扎心实战案例:麻(shi)雀(zhan)虽小,五脏俱全

邬书豪,车联网数据挖掘工程师 ,R语言中文社区专栏作者。微信ID:tsaiedu
知乎专栏:https://www.zhihu.com/people/wu-shu-hao-67/activities
往期回顾


首先呢,猜测一下家的心思:这个推文是啥,标题这么奇怪;哇,推文开头的玻璃(还是碎玻璃)是啥?!还能不能看下去啊......
放心吧,能看的。这是一个对玻璃进行分类的问题,而且还是多分类不平衡问题。虽然说大家对玻璃并没有啥兴趣,但是实战内容还是可以的哦。
废话不说,直直直奔主题了!!!
本次实战大致包括五部分:
可视化
分层抽样
决策树
随机森林
特征选择+随机森林
## 加载后续分析所需程序包
## 加载所需的程序包
library(ggplot2)
library(Rmisc)
library(caret)
## 读取数据+简单探索
## 读取数据+简单探索
glass <- read.csv('../input/glass.csv')
str(glass)
summary(glass)
head(glass)

通过str函数对数据集进行简单的结构探索,我们可以得到三个重要信息:
·导入的数据集是数据框类型
·该数据集有214行,10列
·所有变量均是数值
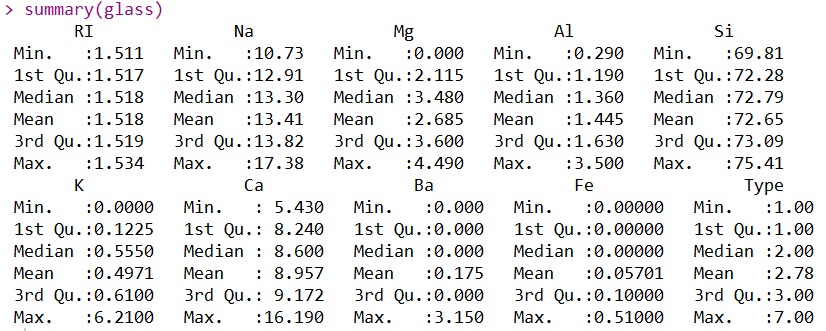
通过summary函数对数据集进行统计主要描述性统计量,我们得到了最小值、中位数、最大值等统计量,方便我们在一定程度上发现各个变量是否存在异常值(最终还得通过业务去决定)。
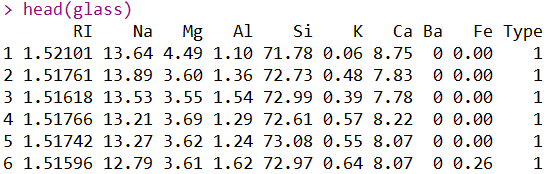
通过head函数,可以展示数据集的前六行。通过这三个函数,就可以大致对整个数据集产生一个轮廓。细心的人到这里就会发现,到底是几类啊,每一类有多少个样本啊,通过简单的探索也没体现处理啊?!不着急,进行简单的探索之后,下一步就用图去探索一些上面为表达出的信息,俗话说的好“能用图不用表,能用表不用文字”。
## 描述性分析
## 探索不同类别的个数
glass$Type <- as.factor(glass$Type)
ggplot(glass, aes(x = Type, fill = Type)) +
geom_bar(width = 0.7) +
labs(x = 'Type', y = 'Count', title = 'The Number Of Different Types') +
theme_bw() +
