,现实世界的环境往往具有使智能体通过获利进行探索的属性(另见Leibo等人(2019b))。
到目前为止,我们已经论证了社会环境--即世界上其他智能体的集合--塑造了reward landscape,从而为智能体的探索和创新提供了外在动力。这些智能体所在的底层环境或基质在激励智能体创新方面也发挥着作用。例如,一个非常简单的底层环境只包括一个没有物体的空房间,无论在其中的智能体群体有多大或多复杂,都不会有创新。我们可以进一步扩展这种论证。考虑一下,如果你将GPT-3(Brown等人,2020)这样的大型语言模型与最新的基于RL的智能体连接起来,在三维世界中解决复杂的问题(具体来说,也许可以考虑Parisotto等人(2020)或任何其他适用于三维模拟世界的最先进的单智能体RL算法)会发生什么。另外,在这个思想实验中,假设我们已经以某种方式解决了language grounding的问题(例如在Harnad(1990)中描述)。选择一个具有现实物理学的三维模拟作为基底,如DMLab-30环境套件的基础(Espeholt等人,2018)。然后将100个这些最先进的RL智能体连接到它。让它们能够通过查询大型语言模型和相互发送文本流来相互交流。由于我们已经假设语言基础问题已经解决,因此智能体能够用名字来指代他们世界中的所有对象,并且这些知识被整合到他们由语言模型提供的更广泛的语言理解中。让所有100个智能体同时生活在同一个模拟世界中。现在,会发生什么?社会就是你所需要的 "假说似乎表明,这将足以启动一个累积性的文化创新爆炸棘轮。但真的会这样吗?当然,底层的具体属性也很重要。我们不相信任何含有足够复杂性的环境都能产生创新,甚至对于一个包含大量认知能力的个体智能体的多智能体系统也是如此。这就提出了一个问题:环境的哪些属性重要,哪些不重要?一个环境是否有必要和充分的条件来 "允许 "实质性的创新?我们甚至如何研究这样的问题?本论文涉及该领域的一个特定假设:微观经济学中重要的属性对于激励智能体进行探索和创新也很重要。原因是经济学是一门激励科学。经济学中强调的环境属性是那些为智能体互动创造激励的环境属性。同时在人工智能中,激励也是智能体探索的动力。激励是我们认为在仅限社交的思想实验中所缺乏的。如果没有任何创新动力,智能体根本不会创新。
通过获利进行的探索取决于环境对探索的激励。激励措施在策略空间上导致了价值梯度的产生。例如,竞争激励提供了探索的内在动力。一旦一个智能体开始习惯性地利用任何特定的解决方案,它就会激励其他智能体投入时间和精力来学习如何适应这种反应。在严格的竞争性双人游戏环境中,如围棋或抬头扑克游戏(Bowling等人,2015;Silver等人,2017),我们将智能体描述为适应性地利用对方,并且(如果使用适当的算法)将最终将收敛到僵局:纳什均衡。然而,这一点可能离他们的初始行为的距离是任意的。在一个大世界里,智能体有可能在很长一段时间内不断完善它们的行为,并创新新的行为以更好地适应对方。
