VideoMAE:简单高效的视频自监督预训练新范式|NeurIPS 2022

新智元报道
新智元报道
【新智元导读】本文将介绍南大、腾讯和上海人工智能实验室被NeurIPS 2022收录的工作。

1. 背景介绍
2. 研究动机
3. 方法介绍
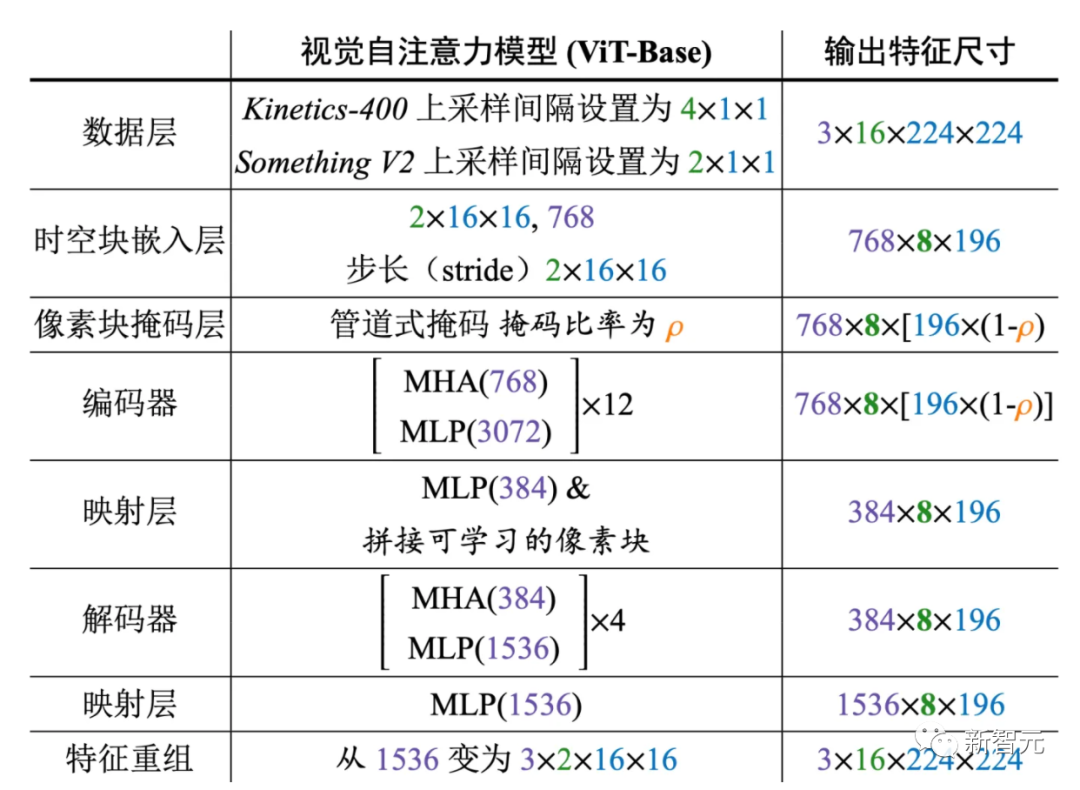
4. VideoMAE实现细节
5. 消融实验
6. VideoMAE的重要特性
7. 主要结果
8. 对社区的影响
9. 总结
背景介绍
研究动机
方法介绍
MAE概述
视频数据的特性
与图像数据相比,视频数据包含了更多的帧,也具有更加丰富的运动信息。本节会先分析一下视频数据的特性。

时序相关性
VideoMAE方法介绍
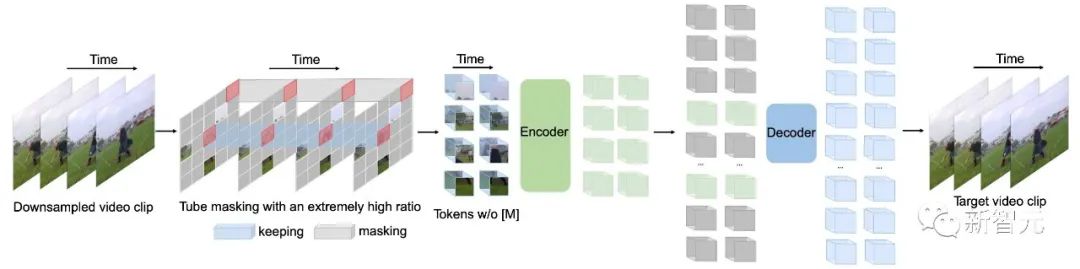