theme(axis.text = element_text(size = rel(1)),
axis.title = element_text(size = rel(1.1)),
plot.title = element_text(size = rel(1.4), hjust = 0.5)) +
guides(fill = 'none')
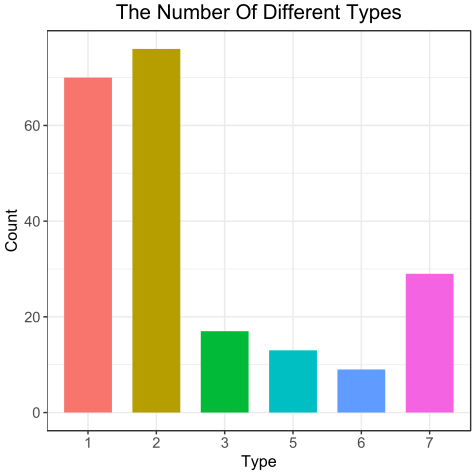
看到这个图,想必上面关于类别的疑问也就得到答复了:一共6类,而且类别不平衡。到这里不得不说一句,其实如果想简单粗暴的查看类别的信息,可以直接使用table(glass$Type)去统计,但是呢,表现出来的效果不同,不同场合使用不同的方式才使最好的。接下来就使用箱线图去探索一下每个自变量与因变量的关系。
## 箱线图---variables VS type
var_names <- names(glass[-10])
gp <- lapply(var_names, function(x) {
ggplot(glass, aes(x = Type, y = eval(parse(text = x)), fill = Type)) +
geom_boxplot() +
labs(y = x, title = paste(x, "VS Type", sep = " ")) +
theme_bw() +
theme(axis.text = element_text(size = rel(1)),
axis.title = element_text(size = rel(1.1)),
plot.title = element_text(size = rel(1.2), hjust = 0.5)) +
guides(fill = 'none')
})
multiplot(plotlist = gp[1:6], cols = 2)
multiplot(plotlist = gp[7:9], cols = 3)
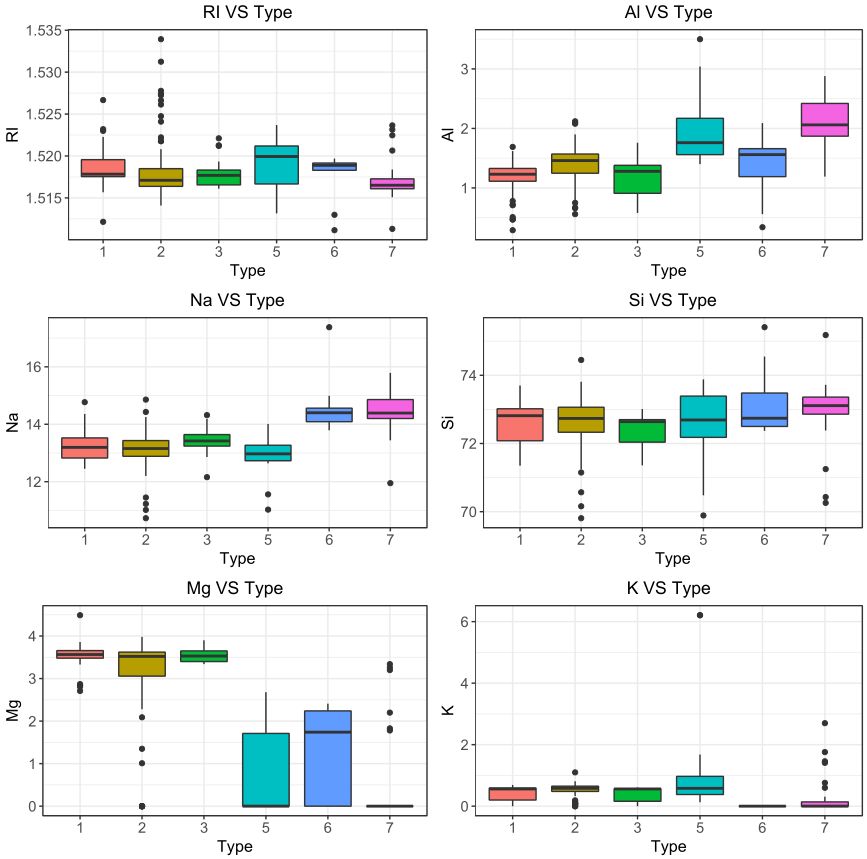
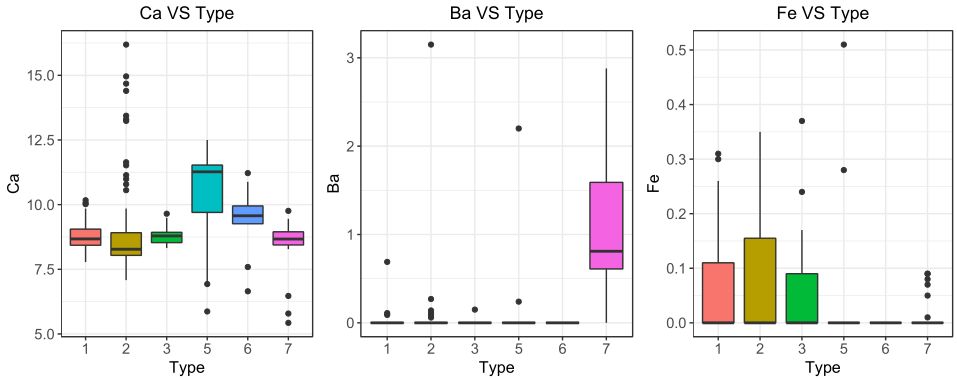
上面的9个箱线图中有几个比较丑,由于对业务的不熟悉和节省篇幅,所以我就不剔除离群点在进行绘图了,有强迫症的可以自己剔除之后在绘图。
通过这几个图呢,大致能看出不同的类别中不同元素和折射率的分布情况。从一定程度上而言,变量分布差距越明显,那么用该变量就更容易区分类别。再次声明:本人不是从事玻璃行业的,不清楚业务问题,所以就不进行“异常值”的处理了,后续直接建模......