生产、消费和贸易等经济行为是由个人制定的,但又交织成一个复杂的整体,由许多个体及其所处环境的相互作用组成。这种行为的相互支持系统会激励个人学习特定种类的事物,例如如何提高生产过程的效率。这适用于人类经济,也应该适用于人工经济。Read(1958)用一个小故事说明了这个观点,这个故事从一支铅笔的角度出发,铅笔自豪地描述了它的诞生。铅笔的木材来自北加州的一棵直纹雪松树,由一队带着锯子、卡车和绳子的伐木工人砍下。铅笔的石墨是在斯里兰卡开采的,其开采涉及一系列其他工具,必须通过海运运到铅笔厂。众多码头工人、水手和灯塔看守人都采取行动,以确保其安全通过。故事就这样持续了好几页,直到读者对诞生了铅笔的、横跨全球的合作机器的复杂性产生了真正的敬畏感。Read (1958) 指出,甚至没有必要让所有参与铅笔构造的人都看到最终产品或对它本身有任何兴趣。但无论如何,铅笔生产系统作为一个整体是连接在一起的。事实上,这个系统不仅仅是这样,它还在蓬勃发展。参与其中的个人不需要关心铅笔,也不需要知道铅笔生产的上游或下游步骤,但他们都通过市场经济提供的激励系统联系在一起。所有的人都朝着他们的目标行动,而市场这只 "看不见的手 "协调着他们的活动。此外,考虑一下如果对铅笔的需求增加会发生什么,例如,如果总人口数量增加,就会发生这种情况。在其他条件相同的情况下,对铅笔的更大需求创造了对石墨和雪松木的更大需求。这激励了所有参与铅笔生产供应链的许多不同的人,使他们提高当地的效率,所以他们最终可能会利用需求的增加,销售更多的产品,获得更大的利润。就强化学习而言,市场经济所创造的激励措施被智能体体验为策略空间上的价值梯度。施加这样的梯度对代理人最终学习的策略可能有很大影响。
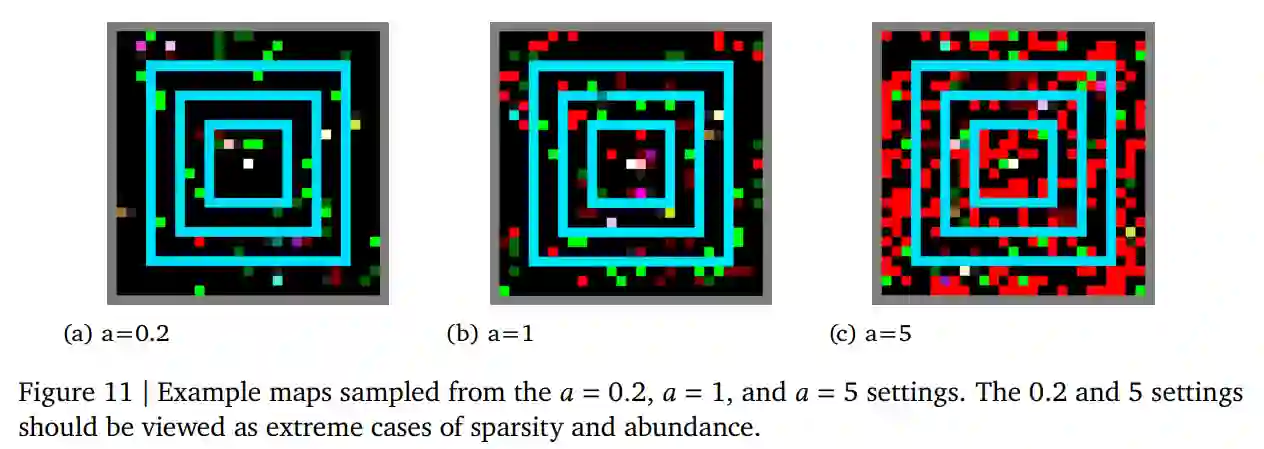
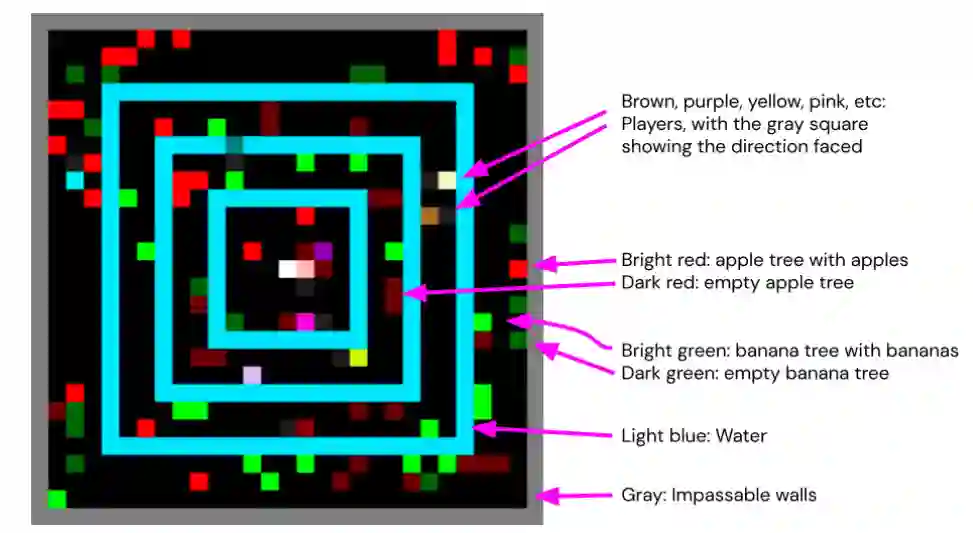
在本文中,我们将准确研究最先进的RL多智能体群体中的微观经济行为(生产、贸易和消费)是如何产生的。在我们称为 Fruit Market 的环境中,利用深度RL智能体从头开始学习如何生产、交易和消耗资源,以最大化他们的个人奖励。当环境以微观经济学 101 学生熟悉的方式发生变化时,通过调整与供给或需求相关的环境特征,人口的均衡生产、消费和定价行为等要素使其在很大程度上朝着我们对微观经济学的预期方向转变。我们的环境包括空间和时间的维度,允许出现诸如反映附近资源丰富的当地价格以及学习利用这些价格差异的智能体的套利行为等现象。然而,我们的工作并不是真正将最先进的人工智能应用于经济建模(为此,请参阅 Zheng et al. (2020))。相反,我们的目标是探索这种微观经济行为的产生,就像我们在创建通用人工智能 (AGI) 的广泛项目中研究任何其他社会行为一样。