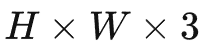 个像素。在具体的实验设置中,Kinetics-400 和 Something-Something V2 数据集上的采样间隔 分别设置为4和2。
个像素。在具体的实验设置中,Kinetics-400 和 Something-Something V2 数据集上的采样间隔 分别设置为4和2。
时空块嵌入
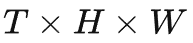 视频片段中大小为
视频片段中大小为
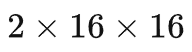 的视觉像素视为一个视觉像素块。因此,采样得到的视频片段经过时空块嵌入(cube embedding)层后可以得到
的视觉像素视为一个视觉像素块。因此,采样得到的视频片段经过时空块嵌入(cube embedding)层后可以得到
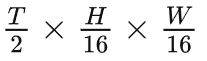 个视觉像素块。在这个过程中,同时会将视觉像素块的通道维度映射为。这种设计可以减少输入数据的时空维度大小,一定程度上也有助于缓解视频数据的时空冗余性。
个视觉像素块。在这个过程中,同时会将视觉像素块的通道维度映射为。这种设计可以减少输入数据的时空维度大小,一定程度上也有助于缓解视频数据的时空冗余性。
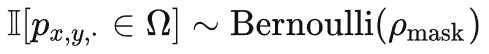 。不同的时间t共享相同的值。使用这种掩码策略,相同空间位置的token将总是会被掩码。所以对于一些视觉像素块(例如,不同掩码策略的示例图第 4 行的包含手指的像素块),网络将无法在其他帧中找到其对应的部分。