## 分层抽样
分层抽样是在不平衡分类问题中常用的一种抽样方法,分层抽样后的数据与原数据的分布几乎一致,也就意味着在此时属于有效抽样。
## 创建训练集和测试集
set.seed(1234)
idx <- createDataPartition(glass$Type, p = 0.7, list = F)
traindata <- glass[idx, ]
testdata <- glass[-idx, ]
round(prop.table(table(glass$Type)), 3)
round(prop.table(table(traindata$Type)), 3)
round(prop.table(table(testdata$Type)), 3)

从上图可以看出,不同的类别在原数据、训练集和测试集中占比还是比较一致的。由于数据集样本较少,比例稍有差距,否则比例趋近一致。
#### 建模分类
## 决策树
## 决策树
ctrl <- trainControl(method = 'boot632', selectionFunction = 'oneSE')
set.seed(1234)
model_C50 <- train(Type ~., data = traindata, method = 'C5.0', trControl = ctrl)
pred_C50 <- predict(model_C50, testdata[-10])
confusionMatrix(pred_C50, testdata$Type) # 0.8361--0.7683
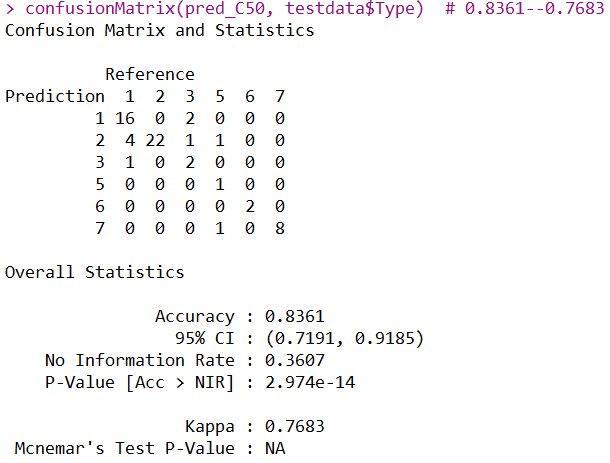
虽然说混淆矩阵的整体正确率不适合去评估类别不平衡的分类问题,但是并不是绝对的。通过此混淆矩阵的结果,可以看出类别少的样本也有不错的分类效果,所以说此混淆矩阵在这里也是合适的,并且kappa值也达到了0.7683,说明模型达到了不错的一致性。
## 随机森林
## 随机森林
set.seed(1234)
model_rf <- train(Type ~., data = traindata, method = 'rf', trControl = ctrl)
pred_rf <- predict(model_rf, testdata[-10])
confusionMatrix(pred_rf, testdata$Type) # 0.8361--0.7673
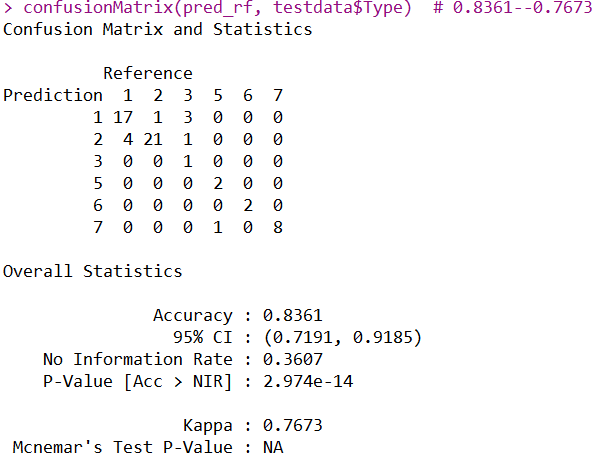
随机森林的正确率也是0.8361,但是通过混淆矩阵的详细情况,可发现预测的类别并不相同。kappa值为0.7673,略比决策树低一点点。整体而言,随机森林模型稍逊于决策树模型。