这项工作的一个关键要素是我们探索必须将哪些微观经济知识(如果有)构建到环境中,以便当前最先进的智能体发现和改进生产、消费、易货和套利行为。我们把自己限制在只调整环境上。我们使用的智能体是通用的深度强化学习智能体,它已被广泛用于其他MARL研究中。它们从一个随机初始化的状态开始训练,没有特定领域的先验知识、参数调整或代码。在这种情况下,我们发现了许多操纵环境的方法,这些方法可以从根本上改变群体收敛的最终行为,方法中包括智能体之间的贸易是否繁荣,或者根本没有出现。除了证明智能体成功学习的经验结果外,我们还对这些环境选择进行了大量分析,以说明为什么会做出这些选择,以及其他选择的表现如何。例如,我们将证明,如果当前的智能体进行交易的行动过于简易,如 "在地上丢一个物品 "或 "给另一个代理人一个物品",则他们不会学会交易。这些动作可以用来交易货物,但很难学会恰当地使用它们:如果另一个智能体还没有学会给予其他东西作为回报,为什么要把物品给他?然而,如果环境含有一种机制,通过使交换原子化来促进交易--在已达成协议的代理之间同时交换物品--那么智能体就能持续学习如何进行交易。在现实世界中,会有一整套的惯例、规范和制度来支持这一点,例如私有财产所有权的概念,用来协调每个人的期望,使交易能够或多或少地以原子方式进行(Segal and Whinston, 2013)。当我们假设一个自动的贸易便利化机制时,我们避开了所有这些结构如何出现的关键问题。这一举措对于目前的工作是至关重要的。否则,我们将无法使用今天最先进的通用智能体取得进展。然而,如果我们的智能体在未来没有这样的机制就不能学习,这将最终对我们的MARL智能体的通用性产生负面影响,因为肯定有许多重要的经济行为和现象是由潜在的市场诱导惯例、规范和机构的属性决定的(Coase, 1988)。在不否定这种市场诱导结构的重要性的情况下,我们暂时把它们放在一边。通过把注意力集中在以自动贸易解决机制为特征的案例上,我们能够在下游问题上取得进展,如环境变化(如供应和需求转变)如何影响出现的生产、消费、易货和套利行为。学习这些行为对MARL智能体来说仍然是一项复杂的壮举,因为它们涉及到在哪里收获什么,到哪里去寻找其他人进行交易的交错决策,以及提出和接受什么提议。
人工智能研究依赖于捕捉重要认知和社会挑战的模拟环境。这是因为在这种环境中学习的智能体面临着激励措施,该环境中包含促使他们养成认知的习惯,发现描述他们的世界以及他们如何在其中进行有效行为等基本概念(Silver等人,2021)。这种研究方法的一个含义是,为了实现构建具有通用能力的智能体为目标,研究人员必须不断地增加所考虑的环境集。最终,它应该反映对所有概念上不同的智力原则的全面解释。对于在现实生活中如此丰富的社会智能领域,它在MARL研究中的镜像仍然非常不完整。我们在这项工作中的目标是将交易、谈判、专业化和适应不断变化的人口等主题加入到MARL研究的领域中。为了促进这个方向的进一步研究,我们已经准备了一个开源版本的环境,并将把它作为熔炉环境套件纳入下一个版本(Leibo等人,2021)。