这种设计这有助于减轻重建过程中出现「信息泄露」的风险,可以让VideoMAE通过提取原始视频片段中的高层语义信息,来重建被掩码的token。
。不同的时间t共享相同的值。使用这种掩码策略,相同空间位置的token将总是会被掩码。所以对于一些视觉像素块(例如,不同掩码策略的示例图第 4 行的包含手指的像素块),网络将无法在其他帧中找到其对应的部分。这种设计这有助于减轻重建过程中出现「信息泄露」的风险,可以让VideoMAE通过提取原始视频片段中的高层语义信息,来重建被掩码的token。
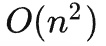 级别的计算复杂度是网络的计算瓶颈,而前文中针对VideoMAE使用了极高掩码比率策略,仅将未被遮蔽的token(例如10%)输入到编码器中。这种设计一定程度上可以有效地缓
级别的计算复杂度的问题。
级别的计算复杂度是网络的计算瓶颈,而前文中针对VideoMAE使用了极高掩码比率策略,仅将未被遮蔽的token(例如10%)输入到编码器中。这种设计一定程度上可以有效地缓
级别的计算复杂度的问题。
VideoMAE实现细节
消融实验
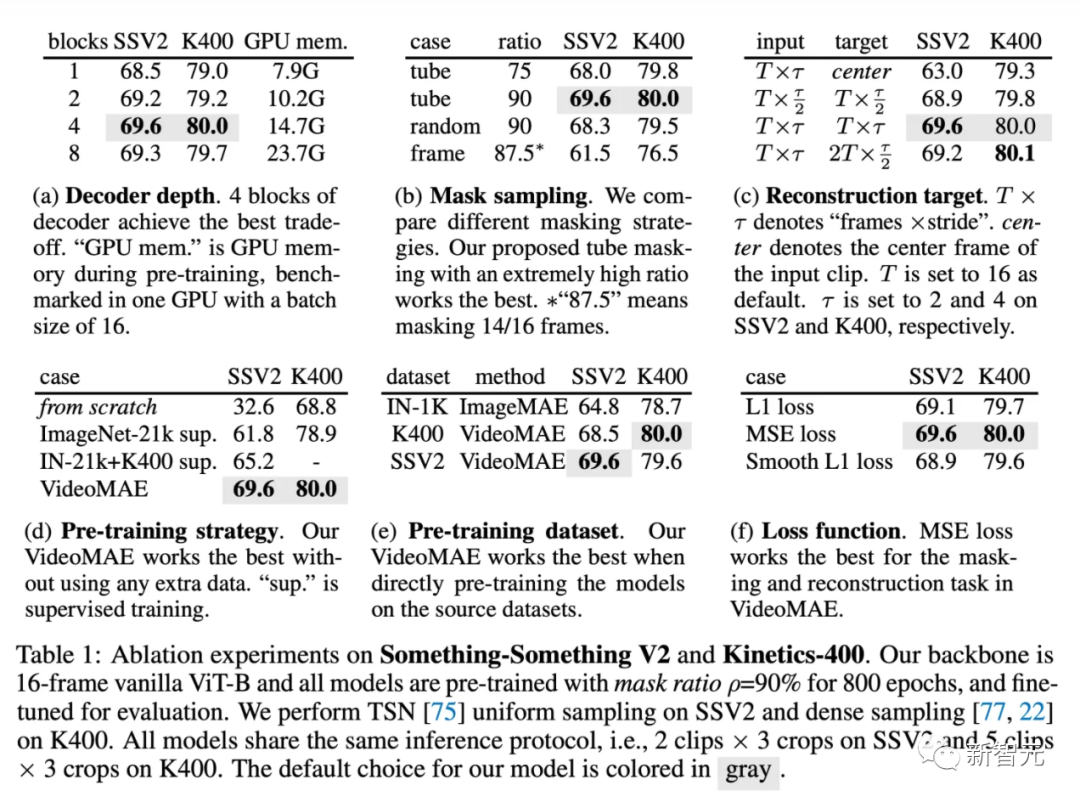
解码器设计
掩码策略
重建目标
预训练策略
预训练数据集
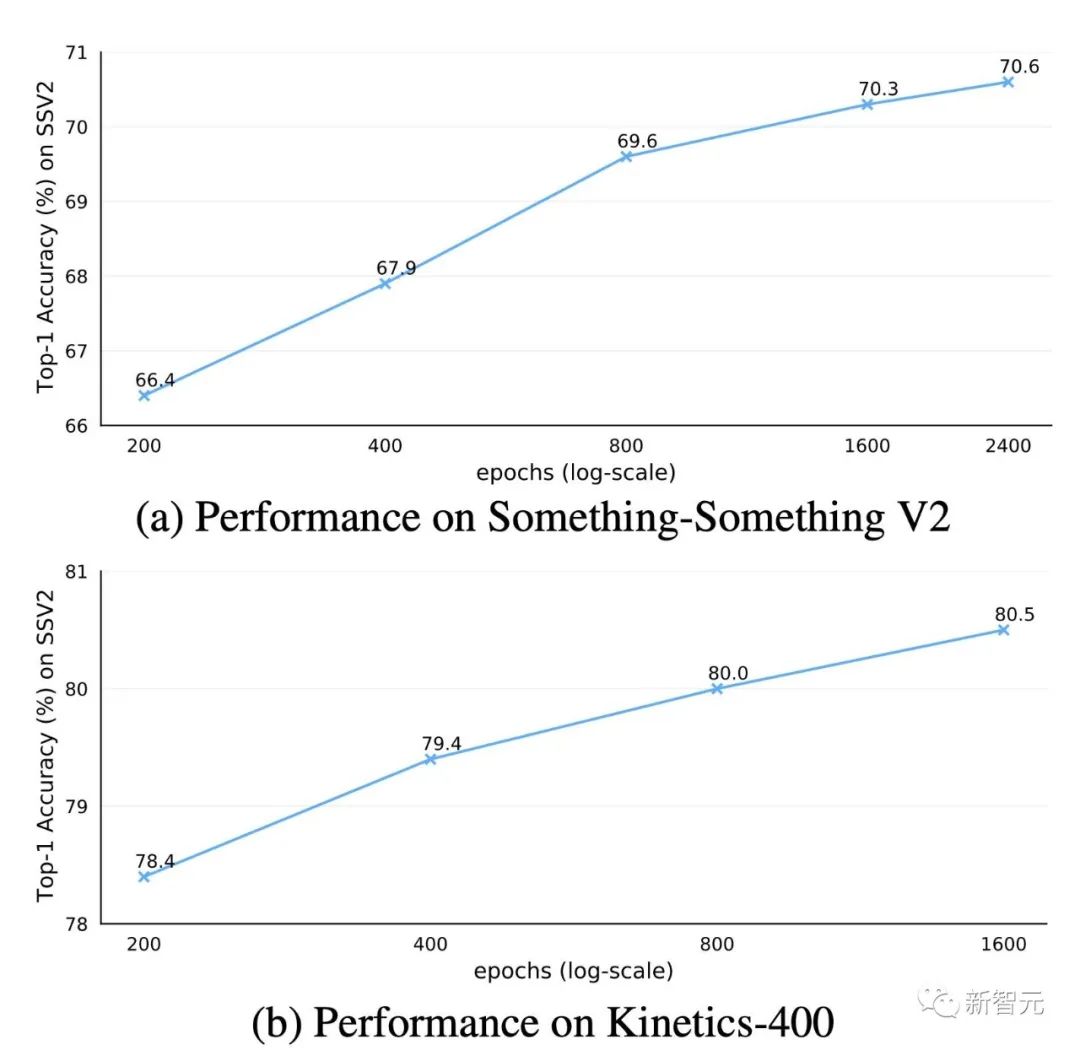
预训练轮次
VideoMAE的重要特性
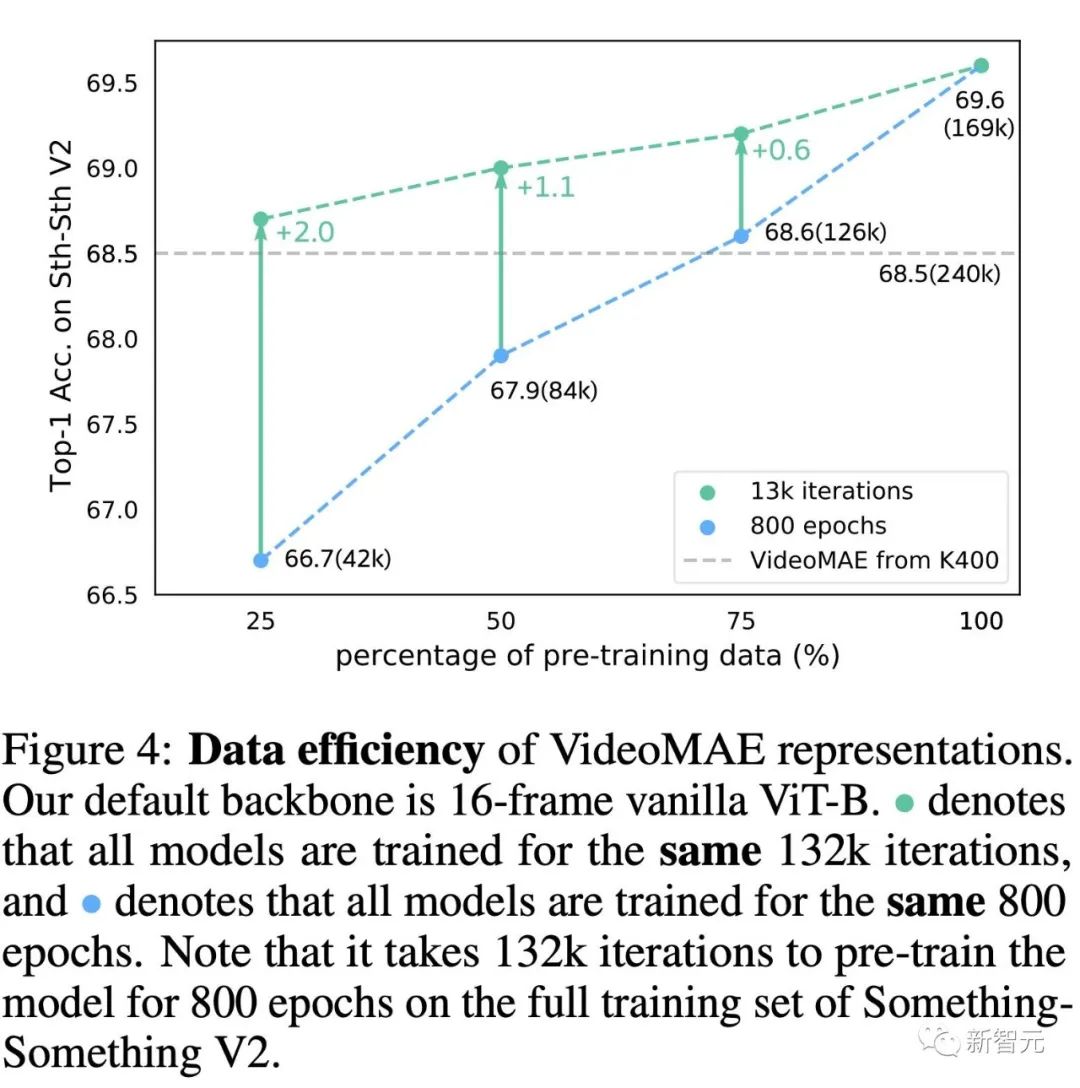
VideoMAE是一种数据高效的学习器