## 特征选择+随机森林
特征选择,简而言之就是筛选出一些高质量的自变量作为最终建立模型的自变量,从而不仅降低模型的复杂度,并且防止过拟合的产生。
rfeControls_rf <- rfeControl(
functions = rfFuncs,
method = 'boot')
set.seed(1)
profile_rf <- rfe(x = traindata[-10],
y = traindata[, 10],
sizes = seq(4, 9, 1),
rfeControl = rfeControls_rf)
profile_rf
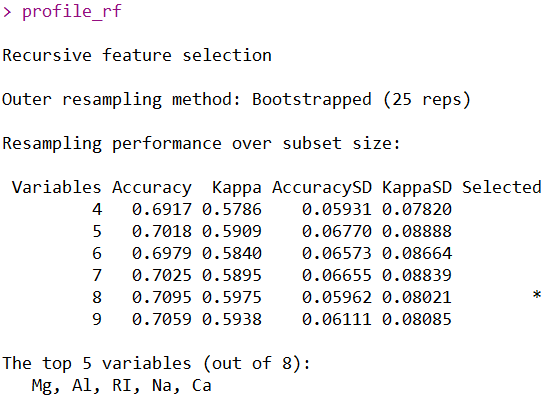
经过自定义特征选择之后,发现使用8个自变量作为建模变量为此时最好的选择,所以我们尝试使用8个自变量建模。
vars_new <- c(profile_rf$optVariables, 'Type')
set.seed(1234)
model_rf2 <- train(Type ~.,
data = traindata[vars_new],
method = 'rf',
trControl = ctrl)
pred_rf2 <- predict(model_rf2, testdata[-10])
confusionMatrix(pred_rf2, testdata$Type) # 0.8525--0.7905
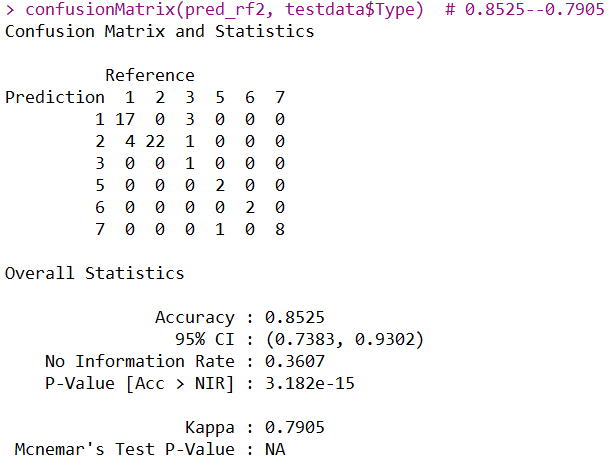
经过特征选择,正确率稍微高了一点点。经过观察混淆矩阵,发现第2类玻璃全部分类正确,之前预测错了一个样本,总而言之,也是提高了,并且模型的复杂度和过拟合性也有所降低。
到最后了,好像忘了一个重要的问题,玻璃的类别详情如下:
1 building_windows_float_processed
2 building_windows_non_float_processed
3 vehicle_windows_float_processed
4 vehicle_windows_non_float_processed (none in this database)
5 containers
6 tableware
7 headlamps
注:本案例不提供数据集,如果要学习完整案例,点击文章底部阅读原文或者扫描课程二维码,购买包含数据集+代码+PPT的《kaggle十大案例精讲课程》,购买学员会赠送文章的数据集。
《kaggle十大案例精讲课程》提供代码+数据集+详细代码注释+老师讲解PPT!综合性的提高你的数据能力,数据处理+数据可视化+建模一气呵成!
相关课程推荐