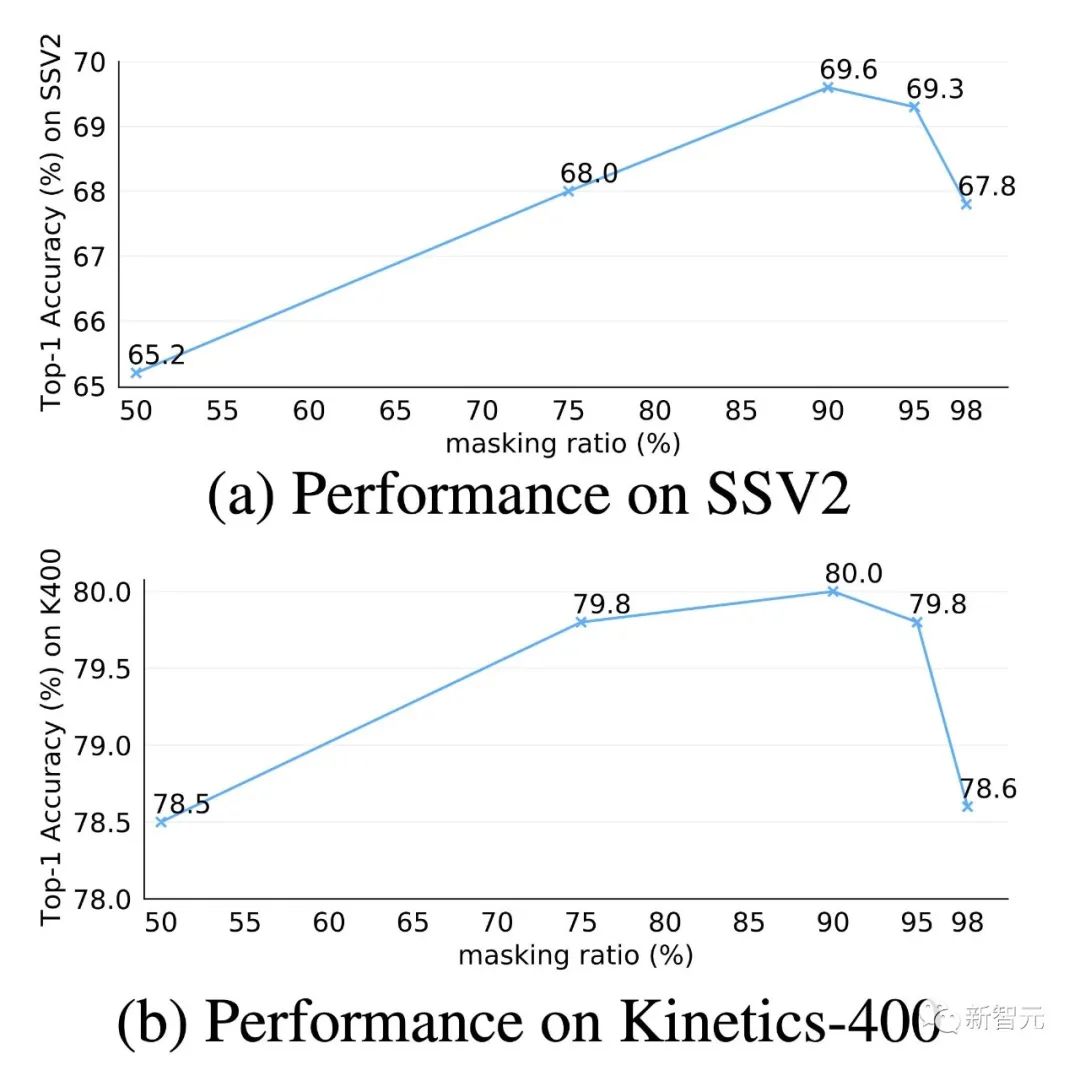
极高的掩码率

泛化和迁移能力:数据的质量与数量

主要结果
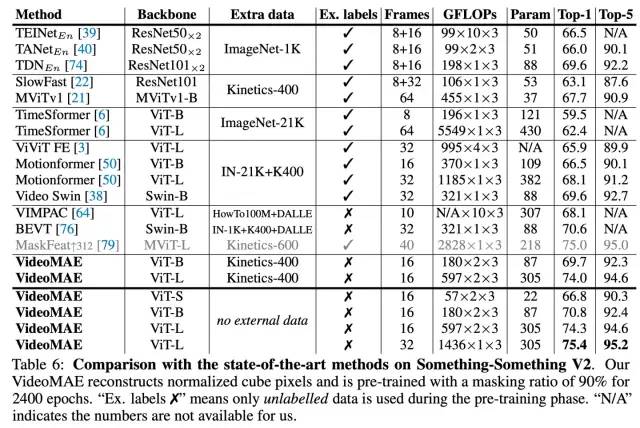
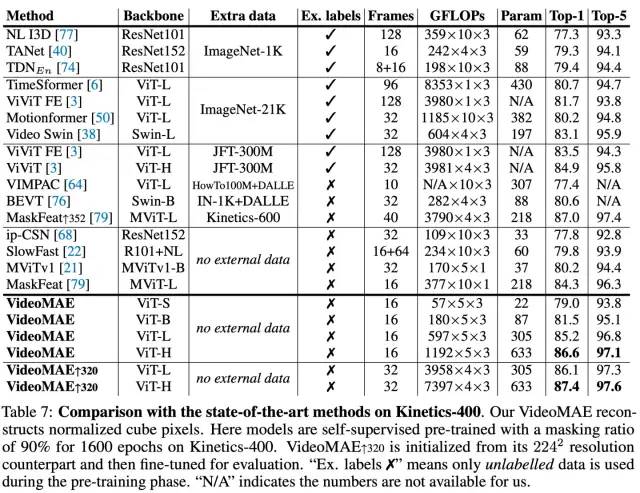
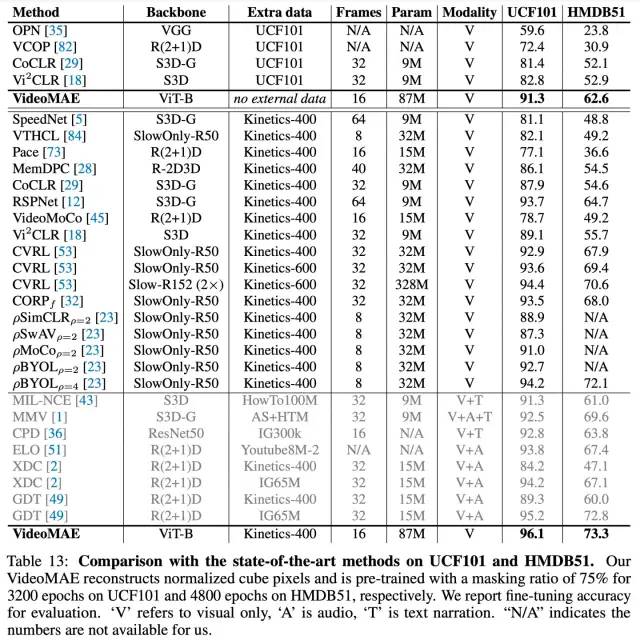
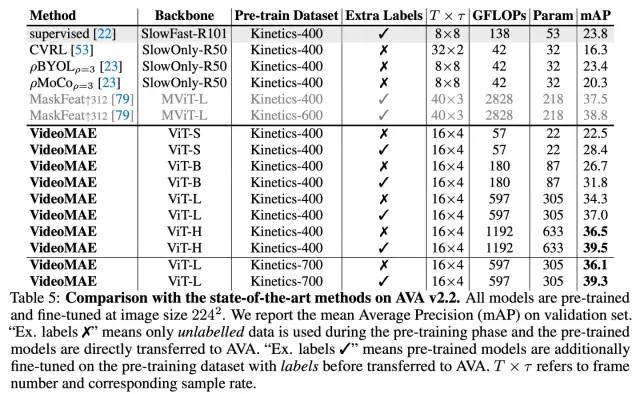
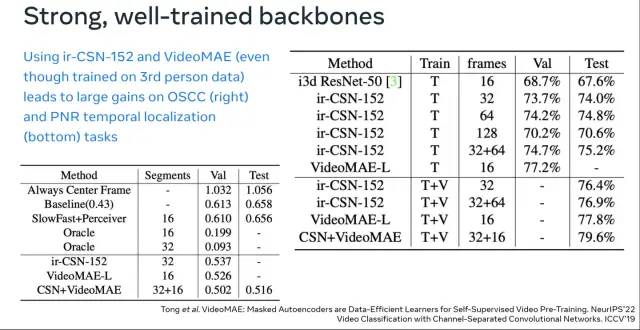
对社区的影响


总结
参考资料:



登录查看更多
相关内容

Arxiv
0+阅读 · 2023年1月31日
Arxiv
13+阅读 · 2020年12月14日

相关VIP内容
相关资讯